Często, gdy piszemy procedurę składowaną, chcemy, aby zachowywała się na różne sposoby w zależności od danych wejściowych użytkownika. Spójrzmy na następujący przykład:
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Ta procedura składowana, którą stworzyłem w bazie danych AdventureWorks2017, ma dwa parametry:@CustomerID i @SortOrder. Pierwszy parametr, @CustomerID, wpływa na zwracane wiersze. Jeśli określony identyfikator klienta jest przekazywany do procedury składowanej, zwraca ona wszystkie zamówienia (top 10) dla tego klienta. W przeciwnym razie, jeśli ma wartość NULL, procedura składowana zwraca wszystkie zamówienia (top 10), niezależnie od klienta. Drugi parametr, @SortOrder, określa sposób sortowania danych — według OrderDate lub SalesOrderID. Zauważ, że tylko pierwszych 10 wierszy zostanie zwróconych zgodnie z porządkiem sortowania.
Tak więc użytkownicy mogą wpływać na zachowanie zapytania na dwa sposoby — które wiersze mają zwrócić i jak je posortować. Mówiąc dokładniej, istnieją 4 różne zachowania dla tego zapytania:
- Zwróć 10 pierwszych wierszy dla wszystkich klientów posortowanych według daty zamówienia (zachowanie domyślne)
- Zwróć 10 pierwszych wierszy dla konkretnego klienta posortowanych według daty zamówienia
- Zwróć 10 pierwszych wierszy dla wszystkich klientów posortowanych według SalesOrderID
- Zwróć 10 pierwszych wierszy dla określonego klienta posortowanych według SalesOrderID
Przetestujmy procedurę składowaną ze wszystkimi 4 opcjami i zbadajmy plan wykonania oraz IO statystyk.
Zwróć 10 najlepszych wierszy dla wszystkich klientów posortowanych według daty zamówienia
Poniżej znajduje się kod do wykonania procedury składowanej:
EXECUTE Sales.GetOrders; GO
Oto plan wykonania:
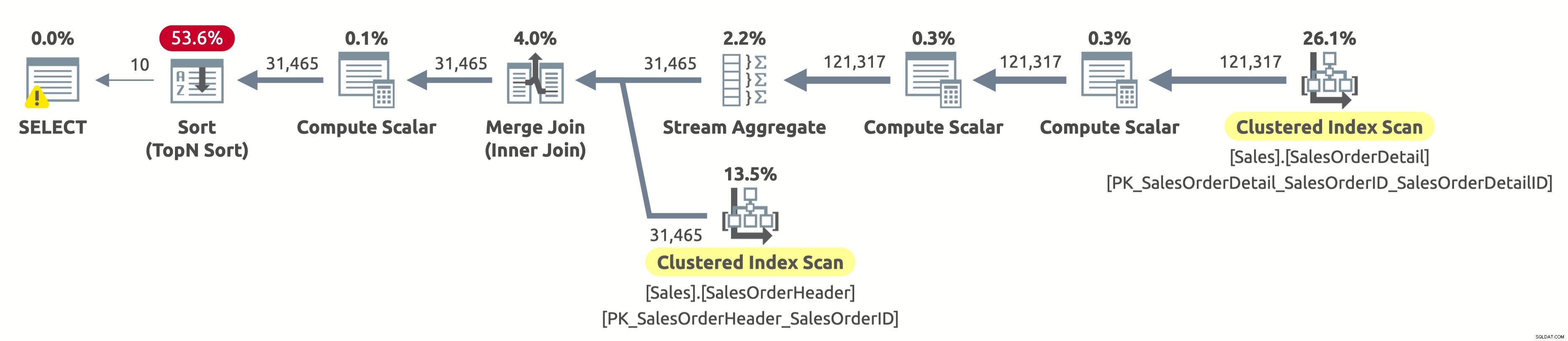
Ponieważ nie przefiltrowaliśmy według klienta, musimy zeskanować całą tabelę. Optymalizator wybrał skanowanie obu tabel przy użyciu indeksów na SalesOrderID, co pozwoliło na wydajną agregację strumienia, a także wydajne łączenie scalające.
Jeśli sprawdzisz właściwości operatora Clustered Index Scan w tabeli Sales.SalesOrderHeader, znajdziesz następujący predykat:[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] jako [SalesOrders].[CustomerID]=[ @CustomerID] LUB [@CustomerID] JEST NULL. Procesor zapytań musi ocenić ten predykat dla każdego wiersza w tabeli, co nie jest zbyt wydajne, ponieważ zawsze będzie oceniane jako prawda.
