Monitorowanie PostgreSQL może czasami przypominać walkę z bydłem podczas burzy. Aplikacje łączą się i wysyłają zapytania tak szybko, że trudno jest zobaczyć, co się dzieje, a nawet uzyskać dobry przegląd wydajności systemu, inny niż typowy programista narzekający na prośby „rzeczy są powolne, pomóż!”.
W poprzednich artykułach omawialiśmy, jak dostać się do źródła, gdy PostgreSQL działa wolno, ale gdy źródłem są konkretnie zapytania, monitorowanie na poziomie podstawowym może nie wystarczyć do oceny, co dzieje się w aktywnym środowisku na żywo.
Wpisz pg_top, specyficzny dla PostgreSQL program do monitorowania aktywności w bazie danych w czasie rzeczywistym, a także do przeglądania podstawowych informacji o samym hoście bazy danych. Podobnie jak linuxowe polecenie „top”, uruchomienie go wprowadza użytkownika w interaktywny widok na żywo aktywności bazy danych na hoście, odświeżając się automatycznie w odstępach czasu.
Instalacja
Instalację pg_top można przeprowadzić w ogólnie oczekiwany sposób:menedżery pakietów i instalacja źródeł. Najnowsza wersja tego artykułu to 3.7.0.
Menedżerowie pakietów
W oparciu o dystrybucję danego linuksa, wyszukaj pgtop lub pg_top w menedżerze pakietów, prawdopodobnie jest on dostępny w pewnym aspekcie dla zainstalowanej wersji PostgreSQL w systemie.
Dystrybucje oparte na Red Hat:
# sudo yum install pg_topDystrybucje oparte na Gentoo:
# sudo apt-get install pgtopŹródło
W razie potrzeby pg_top można zainstalować za pośrednictwem źródła z repozytorium git PostgreSQL. Zapewni to dowolną pożądaną wersję, nawet nowsze wersje, które nie są jeszcze w oficjalnych wydaniach.
Funkcje
Po zainstalowaniu pg_top działa jako bardzo dokładny widok w czasie rzeczywistym w monitorowanej bazie danych, a użycie wiersza poleceń do uruchomienia „pg_top” uruchomi interaktywne narzędzie do monitorowania PostgreSQL.
Samo narzędzie może pomóc rzucić światło na wszystkie procesy aktualnie połączone z bazą danych.
Uruchamianie pg_top
Uruchomienie pg_top jest takie samo, jak samo polecenie „top” w stylu unix / linux, wraz z informacjami o połączeniu z bazą danych.
Aby uruchomić pg_top na hoście lokalnej bazy danych:
pg_top -h localhost -p 5432 -d severalnines -U postgresAby uruchomić pg_top na zdalnym hoście, wymagana jest flaga -r lub --remote-mode, a rozszerzenie pg_proctab zainstalowane na samym hoście:
pg_top -r -h 192.168.1.20 -p 5432 -d severalnines -U postgresCo jest na ekranie
Po uruchomieniu pg_top widzimy wyświetlacz z dużą ilością informacji.
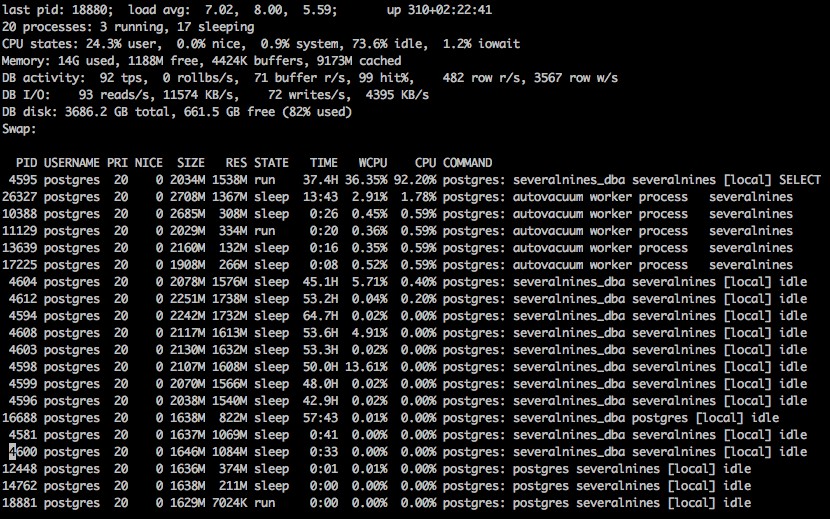 Standardowe wyjście z pg_top w systemie Linux
Standardowe wyjście z pg_top w systemie Linux
Średnia obciążenia:
Podobnie jak w przypadku standardowego polecenia top, to obciążenie jest średnie dla interwałów 1, 5 i 15 minut.
