Monitorowanie to jedno z podstawowych zadań w każdym systemie. Może nam pomóc wykryć problemy i podjąć działania lub po prostu poznać aktualny stan naszych systemów. Korzystanie z wyświetlaczy wizualnych może zwiększyć naszą efektywność, ponieważ możemy łatwiej wykrywać problemy z wydajnością.
W tym blogu zobaczymy, jak używać SCUMM do monitorowania naszych baz danych PostgreSQL i jakich metryk możemy użyć do tego zadania. Przejrzymy również dostępne pulpity nawigacyjne, dzięki czemu możesz łatwo dowiedzieć się, co naprawdę dzieje się z Twoimi instancjami PostgreSQL.
Co to jest SCUMM?
Przede wszystkim zobaczmy, czym jest SCUMM (Severalnines ClusterControl Unified Monitoring and Management).
Jest to nowe rozwiązanie oparte na agentach z agentami zainstalowanymi na węzłach bazy danych.
Agenci SCUMM to eksporterzy Prometheusa, którzy eksportują metryki z usług takich jak PostgreSQL jako metryki Prometheus.
Serwer Prometheus służy do zbierania i przechowywania danych szeregów czasowych od agentów SCUMM.
Prometheus to zestaw narzędzi do monitorowania i ostrzegania o otwartym kodzie źródłowym, który został pierwotnie zbudowany w SoundCloud. Jest to teraz samodzielny projekt typu open source i utrzymywany niezależnie.
Prometheus został zaprojektowany z myślą o niezawodności, aby był systemem, do którego przechodzisz podczas awarii, aby umożliwić szybkie diagnozowanie problemów.
Jak używać SCUMM?
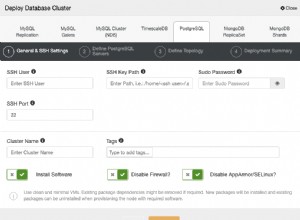
Korzystając z ClusterControl, po wybraniu klastra możemy zobaczyć przegląd naszych baz danych, a także kilka podstawowych metryk, które można wykorzystać do zidentyfikowania problemu. W poniższym panelu możemy zobaczyć konfigurację master-slave z jednym masterem i dwoma slave, z HAProxy i Keepalived.
 Omówienie ClusterControl
Omówienie ClusterControl Jeśli przejdziemy do opcji „Dashboards”, zobaczymy komunikat podobny do poniższego.
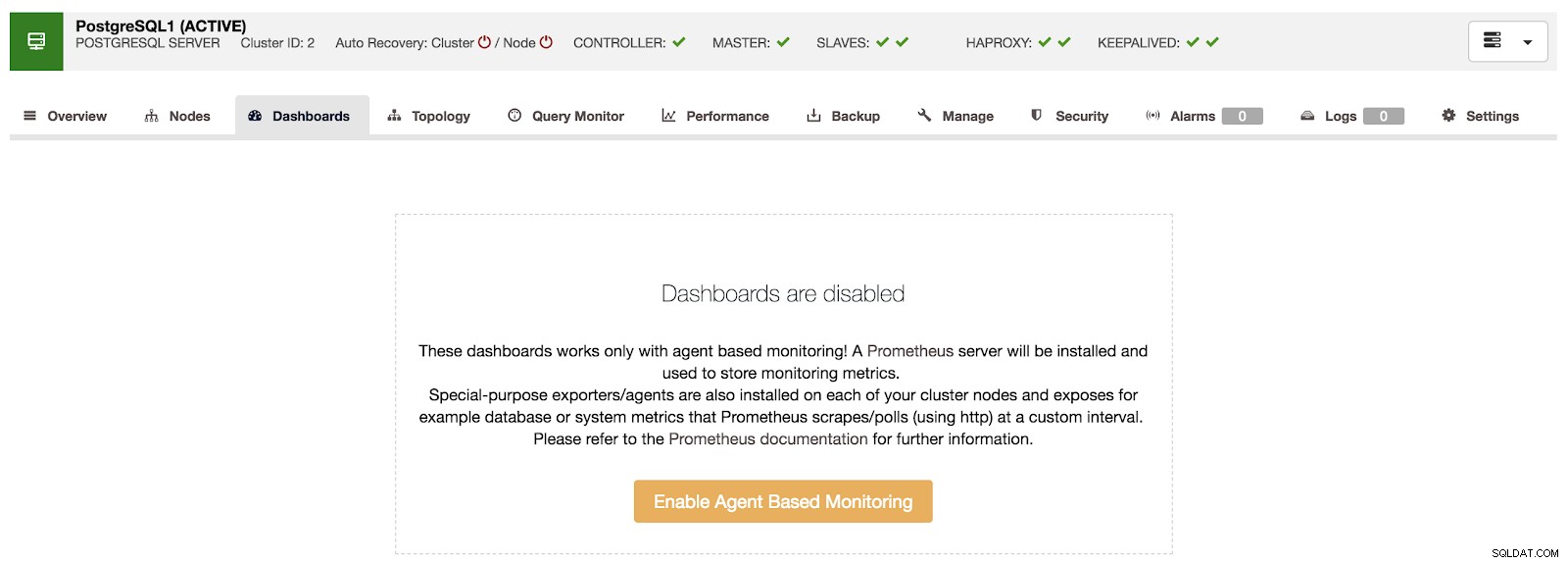 Wyłączone pulpity nawigacyjne ClusterControl
Wyłączone pulpity nawigacyjne ClusterControl Aby skorzystać z tej funkcji, musimy włączyć agenta, o którym mowa powyżej. W tym celu wystarczy nacisnąć przycisk „Włącz monitorowanie oparte na agentach” w tej sekcji.
