Zarządzanie ruchem do bazy danych może być coraz trudniejsze w miarę wzrostu ilości, a baza danych jest w rzeczywistości rozproszona na wielu serwerach. Klienci PostgreSQL zwykle komunikują się z jednym punktem końcowym. Gdy węzeł podstawowy ulegnie awarii, klienci bazy danych będą nadal próbować tego samego adresu IP. W przypadku awaryjnego przełączenia na węzeł pomocniczy aplikacja musi zostać zaktualizowana o nowy punkt końcowy. W tym miejscu chciałbyś umieścić load balancer między aplikacjami a instancjami bazy danych. Może kierować aplikacje do dostępnych/zdrowych węzłów bazy danych i w razie potrzeby przełączać się w tryb awaryjny. Inną korzyścią byłoby zwiększenie wydajności odczytu dzięki efektywnemu wykorzystaniu replik. Możliwe jest utworzenie portu tylko do odczytu, który równoważy odczyty w replikach. W tym blogu omówimy HAProxy. Zobaczymy, co jest, jak działa i jak wdrożyć go w PostgreSQL.
Co to jest HAProxy?
HAProxy to serwer proxy typu open source, którego można użyć do wdrożenia wysokiej dostępności, równoważenia obciążenia i proxy dla aplikacji opartych na protokole TCP i HTTP.
Jako moduł równoważenia obciążenia, HAProxy dystrybuuje ruch z jednego źródła do jednego lub więcej miejsc docelowych i może zdefiniować określone reguły i/lub protokoły dla tego zadania. Jeśli którykolwiek z miejsc docelowych przestanie odpowiadać, jest oznaczany jako offline, a ruch jest przesyłany do pozostałych dostępnych miejsc docelowych.
Jak ręcznie zainstalować i skonfigurować HAProxy
Aby zainstalować HAProxy w systemie Linux, możesz użyć następujących poleceń:
W systemie operacyjnym Ubuntu/Debian:
$ apt-get install haproxy -yW systemie operacyjnym CentOS/RedHat:
$ yum install haproxy -yNastępnie musimy edytować następujący plik konfiguracyjny, aby zarządzać naszą konfiguracją HAProxy:
$ /etc/haproxy/haproxy.cfgKonfiguracja naszego HAProxy nie jest skomplikowana, ale musimy wiedzieć, co robimy. Mamy do skonfigurowania kilka parametrów, w zależności od tego, jak chcemy, aby HAProxy działał. Aby uzyskać więcej informacji, możemy zapoznać się z dokumentacją dotyczącą konfiguracji HAProxy.
Spójrzmy na przykład podstawowej konfiguracji. Załóżmy, że masz następującą topologię bazy danych:
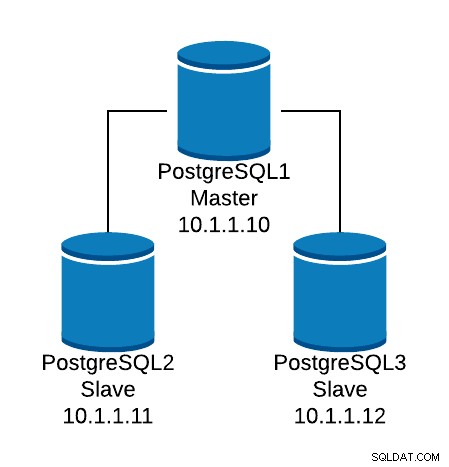 Przykład topologii bazy danych
Przykład topologii bazy danych Chcemy stworzyć odbiornik HAProxy, aby zrównoważyć ruch odczytu między trzema węzłami.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkJak wspomnieliśmy wcześniej, jest tutaj kilka parametrów do skonfigurowania, a ta konfiguracja zależy od tego, co chcemy zrobić. Na przykład:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkJak HAProxy działa w ClusterControl
W przypadku PostgreSQL, HAProxy jest konfigurowane przez ClusterControl z dwoma różnymi portami domyślnie, jednym do odczytu-zapisu i jednym tylko do odczytu.
