Wdrażając klaster baz danych na różnych serwerach, uzyskasz zaletę replikacji polegającą na zwiększeniu dostępności danych. Jednak istnieje potrzeba śledzenia procesów i sprawdzania, czy są uruchomione, czy nie. Jednym z programów wykorzystywanych w tym procesie jest Heartbeat, który ma możliwość sprawdzania i weryfikowania obecności zasobów na jednym lub wielu systemach w danym klastrze. Oprócz PostgreSQL i systemów plików, dla których przechowywane są dane PostgreSQL, DRBD jest jednym z zasobów, które omówimy w tym artykule na temat korzystania z programu Heartbeat.
Ha Heartbeat
Jak omówiono wcześniej na blogu DRBD, wysoką dostępność danych osiąga się poprzez uruchamianie różnych instancji serwera, ale obsługujących te same dane. Te działające instancje serwera można zdefiniować jako klaster w odniesieniu do pulsu. Zasadniczo każda instancja serwera jest fizycznie zdolna do świadczenia tej samej usługi, co inne w ramach tego klastra. Jednak tylko jedna instancja może aktywnie świadczyć usługę na raz w celu zapewnienia wysokiej dostępności danych. Możemy zatem zdefiniować inne instancje jako „gorące części”, które można uruchomić w przypadku awarii kapitana. Pakiet Heartbeat można pobrać z tego linku. Po zainstalowaniu tego pakietu możesz skonfigurować go do pracy z twoim systemem, wykonując poniższą procedurę. Prosta struktura konfiguracji Heartbeat to:
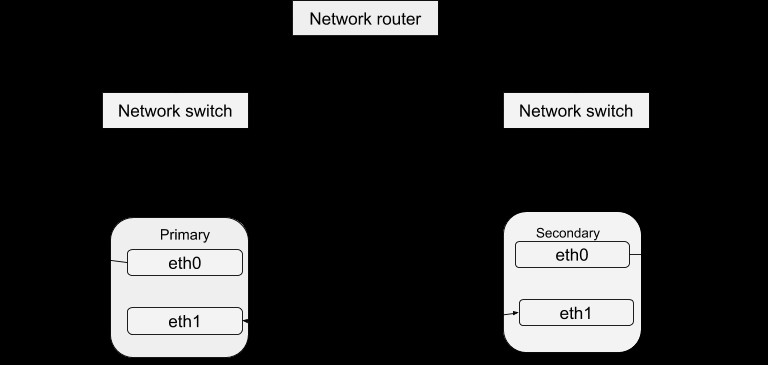
Konfiguracja bicia serca
Zaglądając do katalogu /etc/ha.d znajdziesz kilka plików, które są używane w procesie konfiguracji. Plik ha.cf tworzy główną konfigurację pulsu. Zawiera listę wszystkich węzłów i czasy identyfikacji awarii, a także kieruje pulsem, jakiego typu ścieżki mediów mają być używane i jak je konfigurować. Informacje o zabezpieczeniach klastra są zapisywane w pliku authkeys. Informacje zapisane w tych plikach powinny być identyczne dla wszystkich hostów w klastrze i można to łatwo osiągnąć poprzez synchronizację na wszystkich hostach. Oznacza to, że każda zmiana informacji w jednym hoście powinna zostać skopiowana do wszystkich pozostałych.
Plik Ha.cf
Podstawowy zarys pliku ha.cf to
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:ten jest używany do kierowania Heartbeat, w którym funkcja rejestrowania syslog powinna być używana do nagrywania wiadomości. Najczęściej używane wartości to auth, authpriv, user, local0, syslog i daemon. Możesz również zdecydować, aby nie mieć żadnych dzienników, aby ustawić wartość na none .ie
logfacility none - Keepalive:jest to czas między uderzeniami serca, czyli częstotliwość, z jaką sygnał pulsu jest wysyłany do innych hostów. W powyższym przykładowym kodzie jest ustawiony na 3 sekundy.
- Czas martwy:jest to opóźnienie w sekundach, po którym stwierdza się, że węzeł uległ awarii.
- Czas ostrzeżenia:to opóźnienie w sekundach, po którym w dzienniku zapisywane jest ostrzeżenie wskazujące, że nie można już skontaktować się z węzłem.
- Initdead:jest to czas w sekundach oczekiwania podczas uruchamiania systemu, zanim drugi host zostanie uznany za wyłączony.
- Mcast:jest to zdefiniowana procedura metody wysyłania sygnału bicia serca. W powyższym przykładowym kodzie adres sieciowy multiemisji jest używany przez ograniczone urządzenie sieciowe. W przypadku wielu klastrów adres multiemisji musi być unikalny dla każdego klastra. Możesz także wybrać połączenie szeregowe przez multicast lub jeśli skonfigurowałeś w taki sposób, że istnieje wiele interfejsów sieciowych, użyj obu do połączenia pulsu, jak w przykładzie. Zaletą korzystania z obu jest przezwyciężenie szans na przejściową awarię, która w konsekwencji może spowodować nieprawidłowe zdarzenie awarii.