Czas działania:
Całkowity czas, przez jaki system był online od ostatniego ponownego uruchomienia.
Procesy:
Całkowita liczba połączonych procesów bazy danych, wraz z liczbą uruchomionych i śpiących.
Statystyki procesora:
Statystyki procesora, pokazujące procentowe obciążenie dla użytkownika, systemu i bezczynności, ładne informacje oraz wartości procentowe iowait.
Pamięć:
Całkowita ilość używanej pamięci, wolnej, w buforach i w pamięci podręcznej.
Aktywność bazy danych:
Statystyki aktywności bazy danych, takie jak transakcje na sekundę, liczba wycofań na sekundę, bufory odczytane na sekundę, bufory trafione na sekundę, liczba wierszy odczytanych na sekundę i wierszy zapisanych na sekundę.
DB I/O Activity:
Aktywność Input Output w systemie, pokazująca liczbę odczytów i zapisów na sekundę, a także ilość odczytów i zapisów na sekundę.
Statystyki dysku bazy danych:
Całkowity rozmiar dysku bazy danych, a także ilość wolnego miejsca.
Swap:
Informacje o wykorzystanej przestrzeni wymiany, jeśli istnieje.
Procesy:
Lista procesów połączonych z bazą danych, w tym wszelkie procesy wewnętrzne typu autovacuum. Lista zawiera pid, priorytet, niezłą ilość, używaną pamięć rezydentną, stan połączenia, liczbę użytych sekund procesora, procent procesora i bieżące polecenie, które jest uruchomione przez proces.
Przydatne funkcje interaktywne
Istnieje kilka interaktywnych funkcji w pg_top, do których można uzyskać dostęp podczas jego działania. Pełną listę można znaleźć, wpisując ?, co spowoduje wyświetlenie ekranu pomocy ze wszystkimi dostępnymi opcjami.
Informacje planisty
E — Plan wykonania
Wpisanie E spowoduje wyświetlenie monitu o identyfikator procesu, dla którego należy wyświetlić plan wyjaśnienia. Jest to równoznaczne z uruchomieniem „EXPLAIN
A — WYJAŚNIJ ANALIZĘ (ZAKTUALIZUJ/USUŃ sejf)
Wpisanie A spowoduje wyświetlenie monitu o identyfikator procesu, dla którego należy wyświetlić plan WYJAŚNIJ ANALIZĘ. Jest to równoważne uruchomieniu „EXPLAIN ANALYZE
Informacje o procesie
Q — Pokaż bieżące zapytanie procesu
Wpisanie Q spowoduje wyświetlenie monitu o identyfikator procesu, dla którego należy wyświetlić pełne zapytanie.
I - Pokazuje statystyki we/wy na proces (tylko Linux)
Wchodząc przełączam listę procesów na ekran we/wy, pokazujący odczyty, zapisy itp. każdego procesu na dysk.
L — Pokazuje blokady utrzymywane przez proces
Wpisanie L spowoduje wyświetlenie monitu o identyfikator procesu, dla którego należy wyświetlić wstrzymane blokady. Obejmuje to bazę danych, tabelę, typ blokady oraz przyznanie blokady. Przydatne podczas eksploracji długotrwałych lub oczekujących procesów.
Informacje o relacjach
R – Pokaż statystyki tabeli użytkownika.
Wpisanie R wyświetla statystyki tabeli, w tym skanowanie sekwencyjne, skanowanie indeksu, WSTAWIANIE, AKTUALIZACJA i USUNIĘCIE, wszystkie związane z ostatnią aktywnością.
