Replikacja to współużytkowanie danych transakcyjnych na wielu serwerach w celu zapewnienia spójności między nadmiarowymi węzłami bazy danych. Master weźmie inserty lub aktualizacje i zastosuje je do swojego zestawu danych, podczas gdy slave zmieni swoje dane zgodnie ze zmianami dokonanymi w zestawie danych głównych. Master jest powszechnie określany jako podstawowy i rejestruje zmiany wprowadzone w dzienniku zapisu z wyprzedzeniem (WAL). Z drugiej strony, urządzenia podrzędne są określane jako drugorzędne i replikują swoje dane z dzienników REDO - w tym przypadku WAL.
Istnieją co najmniej 3 podejścia do replikacji w PostgreSQL:
Wbudowana replikacja lub replikacja strumieniowa.
W tym podejściu dane są replikowane z węzła podstawowego do węzła drugorzędnego. Ma jednak kilka niepowodzeń, które są:
- Trudności we wprowadzeniu nowego drugorzędnego. Będzie to wymagało zreplikowania całego stanu, co może wymagać dużych zasobów.
- Brak wbudowanego monitorowania i przełączania awaryjnego. Drugorzędny musi być promowany do podstawowego w przypadku tego ostatniego niepowodzenia. Często ta promocja może spowodować niespójność danych podczas nieobecności głównego.
Rekonstrukcja z WAL
To podejście w jakiś sposób wykorzystuje podejście replikacji strumieniowej, ponieważ wtórne są rekonstruowane z kopii zapasowej wykonanej przez podstawową. Podstawowa wykonuje pełną kopię zapasową bazy danych każdego dnia, oprócz tworzenia kopii przyrostowej co 60 sekund. Zaletą tego podejścia jest to, że podstawowemu nie jest poddawane żadne dodatkowe obciążenie, dopóki drugorzędne nie znajdą się wystarczająco blisko podstawowego, aby rozpocząć przesyłanie strumieniowe dziennika zapisu z wyprzedzeniem (WAL) w celu nadrobienia zaległości. Dzięki takiemu podejściu możesz dodawać lub usuwać repliki bez wpływu na wydajność bazy danych PostgreSQL.
Replikacja na poziomie woluminu dla PostgreSQL (dublowanie dysku)
Jest to ogólne podejście, które dotyczy nie tylko PostgreSQL, ale także wszystkich relacyjnych baz danych. Wykorzystamy Distributed Replicated Block Device (DRBD), rozproszony, replikowany system pamięci masowej dla systemu Linux. Ma działać poprzez dublowanie zawartości przechowywanej w pamięci jednego serwera na innym. Poniżej przedstawiono prostą ilustrację struktury.
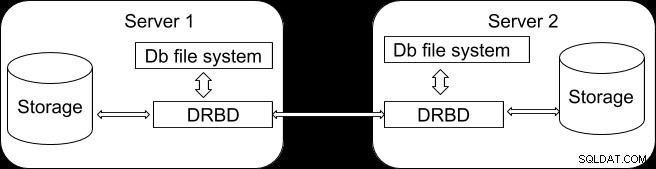
DRBD można uznać za abstrakcję od urządzenia dyskowego, na którym znajduje się baza danych PostgreSQL, ale system operacyjny nigdy nie dowie się, że jego dane znajdują się również na innym serwerze. Korzystając z tego podejścia, możesz nie tylko udostępniać dane, ale także system plików na więcej niż 1 serwerze. Zapisy do DRBD są zatem rozdzielone między wszystkie serwery, przy czym każdy serwer zapisuje informacje na lokalnym fizycznym dysku twardym (urządzenie blokowe). Gdy operacja zapisu jest stosowana do serwera podstawowego, jest następnie rejestrowana na DRBD, a następnie dystrybuowana do drugorzędnych serwerów DRBD. Z drugiej strony, jeśli drugorzędny odbiera operacje zapisu przez DRBD, są one następnie zapisywane na lokalnym urządzeniu fizycznym. W przypadku obsługi przełączania awaryjnego DRBD zapewnia wysoką dostępność danych, ponieważ informacje są dzielone między węzły główne i wiele węzłów drugorzędnych, które są połączone synchronicznie na poziomie bloku.
Konfiguracja DRBD wymagałaby dodatkowego zasobu znanego jako Heartbeat, który omówimy w innym artykule, w celu zwiększenia obsługi automatycznego przełączania awaryjnego. Pakiet zasadniczo zarządza interfejsem na wielu serwerach i automatycznie konfiguruje jeden z serwerów pomocniczych jako główny w przypadku awarii.
