W planie odzyskiwania po awarii, Twój Cel Punktu Odzyskiwania (RPO) jest kluczowym parametrem odzyskiwania, który określa, ile danych możesz utracić. RPO jest podany w czasie, od sekund do dni. W rzeczywistości RPO jest bezpośrednio zależne od systemu tworzenia kopii zapasowych. Oznacza wiek danych kopii zapasowej, które należy odzyskać, aby wznowić normalne działanie.
Jeśli robisz conocną kopię zapasową o 22:00 a system bazy danych ulega awarii nie do naprawienia o godzinie 15:00. następnego dnia tracisz wszystko, co zostało zmienione od czasu ostatniej kopii zapasowej. Twoje RPO w tym konkretnym kontekście to kopia zapasowa z poprzedniego dnia, co oznacza, że możesz sobie pozwolić na utratę jednodniowych zmian.
Poniższy diagram z naszego raportu na temat odzyskiwania po awarii ilustruje tę koncepcję.
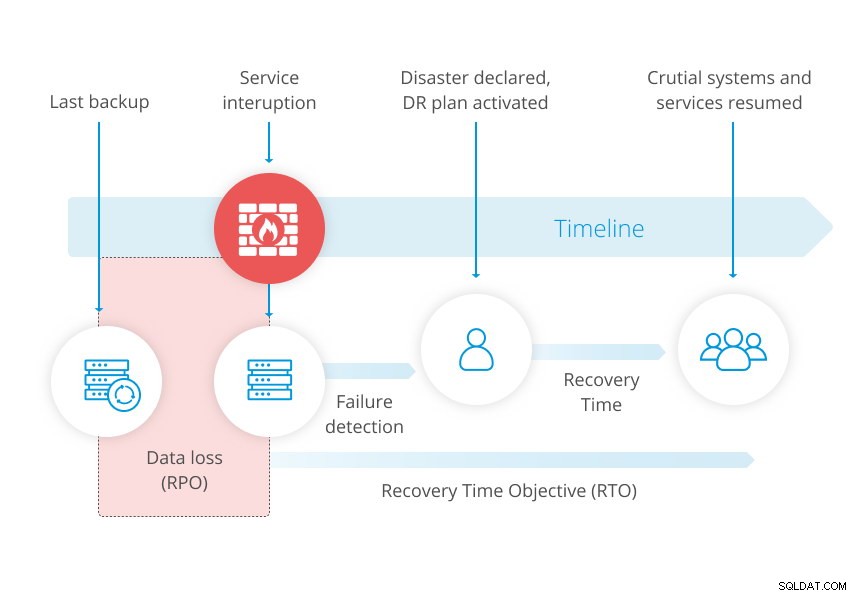
W przypadku ściślejszego RPO kopia zapasowa może jednak nie wystarczyć. Tworząc kopię zapasową bazy danych, w danym momencie robisz migawkę danych. Więc kiedy przywracasz kopię zapasową, przegapisz zmiany, które zaszły między ostatnią kopią zapasową a awarią.
W tym miejscu pojawia się koncepcja odzyskiwania punktu w czasie (PITR).
Co to jest PITR?
Odzyskiwanie punktu w czasie (PITR), jak sama nazwa wskazuje, polega na przywracaniu bazy danych w dowolnym momencie w przeszłości. Aby móc to zrobić, będziemy musieli przywrócić kopię zapasową, a następnie zastosować wszystkie zmiany, które nastąpiły po utworzeniu kopii zapasowej, aż do momentu tuż przed awarią.
W przypadku PostgreSQL zmiany są przechowywane w dziennikach WAL (więcej informacji o warstwach WAL i przechowywanych przez nie danych można znaleźć na tym blogu).
Są więc dwie rzeczy, które musimy zapewnić, aby móc wykonać PITR:kopie zapasowe i WAL (musimy skonfigurować dla nich ciągłą archiwizację).
Aby wykonać PITR, będziemy musieli odzyskać kopię zapasową, a następnie zastosować WAL.
Kiedy to może być przydatne?
Możesz użyć tej strategii za każdym razem, gdy przywracasz dane po problemie, który spowodował uszkodzenie danych. Musisz pamiętać, że starasz się zminimalizować utratę danych, ale istnieją pewne problemy, które mogą spowodować, że dane po tym przestaną być przydatne.
Przykładami tego mogą być nieplanowane modyfikacje danych (DML lub DDL), awarie nośników lub konserwacja bazy danych (np. aktualizacje), które prowadzą do uszkodzenia danych. Nie będziesz w stanie odzyskać zmian danych, które nastąpiły po problemie.
Załóżmy, że użytkownik niewłaściwie wykonał DML, przez co dane całej tabeli zostały błędnie zmienione lub usunięte. Możesz wykonać PITR bazy danych w osobnej lokalizacji, a następnie wyeksportować zawartość tabeli. Następnie możesz przywrócić tę tabelę do istniejącej bazy danych, skutecznie przywracając kopię stanu tabeli przed wystąpieniem problemu.
Oczywiście nie zawsze jest możliwe przywrócenie w ten sposób tylko części bazy danych, więc w takim przypadku konieczne będzie przywrócenie całej bazy danych do danego punktu, co spowoduje minimalną, ale nieuniknioną utratę danych (przeoczysz wszelkie zmiany, które nastąpiły po wystąpieniu problemu).
Jak korzystać z ClusterControl?
W poprzednim blogu mogliśmy zobaczyć, jak ręcznie zaimplementować PITR, teraz zobaczmy, jak użyć ClusterControl do wykonania tego zadania.
