Wprowadzenie
W dzisiejszych czasach wysoka dostępność jest wymogiem dla wielu systemów, niezależnie od używanej technologii. Jest to szczególnie ważne w przypadku baz danych, ponieważ przechowują one dane, na których opierają się krytyczne aplikacje i systemy. Najpopularniejszą strategią osiągania wysokiej dostępności jest replikacja. Istnieją różne sposoby replikacji danych na wielu serwerach i ruchu awaryjnego, gdy na przykład serwer główny przestaje odpowiadać.
Architektura wysokiej dostępności dla PostgreSQL
Istnieje kilka architektur do implementacji wysokiej dostępności w PostgreSQL, ale podstawowymi są architektury podstawowa-gotowość i podstawowa-podstawowa.
Architektury w trybie podstawowej gotowości
Primary-Standby może być najbardziej podstawową architekturą HA, jaką można skonfigurować, i często najłatwiejszą do wdrożenia i utrzymania. Opiera się na jednej podstawowej bazie danych z co najmniej jednym serwerem w trybie gotowości. Te bazy danych w trybie gotowości pozostaną zsynchronizowane (lub prawie zsynchronizowane) z węzłem podstawowym, w zależności od tego, czy replikacja jest synchroniczna, czy asynchroniczna. Jeśli serwer główny ulegnie awarii, serwer w trybie gotowości zawiera prawie wszystkie dane serwera głównego i może zostać szybko przekształcony w nowy główny serwer bazy danych.
Można zaimplementować dwa typy baz danych w trybie gotowości, w zależności od charakteru replikacji:
- Tryby gotowości logicznej — replikacja między trybem podstawowym i gotowości jest wykonywana za pomocą instrukcji SQL.
- Tryby gotowości fizycznej — replikacja między trybem podstawowym i gotowości jest wykonywana poprzez wewnętrzne modyfikacje struktury danych.
W przypadku PostgreSQL strumień rekordów dziennika zapisu z wyprzedzeniem (WAL) jest używany do utrzymywania synchronizacji baz danych w trybie gotowości. Może to być synchroniczne lub asynchroniczne, a cały serwer bazy danych jest replikowany.
Od wersji 10 PostgreSQL zawiera wbudowaną opcję konfigurowania replikacji logicznej, która tworzy strumień logicznych modyfikacji danych na podstawie informacji w dzienniku zapisu z wyprzedzeniem. Ta metoda replikacji umożliwia replikację zmian danych z poszczególnych tabel bez konieczności wyznaczania serwera głównego. Pozwala również na przepływ danych w wielu kierunkach.
Niestety, konfiguracja podstawowa-gotowość nie wystarcza do skutecznego zapewnienia wysokiej dostępności, ponieważ trzeba również radzić sobie z awariami. Aby poradzić sobie z awariami, musisz być w stanie je wykryć. Gdy wiesz, że wystąpiła awaria, na przykład błędy w węźle głównym lub węzeł nie odpowiada, możesz wybrać węzeł rezerwowy, aby zastąpić uszkodzony węzeł z możliwie najmniejszym opóźnieniem. Proces ten musi być jak najbardziej wydajny, aby przywrócić pełną funkcjonalność aplikacji. Sam PostgreSQL nie zawiera automatycznego mechanizmu przełączania awaryjnego, więc będzie to wymagało użycia niestandardowego skryptu lub narzędzi innych firm do tej automatyzacji.
Po przejściu awaryjnym aplikacja musi zostać odpowiednio powiadomiona, aby rozpocząć korzystanie z nowej wersji Podstawowej. Musisz również ocenić stan swojej architektury po przełączeniu awaryjnym, ponieważ możesz napotkać sytuację, w której działa tylko nowy główny (np. przed problemem miałeś węzeł główny i tylko jeden tryb gotowości). W takim przypadku będziesz musiał dodać węzeł gotowości, aby odtworzyć konfigurację podstawowa-gotowość, którą pierwotnie miałeś w celu zapewnienia wysokiej dostępności.
Architektury podstawowe-podstawowe
Architektura podstawowa-podstawowa zapewnia sposób na zminimalizowanie wpływu błędu na jeden z węzłów, ponieważ inne węzły mogą zająć się całym ruchem, tylko potencjalnie nieznacznie wpływając na wydajność ale nigdy nie tracąc funkcjonalności. Architektura podstawowa-główna jest często używana w podwójnym celu tworzenia środowiska o wysokiej dostępności i skalowania w poziomie (w porównaniu z koncepcją skalowalności pionowej, w której dodaje się więcej zasobów do serwera).