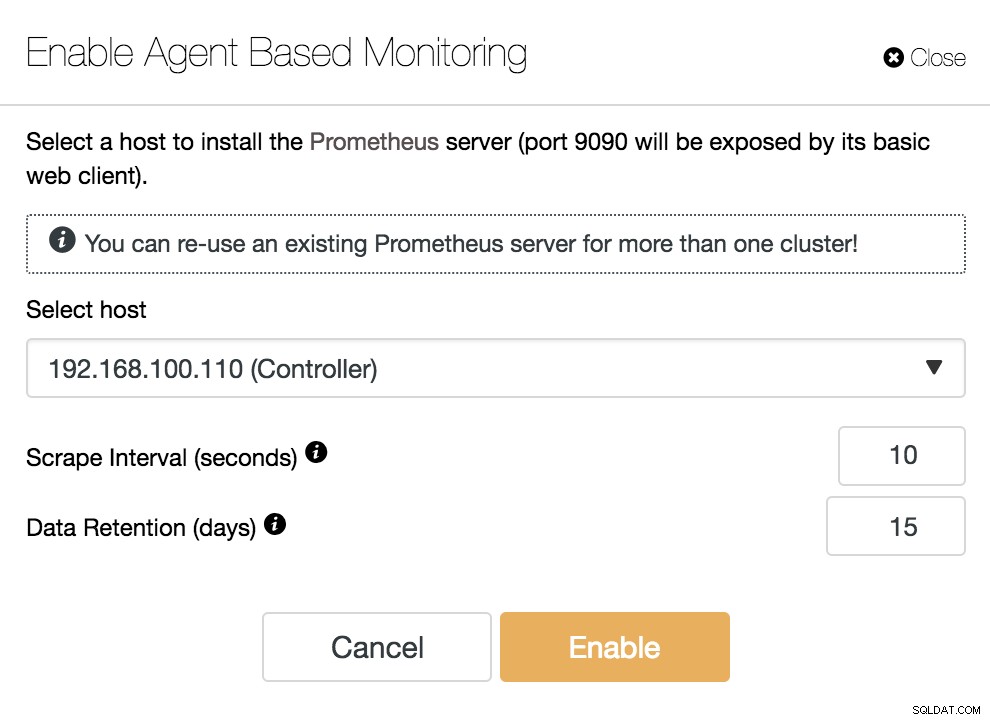 ClusterControl Włącz monitorowanie oparte na agentach
ClusterControl Włącz monitorowanie oparte na agentach Aby włączyć naszego agenta, musimy określić hosta, na którym zainstalujemy nasz serwer Prometheus, który, jak widzimy na przykładzie, może być naszym serwerem ClusterControl.
Musimy również określić:
- Interwał zeskrobywania (sekundy):Ustaw, jak często węzły są zeskrobane w celu uzyskania metryk. Wartość domyślna to 10 sekund.
- Przechowywanie danych (w dniach):określ, jak długo dane są przechowywane przed usunięciem. Wartość domyślna to 15 dni.