X — Pokaż statystyki indeksu użytkownika
Wpisanie X wyświetla statystyki indeksu, w tym skanowanie indeksu, odczyt indeksu i pobieranie indeksu, wszystkie związane z ostatnią aktywnością.
Sortowanie
Sortowanie wyświetlacza można wykonać według dowolnego z następujących znaków.
M - Sortuj według użycia pamięci
N - Sortuj według pid
P - Sortuj według użycia procesora
T - Sortuj według czas
Poniżej znajdują się wpisy określone po naciśnięciu o, co pozwala na sortowanie stron indeksu, tabeli i statystyk we/wy.
o - Określ porządek sortowania (procesor, rozmiar, res, czas, polecenie)
index stats (idx_scan, idx_tup_fetch, idx_tup_read)
statystyki tabeli (seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins, n_tup_upd, n_tup_upd, n_r, r_tup_> , pisze, pisze, komendy)
Połączenie/manipulacja zapytaniami
k - zabij określone procesy
Wpisanie k spowoduje wyświetlenie monitu o proces lub listę procesów bazy danych do zabicia.
r - zmień proces (tylko lokalna baza danych, tylko root)
Wpisanie r spowoduje wyświetlenie monitu o podanie wartości nice, po której nastąpi lista procesów do ustawienia tej nowej wartości nice. Zmienia to priorytet ważnych procesów w systemie.
Przykład:„renice 1 7004”
Różne zastosowania pg_top
Reaktywne użycie pg_top
Ogólnym zastosowaniem pg_top jest tryb interaktywny, który pozwala nam zobaczyć, jakie zapytania są uruchomione w systemie, w którym występują problemy z powolnym działaniem, uruchamiać plany wyjaśniania tych zapytań, zmieniać ważne zapytania, aby przyspieszyć ich wykonywanie, lub zabijać zapytania powodujące poważne spowolnienia . Ogólnie rzecz biorąc, pozwala administratorowi bazy danych na wykonywanie wielu tych samych czynności, które można wykonać ręcznie w systemie, ale w szybszy sposób i wszystko w jednej opcji.
Proaktywne korzystanie z pg_top
Chociaż nie jest to zbyt powszechne, pg_top można uruchomić w „trybie wsadowym”, który wyświetli główne informacje omówione na standardowe wyjście, a następnie zamknie się. Można to zaprogramować w skryptach, aby działały w określonych odstępach czasu, a następnie wysłane do dowolnego pożądanego procesu niestandardowego, przeanalizowane i wygenerowane alerty na podstawie tego, o czym administrator może chcieć otrzymywać alerty. Na przykład, jeśli obciążenie systemu staje się zbyt duże, jeśli istnieje wyższa niż oczekiwana wartość transakcji na sekundę, wszystko, co może wymyślić kreatywny program.
Ogólnie rzecz biorąc, istnieją inne narzędzia do gromadzenia i raportowania tych informacji, ale posiadanie większej liczby opcji jest zawsze dobrą rzeczą, a mając więcej dostępnych narzędzi, można znaleźć najlepsze opcje.
Historyczne wykorzystanie pg_top
Podobnie jak w przypadku poprzedniego użycia, użycia proaktywnego, możemy skryptować pg_top w trybie wsadowym, aby rejestrować migawki tego, jak wygląda baza danych w czasie. Może to być tak proste, jak zapisanie go do pliku tekstowego ze znacznikiem czasu lub przeanalizowanie go i przechowywanie daty w relacyjnej bazie danych w celu generowania raportów. Pozwoliłoby to na znalezienie większej ilości informacji po poważnym incydencie, takim jak awaria bazy danych o 4 rano. Im więcej dostępnych danych, tym bardziej prawdopodobne jest znalezienie problemów.
Więcej informacji
Dokumentacja projektu jest dość ograniczona, a większość informacji jest dostępna na stronie podręcznika systemu Linux, którą można znaleźć uruchamiając „man pg_top”. Społeczność PostgreSQL może pomóc z pytaniami lub problemami za pośrednictwem list dyskusyjnych PostgreSQL lub oficjalnego czatu IRC znajdującego się na freenode, nazwa kanału #postgresql.