Włączanie odzyskiwania do punktu w czasie
Aby włączyć funkcję PITR, musimy mieć włączoną archiwizację WAL. W tym celu możemy przejść do ClusterControl -> Wybierz Klaster PostgreSQL -> Akcje węzłów -> Włącz archiwizację WAL lub po prostu przejść do ClusterControl -> Wybierz Klaster PostgreSQL -> Kopia zapasowa -> Ustawienia i włączyć opcję „Włącz odzyskiwanie do określonego punktu w czasie (Archiwizacja WAL)”, jak zobaczymy na poniższym obrazku.
Musimy pamiętać, że aby włączyć Archiwizację WAL, musimy zrestartować naszą bazę danych. ClusterControl może to zrobić również za nas.
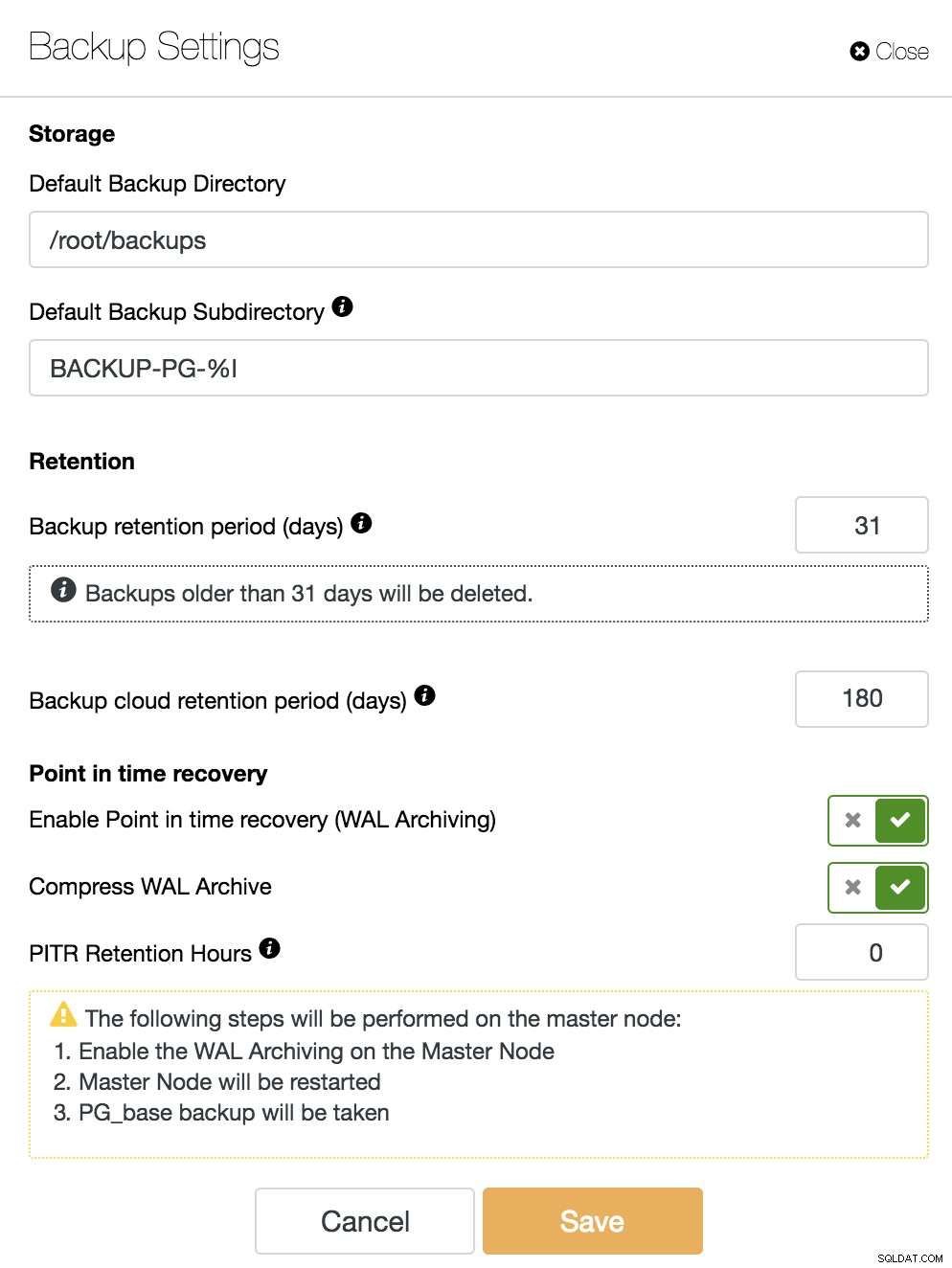
Oprócz opcji wspólnych dla wszystkich kopii zapasowych, takich jak „Katalog kopii zapasowych” i „Okres przechowywania kopii zapasowych”, tutaj możemy również określić okres przechowywania WAL. Domyślnie jest to 0, co oznacza na zawsze.