Nadal musimy posortować wszystkie dane według daty zamówienia, aby zwrócić pierwszych 10 wierszy. Gdyby istniał indeks w OrderDate, to optymalizator prawdopodobnie użyłby go do zeskanowania tylko pierwszych 10 wierszy z Sales.SalesOrderHeader, ale takiego indeksu nie ma, więc plan wydaje się w porządku, biorąc pod uwagę dostępne indeksy.
Oto wynik statystyk IO:
- Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 689
- Tabela „Szczegóły zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 1248
Jeśli pytasz, dlaczego jest ostrzeżenie dla operatora SELECT, oznacza to, że jest to ostrzeżenie o nadmiernym przyznaniu. W tym przypadku nie jest to spowodowane problemem w planie wykonania, ale raczej tym, że procesor zapytań zażądał 1024 KB (co jest domyślnie minimum) i użył tylko 16 KB.
Czasami buforowanie planu nie jest dobrym pomysłem
Następnie chcemy przetestować scenariusz zwracania 10 pierwszych wierszy dla konkretnego klienta posortowanych według daty zamówienia. Poniżej znajduje się kod:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Plan wykonania jest dokładnie taki sam jak poprzednio. Tym razem plan jest bardzo nieefektywny, ponieważ skanuje obie tabele tylko po to, aby zwrócić 3 zamówienia. Istnieją znacznie lepsze sposoby wykonania tego zapytania.
Powodem w tym przypadku jest buforowanie planu. Plan wykonania został wygenerowany w pierwszym wykonaniu na podstawie wartości parametrów w tym konkretnym wykonaniu — metoda znana jako wąchanie parametrów. Ten plan był przechowywany w pamięci podręcznej planów do ponownego wykorzystania i od teraz każde wywołanie tej procedury składowanej będzie ponownie wykorzystywać ten sam plan.
To jest przykład, w którym buforowanie planu nie jest dobrym pomysłem. Ze względu na charakter tej procedury składowanej, która ma 4 różne zachowania, spodziewamy się uzyskać inny plan dla każdego zachowania. Ale utknęliśmy z jednym planem, który jest dobry tylko dla jednej z 4 opcji, w oparciu o opcję użytą w pierwszym wykonaniu.