PostgreSQL nie obsługuje jeszcze tej architektury „natywnie”, więc będziesz musiał odwołać się do narzędzi i implementacji innych firm. Wybierając rozwiązanie, należy pamiętać, że istnieje wiele projektów/narzędzi, ale niektóre z nich nie są już obsługiwane, podczas gdy inne są nowe i mogą nie zostać przetestowane w produkcji.
Równoważenie obciążenia
Systemy równoważenia obciążenia to narzędzia, których można użyć do zarządzania ruchem z Twojej aplikacji, aby jak najlepiej wykorzystać architekturę bazy danych.
Narzędzia te są nie tylko pomocne w równoważeniu obciążenia baz danych, ale także pomagają aplikacjom przekierowywać do dostępnych/zdrowych węzłów, a nawet określać porty o różnych rolach.
HAProxy to moduł równoważenia obciążenia, który rozdziela ruch z jednego źródła do jednego lub więcej miejsc docelowych i może zdefiniować określone reguły i/lub protokoły dla tego zadania. Jeśli którykolwiek z miejsc docelowych przestanie odpowiadać, zostanie oznaczony jako offline, a ruch jest kierowany do pozostałych dostępnych miejsc docelowych.
Keepalived to usługa, która umożliwia skonfigurowanie wirtualnego adresu IP w ramach aktywnej/pasywnej grupy serwerów. Ten wirtualny adres IP jest przypisany do aktywnego serwera. Jeśli ten serwer ulegnie awarii, adres IP zostanie automatycznie przeniesiony do „dodatkowego” serwera pasywnego, umożliwiając mu dalszą pracę z tym samym adresem IP w sposób przejrzysty dla systemów.
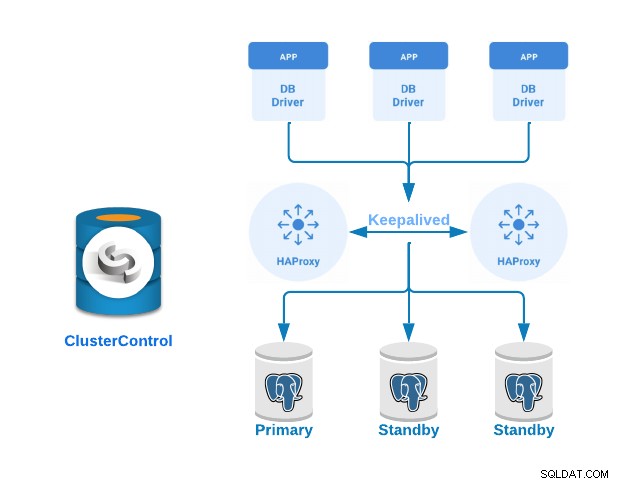
Zobaczmy teraz, jak zaimplementować klaster Primary-Standby PostgreSQL z serwerami równoważenia obciążenia i konfiguracją utrzymywania aktywności między nimi. Zademonstrujemy to za pomocą łatwego w użyciu interfejsu ClusterControl.
W tym przykładzie utworzymy:
- 3 serwery PostgreSQL (jeden podstawowy i dwa w trybie gotowości).
- 2 systemy równoważenia obciążenia HAProxy.
- Utrzymuj konfigurację między serwerami równoważenia obciążenia.
Wdrażanie bazy danych
Aby wdrożyć bazę danych za pomocą ClusterControl, po prostu wybierz opcję „Wdróż” i postępuj zgodnie z wyświetlanymi instrukcjami.