- Auto_failback:ponownie łączy serwer, który uległ awarii, z powrotem do klastra, jeśli stanie się dostępny. Może to jednak spowodować zamieszanie, jeśli serwer zostanie włączony, a następnie przejdzie do trybu online w innym czasie. Jeśli chodzi o DRBD, jeśli nie jest dobrze skonfigurowany, możesz otrzymać więcej niż jeden zestaw danych na tym samym serwerze. Dlatego zaleca się, aby zawsze był wyłączony.
- Węzeł:przedstawia węzeł w grupie klastrów Heartbeat. Powinieneś mieć co najmniej 1 węzeł dla każdego.
Dodatkowe konfiguracje
Możesz także ustawić dodatkowe informacje konfiguracyjne, takie jak:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:jest to ważne, aby zapewnić łączność na publicznym interfejsie serwerów i połączenie z innym hostem. Ważne jest, aby wziąć pod uwagę adres IP, a nie nazwę hosta dla maszyny docelowej.
- Respawn:jest to polecenie do uruchomienia, gdy wystąpi awaria.
- Apiauth:jest autorytetem niepowodzenia. Musisz skonfigurować identyfikator użytkownika i grupy, z którym polecenie zostanie wykonane. Plik authkeys zawiera informacje o autoryzacji dla klastra Heartbeat, a ten klucz jest bardzo unikalny do weryfikowania maszyn w danym klastrze Heartbeat.
- Deadping:określa limit czasu, zanim brak odpowiedzi wywoła awarię.
Integracja Heartbeat z Postgresem i DRBD
Jak wspomniano wcześniej, gdy serwer główny ulegnie awarii, inny serwer z danym klastrem uruchomi się, aby zapewnić tę samą usługę. Heartbeat pomaga w konfiguracji zasobów, które zwiększają wybór serwera w przypadku awarii. Określa na przykład, które poszczególne serwery powinny zostać uruchomione lub odrzucone w przypadku awarii. Wpisując się do pliku haresources w katalogu /etc/ha.d, otrzymujemy zarys zasobów, którymi można zarządzać. Ścieżka do pliku zasobów to /etc/ha.d/resource.d, a definicja zasobu znajduje się w jednym wierszu:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(zwróć uwagę na spacje).
- Drbd1:odnosi się do nazwy preferowanego hosta, który ma być wyższy od serwera, który jest zwykle używany jako domyślny master do obsługi usługi. Jak wspomniano na blogu DRBD, potrzebujemy zasobów dla naszego serwera i są one zdefiniowane w wierszu jako drbddisk, system plików i postgres. Ostatnie pole to wirtualny adres IP, który należy wykorzystać do udostępnienia usługi, czyli połączenia z serwerem Postgres. Domyślnie zostanie przydzielony do serwera, który jest aktywny w momencie rozpoczęcia bicia serca. Gdy wystąpi awaria, zasoby te zostaną uruchomione na serwerze zapasowym w kolejności rozmieszczenia podczas wywoływania odpowiedniego skryptu. W ustawieniu skrypt przełączy dysk DRBD na hoście pomocniczym w tryb podstawowy, dzięki czemu urządzenie będzie odczytywać/zapisywać.
- System plików:będzie to zarządzać zasobami systemu plików iw tym przypadku wybrano DRBD, więc zostanie on zamontowany podczas wywoływania skryptu zasobów.
- Postgres:uruchomi lub zarządza serwerem Postgres
Czasami chcesz otrzymywać powiadomienia e-mailem. Aby to zrobić, dodaj ten wiersz do pliku zasobów wraz z wiadomością e-mail, aby otrzymywać ostrzeżenia:
MailTo:: example@sqldat.com::DRBDFailureAby rozpocząć bicie serca, możesz uruchomić polecenie
/etc/ha.d/heartbeat startlub zrestartuj serwer podstawowy i pomocniczy. Teraz, jeśli uruchomisz polecenie
$ /usr/lib64/heartbeat/hb_standbyBieżący węzeł zostanie uruchomiony w celu czystego przekazania swoich zasobów drugiemu węzłowi.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentObsługa błędów na poziomie systemu
Czasami jądro serwera może być uszkodzone, co wskazuje na potencjalny problem z serwerem. Musisz skonfigurować serwer tak, aby usuwał się z klastra w przypadku wystąpienia problemu. Ten problem jest często określany jako panika jądra i w konsekwencji powoduje twardy restart komputera. Możesz wymusić ponowne uruchomienie, ustawiając kernel.panic i kernel.panic_on_oop w pliku kontrolnym jądra /etc/sysctl.conf. To znaczy
kernel.panic_on_oops = 1
kernel.panic = 1Inną opcją jest zrobienie tego z wiersza poleceń za pomocą polecenia sysctl, tj.:
$ sysctl -w kernel.panic=1Możesz także edytować plik sysctl.conf i ponownie załadować informacje konfiguracyjne za pomocą tego polecenia.
sysctl -pWartość wskazuje liczbę sekund oczekiwania przed ponownym uruchomieniem. Drugi węzeł pulsu powinien następnie wykryć, że serwer nie działa, a następnie przełączyć hosta awaryjnego.
Wniosek
Heartbeat to podsystem, który umożliwia wybór serwera pomocniczego na system podstawowy i system zapasowy w przypadku awarii serwera aktywnego. Określa również, czy wszystkie inne serwery są aktywne. Zapewnia również transfer zasobów do nowego węzła głównego