Wyłączmy buforowanie planu dla tej procedury składowanej, aby zobaczyć najlepszy plan, jaki może wymyślić optymalizator dla każdego z pozostałych 3 zachowań. Zrobimy to, dodając WITH RECOMPILE do polecenia EXECUTE.
Zwróć 10 najlepszych wierszy dla konkretnego klienta posortowanych według daty zamówienia
Poniżej znajduje się kod do zwrócenia 10 pierwszych wierszy dla konkretnego klienta posortowanych według daty zamówienia:
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Poniżej znajduje się plan wykonania:
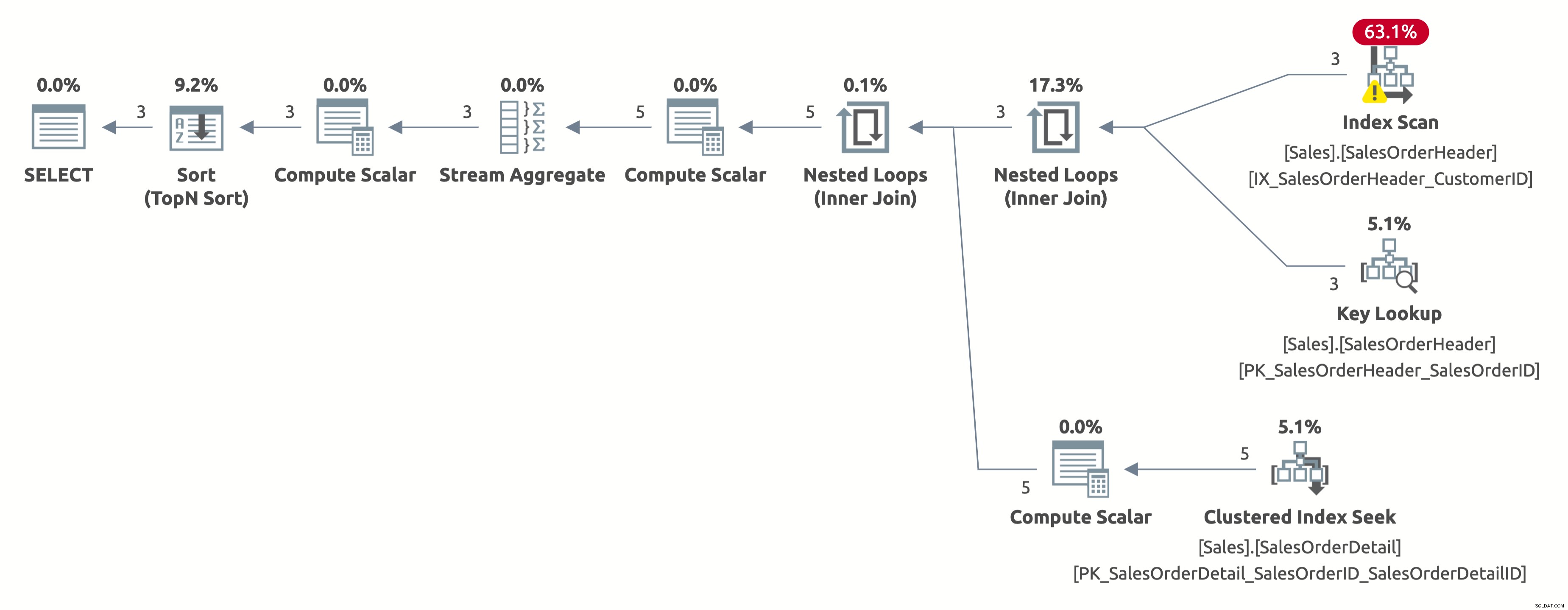
Tym razem otrzymujemy lepszy plan, który wykorzystuje indeks na CustomerID. Optymalizator poprawnie szacuje 2,6 wiersza dla CustomerID =11006 (rzeczywista liczba to 3). Ale zauważ, że wykonuje skanowanie indeksu zamiast wyszukiwania indeksu. Nie może przeprowadzić wyszukiwania indeksu, ponieważ musi ocenić następujący predykat dla każdego wiersza w tabeli:[AdventureWorks2017].[Sales].[SalesOrderHeader].[IDKlienta] jako [ZamówieniaSprzedaży].[IDKlienta]=[@IDKlienta]. ] LUB [@CustomerID] JEST NULL.
Oto wynik statystyk IO:
- Tabela „Szczegóły zamówienia sprzedaży”. Liczba skanów 3, odczyty logiczne 9
- Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 66
Zwróć 10 najlepszych wierszy dla wszystkich klientów posortowanych według SalesOrderID
Poniżej znajduje się kod zwracający 10 pierwszych wierszy dla wszystkich klientów posortowanych według SalesOrderID:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Poniżej znajduje się plan wykonania:
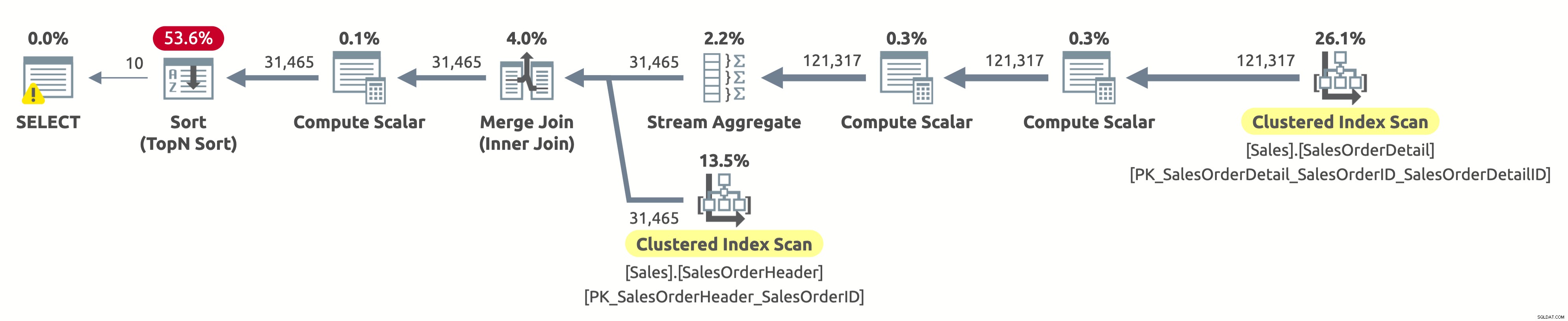
Hej, to jest ten sam plan wykonania, co w pierwszej opcji. Ale tym razem coś jest nie tak. Wiemy już, że klastrowane indeksy w obu tabelach są sortowane według SalesOrderID. Wiemy również, że plan skanuje oba z nich w logicznej kolejności, aby zachować porządek sortowania (właściwość Ordered jest ustawiona na True). Operator Merge Join również zachowuje porządek sortowania. Ponieważ teraz prosimy o posortowanie wyniku według SalesOrderID i jest on już posortowany w ten sposób, dlaczego musimy płacić za drogiego operatora sortowania?