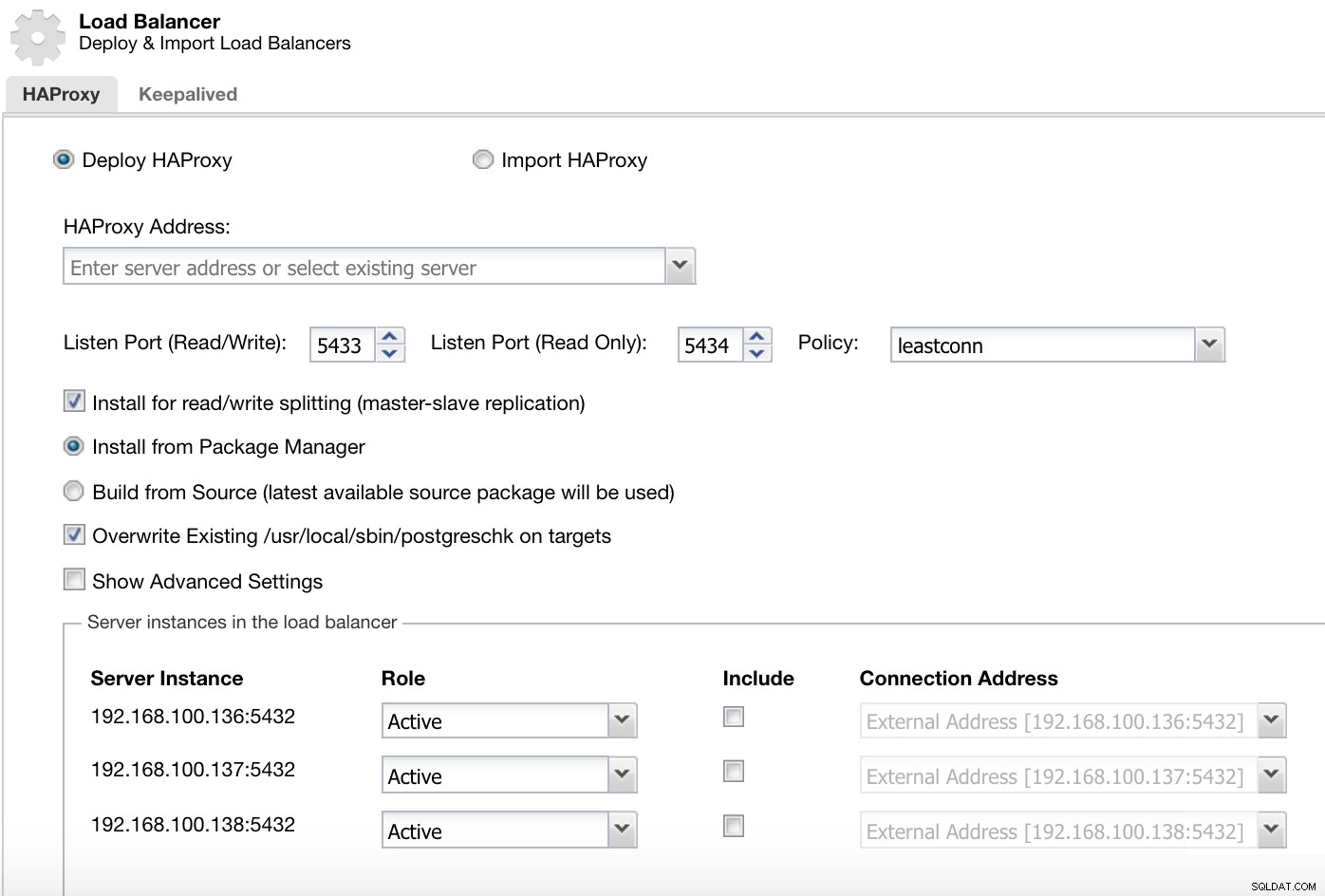 Informacje o wdrożeniu modułu równoważenia obciążenia ClusterControl 1
Informacje o wdrożeniu modułu równoważenia obciążenia ClusterControl 1 W naszym porcie do odczytu i zapisu nasz serwer główny jest w trybie online, a reszta naszych węzłów jest w trybie offline, a na porcie tylko do odczytu mamy zarówno serwer główny, jak i urządzenia podrzędne w trybie online.