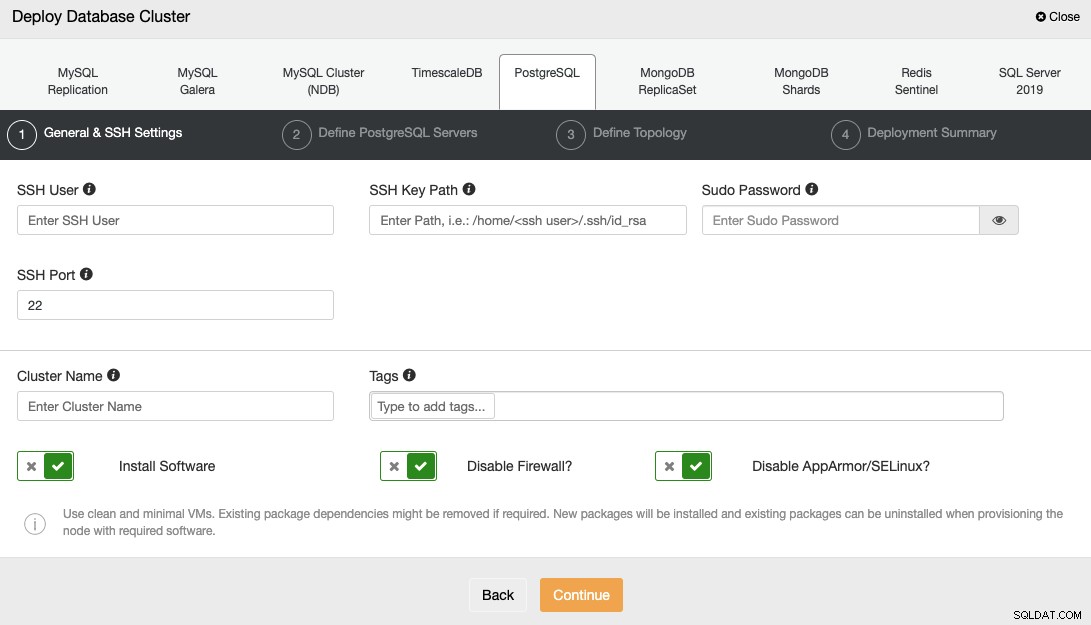
Wybierając PostgreSQL, musisz określić Użytkownika, Klucz lub Hasło oraz Port do łączenia się przez SSH z Twoimi serwerami. Potrzebujesz również nazwy nowego klastra i wybierz, czy chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
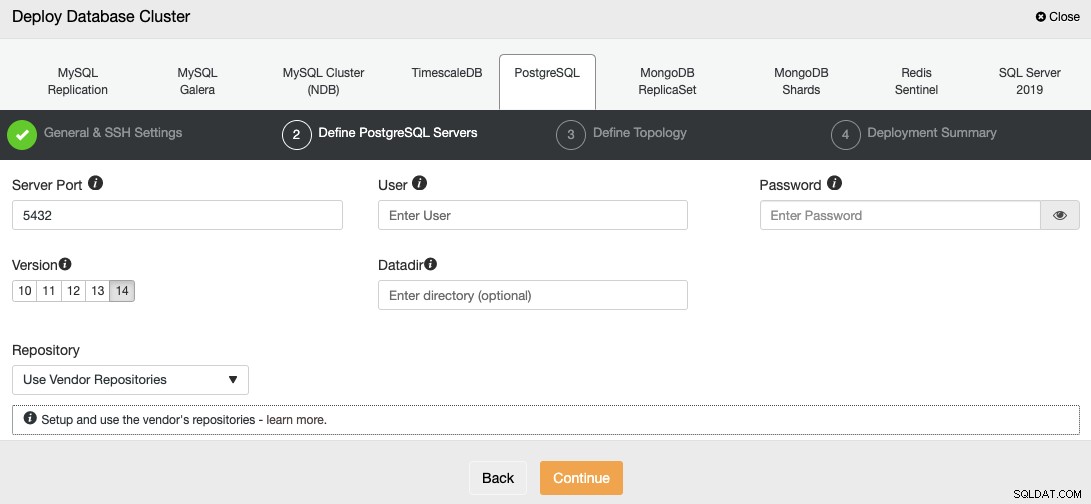
Po skonfigurowaniu informacji dostępowych SSH należy zdefiniować użytkownika bazy danych, wersja i katalog danych (opcjonalnie). Możesz także określić, którego repozytorium chcesz użyć; oficjalne repozytorium dostawców będzie używane domyślnie.
W następnym kroku musisz dodać swoje serwery do tworzonego klastra.
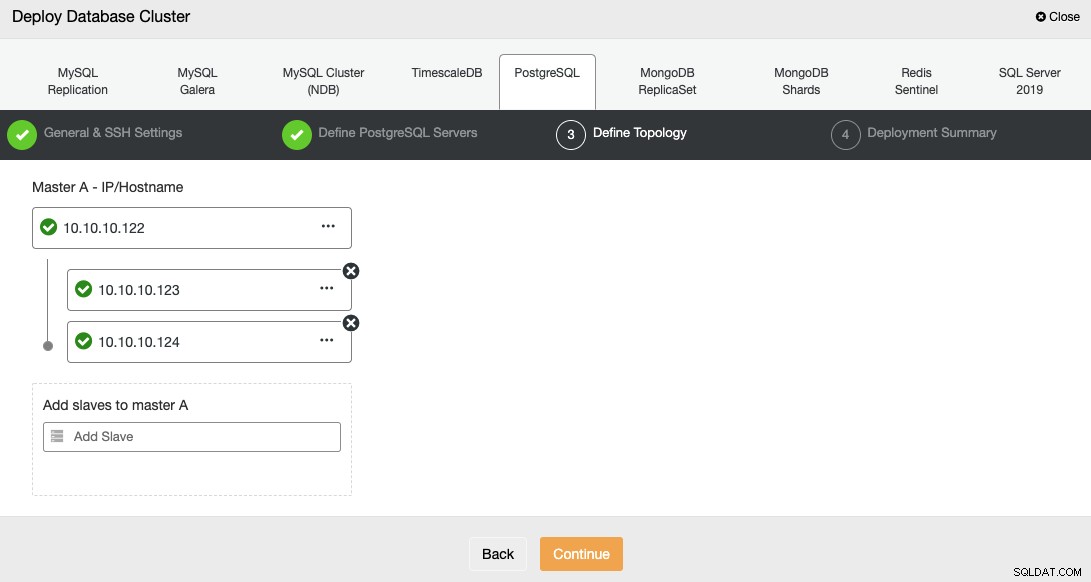
Podczas dodawania serwerów możesz podać adres IP lub nazwę hosta.