Cóż, jeśli zaznaczysz operator Sort, zauważysz, że sortuje dane zgodnie z Expr1004. A jeśli zaznaczysz operator Oblicz skalarny po prawej stronie operatora Sort, odkryjesz, że Wyr1004 wygląda następująco:

Wiem, że to nie jest ładny widok. Jest to wyrażenie, które mamy w klauzuli ORDER BY naszego zapytania. Problem polega na tym, że optymalizator nie może ocenić tego wyrażenia w czasie kompilacji, więc musi obliczyć je dla każdego wiersza w czasie wykonywania, a następnie na tej podstawie posortować cały zestaw rekordów.
Wyjście statystyk IO jest takie samo jak w pierwszym wykonaniu:
- Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 689
- Tabela „Szczegóły zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 1248
Zwróć 10 pierwszych wierszy dla określonego klienta posortowanych według SalesOrderID
Poniżej znajduje się kod do zwrócenia 10 pierwszych wierszy dla określonego klienta posortowanych według SalesOrderID:
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Plan realizacji jest taki sam jak w przypadku drugiej opcji (zwróć 10 górnych wierszy dla konkretnego klienta posortowane według OrderDate). Plan ma te same dwa problemy, o których już wspomnieliśmy. Pierwszym problemem jest wykonanie skanowania indeksu, a nie wyszukiwania indeksu ze względu na wyrażenie w klauzuli WHERE. Drugim problemem jest wykonanie kosztownego sortowania ze względu na wyrażenie w klauzuli ORDER BY.
Więc, co powinniśmy zrobić?
Przypomnijmy sobie najpierw, z czym mamy do czynienia. Mamy parametry, które określają strukturę zapytania. Dla każdej kombinacji wartości parametrów otrzymujemy inną strukturę zapytania. W przypadku parametru @CustomerID dwa różne zachowania mają wartość NULL lub NOT NULL i wpływają na klauzulę WHERE. W przypadku parametru @SortOrder możliwe są dwie wartości, które wpływają na klauzulę ORDER BY. Rezultatem są 4 możliwe struktury zapytań i chcielibyśmy otrzymać inny plan dla każdej z nich.
Następnie mamy dwa różne problemy. Pierwszym z nich jest buforowanie planu. Dla procedury składowanej istnieje tylko jeden plan, który zostanie wygenerowany na podstawie wartości parametrów w pierwszym wykonaniu. Drugi problem polega na tym, że nawet po wygenerowaniu nowego planu nie jest on wydajny, ponieważ optymalizator nie może ocenić „dynamicznych” wyrażeń w klauzuli WHERE i klauzuli ORDER BY w czasie kompilacji.
Możemy spróbować rozwiązać te problemy na kilka sposobów:
- Użyj serii instrukcji JEŻELI-ELSE
- Podziel procedurę na oddzielne procedury składowane
- Użyj OPCJI (REKOMPILUJ)
- Generuj zapytanie dynamicznie
Użyj serii instrukcji IF-ELSE
Pomysł jest prosty:zamiast „dynamicznych” wyrażeń w klauzuli WHERE iw klauzuli ORDER BY, możemy podzielić wykonanie na 4 gałęzie za pomocą instrukcji IF-ELSE — jedna gałąź dla każdego możliwego zachowania.
Na przykład, poniżej znajduje się kod dla pierwszej gałęzi:
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Takie podejście może pomóc w generowaniu lepszych planów, ale ma pewne ograniczenia.
Po pierwsze, procedura składowana staje się dość długa i trudniej ją pisać, czytać i konserwować. I wtedy mamy tylko dwa parametry. Gdybyśmy mieli 3 parametry, mielibyśmy 8 gałęzi. Wyobraź sobie, że musisz dodać kolumnę do klauzuli SELECT. Musiałbyś dodać kolumnę w 8 różnych zapytaniach. Staje się koszmarem konserwacyjnym, z wysokim ryzykiem błędu ludzkiego.
