Ten artykuł jest trzecią częścią serii poświęconej błędom, pułapkom i najlepszym praktykom w T-SQL. Wcześniej zajmowałem się determinizmem i podzapytaniami. Tym razem skupiam się na łączeniu. Niektóre z błędów i najlepszych praktyk, które tu omawiam, są wynikiem ankiety, którą przeprowadziłem wśród innych MVP. Dziękujemy Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man i Paul White za przedstawienie swoich spostrzeżeń!
W moich przykładach użyję przykładowej bazy danych o nazwie TSQLV5. Skrypt, który tworzy i wypełnia tę bazę danych, oraz jego diagram ER można znaleźć tutaj.
W tym artykule skupię się na czterech klasycznych typowych błędach:COUNT(*) w złączeniach zewnętrznych, agregatach podwójnie zanurzanych, sprzeczności ON-WHERE i sprzeczności złączeń OUTER-INNER. Wszystkie te błędy są związane z podstawami zapytań T-SQL i można ich łatwo uniknąć, jeśli zastosujesz się do prostych najlepszych praktyk.
COUNT(*) w złączeniach zewnętrznych
Nasz pierwszy błąd dotyczy niepoprawnych zliczeń zgłoszonych dla pustych grup w wyniku użycia sprzężenia zewnętrznego i agregacji COUNT(*). Rozważ następujące zapytanie obliczające liczbę zamówień i całkowity transport na klienta:
USE TSQLV5; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip SELECT custid, COUNT(*) AS numorders, SUM(freight) AS totalfreight FROM Sales.Orders GROUP BY custid ORDER BY custid;
To zapytanie generuje następujące dane wyjściowe (w skrócie):
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 23 5 637.94 ... 56 10 862.74 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (89 rows affected)
Obecnie w tabeli Klienci znajduje się 91 klientów, z czego 89 złożyło zamówienia; stąd wynik tego zapytania pokazuje 89 grup klientów i ich poprawną liczbę zamówień oraz łączne agregaty frachtu. Klienci o identyfikatorach 22 i 57 są obecni w tabeli Klienci, ale nie złożyli żadnych zamówień i dlatego nie pojawiają się w wyniku.
Załóżmy, że jesteś proszony o uwzględnienie klientów, którzy nie mają żadnych powiązanych zamówień w wyniku zapytania. Naturalną rzeczą w takim przypadku jest wykonanie lewego połączenia zewnętrznego pomiędzy Klientami i Zamówieniami, aby zachować klientów bez zamówień. Jednak typowym błędem podczas konwersji istniejącego rozwiązania na takie, które stosuje sprzężenie, jest pozostawienie obliczenia liczby zamówień jako COUNT(*), jak pokazano w następującym zapytaniu (nazwijmy je Zapytanie 1):
SELECT C.custid, COUNT(*) AS numorders, SUM(O.freight) AS totalfreight
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
GROUP BY C.custid
ORDER BY C.custid; To zapytanie generuje następujące dane wyjściowe:
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 1 NULL 23 5 637.94 ... 56 10 862.74 57 1 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rows affected)
Zauważ, że klienci 22 i 57 tym razem pojawiają się w wyniku, ale ich liczba zamówień pokazuje 1 zamiast 0, ponieważ COUNT(*) zlicza wiersze, a nie zamówienia. Całkowity fracht jest zgłaszany poprawnie, ponieważ SUM(fracht) ignoruje dane wejściowe NULL.
Plan dla tego zapytania pokazano na rysunku 1.
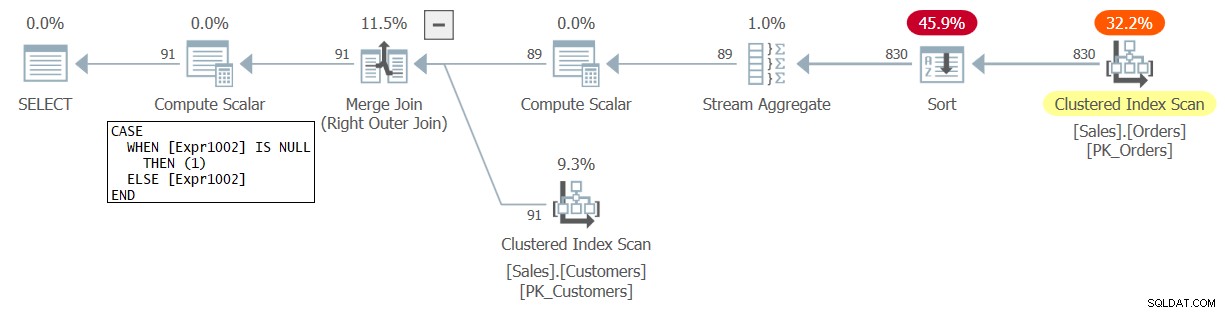 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
W tym planie Expr1002 reprezentuje liczbę wierszy na grupę, która w wyniku sprzężenia zewnętrznego jest początkowo ustawiona na NULL dla klientów bez pasujących zamówień. Operator Compute Scalar znajdujący się tuż pod głównym węzłem SELECT konwertuje NULL na 1. Jest to wynik liczenia wierszy, a nie liczenia zamówień.