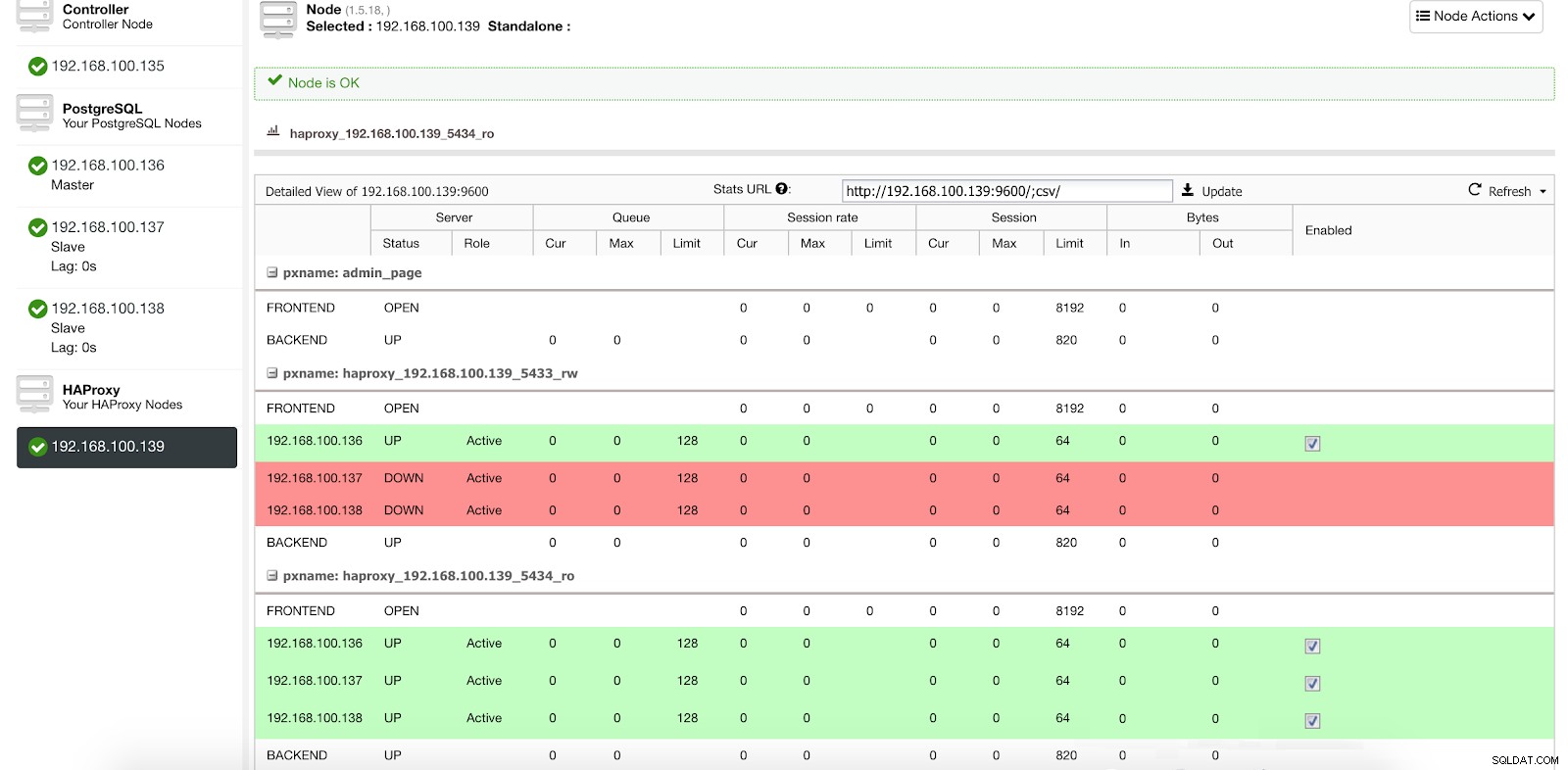 ClusterControl Statystyki równoważenia obciążenia 1
ClusterControl Statystyki równoważenia obciążenia 1 Gdy HAProxy wykryje, że jeden z naszych węzłów, master lub slave, jest niedostępny, automatycznie oznacza go jako offline i nie bierze go pod uwagę podczas wysyłania ruchu. Wykrywanie odbywa się za pomocą skryptów sprawdzania kondycji, które są konfigurowane przez ClusterControl w czasie wdrażania. Sprawdzają one, czy instancje działają, czy są w trakcie odzyskiwania, czy są tylko do odczytu.
Kiedy ClusterControl promuje slave'a do mastera, nasz HAProxy oznacza stary master jako offline (dla obu portów) i umieszcza promowany węzeł online (w porcie do odczytu i zapisu).