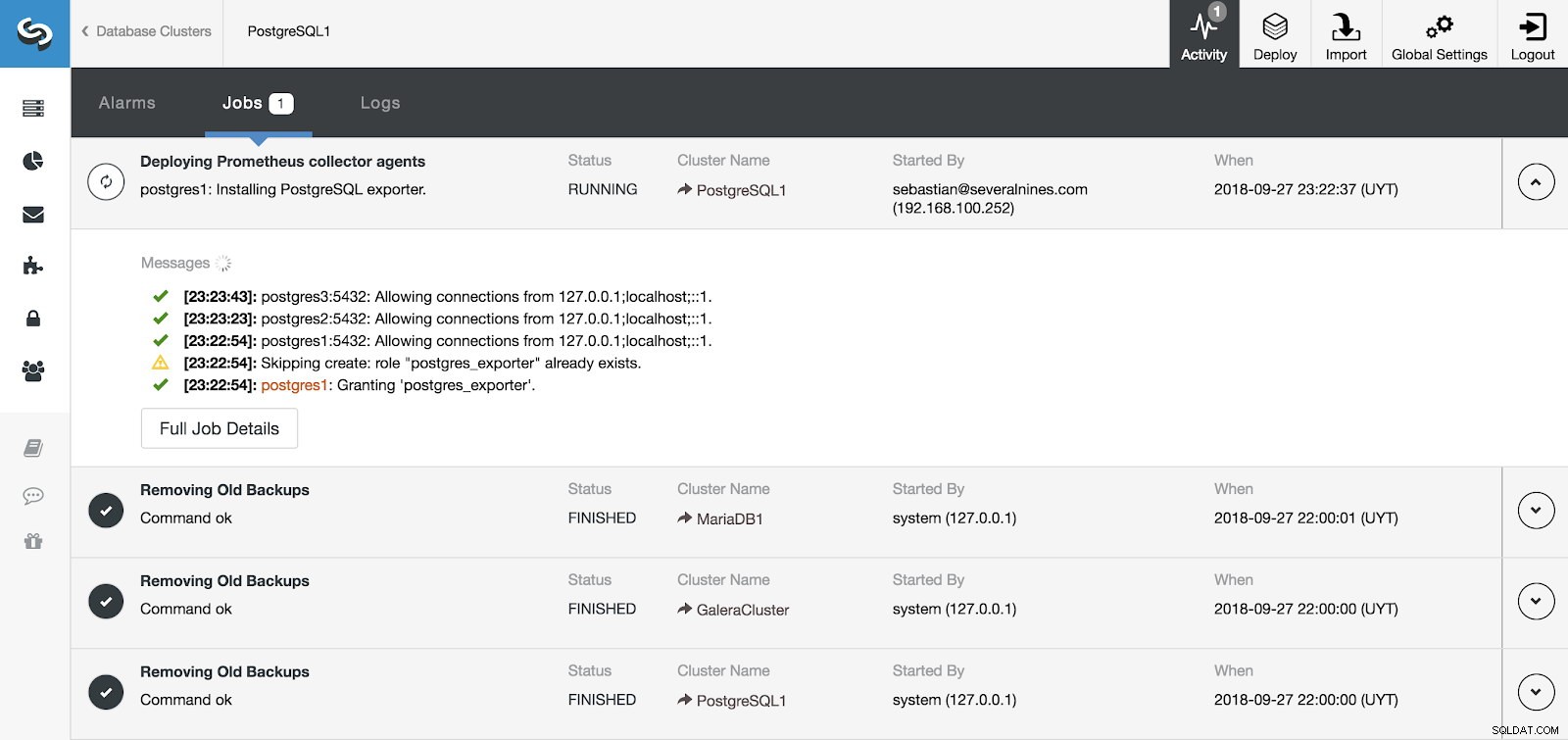 Sekcja aktywności ClusterControl
Sekcja aktywności ClusterControl Możemy monitorować instalację naszego serwera i agentów z sekcji Aktywność w ClusterControl, a po jej zakończeniu możemy zobaczyć nasz klaster z agentami włączonymi z głównego ekranu ClusterControl.
 ClusterControl Agents włączone
ClusterControl Agents włączone Panele informacyjne
Po włączeniu naszych agentów, jeśli przejdziemy do sekcji Pulpity, zobaczymy coś takiego:
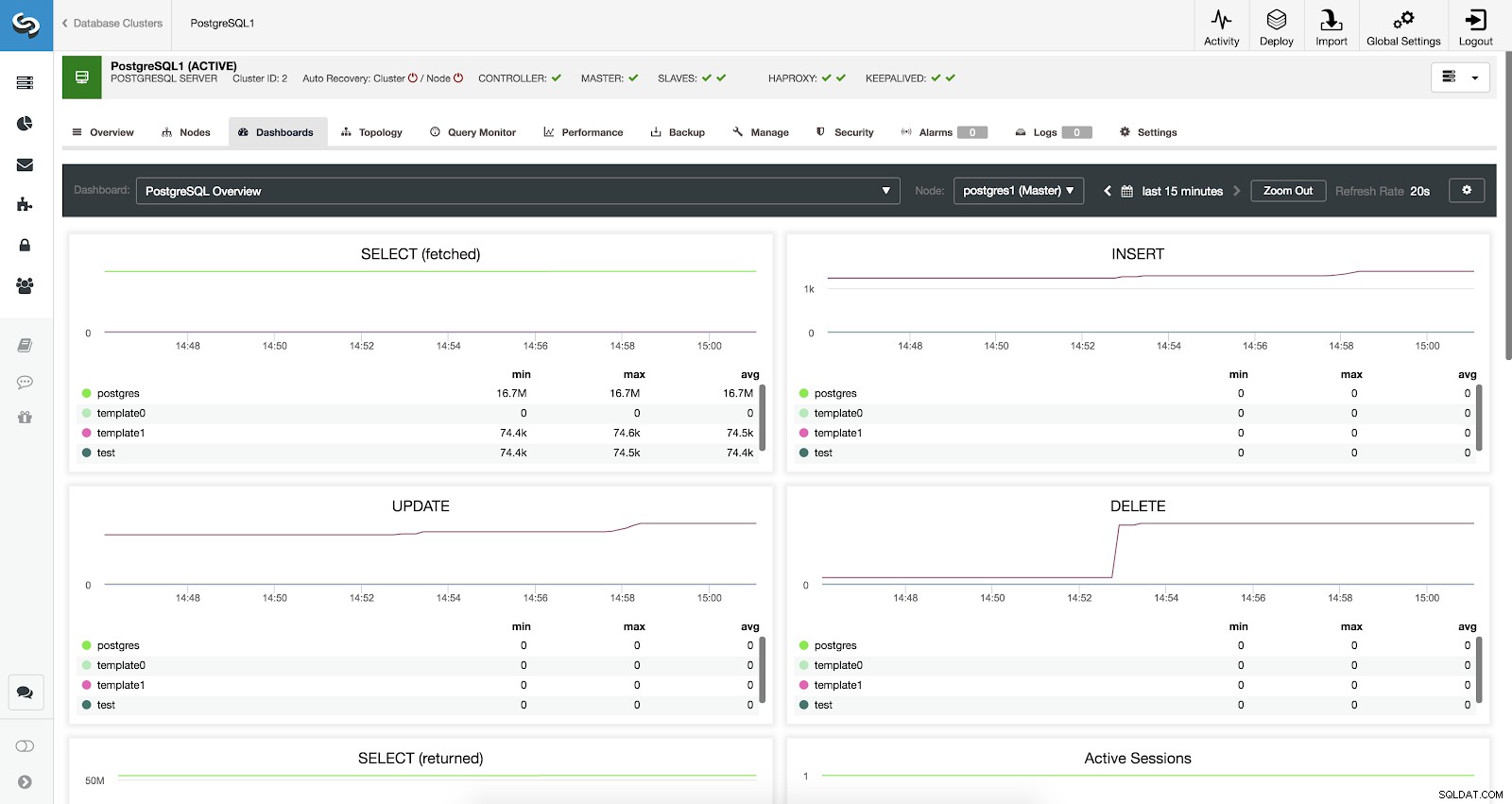 Włączono panele kontrolne ClusterControl
Włączono panele kontrolne ClusterControl Dostępne są trzy różne rodzaje pulpitów nawigacyjnych:Przegląd systemu, Wykresy między serwerami i Przegląd PostgreSQL. Ostatni jest tym, co domyślnie widzimy po wejściu do tej sekcji.
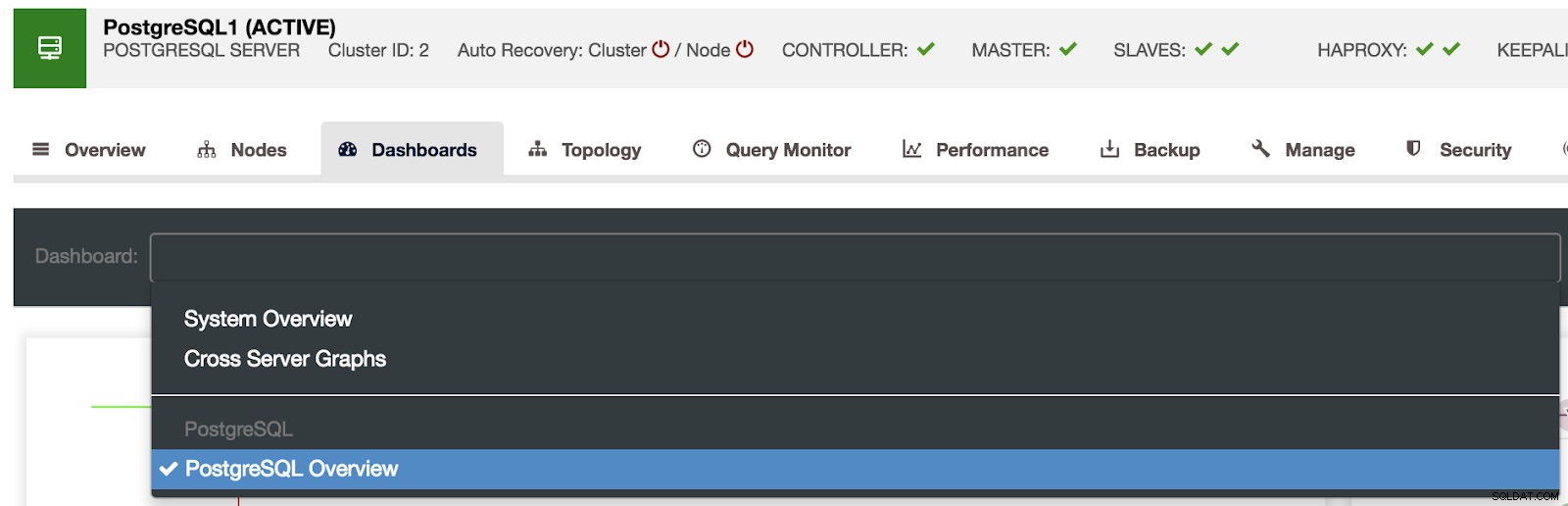 Wybór pulpitów nawigacyjnych ClusterControl
Wybór pulpitów nawigacyjnych ClusterControl Tutaj możemy również określić, który węzeł monitorować, zakres czasu i częstotliwość odświeżania.