Aby naprawić ten błąd, chcesz zastosować agregację COUNT do elementu z niezachowanej strony sprzężenia zewnętrznego i chcesz się upewnić, że jako dane wejściowe zostanie użyta kolumna nie dopuszczająca wartości NULL. Dobrym wyborem byłaby kolumna klucza podstawowego. Oto zapytanie o rozwiązanie (nazwijmy je Zapytanie 2) z naprawionym błędem:
SELECT C.custid, COUNT(O.orderid) AS numorders, SUM(O.freight) AS totalfreight
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
GROUP BY C.custid
ORDER BY C.custid; Oto wynik tego zapytania:
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 0 NULL 23 5 637.94 ... 56 10 862.74 57 0 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rows affected)
Zauważ, że tym razem klienci 22 i 57 pokazują prawidłową liczbę zero.
Plan dla tego zapytania pokazano na rysunku 2.
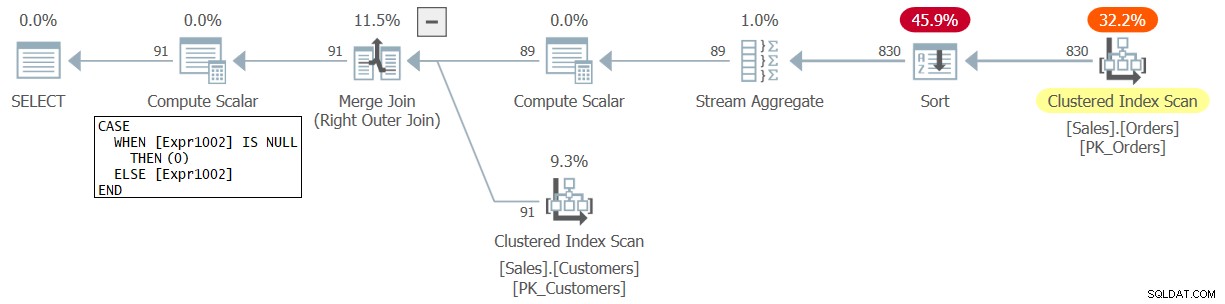 Rysunek 2:Plan dla zapytania 2
Rysunek 2:Plan dla zapytania 2
Możesz również zobaczyć zmianę w planie, gdzie NULL reprezentujący liczbę dla klienta bez pasujących zamówień jest konwertowany na 0, a nie 1 tym razem.
Używając złączeń, uważaj na zastosowanie agregacji COUNT(*). Kiedy używasz złączeń zewnętrznych, zwykle jest to błąd. Najlepszym rozwiązaniem jest zastosowanie agregacji COUNT do kolumny niepodlegającej wartości NULL po stronie wielu sprzężenia jeden-do-wielu. Kolumna klucza podstawowego jest dobrym wyborem do tego celu, ponieważ nie zezwala na wartości NULL. Może to być dobrą praktyką nawet w przypadku używania sprzężeń wewnętrznych, ponieważ nigdy nie wiadomo, czy w późniejszym czasie ze względu na zmianę wymagań trzeba będzie zmienić sprzężenie wewnętrzne na zewnętrzne.
Podwójnie zanurzane kruszywa
Nasz drugi błąd to także mieszanie złączeń i agregacji, tym razem z wielokrotnym uwzględnianiem wartości źródłowych. Rozważ następujące zapytanie jako przykład:
SELECT C.custid, COUNT(O.orderid) AS numorders, SUM(O.freight) AS totalfreight,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY C.custid
ORDER BY C.custid; To zapytanie łączy Customers, Orders i OrderDetails, grupuje wiersze według custid i ma na celu obliczenie agregatów, takich jak liczba zamówień, całkowity fracht i całkowita wartość na klienta. To zapytanie generuje następujące dane wyjściowe:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 12 419.60 4273.00 2 10 306.59 1402.95 3 17 667.29 7023.98 4 30 1447.14 13390.65 5 52 4835.18 24927.58 ... 87 37 2611.93 15648.70 88 19 546.96 6068.20 89 40 4017.32 27363.61 90 17 262.16 3161.35 91 16 461.53 3531.95
Czy widzisz błąd tutaj?