Po drugie, nadal w pewnym stopniu mamy problem z buforowaniem planu i sniffowaniem parametrów. Dzieje się tak, ponieważ w pierwszym wykonaniu optymalizator wygeneruje plan dla wszystkich 4 zapytań na podstawie wartości parametrów w tym wykonaniu. Załóżmy, że pierwsze wykonanie będzie używało domyślnych wartości parametrów. W szczególności wartość @CustomerID będzie wynosić NULL. Wszystkie zapytania zostaną zoptymalizowane na podstawie tej wartości, w tym zapytanie z klauzulą WHERE (SalesOrders.CustomerID =@CustomerID). Optymalizator oszacuje 0 wierszy dla tych zapytań. Załóżmy teraz, że drugie wykonanie będzie używać wartości innej niż null dla @CustomerID. Zostanie użyty plan z pamięci podręcznej, który szacuje 0 wierszy, nawet jeśli klient może mieć wiele zamówień w tabeli.
Podziel procedurę na oddzielne przechowywane procedury
Zamiast 4 gałęzi w ramach tej samej procedury składowanej możemy utworzyć 4 oddzielne procedury składowane, każda z odpowiednimi parametrami i odpowiednim zapytaniem. Następnie możemy albo przepisać aplikację, aby zdecydować, którą procedurę składowaną wykonać zgodnie z pożądanymi zachowaniami. Lub, jeśli chcemy, aby była przezroczysta dla aplikacji, możemy przepisać oryginalną procedurę składowaną, aby zdecydować, którą procedurę wykonać na podstawie wartości parametrów. Zamierzamy użyć tych samych instrukcji JEŻELI-ELSE, ale zamiast wykonywać zapytanie w każdej gałęzi, wykonamy oddzielną procedurę składowaną.
Zaletą jest to, że rozwiązujemy problem z buforowaniem planu, ponieważ każda procedura składowana ma teraz swój własny plan, a plan dla każdej procedury składowanej zostanie wygenerowany przy pierwszym wykonaniu na podstawie podsłuchiwania parametrów.
Ale nadal mamy problem z utrzymaniem. Niektórzy mogą powiedzieć, że teraz jest jeszcze gorzej, ponieważ musimy utrzymywać wiele procedur składowanych. Ponownie, jeśli zwiększymy liczbę parametrów do 3, otrzymalibyśmy 8 odrębnych procedur składowanych.
Użyj OPCJI (REKOMPILUJ)
OPCJA (RECOMPILE) działa jak magia. Wystarczy wypowiedzieć słowa (lub dołączyć je do zapytania), a dzieje się magia. Naprawdę rozwiązuje tak wiele problemów, ponieważ kompiluje zapytanie w czasie wykonywania i robi to przy każdym wykonaniu.
Ale musisz być ostrożny, ponieważ wiesz, co mówią:„Z wielką mocą wiąże się wielka odpowiedzialność”. Jeśli używasz OPCJI (RECOMPILE) w zapytaniu, które jest wykonywane bardzo często w zajętym systemie OLTP, możesz zabić system, ponieważ serwer musi skompilować i wygenerować nowy plan przy każdym wykonaniu, zużywając dużo zasobów procesora. To naprawdę niebezpieczne. Jeśli jednak zapytanie jest wykonywane tylko raz na jakiś czas, powiedzmy raz na kilka minut, to prawdopodobnie jest bezpieczne. Ale zawsze testuj wpływ w swoim konkretnym środowisku.