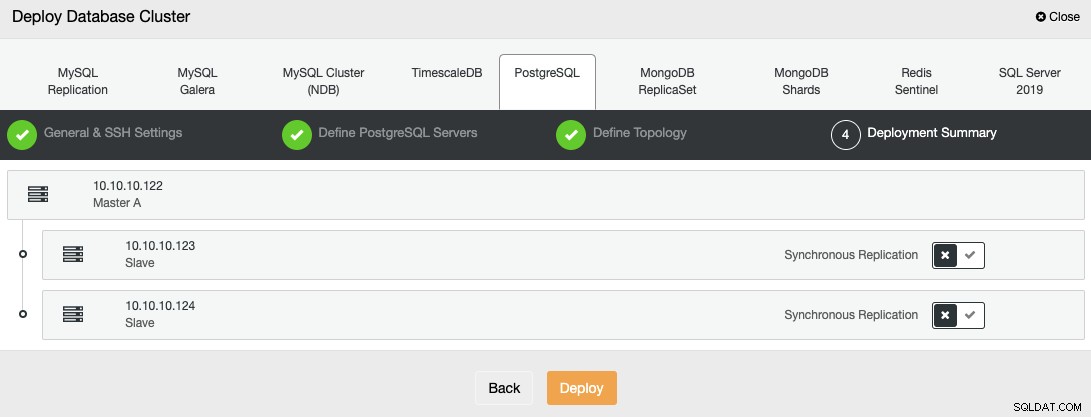
W ostatnim kroku możesz wybrać, czy twoja replikacja będzie synchroniczna czy asynchroniczna.
Możesz monitorować stan tworzenia nowego klastra z ClusterControl monitor aktywności.
Po zakończeniu zadania możesz zobaczyć swój klaster w głównym ClusterControl ekran.
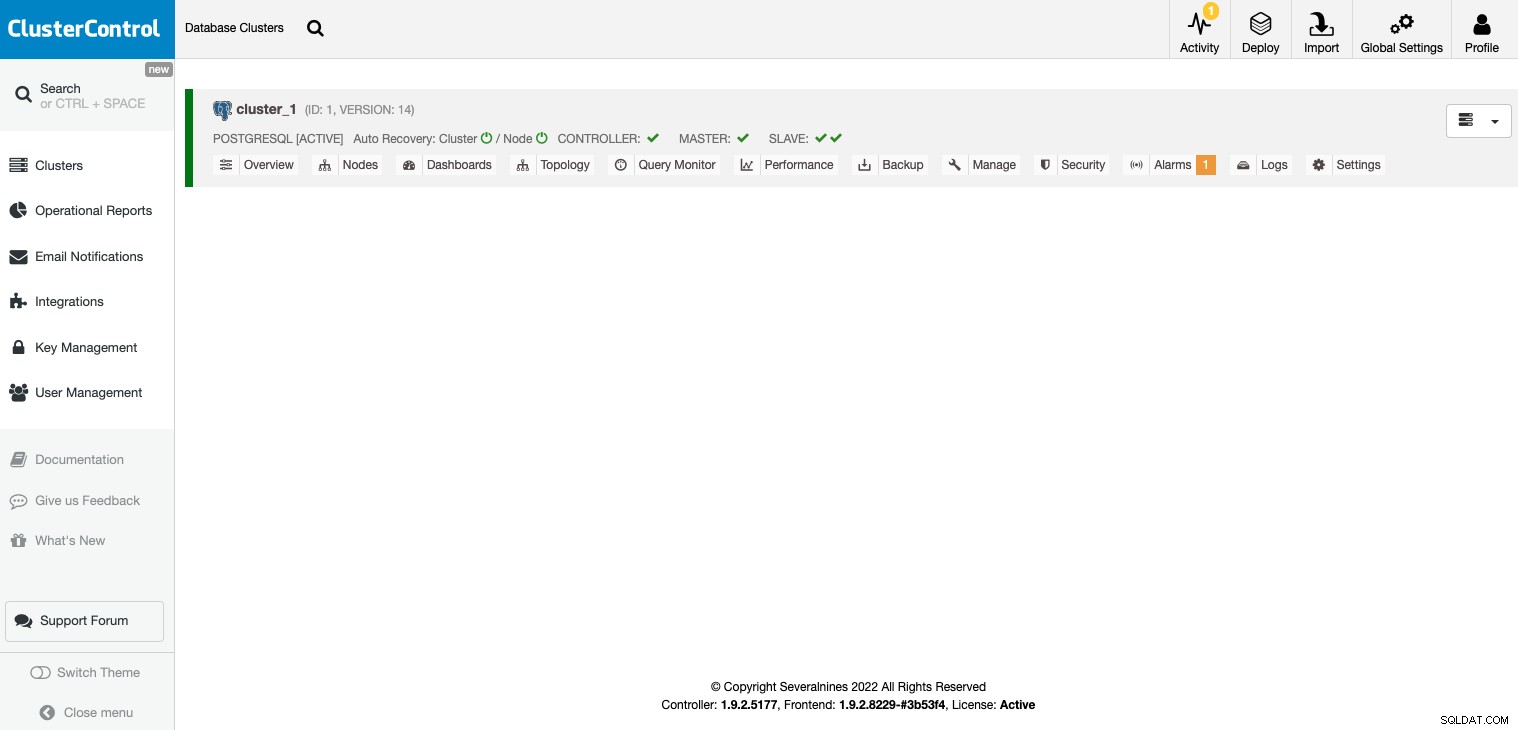
Po utworzeniu klastra możesz wykonać kilka zadań, takich jak dodanie load balancer (HAProxy) lub nowa replika.