Nagłówki zamówień są przechowywane w tabeli Orders, a odpowiadające im linie zamówienia są przechowywane w tabeli OrderDetails. Kiedy łączysz nagłówki zamówień z odpowiadającymi im liniami zamówienia, nagłówek jest powtarzany w wyniku łączenia na linię. W rezultacie agregacja COUNT(O.orderid) niepoprawnie odzwierciedla liczbę wierszy zamówienia, a nie liczbę zamówień. Podobnie SUM(O.freight) błędnie uwzględnia fracht wielokrotnie na zamówienie — tyle, ile jest wierszy zamówienia w zamówieniu. Jedyne poprawne obliczenie agregujące w tym zapytaniu to to, które służy do obliczenia całkowitej wartości, ponieważ jest stosowane do atrybutów linii zamówienia:SUM(OD.qty * OD.cena jednostkowa * (1 – OD.discount).
Aby uzyskać prawidłową liczbę zamówień, wystarczy użyć odrębnej agregacji liczby:COUNT(DISTINCT O.orderid). Można by pomyśleć, że tę samą poprawkę można zastosować do obliczenia całkowitego ładunku, ale to tylko wprowadzi nowy błąd. Oto nasze zapytanie z różnymi agregatami zastosowanymi do miar nagłówka zamówienia:
SELECT C.custid, COUNT(DISTINCT O.orderid) AS numorders, SUM(DISTINCT O.freight) AS totalfreight,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY C.custid
ORDER BY C.custid; To zapytanie generuje następujące dane wyjściowe:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 6 225.58 4273.00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 448.23 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 87.66 3161.35 ***** 91 7 175.74 3531.95
Liczba zamówień jest teraz poprawna, ale nie są to całkowite wartości frachtu. Czy widzisz nowy błąd?
Nowy błąd jest bardziej nieuchwytny, ponieważ objawia się tylko wtedy, gdy ten sam klient ma co najmniej jeden przypadek, w którym wiele zamówień ma dokładnie takie same wartości frachtu. W takim przypadku teraz bierzesz pod uwagę fracht tylko raz na klienta, a nie raz na zamówienie, jak powinieneś.
Użyj następującego zapytania (wymaga programu SQL Server 2017 lub nowszego), aby zidentyfikować różne wartości frachtu dla tego samego klienta:
WITH C AS
(
SELECT custid, freight,
STRING_AGG(CAST(orderid AS VARCHAR(MAX)), ', ')
WITHIN GROUP(ORDER BY orderid) AS orders
FROM Sales.Orders
GROUP BY custid, freight
HAVING COUNT(*) > 1
)
SELECT custid,
STRING_AGG(CONCAT('(freight: ', freight, ', orders: ', orders, ')'), ', ') as duplicates
FROM C
GROUP BY custid; To zapytanie generuje następujące dane wyjściowe:
custid duplicates ------- --------------------------------------- 4 (freight: 23.72, orders: 10743, 10953) 90 (freight: 0.75, orders: 10615, 11005)
Dzięki tym odkryciom zdajesz sobie sprawę, że zapytanie z błędem zgłosiło niepoprawne wartości frachtu całkowitego dla klientów 4 i 90. Zapytanie podało prawidłowe wartości frachtu całkowitego dla pozostałych klientów, ponieważ ich wartości frachtu okazały się unikalne.
Aby naprawić błąd, musisz oddzielić obliczanie agregatów zamówień i linii zamówień na różne kroki za pomocą wyrażeń tabelowych, na przykład:
WITH O AS
(
SELECT custid, COUNT(orderid) AS numorders, SUM(freight) AS totalfreight
FROM Sales.Orders
GROUP BY custid
),
OD AS
(
SELECT O.custid,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY O.custid
)
SELECT C.custid, O.numorders, O.totalfreight, OD.totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN O
ON C.custid = O.custid
LEFT OUTER JOIN OD
ON C.custid = OD.custid
ORDER BY C.custid; To zapytanie generuje następujące dane wyjściowe:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 6 225.58 4273.00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 471.95 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 88.41 3161.35 ***** 91 7 175.74 3531.95
Zauważ, że łączne wartości frachtu dla klientów 4 i 90 są teraz wyższe. To są prawidłowe liczby.
Najlepszą praktyką jest bycie uważnym podczas łączenia i agregowania danych. Chcesz być czujny na takie przypadki podczas łączenia wielu tabel i stosowania agregacji do miar z tabeli, która nie jest krawędzią ani liściem tabeli w sprzężeniach. W takim przypadku zwykle musisz zastosować obliczenia agregujące w wyrażeniach tabelowych, a następnie połączyć wyrażenia tabelowe.