W naszym przypadku, zakładając, że możemy bezpiecznie użyć OPCJI (RECOMPILE), wystarczy dodać magiczne słowa na końcu zapytania, jak pokazano poniżej:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Zobaczmy teraz, jak działa magia. Na przykład, poniżej przedstawiono plan drugiego zachowania:
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
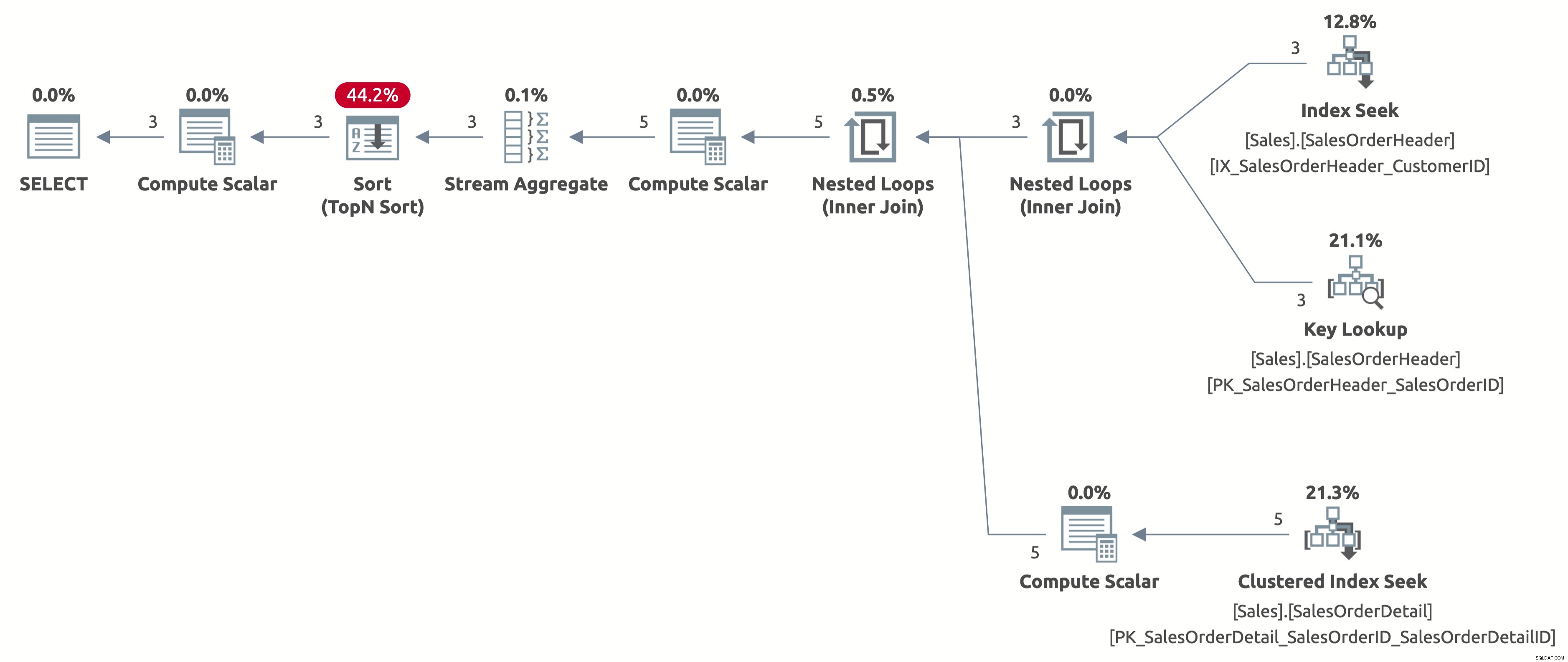
Teraz otrzymujemy wydajne wyszukiwanie indeksu z poprawnym oszacowaniem 2,6 wierszy. Nadal musimy sortować według daty zamówienia, ale teraz sortowanie odbywa się bezpośrednio według daty zamówienia i nie musimy już obliczać wyrażenia CASE w klauzuli ORDER BY. Jest to najlepszy możliwy plan dla tego zachowania zapytań w oparciu o dostępne indeksy.
Oto wynik statystyk IO:
- Tabela „Szczegóły zamówienia sprzedaży”. Liczba skanów 3, odczyty logiczne 9
- Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 11
Powodem, dla którego OPCJA (RECOMPILE) jest tak wydajna w tym przypadku, jest to, że rozwiązuje dokładnie dwa problemy, które tutaj mamy. Pamiętaj, że pierwszym problemem jest buforowanie planu. OPCJA (RECOMPILE) całkowicie eliminuje ten problem, ponieważ za każdym razem ponownie kompiluje zapytanie. Drugim problemem jest niezdolność optymalizatora do oceny złożonego wyrażenia w klauzuli WHERE iw klauzuli ORDER BY w czasie kompilacji. Ponieważ OPCJA (RECOMPILE) ma miejsce w czasie wykonywania, rozwiązuje problem. Ponieważ w czasie wykonywania optymalizator ma o wiele więcej informacji w porównaniu z czasem kompilacji, a to robi różnicę.