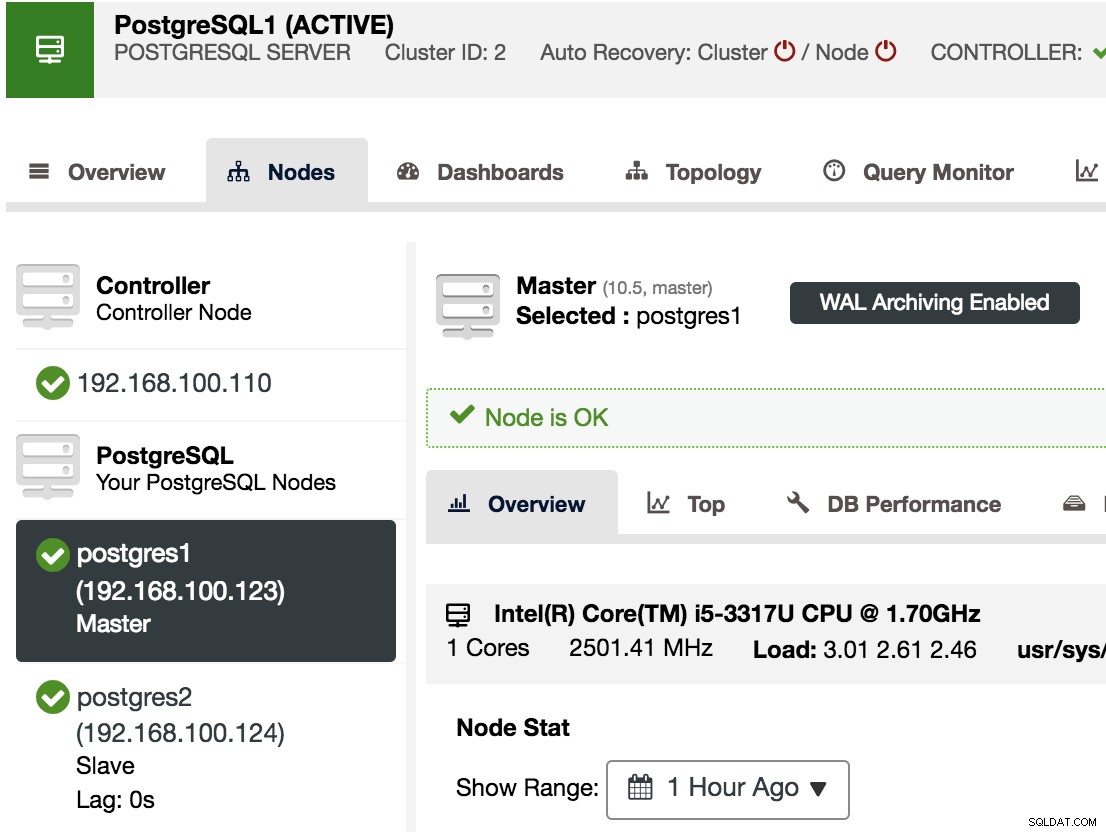
Aby potwierdzić, że mamy włączoną archiwizację WAL, możemy wybrać nasz węzeł główny w ClusterControl -> Wybierz klaster PostgreSQL -> Węzły i powinniśmy zobaczyć komunikat WAL Archiwizacja włączona, jak widać na poniższym obrazku.
Tworzenie kopii zapasowej zgodnej z odzyskiwaniem punktu w czasie
Mając włączoną archiwizację WAL, jak widzieliśmy w poprzednim kroku, możemy stworzyć naszą kopię zapasową zgodną z PITR. W tym celu przejdź do ClusterControl -> Wybierz Klaster PostgreSQL -> Kopia zapasowa -> Utwórz kopię zapasową.
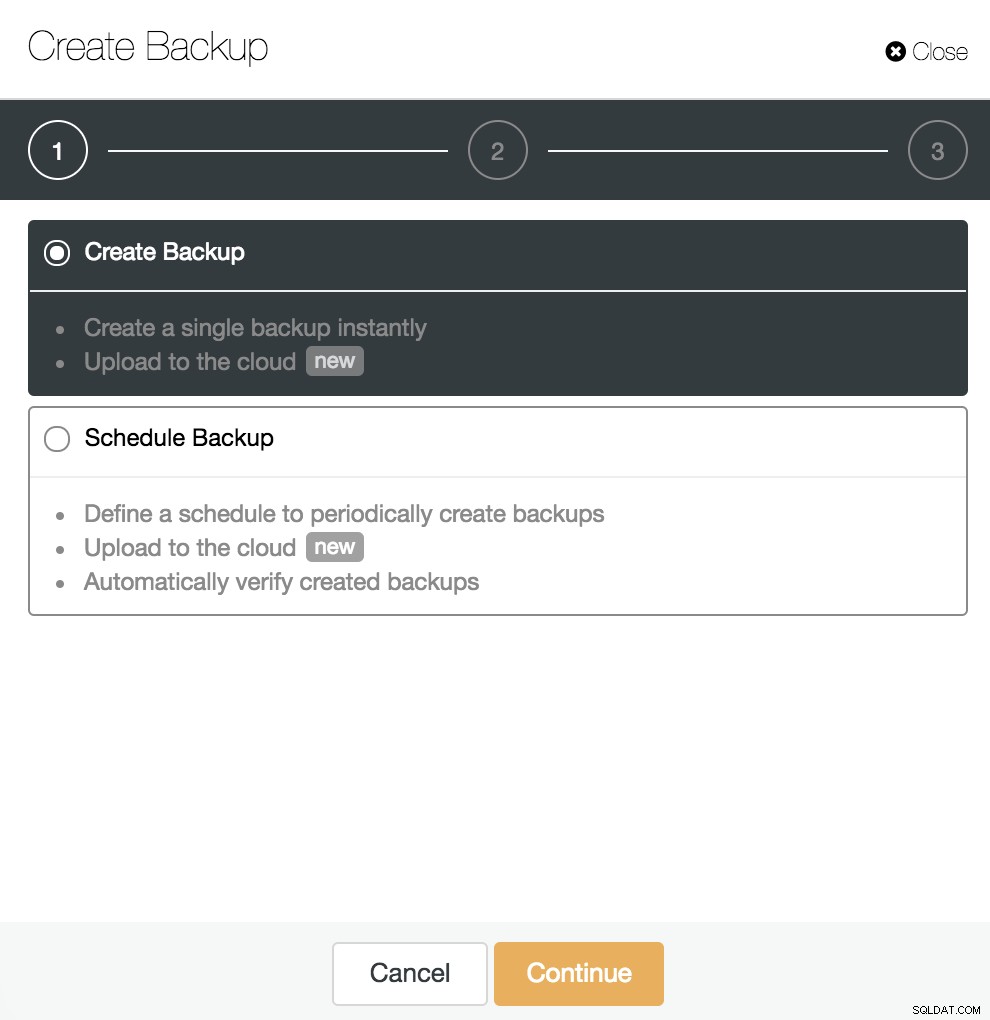
Możemy stworzyć nową kopię zapasową lub skonfigurować zaplanowaną. W naszym przykładzie natychmiast utworzymy pojedynczą kopię zapasową.