Więc błąd podwójnego zanurzania agregatów został naprawiony. Jednak w tym zapytaniu istnieje potencjalnie inny błąd. Czy potrafisz to zauważyć? Podam szczegóły dotyczące takiego potencjalnego błędu, jak czwarty przypadek, który omówię później w sekcji „Sprzeczność łączenia OUTER-INNER”.
Sprzeczność ON-GDZIE
Nasz trzeci błąd wynika z pomylenia ról, jakie mają odgrywać klauzule ON i WHERE. Załóżmy na przykład, że przydzielono Ci zadanie dopasowania klientów i zamówień, które złożyli od 12 lutego 2019 r., ale także uwzględnij w danych wyjściowych klientów, którzy od tego czasu nie złożyli zamówień. Próbujesz rozwiązać zadanie za pomocą następującego zapytania (nazwij je Zapytanie 3):
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
WHERE O.orderdate >= '20190212'; Podczas używania sprzężenia wewnętrznego zarówno ON, jak i WHERE pełnią tę samą rolę filtrowania, dlatego nie ma znaczenia, jak organizujesz predykaty między tymi klauzulami. Jednak w przypadku korzystania z zewnętrznego sprzężenia, jak w naszym przypadku, klauzule te mają inne znaczenie.
Klauzula ON pełni rolę dopasowania, co oznacza, że zostaną zwrócone wszystkie wiersze z zachowanej strony złączenia (w naszym przypadku Klienci). Te, które mają dopasowania oparte na predykacie ON, są powiązane ze swoimi dopasowaniami, a co za tym idzie, powtarzane na mecz. Te, które nie mają żadnych dopasowań, są zwracane z wartościami NULL jako symbolami zastępczymi w atrybutach strony niezachowanej.
Z drugiej strony, klauzula WHERE odgrywa prostszą rolę filtrującą — zawsze. Oznacza to, że zwracane są wiersze, dla których predykat filtrowania ma wartość true, a wszystkie pozostałe są odrzucane. W rezultacie niektóre wiersze z zachowanej strony połączenia można całkowicie usunąć.
Pamiętaj, że atrybuty z niezachowanej strony sprzężenia zewnętrznego (w naszym przypadku Orders) są oznaczone jako NULL dla zewnętrznych wierszy (nonmatches). Za każdym razem, gdy stosujesz filtr obejmujący element z niezachowanej strony sprzężenia, predykat filtru jest oceniany jako nieznany dla wszystkich zewnętrznych wierszy, co powoduje ich usunięcie. Jest to zgodne z trójwartościową logiką predykatów, za którą stosuje się SQL. W efekcie sprzężenie staje się w rezultacie sprzężeniem wewnętrznym. Jedynym wyjątkiem od tej reguły jest sytuacja, gdy w elemencie po stronie niezachowanej poszukujesz wartości NULL w celu zidentyfikowania niedopasowań (element IS NULL).
Nasze błędne zapytanie generuje następujące dane wyjściowe:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (195 rows affected)
Pożądany wynik ma mieć 213 wierszy, w tym 195 wierszy reprezentujących zamówienia złożone od 12 lutego 2019 r. oraz 18 dodatkowych wierszy reprezentujących klientów, którzy od tego czasu nie składali zamówień. Jak widać, rzeczywiste dane wyjściowe nie obejmują klientów, którzy nie złożyli zamówień od określonej daty.
Plan dla tego zapytania pokazano na rysunku 3.
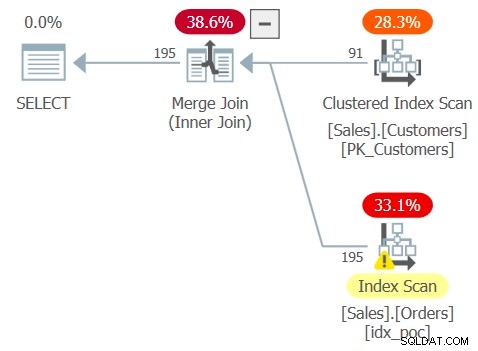 Rysunek 3:Plan dla zapytania 3
Rysunek 3:Plan dla zapytania 3
Zauważ, że optymalizator wykrył sprzeczność i wewnętrznie przekształcił sprzężenie zewnętrzne w sprzężenie wewnętrzne. Dobrze to widzieć, ale jednocześnie jest to wyraźna wskazówka, że w zapytaniu jest błąd.
Widziałem przypadki, w których ludzie próbowali naprawić błąd, dodając predykat OR O.orderid IS NULL do klauzuli WHERE, na przykład:
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
WHERE O.orderdate >= '20190212'
OR O.orderid IS NULL; Jedynym zgodnym predykatem jest ten, który porównuje identyfikatory klientów z obu stron. Tak więc samo łączenie zwraca klientów, którzy złożyli zamówienia w ogóle, wraz z odpowiadającymi im zamówieniami, a także klientów, którzy w ogóle nie złożyli zamówień, z wartościami NULL w atrybutach zamówienia. Następnie filtrowanie predykatów filtruje klientów, którzy złożyli zamówienia od określonej daty, a także klientów, którzy w ogóle nie złożyli zamówień (klienci 22 i 57). W zapytaniu brakuje klientów, którzy złożyli niektóre zamówienia, ale nie od określonej daty!