Zobaczmy teraz, co się stanie, gdy wypróbujemy trzecie zachowanie:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
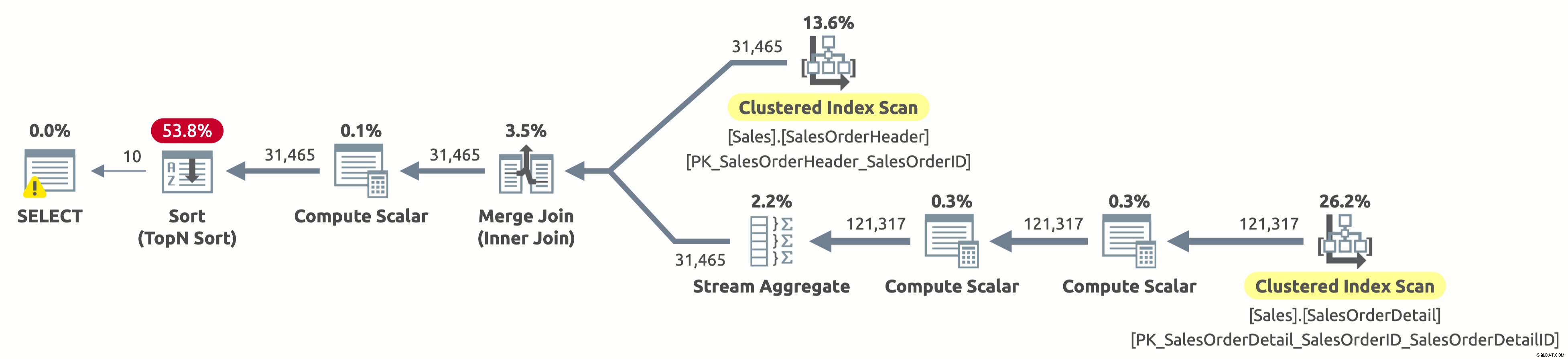
Houston, mamy problem. Plan nadal skanuje całkowicie obie tabele, a następnie sortuje wszystko, zamiast skanować tylko pierwszych 10 wierszy z Sales.SalesOrderHeader i całkowicie unikać sortowania. Co się stało?
Jest to interesujący „przypadek” związany z wyrażeniem CASE w klauzuli ORDER BY. Wyrażenie CASE ocenia listę warunków i zwraca jedno z wyrażeń wynikowych. Ale wyrażenia wynikowe mogą mieć różne typy danych. Jaki byłby typ danych całego wyrażenia CASE? Cóż, wyrażenie CASE zawsze zwraca typ danych o najwyższym priorytecie. W naszym przypadku kolumna OrderDate ma typ danych DATETIME, natomiast kolumna SalesOrderID ma typ danych INT. Typ danych DATETIME ma wyższy priorytet, więc wyrażenie CASE zawsze zwraca DATETIME.
Oznacza to, że jeśli chcemy sortować według SalesOrderID, wyrażenie CASE musi najpierw niejawnie przekonwertować wartość SalesOrderID na DATETIME dla każdego wiersza przed jego posortowaniem. Czy widzisz operator Compute Scalar po prawej stronie operatora Sort w powyższym planie? Właśnie to robi.
Jest to problem sam w sobie i pokazuje, jak niebezpieczne może być mieszanie różnych typów danych w jednym wyrażeniu CASE.
Możemy obejść ten problem, przepisując klauzulę ORDER BY na inne sposoby, ale sprawiłoby to, że kod byłby jeszcze bardziej brzydki i trudny do odczytania i utrzymania. Więc nie pójdę w tym kierunku.
Zamiast tego wypróbujmy następną metodę…
Generuj zapytanie dynamicznie
Ponieważ naszym celem jest wygenerowanie 4 różnych struktur zapytań w jednym zapytaniu, dynamiczny SQL może być w tym przypadku bardzo przydatny. Pomysł polega na dynamicznym budowaniu zapytania na podstawie wartości parametrów. W ten sposób możemy zbudować 4 różne struktury zapytań w jednym kodzie, bez konieczności utrzymywania 4 kopii zapytania. Każda struktura zapytania zostanie skompilowana raz, przy pierwszym wykonaniu, i otrzyma najlepszy plan, ponieważ nie zawiera żadnych złożonych wyrażeń.
To rozwiązanie jest bardzo podobne do rozwiązania z wieloma procedurami składowanymi, ale zamiast utrzymywać 8 procedur składowanych dla 3 parametrów, utrzymujemy tylko jeden kod, który dynamicznie buduje zapytanie.
Wiem, że dynamiczny SQL jest również brzydki i czasami może być dość trudny w utrzymaniu, ale myślę, że nadal jest to łatwiejsze niż utrzymywanie wielu procedur składowanych i nie skaluje się wykładniczo wraz ze wzrostem liczby parametrów.