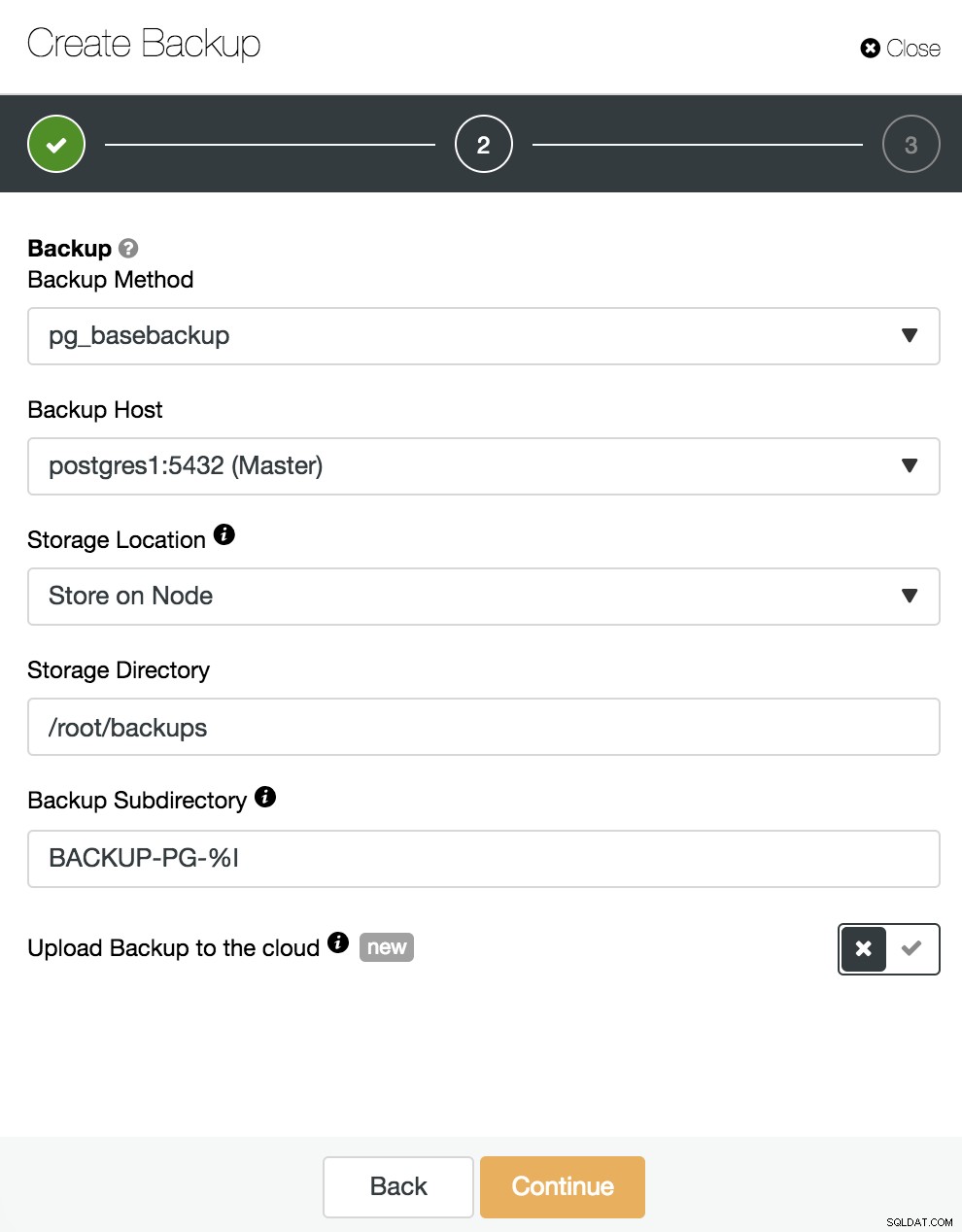
Tutaj musimy wybrać metodę „pg_basebackup”, zgodną z PITR, serwer, z którego zostanie pobrana kopia zapasowa (aby była kompatybilna z PITR, musi to być master), oraz gdzie chcemy przechowywać kopię zapasową. Możemy również przesłać naszą kopię zapasową do chmury (AWS, Google lub Azure), włączając odpowiedni przycisk.