To zapytanie generuje następujące dane wyjściowe:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 22 Customer DTDMN NULL NULL 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (197 rows affected)
Aby poprawnie naprawić błąd, potrzebujesz zarówno predykatu, który porównuje identyfikatory klientów z obu stron, jak i predykatu z datą zamówienia, który będzie uważany za pasujące predykaty. Aby to osiągnąć, oba muszą być określone w klauzuli ON, w ten sposób (nazwij to zapytanie 4):
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
AND O.orderdate >= '20190212'; To zapytanie generuje następujące dane wyjściowe:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 3 Customer KBUDE NULL NULL 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 7 Customer QXVLA NULL NULL 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 21 Customer KIDPX NULL NULL 22 Customer DTDMN NULL NULL 23 Customer WVFAF NULL NULL 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (213 rows affected)
Plan dla tego zapytania pokazano na rysunku 4.
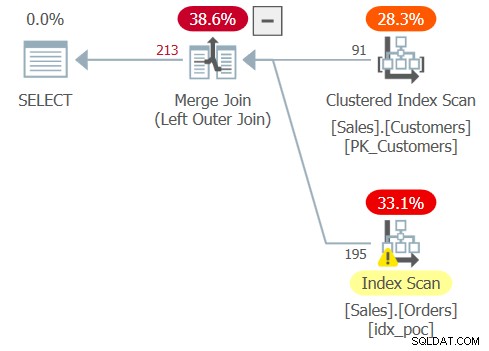 Rysunek 4:Plan dla zapytania 4
Rysunek 4:Plan dla zapytania 4
Jak widać, tym razem optymalizator obsługiwał łączenie jako łączenie zewnętrzne.
To bardzo proste zapytanie, którego użyłem w celach ilustracyjnych. W przypadku znacznie bardziej skomplikowanych i złożonych zapytań nawet doświadczeni programiści mogą mieć trudności z ustaleniem, czy predykat należy do klauzuli ON, czy do klauzuli WHERE. To, co ułatwia mi życie, to po prostu zadać sobie pytanie, czy predykat jest predykatem pasującym, czy filtrującym. Jeśli to pierwsze, należy do klauzuli ON; jeśli to drugie, należy do klauzuli WHERE.
Zewnętrzna-wewnętrzna sprzeczność łączenia
Nasz czwarty i ostatni błąd jest w pewnym sensie odmianą trzeciego błędu. Zwykle dzieje się to w zapytaniach z wieloma sprzężeniami, w których mieszasz typy sprzężenia. Jako przykład załóżmy, że musisz połączyć tabele Klienci, Zamówienia, Szczegóły zamówienia, Produkty i Dostawcy, aby zidentyfikować pary klient-dostawca, które miały wspólne działania. Piszesz następujące zapytanie (nazwij je Zapytanie 5):
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
INNER JOIN Sales.Orders AS O
ON O.custid = C.custid
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
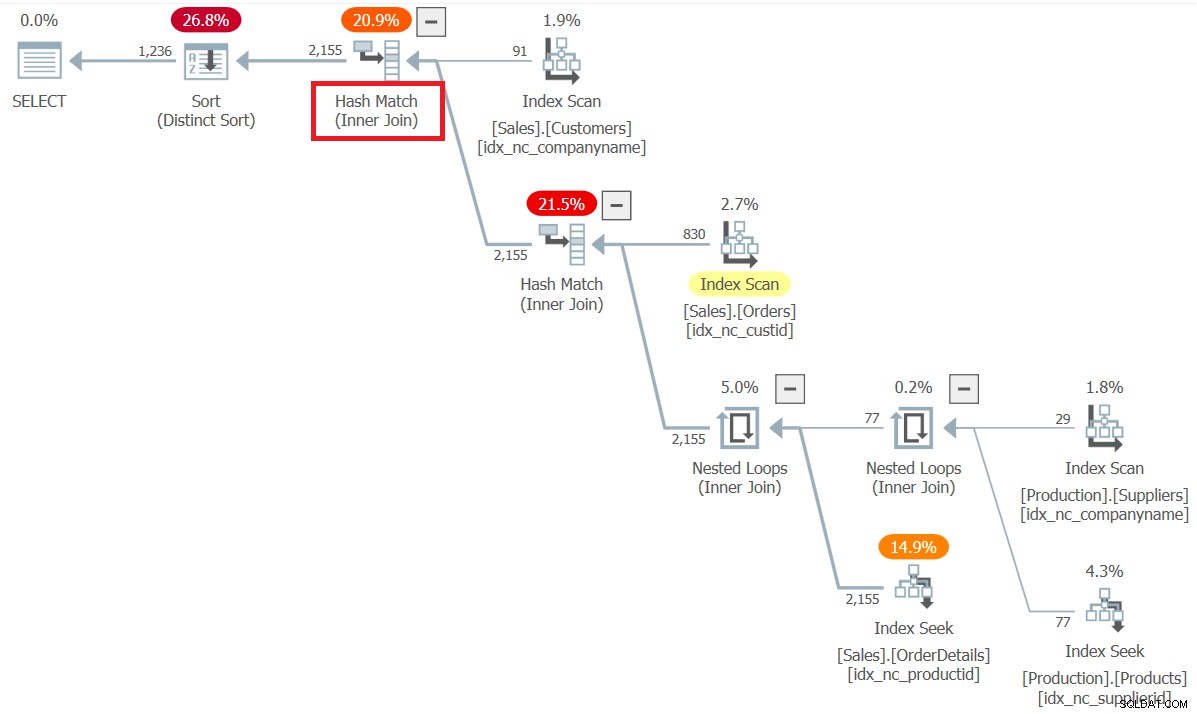
ON S.supplierid = P.supplierid; To zapytanie generuje następujące dane wyjściowe z 1236 wierszami:
custid customer supplierid supplier ------- --------------- ----------- --------------- 1 Customer NRZBB 1 Supplier SWRXU 1 Customer NRZBB 3 Supplier STUAZ 1 Customer NRZBB 7 Supplier GQRCV ... 21 Customer KIDPX 24 Supplier JNNES 21 Customer KIDPX 25 Supplier ERVYZ 21 Customer KIDPX 28 Supplier OAVQT 23 Customer WVFAF 3 Supplier STUAZ 23 Customer WVFAF 7 Supplier GQRCV 23 Customer WVFAF 8 Supplier BWGYE ... 56 Customer QNIVZ 26 Supplier ZWZDM 56 Customer QNIVZ 28 Supplier OAVQT 56 Customer QNIVZ 29 Supplier OGLRK 58 Customer AHXHT 1 Supplier SWRXU 58 Customer AHXHT 5 Supplier EQPNC 58 Customer AHXHT 6 Supplier QWUSF ... (1236 rows affected)
Plan dla tego zapytania pokazano na rysunku 5.
 Rysunek 5:Plan dla zapytania 5
Rysunek 5:Plan dla zapytania 5
Wszystkie sprzężenia w planie są przetwarzane jako sprzężenia wewnętrzne, jak można się spodziewać.
Możesz również zaobserwować w planie, że optymalizator zastosował optymalizację kolejności łączenia. W przypadku złączeń wewnętrznych optymalizator wie, że może zmienić fizyczną kolejność złączeń w dowolny sposób, zachowując przy tym znaczenie oryginalnego zapytania, dzięki czemu ma dużą elastyczność. Tutaj jego optymalizacja oparta na kosztach zaowocowała zamówieniem:join(Klienci, join(Zamówienia, join(join(Dostawcy, Produkty), Szczegóły Zamówień))).
Załóżmy, że pojawia się wymóg zmiany zapytania tak, aby obejmowało klientów, którzy nie złożyli zamówień. Przypomnijmy, że obecnie mamy dwóch takich klientów (o identyfikatorach 22 i 57), więc pożądany wynik ma mieć 1238 wierszy. Częstym błędem w takim przypadku jest zmiana sprzężenia wewnętrznego między Klientami i Zamówieniami na lewe sprzężenie zewnętrzne, ale pozostawienie wszystkich pozostałych sprzężeń jako wewnętrznych, na przykład:
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid; Gdy po lewym sprzężeniu zewnętrznym następuje następnie sprzężenie wewnętrzne lub prawe zewnętrzne, a predykat sprzężenia porównuje coś z niezachowanej strony lewego sprzężenia zewnętrznego z jakimś innym elementem, wynikiem predykatu jest nieznana wartość logiczna, a oryginalny zewnętrzny wiersze są odrzucane. Lewe sprzężenie zewnętrzne w efekcie staje się sprzężeniem wewnętrznym.
W rezultacie to zapytanie generuje takie same dane wyjściowe jak dla zapytania 5, zwracając tylko 1236 wierszy. Również tutaj optymalizator wykrywa sprzeczność i przekształca sprzężenie zewnętrzne w sprzężenie wewnętrzne, generując taki sam plan, jak pokazano wcześniej na rysunku 5.