Wdrażanie systemu równoważenia obciążenia
Aby przeprowadzić wdrożenie systemu równoważenia obciążenia, wybierz opcję „Dodaj system równoważenia obciążenia” w działaniach klastra i wypełnij wymagane informacje.
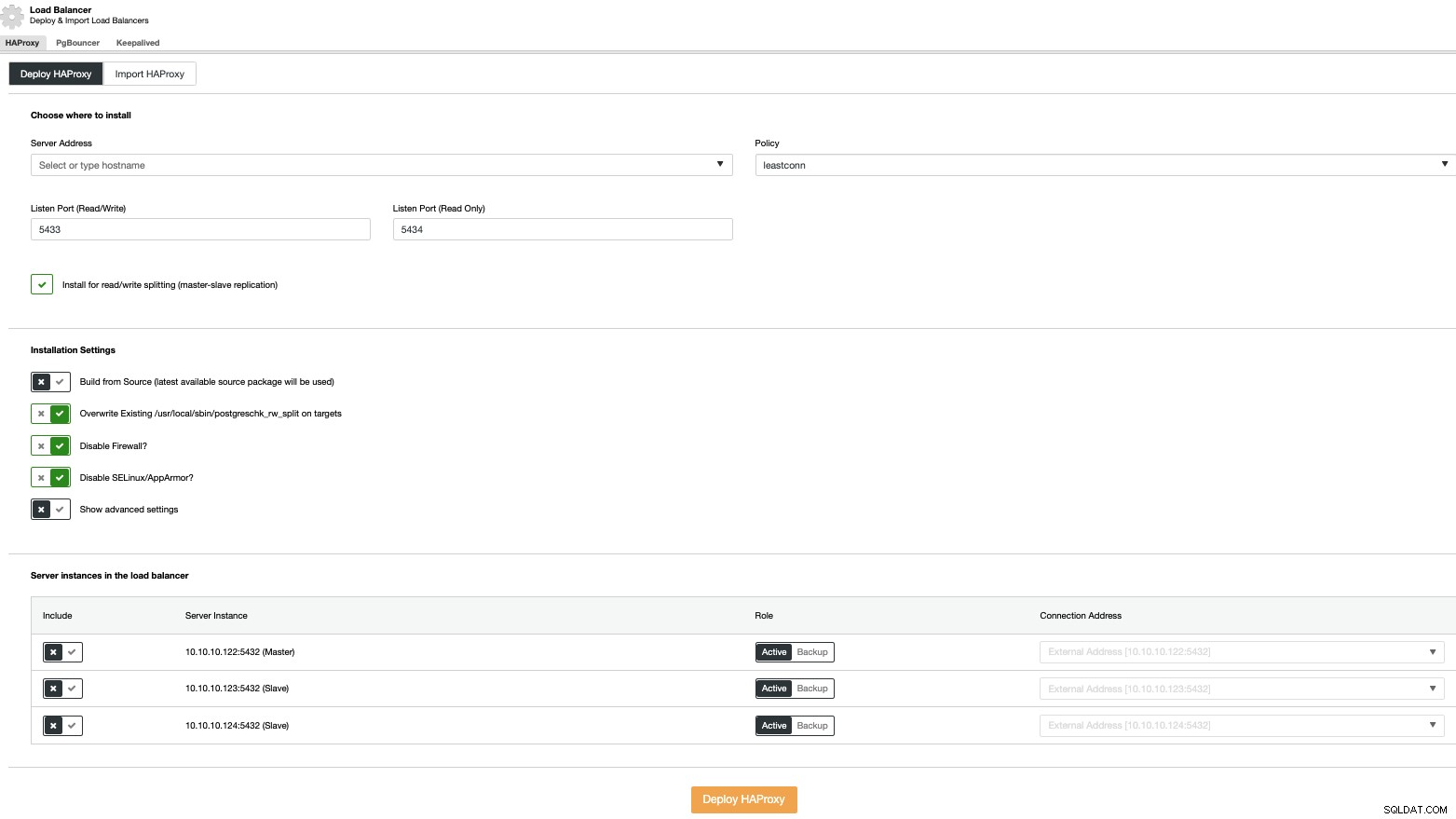
Wystarczy dodać adres IP lub nazwę hosta, port, zasady, oraz węzły, które skonfigurujesz w swoich systemach równoważenia obciążenia.
Utrzymywane wdrażanie