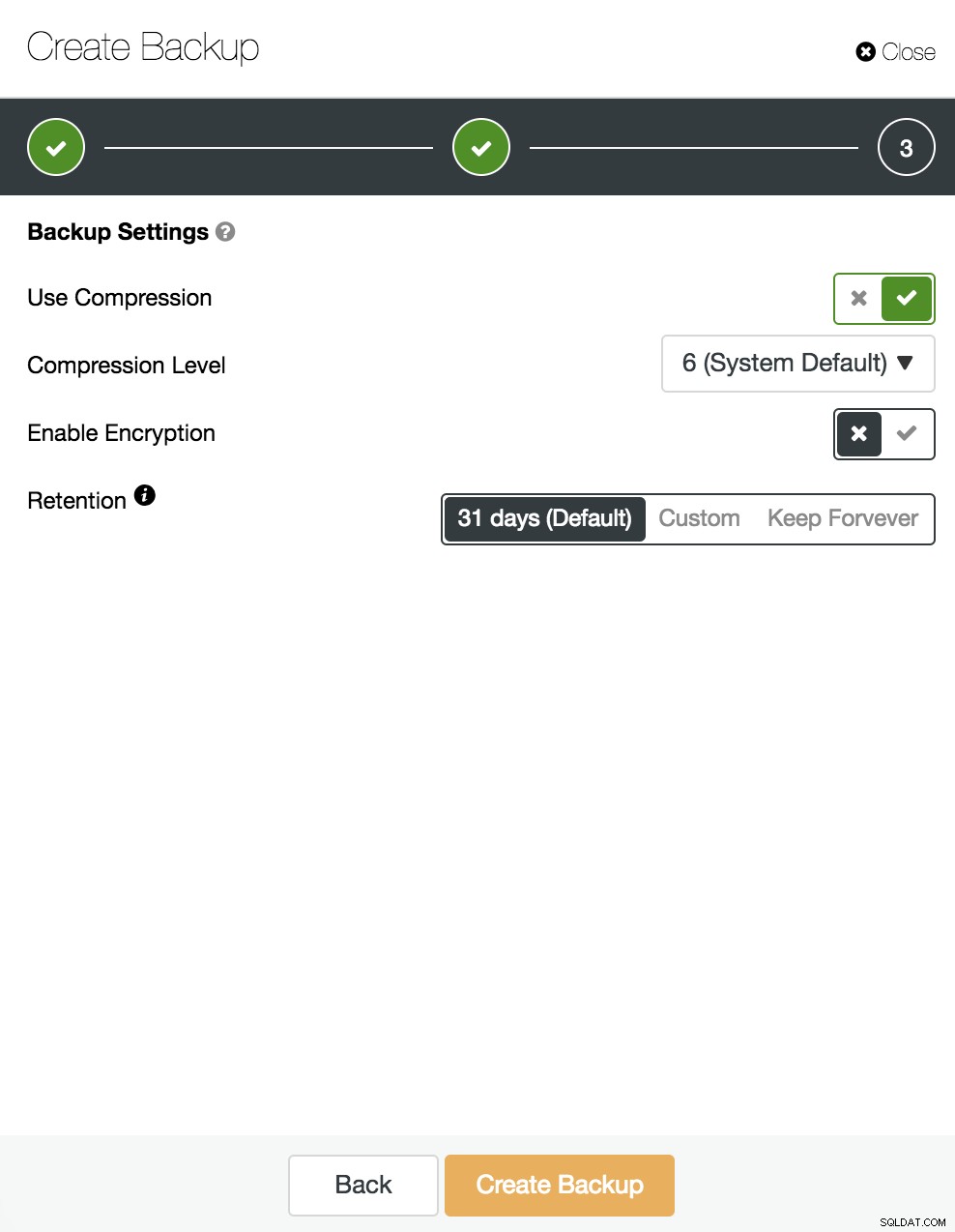
Następnie określamy użycie kompresji, szyfrowania i przechowywania naszej kopii zapasowej.
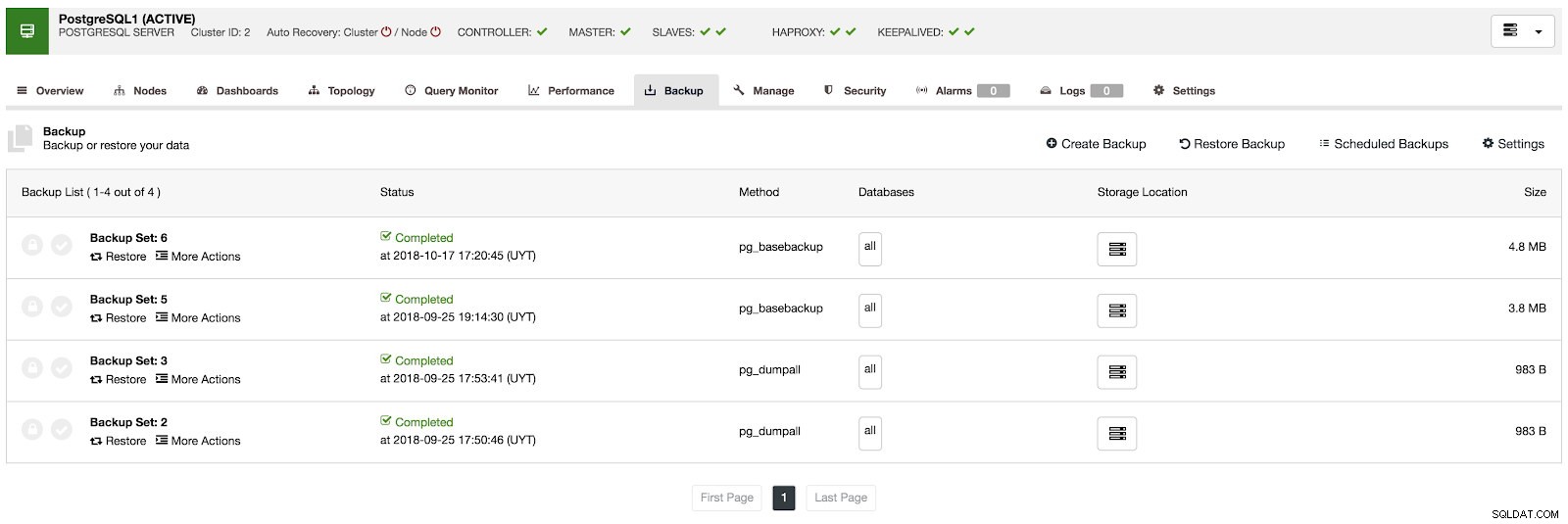
W sekcji kopii zapasowej możemy zobaczyć postęp tworzenia kopii zapasowej oraz informacje, takie jak metoda, rozmiar, lokalizacja i inne.