Częstą próbą naprawienia tego błędu jest pozostawienie wszystkich złączeń lewego złączenia zewnętrznego, na przykład:
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
LEFT OUTER JOIN Production.Products AS P
ON P.productid = OD.productid
LEFT OUTER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid; To zapytanie generuje następujące dane wyjściowe, które obejmują klientów 22 i 57:
custid customer supplierid supplier ------- --------------- ----------- --------------- 1 Customer NRZBB 1 Supplier SWRXU 1 Customer NRZBB 3 Supplier STUAZ 1 Customer NRZBB 7 Supplier GQRCV ... 21 Customer KIDPX 24 Supplier JNNES 21 Customer KIDPX 25 Supplier ERVYZ 21 Customer KIDPX 28 Supplier OAVQT 22 Customer DTDMN NULL NULL 23 Customer WVFAF 3 Supplier STUAZ 23 Customer WVFAF 7 Supplier GQRCV 23 Customer WVFAF 8 Supplier BWGYE ... 56 Customer QNIVZ 26 Supplier ZWZDM 56 Customer QNIVZ 28 Supplier OAVQT 56 Customer QNIVZ 29 Supplier OGLRK 57 Customer WVAXS NULL NULL 58 Customer AHXHT 1 Supplier SWRXU 58 Customer AHXHT 5 Supplier EQPNC 58 Customer AHXHT 6 Supplier QWUSF ... (1238 rows affected)
Z tym rozwiązaniem wiążą się jednak dwa problemy. Załóżmy, że oprócz Customers możesz mieć wiersze w innej tabeli w zapytaniu bez pasujących wierszy w kolejnej tabeli, i że w takim przypadku nie chcesz zachowywać tych zewnętrznych wierszy. Na przykład, co by było, gdyby w twoim środowisku można było stworzyć nagłówek dla zamówienia, a później wypełnić go liniami zamówienia. Załóżmy, że w takim przypadku zapytanie nie ma zwracać takich pustych nagłówków zamówień. Mimo to zapytanie ma zwracać klientów bez zamówień. Ponieważ sprzężenie między Orders i OrderDetails jest lewym sprzężeniem zewnętrznym, to zapytanie zwróci takie puste zamówienia, nawet jeśli nie powinno.
Innym problemem jest to, że podczas używania złączeń zewnętrznych nakładasz na optymalizator większe ograniczenia w zakresie rearanżacji, które może on badać w ramach optymalizacji kolejności złączeń. Optymalizator może zmienić rozmieszczenie złączenia A LEFT OUTER JOIN B na B RIGHT OUTER JOIN A, ale jest to właściwie jedyna zmiana, jaką może badać. W przypadku złączeń wewnętrznych optymalizator może również zmienić kolejność tabel poza odwracanie stron, na przykład może zmienić kolejność join(join(join(join(A, B), C), D), E)))) na join(A, join(B, join(join(E, D), C))), jak pokazano wcześniej na rysunku 5.
Jeśli się nad tym zastanowisz, to, czego naprawdę szukasz, to lewe dołączenie do Klientów z wynikiem wewnętrznych połączeń między resztą tabel. Oczywiście możesz to osiągnąć za pomocą wyrażeń tabelowych. Jednak T-SQL obsługuje inną sztuczkę. Tym, co naprawdę decyduje o kolejności łączenia logicznego, nie jest dokładnie kolejność tabel w klauzuli FROM, a raczej kolejność klauzul ON. Jednak, aby zapytanie było poprawne, każda klauzula ON musi znajdować się tuż pod dwiema jednostkami, do których się łączy. Aby więc uznać łączenie Klientów z resztą za ostatnie, wystarczy przenieść klauzulę ON, która łączy Klientów z resztą jako ostatnią, na przykład:
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
-- move from here -----------------------
INNER JOIN Sales.OrderDetails AS OD --
ON OD.orderid = O.orderid --
INNER JOIN Production.Products AS P --
ON P.productid = OD.productid --
INNER JOIN Production.Suppliers AS S --
ON S.supplierid = P.supplierid --
ON O.custid = C.custid; -- <-- to here -- Teraz kolejność łączenia logicznego to:leftjoin(Klienci, join(join(join(Orders, OrderDetails), Products), Suppliers)). Tym razem zatrzymasz klientów, którzy nie złożyli zamówień, ale nie zachowasz nagłówków zamówień, które nie mają pasujących wierszy zamówienia. Ponadto umożliwiasz optymalizatorowi pełną elastyczność porządkowania złączeń w wewnętrznych złączach między zamówieniami, szczegółami zamówienia, produktami i dostawcami.