Aby przeprowadzić wdrożenie z podtrzymaniem, wybierz klaster, przejdź do menu „Zarządzaj” i sekcji „Load Balancer”, a następnie wybierz opcję „Zachowaj aktywność”.
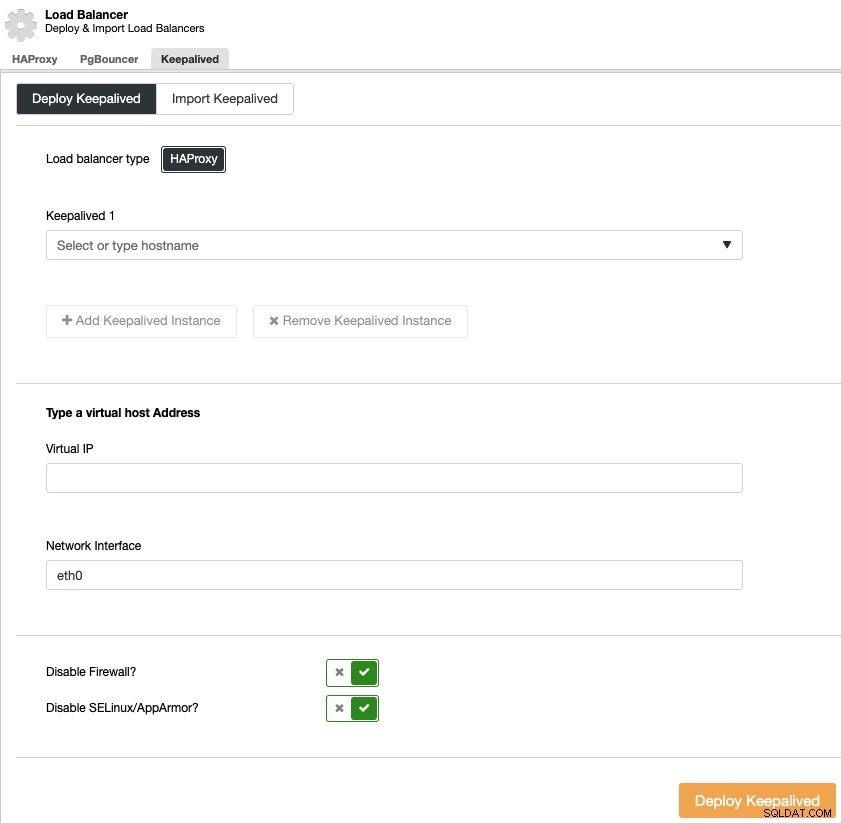
Musisz wybrać serwery równoważenia obciążenia i wirtualny adres IP dla swojego wysokiego środowisko dostępności.
Keepalived używa wirtualnego adresu IP i migruje go z jednego systemu równoważenia obciążenia do drugiego w przypadku awarii, aby Twoje systemy mogły nadal działać normalnie.