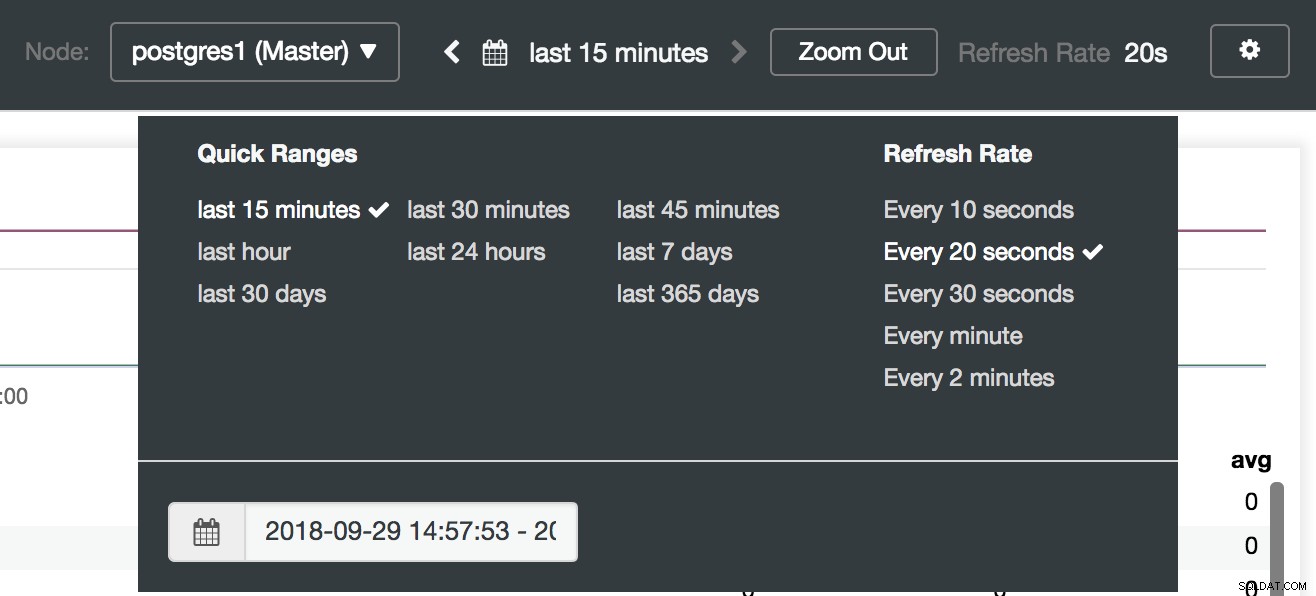 Opcje panelu ClusterControl
Opcje panelu ClusterControl W sekcji konfiguracji możemy włączyć lub wyłączyć naszych agentów (Eksporterów), sprawdzić status agentów i zweryfikować wersję naszego serwera Prometheus.
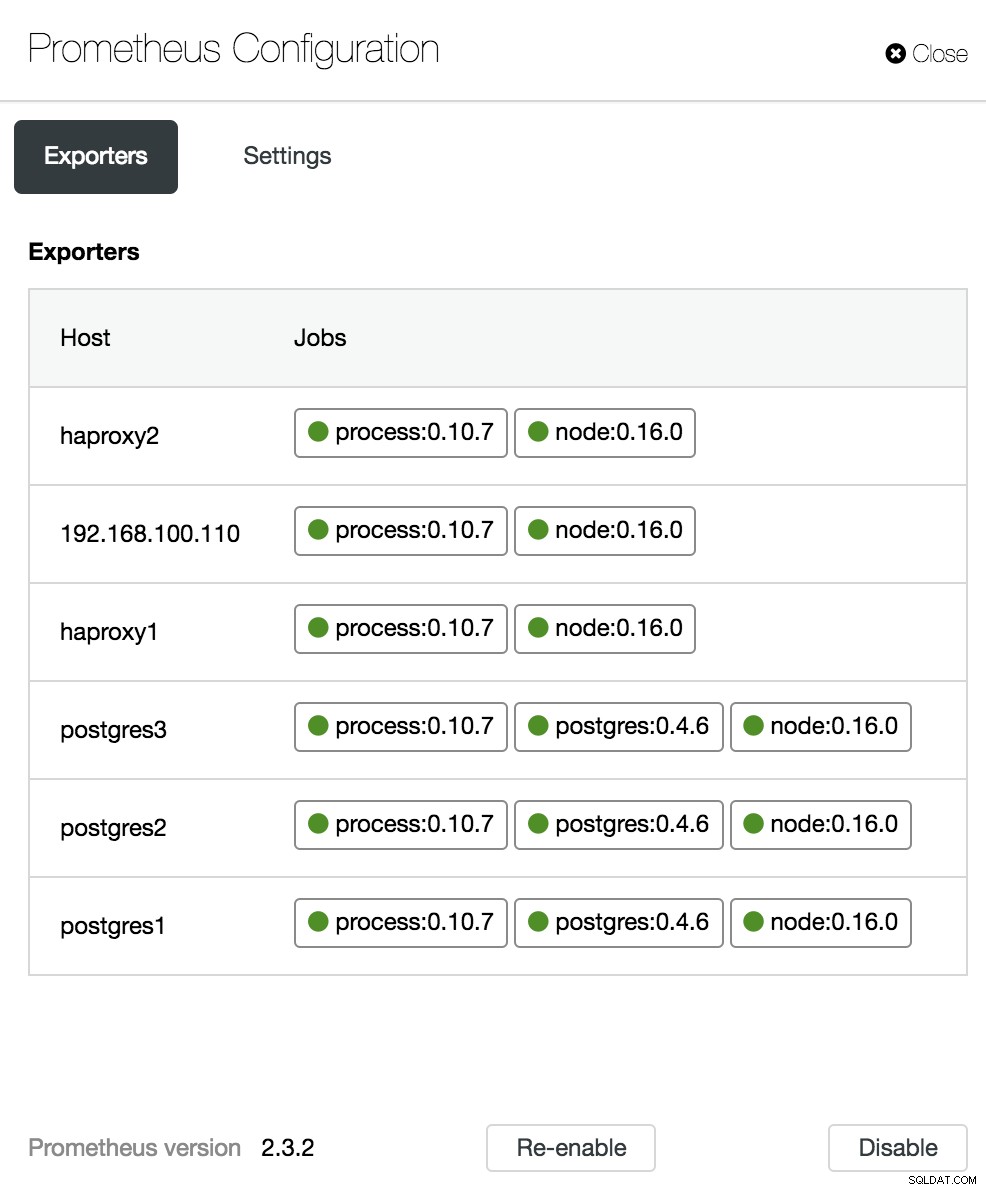 Konfiguracja panelu ClusterControl
Konfiguracja panelu ClusterControl Wskaźniki przeglądu PostgreSQL
Zobaczmy teraz, jakie metryki mamy dostępne dla każdej z naszych baz danych PostgreSQL (wszystkie dla wybranego węzła).
- SELECT (pobrane):Liczba wierszy wybranych (pobranych) dla każdej bazy danych. Pobrane wiersze odnoszą się do aktywnych wierszy pobranych z tabeli.
- SELECT (zwrócony):Liczba wierszy wybranych (zwróconych) dla każdej bazy danych. Zwrócone wiersze odnoszą się do wszystkich wierszy odczytanych z tabeli, w tym wierszy martwych i jeszcze nie zatwierdzonych (w przeciwieństwie do wierszy pobranych, które liczą tylko aktywne krotki).
- WSTAW:Ilość wierszy wstawionych dla każdej bazy danych.
- AKTUALIZACJA:Liczba wierszy zaktualizowanych dla każdej bazy danych.
- USUŃ:Liczba wierszy usuniętych dla każdej bazy danych.
- Aktywne sesje:liczba aktywnych sesji (min., maks. i średnia) dla każdej bazy danych.
- Sesje bezczynności:liczba bezczynnych sesji (min., maks. i średnia) dla każdej bazy danych.