Instalacja i konfiguracja DRBD
Preferowaną metodą instalacji DRBD jest użycie prekompilowanych binarnych pakietów instalacyjnych. Upewnij się, że wersja pakietów jądra jest zgodna z twoim aktywnym bieżącym jądrem.
Pliki konfiguracyjne dla wszystkich węzłów, które są podstawowe lub drugorzędne, powinny być identyczne. Również jeśli konieczne jest zaktualizowanie wersji jądra, upewnij się, że odpowiedni moduł jądra-drdb jest dostępny dla nowej wersji jądra.
Konfiguracja DRBD dla węzła podstawowego
Jest to pierwszy krok, w którym będziesz musiał utworzyć urządzenie blokowe DRBD i system plików, w którym możesz przechowywać swoje dane. Plik konfiguracyjny można znaleźć w /etc/drbd.conf. Plik definiuje szereg parametrów konfiguracji DRBD, które obejmują:rozmiary bloków, definicję informacji bezpieczeństwa urządzeń DRBD, które chcesz utworzyć i częstotliwość aktualizacji. Konfiguracje mogą być ograniczone do globalnego lub powiązanego z określonym zasobem. Wymagane kroki to:
-
Szybkość synchronizacji, która określa szybkość, z jaką urządzenia są synchronicznie połączone w tle po wymianie dysku, awarii lub wstępnej konfiguracji. Można to ustawić, edytując parametr szybkości w bloku synchronizacji:
syncer{ rate 15M } -
Konfiguracja uwierzytelniania zapewniająca, że tylko hosty z tym samym wspólnym sekretem będą mogły dołączyć do grupy węzłów DRBD. Hasło jest mechanizmem wymiany skrótów obsługiwanym przez DRBD.
cram-hmac-alg “sha1” shared-secret “hash-password-string” -
Konfigurowanie informacji o hoście. Informacje o węźle, takie jak host, można znaleźć w pliku drbd.conf każdego węzła. Niektóre parametry do skonfigurowania to:
- Adres:adres IP i numer portu hosta, na którym znajduje się urządzenie DRBD.
- Urządzenie:ścieżka logicznego urządzenia blokowego utworzonego przez DRBD.
- Dysk:Odnosi się do urządzenia blokowego przechowującego dane.
- Meta-dysk:przechowuje metadane urządzenia DRBD. Jego rozmiar może wynosić do 128 MB. Możesz ustawić go jako dysk wewnętrzny, aby DRBD używał fizycznego urządzenia blokowego do przechowywania tych informacji w ostatnich sekcjach dysku.
Prosta konfiguracja dla podstawowego:
on drbd-one { device /dev/drbd0; disk /dev/sdd1; address 192.168.103.40:8080; meta-disk internal; }Konfiguracja musi zostać powtórzona z urządzeniami wtórnymi z adresem IP zgodnym z hostem korespondenta.
on drbd-two { device /dev/drbd0; disk /dev/sdd1; address 192.168.103.41:8080; meta-disk internal; } -
Tworzenie metadanych dla urządzeń za pomocą tego polecenia:
Ten proces jest obowiązkowy przed uruchomieniem węzła podstawowego.$ drbdadm create create-md all - Uruchom DRBD za pomocą tego polecenia:
Dzięki temu DRBD może uruchomić, zainicjować i utworzyć zdefiniowane urządzenia DRBD.$ /etc/init.d/drbd start - Oznacz nowe urządzenie jako podstawowe i zainicjuj je za pomocą tego polecenia:
Utwórz system plików na urządzeniu blokowym, aby można było używać standardowego urządzenia blokowego utworzonego przez DRBD.$ drbdadm -- --overwrite-data-of-peer primary all - Przygotuj system podstawowy do użycia, montując system plików. Te polecenia powinny to dla Ciebie przygotować:
$ mkdir /mnt/drbd $ mount /dev/drbd0 /mnt/drbd $ echo “DRBD Device” > /mnt/drbd/example_file
Konfiguracja DRBD dla węzła dodatkowego
Możesz wykonać te same kroki powyżej, z wyjątkiem tworzenia systemu plików na węźle drugorzędnym, ponieważ informacje są automatycznie przesyłane z węzła podstawowego.
-
Skopiuj plik /etc/drbd.conf z węzła podstawowego do węzła dodatkowego. Ten plik zawiera potrzebne informacje i konfigurację.