Jeśli wykonałeś poprzednie kroki, powinieneś mieć następującą topologię:
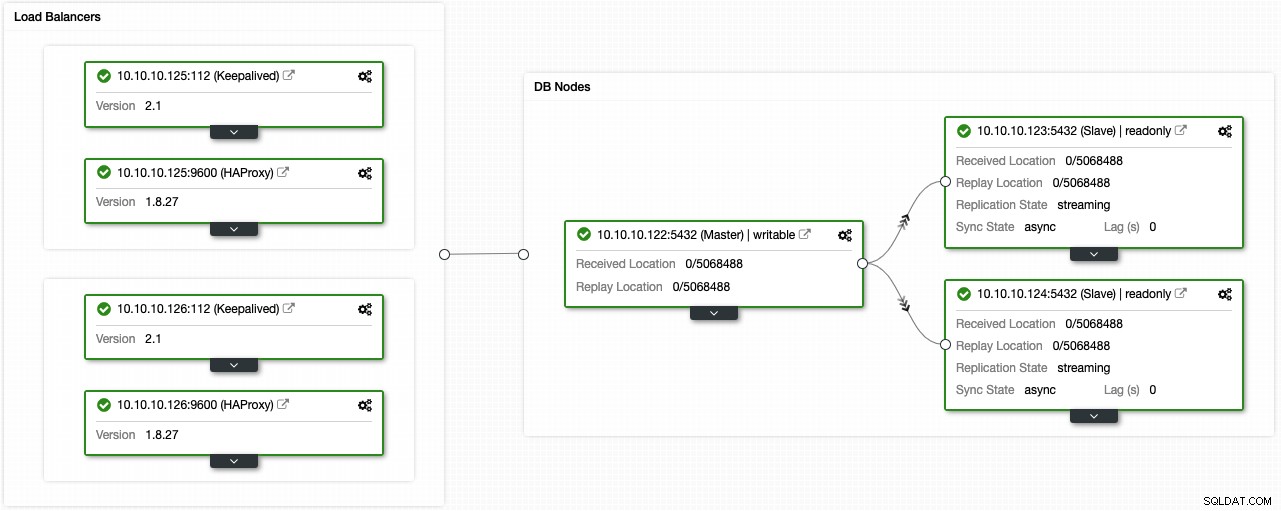
Możesz ulepszyć to środowisko wysokiej dostępności, dodając pulę połączeń, taką jak PgBouncer. Nie jest to konieczne, ale może być pomocne w poprawie wydajności i obsłudze aktywnych połączeń w przypadku awarii, a najlepsze jest to, że możesz go również wdrożyć za pomocą ClusterControl.
Przełączanie awaryjne ClusterControl
Załóżmy, że opcja „Autoodzyskiwanie” jest WŁĄCZONA na serwerze ClusterControl. W przypadku awarii głównej, ClusterControl przeniesie najbardziej zaawansowany tryb gotowości (jeśli nie znajduje się na czarnej liście) do podstawowego, a także powiadomi Cię o problemie. Przełączy również awaryjnie pozostałe węzły w trybie gotowości w celu replikacji z nowego głównego.
HAProxy jest domyślnie skonfigurowane z dwoma różnymi portami; porty do odczytu i zapisu oraz tylko do odczytu.
W swoim porcie do odczytu i zapisu serwer główny jest w trybie online, a pozostałe węzły w trybie offline, a na porcie tylko do odczytu masz zarówno tryb główny, jak i tryb gotowości.
Gdy HAProxy wykryje, że jeden z węzłów — podstawowy lub w trybie gotowości — jest niedostępny, automatycznie oznacza go jako offline. Nie bierze go pod uwagę przy wysyłaniu do niego ruchu. Wykrywanie jest wykonywane przez skrypty sprawdzania kondycji, które ClusterControl konfiguruje podczas wdrażania. Sprawdzają one, czy instancje działają, czy są w trakcie odzyskiwania, czy są tylko do odczytu.
Gdy ClusterControl promuje stan wstrzymania do podstawowego, HAProxy oznacza stary główny jako offline dla obu portów i umieszcza promowany węzeł online w porcie do odczytu i zapisu.
Jeśli twój aktywny HAProxy, który przypisał wirtualny adres IP, z którym łączą się twoje systemy, ulegnie awarii, Keepalived automatycznie migruje ten adres IP do pasywnego HAProxy. Oznacza to, że Twoje systemy będą mogły dalej normalnie funkcjonować.
W ten sposób Twoje systemy będą nadal działać zgodnie z oczekiwaniami i bez Twojej ręcznej interwencji.