- Tabele blokad:Liczba blokad (min., maks. i średnia) rozdzielonych według typu dla każdej bazy danych.
- Wykorzystanie we/wy dysku:Wykorzystanie we/wy dysku serwera.
- Wykorzystanie dysku:Procentowe wykorzystanie dysku serwera (min., maks. i średnie).
- Opóźnienie dysku:Opóźnienie dysku serwera.
Omówienie wskaźników PostgreSQL ClusterControl Wskaźniki przeglądu systemu
Aby monitorować nasz system, dla każdego serwera mamy dostępne następujące metryki (wszystkie dla wybranego węzła):
- Czas działania systemu:czas od uruchomienia serwera.
- Procesory:liczba procesorów.
- RAM:Ilość pamięci RAM.
- Dostępna pamięć:Procent dostępnej pamięci RAM.
- Średnie obciążenie:minimalne, maksymalne i średnie obciążenie serwera.
- Pamięć:dostępna, całkowita i używana pamięć serwera.
- Wykorzystanie procesora:informacje o minimalnym, maksymalnym i średnim wykorzystaniu procesora przez serwer.
- Dystrybucja pamięci:Dystrybucja pamięci (bufor, pamięć podręczna, wolna i używana) w wybranym węźle.
- Wskaźniki nasycenia:minimalne, maksymalne i średnie obciążenia we/wy i procesora w wybranym węźle.
- Zaawansowane szczegóły pamięci:szczegóły użycia pamięci, takie jak strony, bufor i inne, w wybranym węźle.
- Rozwidlenia:Liczba procesów rozwidlenia. Rozwidlenie to operacja, w ramach której proces tworzy swoją kopię. Zwykle jest to wywołanie systemowe, zaimplementowane w jądrze.