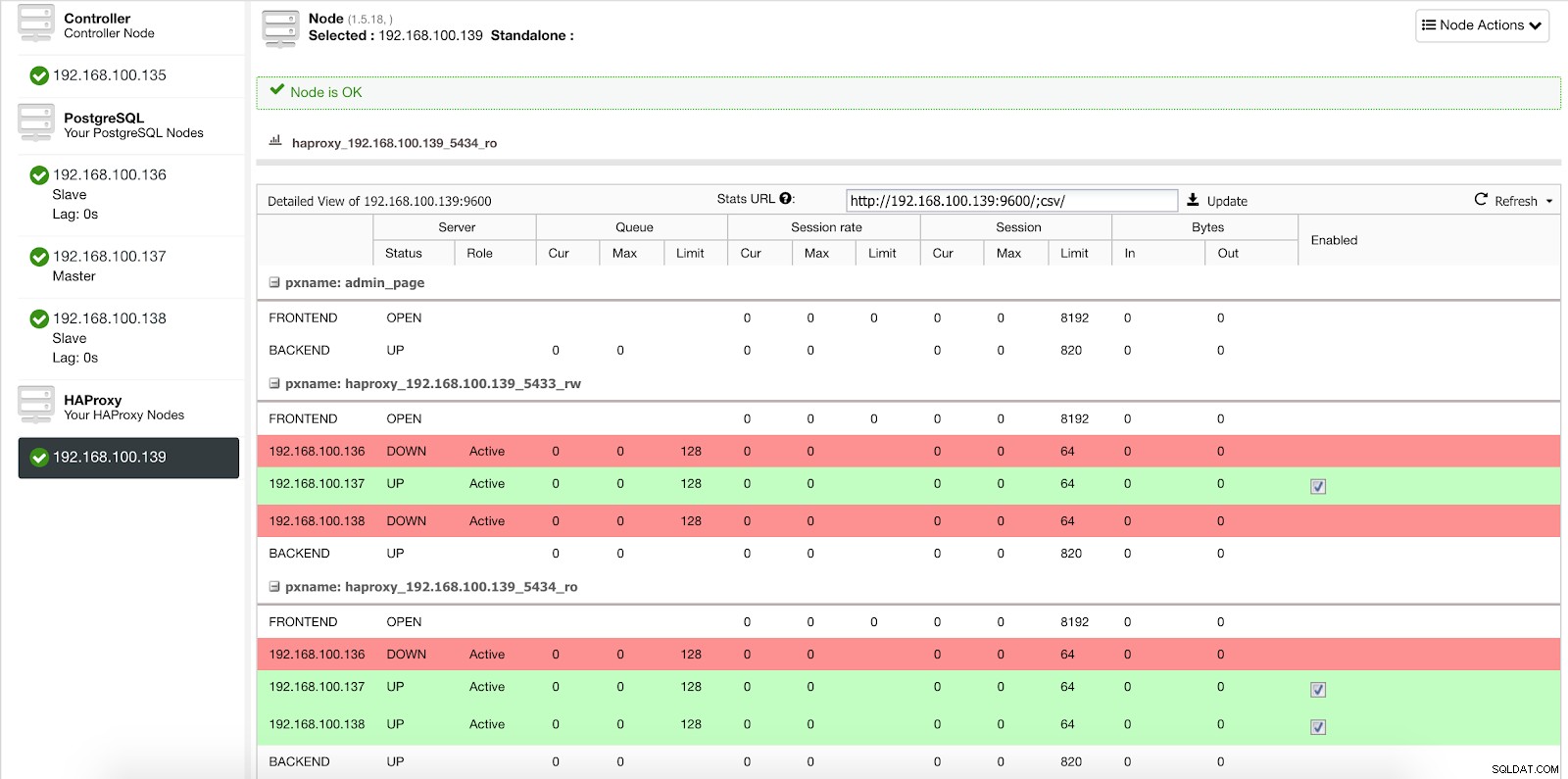 ClusterControl Statystyki równoważenia obciążenia 2
ClusterControl Statystyki równoważenia obciążenia 2 W ten sposób nasze systemy działają normalnie i bez naszej interwencji.
Jak wdrożyć HAProxy z ClusterControl
W naszym przykładzie stworzyliśmy środowisko z 1 urządzeniem głównym i 2 urządzeniami podrzędnymi — zobacz zrzut ekranu widoku topologii w ClusterControl. Dodamy teraz nasz system równoważenia obciążenia HAProxy.