Rozważania
Jeśli uda Ci się odzyskać stary uszkodzony węzeł główny, NIE zostanie on domyślnie automatycznie ponownie wprowadzony do klastra. Musisz to zrobić ręcznie. Jednym z powodów jest to, że jeśli replika była opóźniona w momencie awarii, a ClusterControl doda starą podstawową do klastra, oznaczałoby to utratę informacji lub niespójność danych w węzłach. Możesz również szczegółowo przeanalizować problem. Jeśli ClusterControl właśnie ponownie wprowadził uszkodzony węzeł do klastra, prawdopodobnie utracisz informacje diagnostyczne.
Ponadto, jeśli przełączanie awaryjne nie powiedzie się, nie są podejmowane żadne dalsze próby. Do przeanalizowania problemu i wykonania odpowiednich czynności wymagana jest ręczna interwencja. Ma to na celu uniknięcie sytuacji, w której ClusterControl, jako menedżer wysokiej dostępności, próbuje promować następny tryb gotowości i następny. Może wystąpić problem i musisz to sprawdzić.
Bezpieczeństwo
Jedną ważną rzeczą, o której nie można zapomnieć przed rozpoczęciem produkcji w środowisku wysokiej dostępności, jest zapewnienie jego bezpieczeństwa.
Kilka aspektów bezpieczeństwa, które należy wziąć pod uwagę, obejmuje szyfrowanie, zarządzanie rolami i ograniczenia dostępu według adresu IP, które szczegółowo omówiliśmy w poprzednim blogu.
W swojej bazie danych PostgreSQL masz plik pg_hba.conf, który obsługuje uwierzytelnianie klienta. Możesz ograniczyć typ połączenia, źródłowy adres IP lub sieć, z którą bazą danych możesz się połączyć iz którymi użytkownikami. Dlatego ten plik jest krytycznym elementem bezpieczeństwa PostgreSQL.
Możesz skonfigurować bazę danych PostgreSQL z pliku postgresql.conf, aby nasłuchiwała tylko na określonym interfejsie sieciowym i innym porcie niż domyślny (5432), unikając w ten sposób podstawowych prób połączenia z niechcianych źródeł .
Właściwe zarządzanie użytkownikami, przy użyciu bezpiecznych haseł lub ograniczanie dostępu i uprawnień, to kolejny ważny element ustawień bezpieczeństwa. Zaleca się przypisanie jak najmniejszej możliwej liczby uprawnień wszystkim użytkownikom i określenie, jeśli to możliwe, źródła połączenia.
Możesz także włączyć szyfrowanie danych podczas przesyłania lub w spoczynku, aby uniknąć dostępu do informacji osobom nieupoważnionym.
Dziennik audytu jest pomocny w zrozumieniu, co się dzieje lub co wydarzyło się w Twojej bazie danych. PostgreSQL umożliwia skonfigurowanie kilku parametrów logowania, a nawet użycie rozszerzenia pgAudit do tego zadania.
Ostatnie, ale nie mniej ważne, zaleca się aktualizowanie bazy danych i serwerów za pomocą najnowszych poprawek, aby uniknąć zagrożeń bezpieczeństwa. W tym celu ClusterControl umożliwia generowanie raportów operacyjnych w celu sprawdzenia, czy masz dostępne aktualizacje, a nawet pomaga zaktualizować serwery baz danych.
Wnioski
Wdrożenia o wysokiej dostępności mogą wydawać się trudne do osiągnięcia, szczególnie jeśli chodzi o zrozumienie różnych architektur i niezbędnych komponentów do ich prawidłowej konfiguracji.
Jeśli zarządzasz HA ręcznie, koniecznie sprawdź Wykonywanie zmian w topologii replikacji dla PostgreSQL. Wiele osób będzie szukać narzędzi, takich jak ClusterControl, które pomogą w zarządzaniu wdrażaniem, systemami równoważenia obciążenia, przełączaniem awaryjnym, bezpieczeństwem i nie tylko w celu uzyskania pełnego środowiska wysokiej dostępności. Możesz pobrać ClusterControl za darmo przez 30 dni, aby zobaczyć, jak może zmniejszyć obciążenie związane z zarządzaniem infrastrukturą bazy danych o wysokiej dostępności.
Niezależnie od tego, czy zdecydujesz się zarządzać swoimi bazami danych PostgreSQL o wysokiej dostępności, pamiętaj, aby śledzić nas na Twitterze lub LinkedIn lub zasubskrybuj nasz biuletyn, aby otrzymywać najnowsze aktualizacje i najlepsze praktyki zarządzania konfiguracjami baz danych.