- Procesy:liczba procesów uruchomionych lub oczekujących w systemie operacyjnym.
- Przełączniki kontekstu:Przełącznik kontekstu to akcja przechowywania stanu procesu lub wątku.
- Przerwania:Liczba przerwań. Przerwanie to zdarzenie, które zmienia normalny przebieg wykonywania programu i może być generowane przez urządzenia sprzętowe lub nawet przez sam procesor.
- Ruch sieciowy:przychodzący i wychodzący ruch sieciowy w kilobajtach na sekundę w wybranym węźle.
- Wykorzystanie sieci co godzinę:ruch wysłany i odebrany w ciągu ostatniego dnia.
- Zamień:Zamień użycie (bezpłatne i używane) w wybranym węźle.
- Aktywność wymiany:odczytuje i zapisuje dane podczas wymiany.
- Aktywność we/wy:wchodzenie na stronę i wyjście na stronę we/wy.
- Deskryptory plików:Przydzielone i ograniczone deskryptory plików.
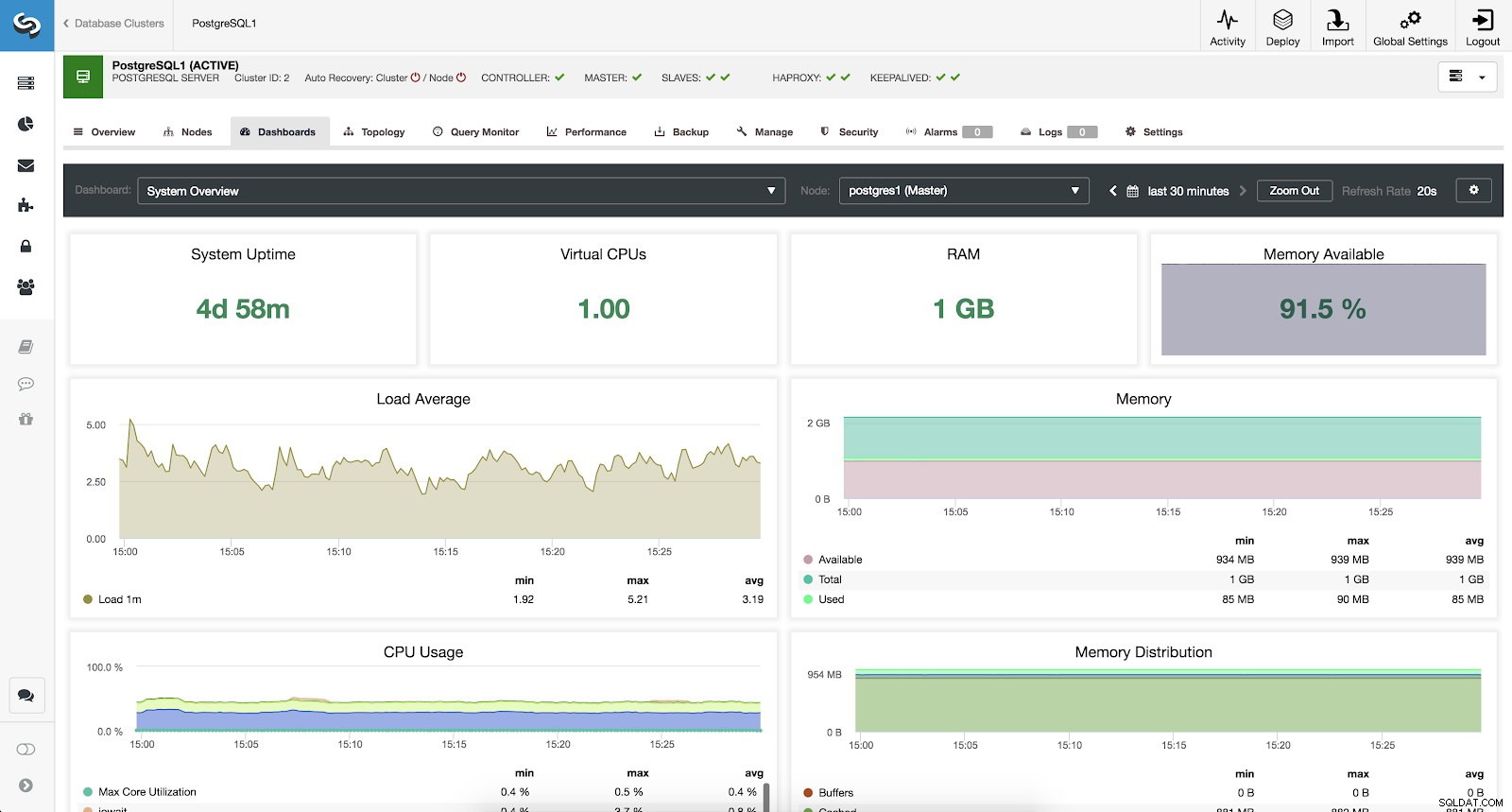 Wskaźniki przeglądu systemu ClusterControl
Wskaźniki przeglądu systemu ClusterControl Wskaźniki wykresów międzyserwerowych
Jeśli chcemy zobaczyć ogólny stan wszystkich naszych serwerów, możemy użyć tego pulpitu nawigacyjnego z następującymi danymi:
- Średnie obciążenie:Serwery średnio obciążają każdy serwer.