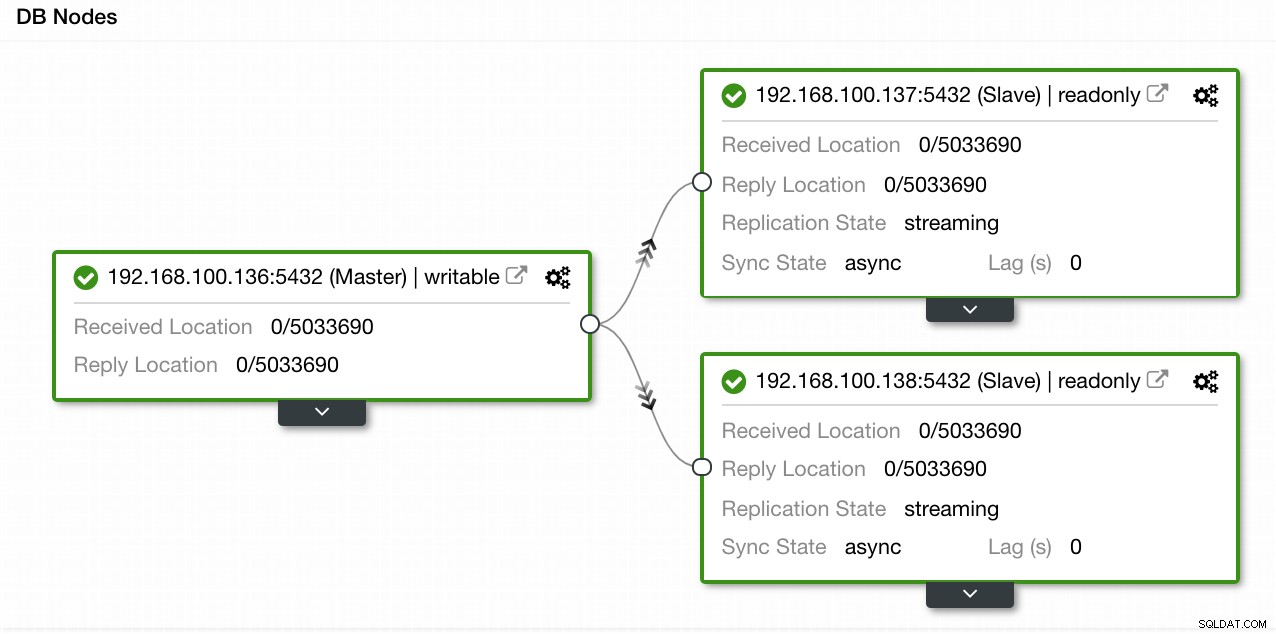 ClusterControl Topology View 1
ClusterControl Topology View 1 W tym celu musimy przejść do ClusterControl -> PostgreSQL Cluster Actions -> Add Load Balancer
 ClusterControl Cluster Actions Menu
ClusterControl Cluster Actions Menu Tutaj musimy dodać informacje, których ClusterControl użyje do zainstalowania i skonfigurowania naszego modułu równoważenia obciążenia HAProxy.
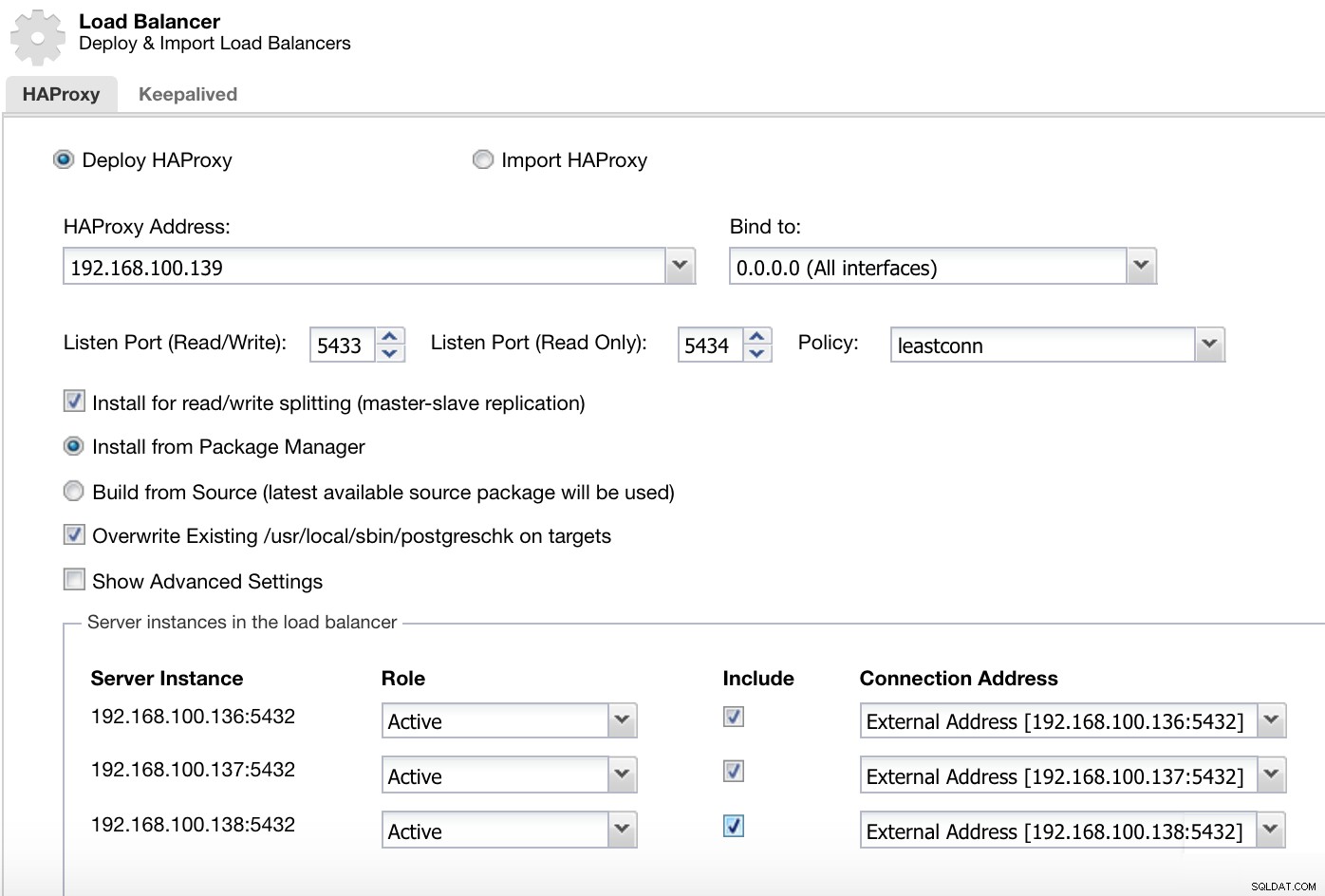 Informacje o wdrożeniu modułu równoważenia obciążenia ClusterControl 2
Informacje o wdrożeniu modułu równoważenia obciążenia ClusterControl 2 Informacje, które musimy wprowadzić to:
Akcja:Wdróż lub Importuj.
Adres HAProxy:Adres IP naszego serwera HAProxy.
Bind to:Interfejs lub adres IP, na którym HAProxy będzie nasłuchiwać.
Port nasłuchiwania (odczyt/zapis):port dla trybu odczytu/zapisu.
Port nasłuchiwania (tylko do odczytu):Port w trybie tylko do odczytu.
Zasady:Może to być:
- leastconn:serwer z najmniejszą liczbą połączeń odbiera połączenie.
- roundrobin:każdy serwer jest używany po kolei, zgodnie z ich wagą.
- źródło:źródłowy adres IP jest haszowany i dzielony przez całkowitą wagę działających serwerów, aby określić, który serwer otrzyma żądanie.
Zainstaluj w celu dzielenia odczytu/zapisu:Do replikacji master-slave.
Źródło:możemy wybrać opcję Instaluj z menedżera pakietów lub kompilację ze źródła.
Zastąp istniejący postgreschk w celach.
I musimy wybrać serwery, które chcesz dodać do konfiguracji HAProxy i kilka dodatkowych informacji, takich jak:
Rola:Może być Aktywna lub Kopia zapasowa.
Uwzględnij:Tak lub Nie.
Informacje o adresie połączenia.
Ponadto możemy skonfigurować ustawienia zaawansowane, takie jak użytkownik administratora, nazwa zaplecza, limity czasu i inne.