Odzyskiwanie punktu w czasie z kopii zapasowej
Po zakończeniu tworzenia kopii zapasowej możemy ją przywrócić za pomocą funkcji ClusterControl PITR. W tym celu w naszej sekcji kopii zapasowej (ClusterControl -> Wybierz PostgreSQL Cluster -> Backup) możemy wybrać „Przywróć kopię zapasową” lub bezpośrednio „Przywróć” na kopii zapasowej, którą chcemy przywrócić.
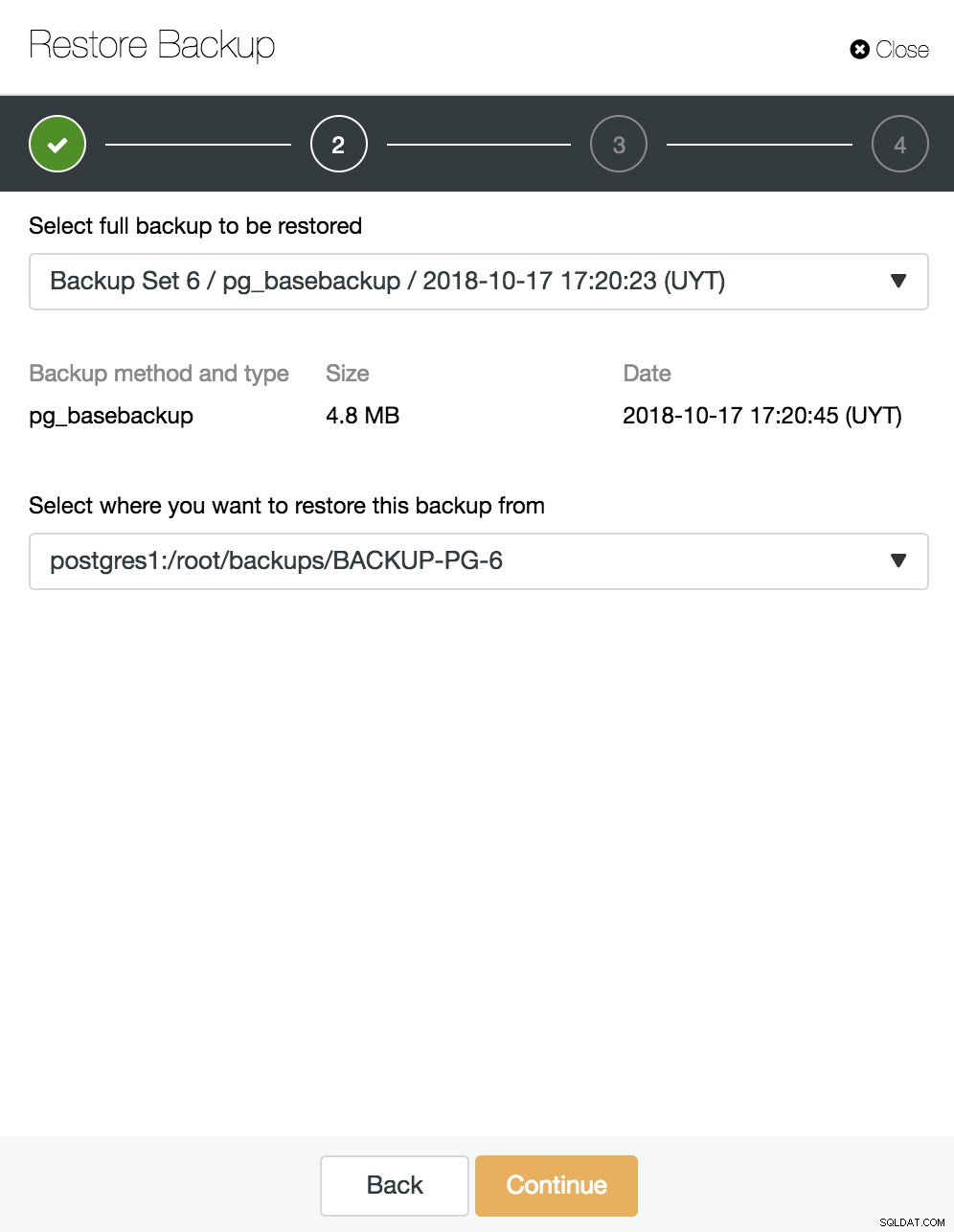
Tutaj wybieramy, którą kopię zapasową chcemy przywrócić iz którego katalogu.