-
Na podstawowym urządzeniu dyskowym utwórz metadane DRBD za pomocą polecenia:
$ drbdadm create-md all -
Uruchom DRBD poleceniem:
DRBD rozpocznie kopiowanie danych z węzła głównego do węzła wtórnego, a czas zależy od rozmiaru przesyłanych danych. Jeśli przeglądasz plik /proc/drbd, możesz zobaczyć postęp.$ /etc/init.d/drbd start$ cat /proc/drbd version: 8.0.0 (api:80/proto:80) SVN Revision: 2947 build by example@sqldat.com, 2018-08-24 16:43:05 0: cs:SyncSource st:Primary/Secondary ds:UpToDate/Inconsistent C r--- ns:252284 nr:0 dw:0 dr:257280 al:0 bm:15 lo:0 pe:7 ua:157 ap:0 [==>.................] sync'ed: 12.3% (1845088/2097152)K finish: 0:06:06 speed: 4,972 (4,580) K/sec resync: used:1/31 hits:15901 misses:16 starving:0 dirty:0 changed:16 act_log: used:0/257 hits:0 misses:0 starving:0 dirty:0 changed:0 -
Monitoruj synchronizację za pomocą polecenia watch w określonych odstępach czasu
$ watch -n 10 ‘cat /proc/drbd‘
Zarządzanie instalacją DRBD
Aby śledzić stan urządzenia DRBD, używamy /proc/drbd.
Możesz ustawić stan wszystkich urządzeń lokalnych jako podstawowy za pomocą polecenia
$ drbdadm primary allUstaw jako urządzenie główne jako drugorzędne
$ drbdadm secondary allAby odłączyć węzły DRBD
$ drbdadm disconnect allPodłącz ponownie węzły DRBD
$ drbd connect allKonfigurowanie PostgreSQL dla DRBD
Wiąże się to z wyborem urządzenia, dla którego PostgreSQL będzie przechowywać dane. W przypadku nowej instalacji możesz wybrać instalację PostgreSQL całkowicie na urządzeniu DRBD lub katalogu danych, który ma znajdować się w nowym systemie plików i musi znajdować się w węźle podstawowym. Dzieje się tak, ponieważ węzeł podstawowy jest jedynym, który może zamontować system plików urządzenia DRBD w trybie odczytu/zapisu. Pliki danych Postgres są często archiwizowane w /var/lib/pgsql, podczas gdy pliki konfiguracyjne są przechowywane w /etc/sysconfig/pgsql.
Konfigurowanie PostgreSQL do korzystania z nowego urządzenia DRBD
-
Jeśli masz uruchomiony PostgreSQL, zatrzymaj go za pomocą tego polecenia:
$ /etc/init.d/postgresql -9.0 -
Zaktualizuj urządzenie DRBD za pomocą plików konfiguracyjnych za pomocą poleceń:
$ mkdir /mnt/drbd/pgsql/sysconfig $ cp /etc/sysconfig/pgsql/* /mnt/drbd/pgsql/sysconfig -
Zaktualizuj DRBD za pomocą katalogu danych PostgreSQL i plików systemowych za pomocą:
$ cp -pR /var/lib/pgsql /mnt/drbd/pgsql/data -
Utwórz dowiązanie symboliczne do nowego katalogu konfiguracyjnego w systemie plików urządzenia DRBD z /etc/sysconfig/pgsql za pomocą polecenia:
$ ln -s /mnt/drbd/pgsql/sysconfig /etc/sysconfig/pgsql -
Usuń katalog /var/lib/pgsql, odmontuj /mnt/drbd/pgsql i podłącz urządzenie drbd do /var/lib/pgsql.
-
Uruchom PostgreSQL poleceniem:
$ /etc/init.d/postgresql -9.0 start
Dane PostgreSQL powinny być teraz obecne w systemie plików działającym na twoim urządzeniu DRBD pod skonfigurowanym urządzeniem. Zawartość baz danych jest również kopiowana do drugorzędnego węzła DRBD, ale nie można uzyskać do niej dostępu, ponieważ urządzenie DRBD pracujące w węźle drugorzędnym może być nieobecne.
Ważne funkcje w podejściu DRBD
- Parametry strojenia są wysoce konfigurowalne.
- Istniejące wdrożenia można łatwo skonfigurować za pomocą DRBD bez utraty danych.
- Żądania odczytu są równo wyważone
- Uwierzytelnianie ze wspólnym sekretem zabezpiecza konfigurację i jej dane.