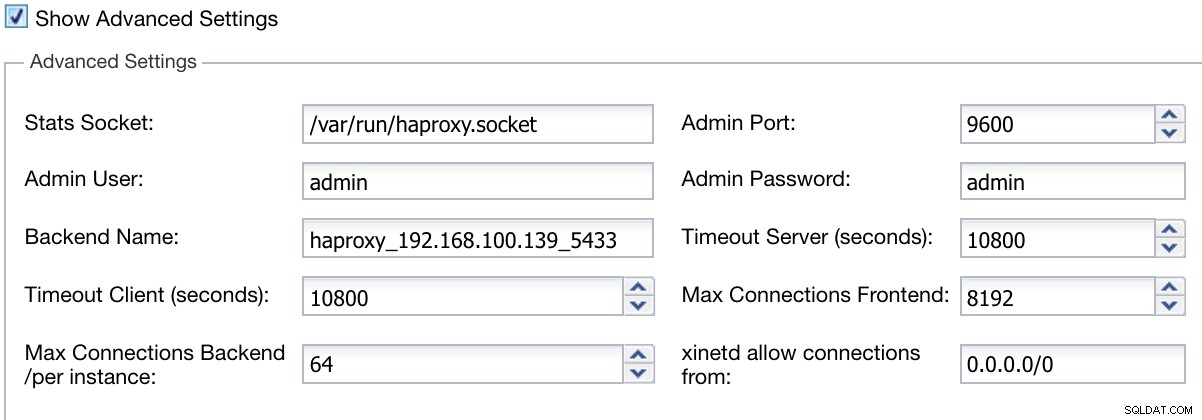 Zaawansowane informacje dotyczące wdrażania modułu równoważenia obciążenia ClusterControl
Zaawansowane informacje dotyczące wdrażania modułu równoważenia obciążenia ClusterControl Po zakończeniu konfiguracji i potwierdzeniu wdrożenia możemy śledzić postęp w sekcji Aktywność w interfejsie użytkownika ClusterControl.
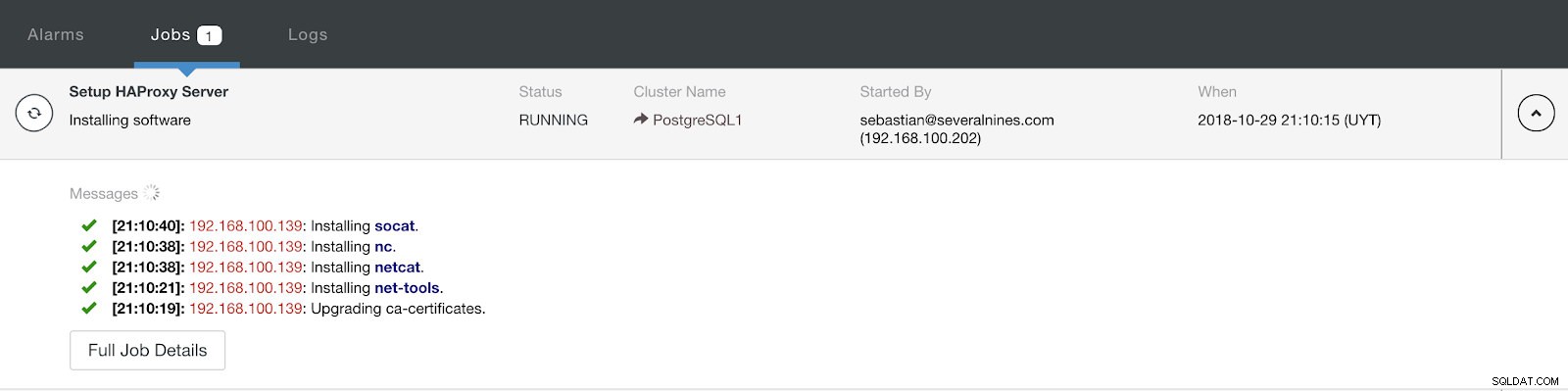 Sekcja aktywności ClusterControl
Sekcja aktywności ClusterControl Po zakończeniu powinniśmy mieć następującą topologię:
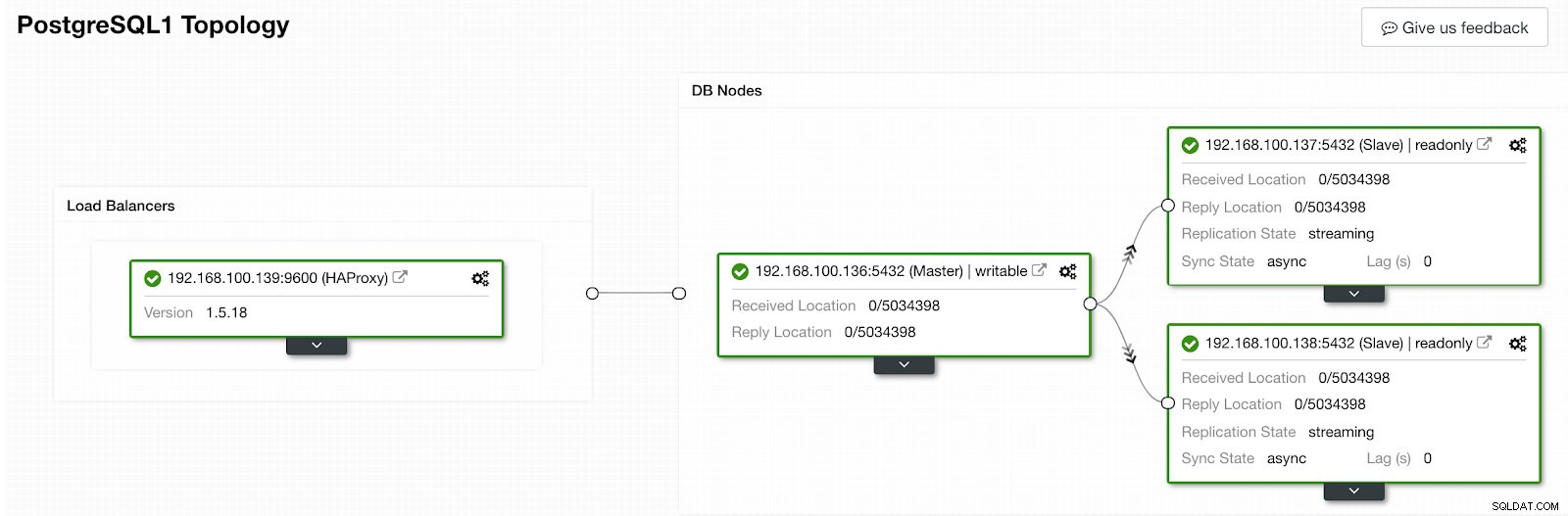 ClusterControl Topology View 2
ClusterControl Topology View 2 Możemy ulepszyć nasz projekt HA, dodając nowy węzeł HAProxy i konfigurując między nimi usługę Keepalved. Wszystko to może być wykonane przez ClusterControl. Więcej informacji można znaleźć w naszym poprzednim blogu o PostgreSQL i HA.
Używanie ClusterControl CLI do dodawania równoważnika obciążenia HAProxy
Ten opcjonalny pakiet, znany również jako s9s-tools, został wprowadzony w ClusterControl w wersji 1.4.1, który zawiera plik binarny o nazwie s9s. Jest to narzędzie wiersza poleceń do interakcji, kontroli i zarządzania infrastrukturą bazy danych za pomocą ClusterControl. Projekt wiersza poleceń s9s jest open source i można go znaleźć na GitHub.