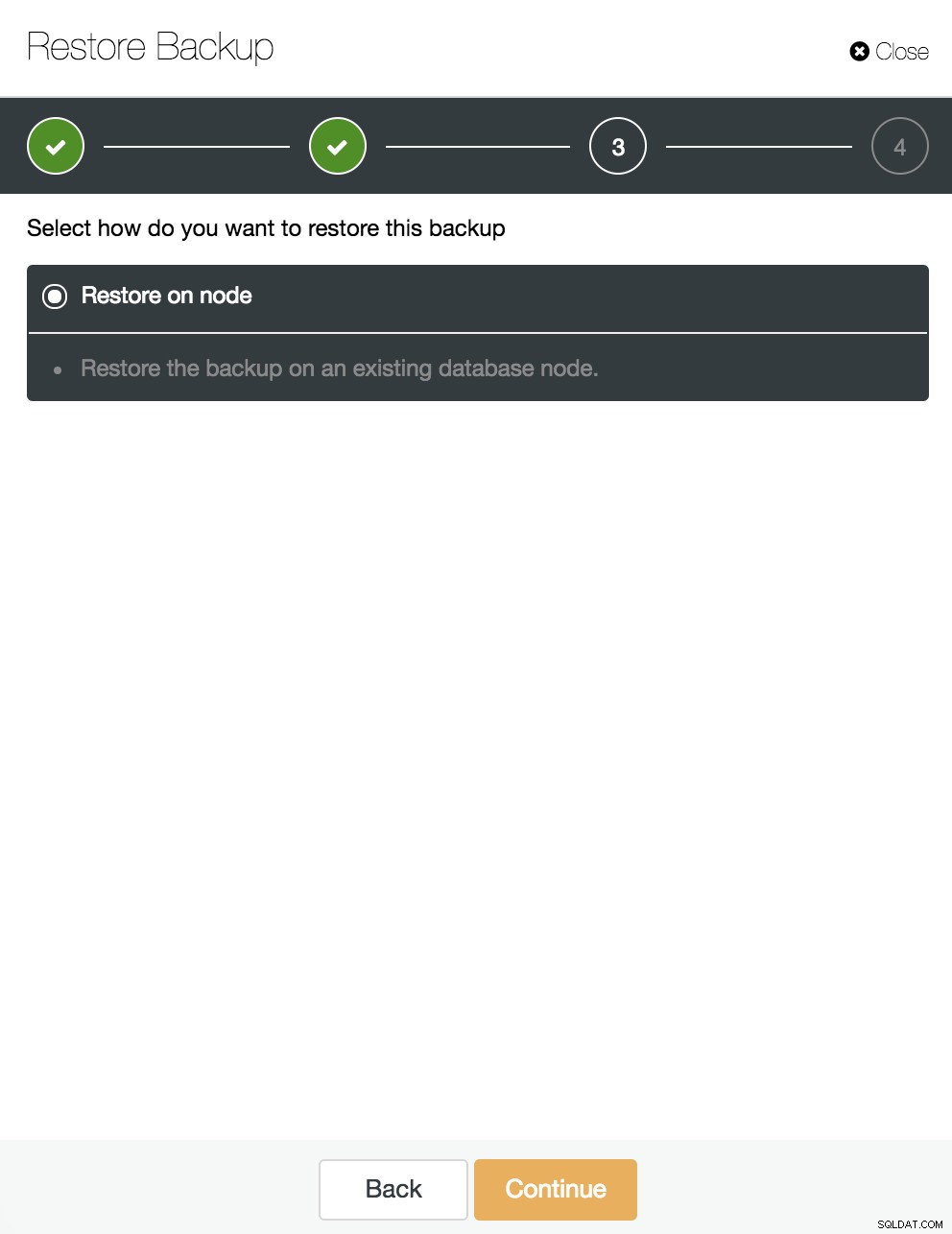
Pozostawiamy zaznaczoną opcję „Przywróć w węźle” i kontynuuj.
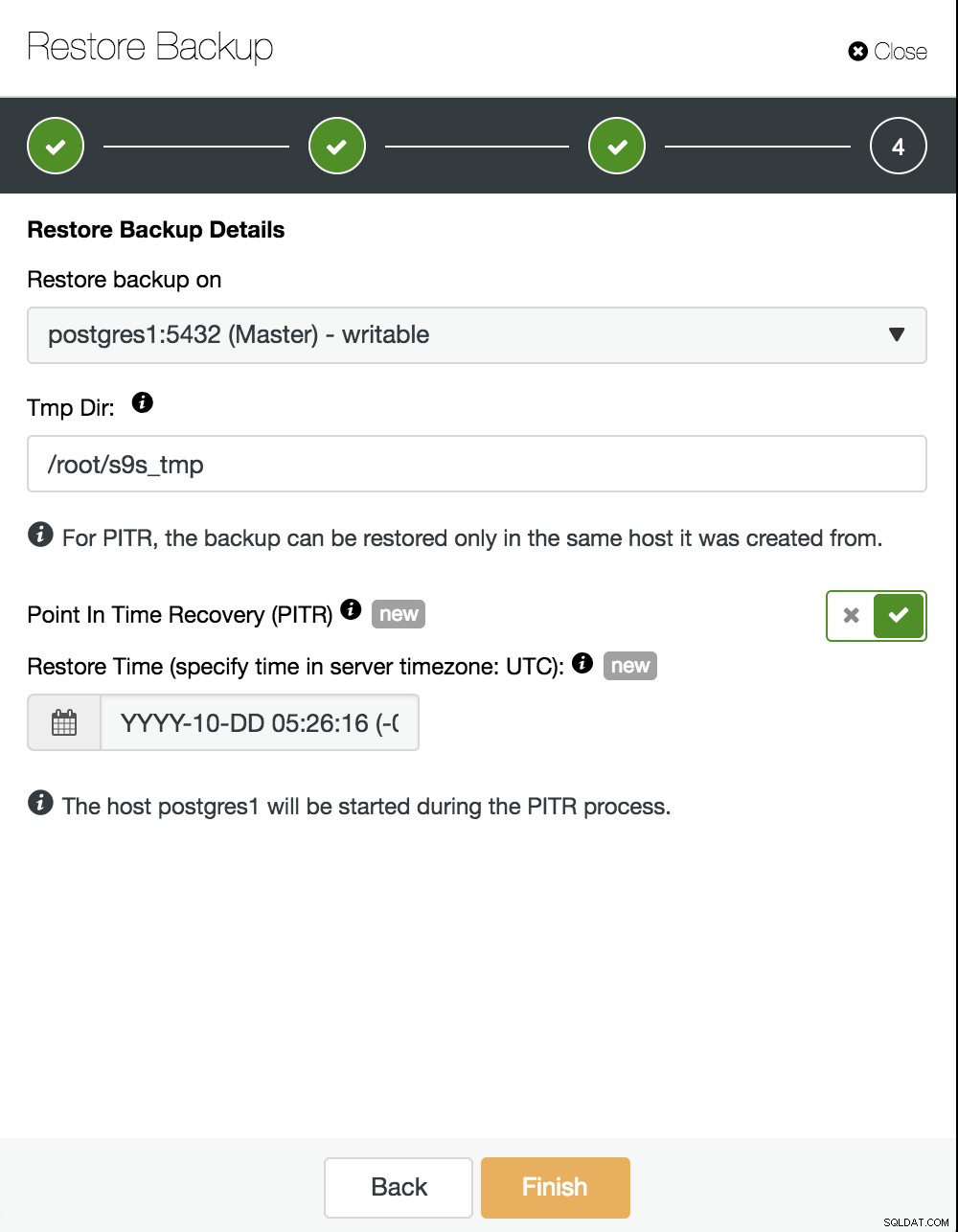
Teraz musimy wybrać, gdzie przywrócić naszą kopię zapasową i włączyć opcję PITR. Określając czas, będzie to czas do kiedy wyzdrowiejemy. Weź pod uwagę, że używana jest strefa czasowa UTC i że nasza usługa PostgreSQL w master zostanie zrestartowana.