Oto kod:
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Zauważ, że nadal używam wewnętrznego parametru dla identyfikatora klienta i wykonuję dynamiczny kod za pomocą sys.sp_executesql aby przekazać wartość parametru. Jest to ważne z dwóch powodów. Po pierwsze, aby uniknąć wielu kompilacji tej samej struktury zapytania dla różnych wartości @CustomerID. Po drugie, aby uniknąć wstrzyknięcia SQL.
Jeśli spróbujesz teraz wykonać procedurę składowaną przy użyciu różnych wartości parametrów, zobaczysz, że każde zachowanie lub struktura zapytania otrzymuje najlepszy plan wykonania, a każdy z 4 planów jest kompilowany tylko raz.
Jako przykład, poniżej przedstawiono plan trzeciego zachowania:
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
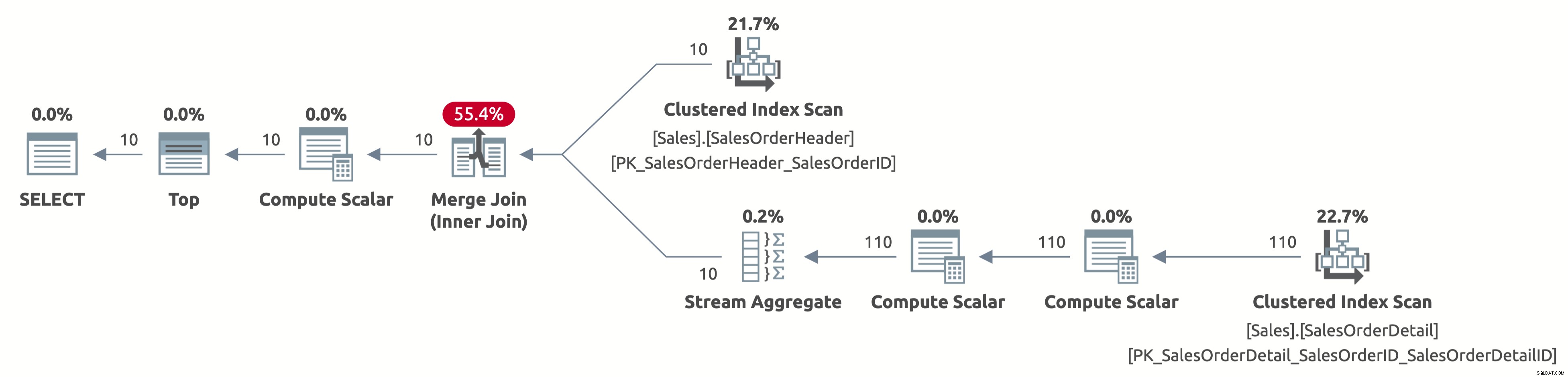
Teraz skanujemy tylko pierwszych 10 wierszy z tabeli Sales.SalesOrderHeader, a także skanujemy tylko pierwszych 110 wierszy z tabeli Sales.SalesOrderDetail. Ponadto nie ma operatora sortowania, ponieważ dane są już posortowane według SalesOrderID.
Oto wynik statystyk IO:
- Tabela „Szczegóły zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 4
- Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 1, odczyty logiczne 3
Wniosek
Gdy używasz parametrów do zmiany struktury zapytania, nie używaj złożonych wyrażeń w zapytaniu, aby uzyskać oczekiwane zachowanie. W większości przypadków prowadzi to do słabej wydajności i nie bez powodu. Pierwszym powodem jest to, że plan zostanie wygenerowany na podstawie pierwszego wykonania, a następnie wszystkie kolejne wykonania będą ponownie wykorzystywać ten sam plan, który jest odpowiedni tylko dla jednej struktury zapytania. Drugim powodem jest to, że optymalizator ma ograniczone możliwości oceny tych złożonych wyrażeń w czasie kompilacji.
Istnieje kilka sposobów na przezwyciężenie tych problemów i przeanalizowaliśmy je w tym artykule. W większości przypadków najlepszą metodą byłoby dynamiczne budowanie zapytania na podstawie wartości parametrów. W ten sposób każda struktura zapytania zostanie skompilowana raz z najlepszym możliwym planem.
Kiedy tworzysz zapytanie za pomocą dynamicznego SQL, upewnij się, że używasz parametrów tam, gdzie jest to właściwe, i sprawdź, czy Twój kod jest bezpieczny.