Począwszy od wersji 1.4.1, skrypt instalacyjny automatycznie zainstaluje pakiet (s9s-tools) w węźle ClusterControl.
ClusterControl CLI otwiera nowe drzwi do automatyzacji klastra, gdzie można go łatwo zintegrować z istniejącymi narzędziami do automatyzacji wdrażania, takimi jak Ansible, Puppet, Chef lub Salt.
Spójrzmy na przykład, jak utworzyć równoważnik obciążenia HAProxy z adresem IP 192.168.100.142 na identyfikatorze klastra 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.A potem możemy sprawdzić wszystkie nasze węzły z wiersza poleceń:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Aby uzyskać więcej informacji na temat s9s i tego, jak z niego korzystać, możesz sprawdzić oficjalną dokumentację lub to, jak blogować na ten temat.
Wniosek
W tym blogu omówiliśmy, w jaki sposób HAProxy może nam pomóc w zarządzaniu ruchem przychodzącym z aplikacji do naszej bazy danych PostgreSQL. Sprawdziliśmy, jak można go ręcznie wdrożyć i skonfigurować, a następnie zobaczyliśmy, jak można go zautomatyzować za pomocą ClusterControl. Aby uniknąć sytuacji, w której HAProxy stanie się pojedynczym punktem awarii (SPOF), upewnij się, że wdrażasz co najmniej dwie instancje HAProxy i zaimplementuj na nich coś w rodzaju Keepalived i Virtual IP.