- Wykorzystanie pamięci:Procent wykorzystania pamięci dla każdego serwera.
- Ruch sieciowy:minimalny, maksymalny i średni kB ruchu sieciowego na sekundę.
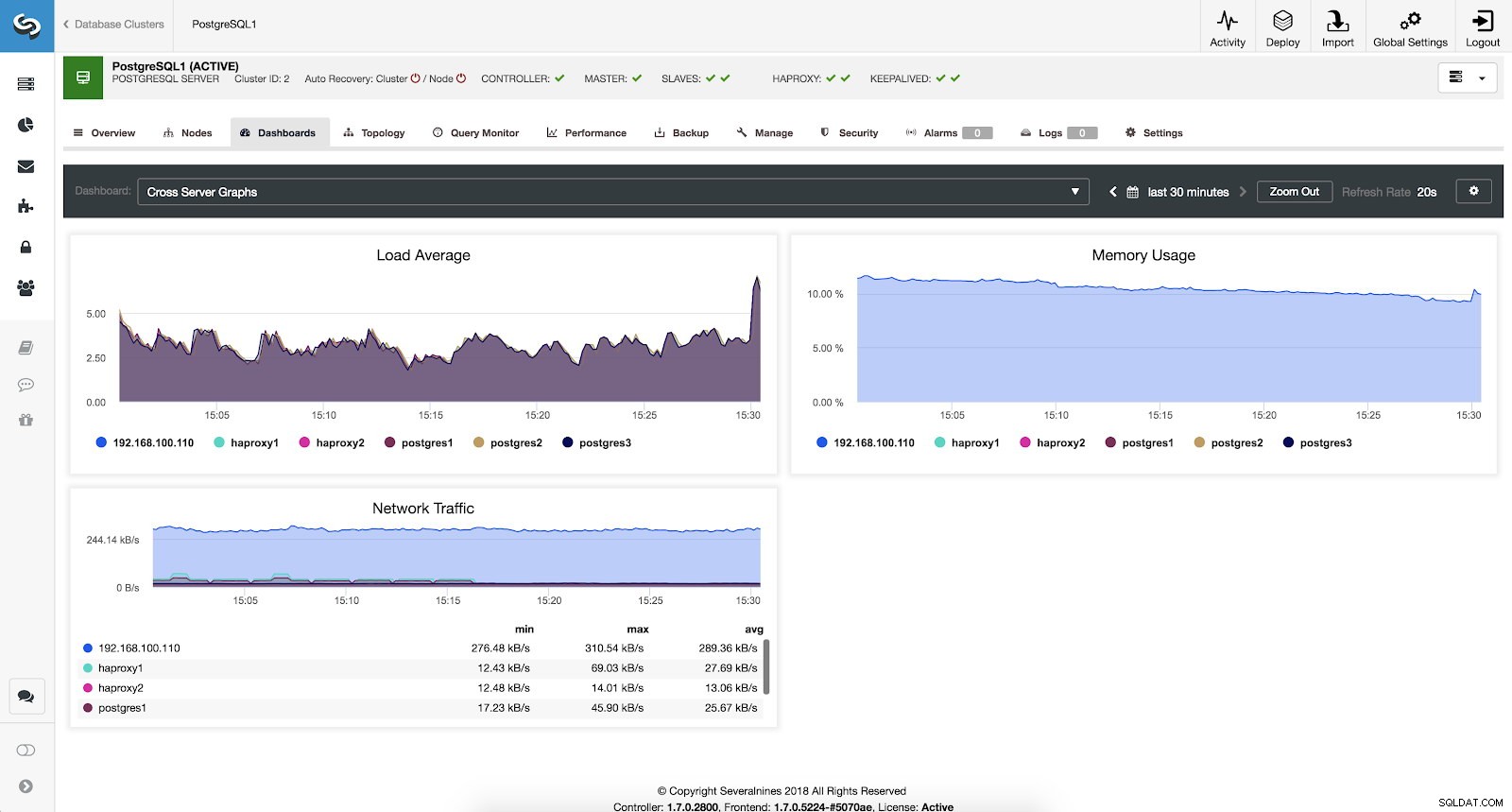 ClusterControl Cross Server Graphs
ClusterControl Cross Server Graphs Wniosek
Istnieje wiele sposobów monitorowania PostgreSQL. ClusterControl zapewnia monitorowanie zarówno bezagentowe, jak i teraz oparte na agentach za pośrednictwem Prometheusa. Zapewnia dane monitorowania o wyższej rozdzielczości, a także różne pulpity nawigacyjne, aby zrozumieć wydajność bazy danych. ClusterControl może również integrować się z zewnętrznymi narzędziami, takimi jak Slack lub PagerDuty, w celu ostrzegania.