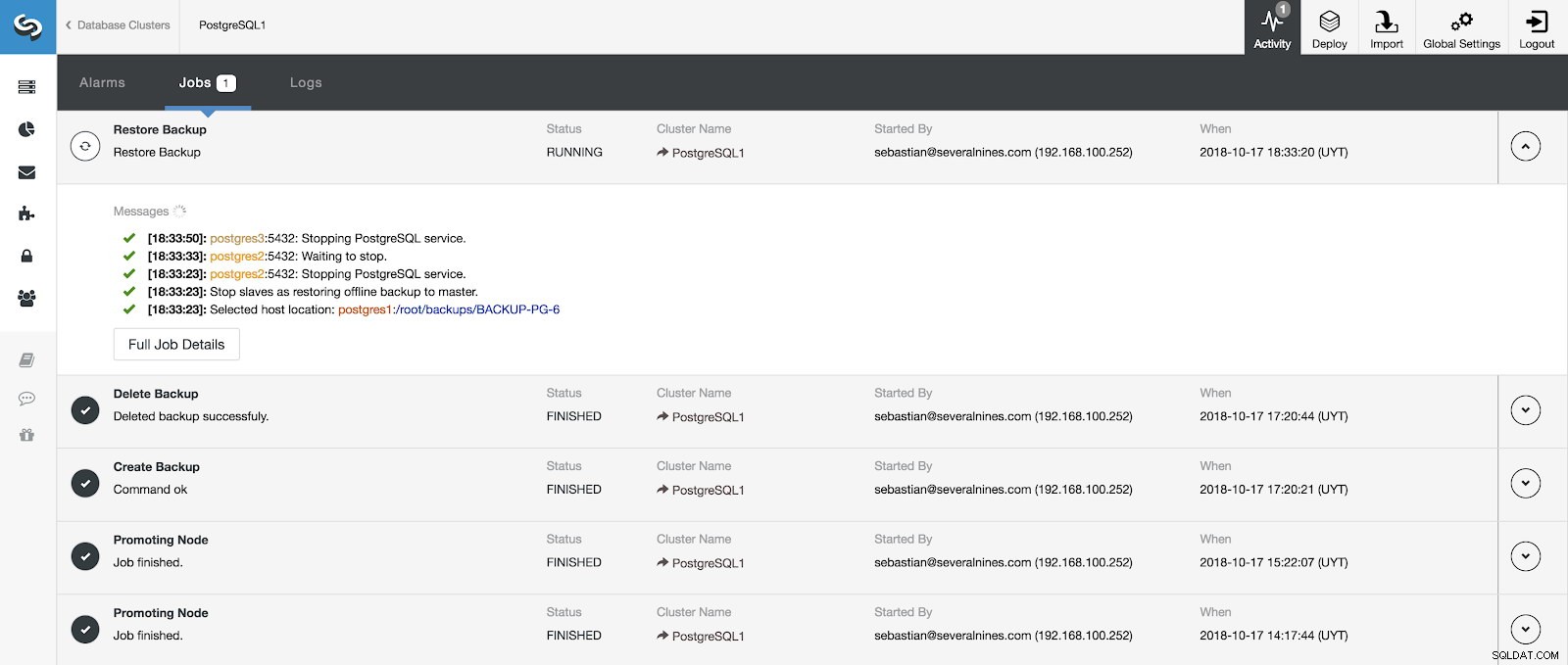
Możemy monitorować postęp naszego przywracania w sekcji Aktywność w naszym ClusterControl.
Wniosek
PITR jest potrzebną funkcją, aby sprostać wąskim RPO. Musimy go poprawnie skonfigurować, aby zapewnić poprawny plan odzyskiwania po awarii. ClusterControl zapewnia łatwy w użyciu interfejs, który pomoże Ci zaimplementować PITR dla baz danych PostgreSQL.