Jedyną wadą tej składni jest czytelność. Dobrą wiadomością jest to, że można to łatwo naprawić, używając nawiasów, tak jak to (nazwij to zapytanie 6):
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN
( Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid )
ON O.custid = C.custid; Nie pomyl użycia nawiasów w tym miejscu z tabelą pochodną. Nie jest to tabela pochodna, a raczej sposób na oddzielenie niektórych operatorów tabeli do ich własnej jednostki dla jasności. Język tak naprawdę nie potrzebuje tych nawiasów, ale są one zdecydowanie zalecane ze względu na czytelność.
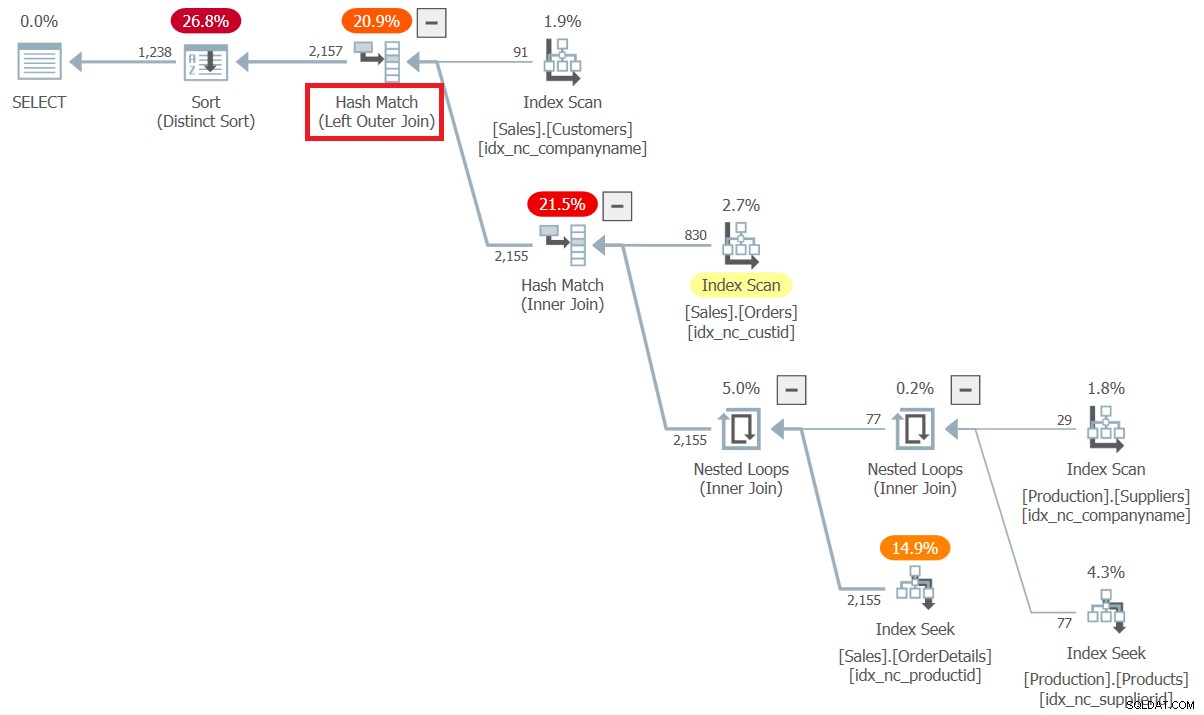
Plan dla tego zapytania pokazano na rysunku 6.
 Rysunek 6:Plan dla zapytania 6
Rysunek 6:Plan dla zapytania 6
Zauważ, że tym razem połączenie między Klientami a resztą jest przetwarzane jako połączenie zewnętrzne i że optymalizator zastosował optymalizację kolejności łączenia.
Wniosek
W tym artykule omówiłem cztery klasyczne błędy związane z łączeniami. When using outer joins, computing the COUNT(*) aggregate typically results in a bug. The best practice is to apply the aggregate to a non-NULLable column from the nonpreserved side of the join.
When joining multiple tables and involving aggregate calculations, if you apply the aggregates to a nonleaf table in the joins, it’s usually a bug resulting in double-dipping aggregates. The best practice is then to apply the aggregates within table expressions and joining the table expressions.
It’s common to confuse the meanings of the ON and WHERE clauses. With inner joins, they’re both filters, so it doesn’t really matter how you organize your predicates within these clauses. However, with outer joins the ON clause serves a matching role whereas the WHERE clause serves a filtering role. Understanding this helps you figure out how to organize your predicates within these clauses.
In multi-join queries, a left outer join that is subsequently followed by an inner join, or a right outer join, where you compare an element from the nonpreserved side of the join with others (other than the IS NULL test), the outer rows of the left outer join are discarded. To avoid this bug, you want to apply the left outer join last, and this can be achieved by shifting the ON clause that connects the preserved side of this join with the rest to appear last. Use parentheses for clarity even though they are not required.



