Wprowadzenie
Niezależnie od technologii bazy danych, konieczne jest skonfigurowanie monitorowania, zarówno do wykrywania problemów i podejmowania działań, jak i po prostu do poznania aktualnego stanu naszych systemów.
W tym celu istnieje kilka narzędzi płatnych i bezpłatnych. W tym blogu skupimy się w szczególności na jednym:Nagios Core.
Co to jest Nagios Core?
Nagios Core to system Open Source do monitorowania hostów, sieci i usług. Pozwala konfigurować alerty i ma dla nich różne stany. Pozwala na implementację wtyczek opracowanych przez społeczność, a nawet pozwala nam konfigurować własne skrypty monitorujące.
Jak zainstalować Nagios?
Oficjalna dokumentacja pokazuje nam, jak zainstalować Nagios Core na systemach CentOS lub Ubuntu.
Zobaczmy przykład niezbędnych kroków do instalacji na CentOS 7.
Wymagane pakiety
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipPobierz Nagios Core, wtyczki Nagios i NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzDodaj użytkownika i grupę Nagios
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheInstalacja Nagios
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgInstalacja wtyczki Nagios i NRPE
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginDodajemy następujący wiersz na końcu naszego pliku /usr/local/nagios/etc/objects/command.cfg, aby używać NRPE podczas sprawdzania naszych serwerów:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Rozpoczyna się Nagios
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdDostęp do internetu
Tworzymy użytkownika, aby uzyskać dostęp do interfejsu internetowego i możemy wejść na stronę.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://Adres_IP/nagios/
 Dostęp do sieci Nagios
Dostęp do sieci Nagios Jak skonfigurować Nagios?
Teraz, gdy mamy zainstalowane nasze Nagios, możemy kontynuować konfigurację. W tym celu musimy przejść do lokalizacji odpowiadającej naszej instalacji, w naszym przykładzie /usr/local/nagios/etc.
Istnieje kilka różnych plików konfiguracyjnych, które musisz utworzyć lub edytować, zanim zaczniesz cokolwiek monitorować.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: Plik konfiguracyjny CGI zawiera szereg dyrektyw, które wpływają na działanie CGI. Zawiera również odniesienie do głównego pliku konfiguracyjnego, więc CGI wiedzą, jak skonfigurowałeś Nagios i gdzie przechowywane są definicje obiektów.
- htpasswd.users: Ten plik zawiera użytkowników utworzonych w celu uzyskania dostępu do interfejsu sieciowego Nagios.
- nagios.cfg: Główny plik konfiguracyjny zawiera szereg dyrektyw, które wpływają na działanie demona Nagios Core.
- obiekty: Podczas instalacji Nagios, w tym miejscu umieszczanych jest kilka przykładowych plików konfiguracyjnych obiektów. Możesz użyć tych przykładowych plików, aby zobaczyć, jak działa dziedziczenie obiektów i dowiedzieć się, jak definiować własne definicje obiektów. Obiekty to wszystkie elementy zaangażowane w logikę monitorowania i powiadomień.
- resource.cfg: Służy do określenia opcjonalnego pliku zasobów, który może zawierać definicje makr. Makra umożliwiają odwoływanie się do informacji o hostach, usługach i innych źródłach w twoich poleceniach.
W obrębie obiektów możemy znaleźć szablony, które można wykorzystać przy tworzeniu nowych obiektów. Na przykład widzimy, że w naszym pliku /usr/local/nagios/etc/objects/templates.cfg znajduje się szablon o nazwie linux-server, który zostanie użyty do dodania naszych serwerów.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Korzystając z tego szablonu, nasze hosty odziedziczą konfigurację bez konieczności określania ich pojedynczo na każdym dodanym serwerze.
Mamy również predefiniowane polecenia, kontakty i przedziały czasowe.
Polecenia będą używane przez Nagios do kontroli i to właśnie dodajemy w pliku konfiguracyjnym każdego serwera, aby go monitorować. Na przykład PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Mamy możliwość tworzenia kontaktów lub grup i określania alertów, do których chcę dotrzeć, do której osoby lub grupy.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}W przypadku naszych kontroli i alertów możemy skonfigurować w jakich godzinach i dniach chcemy je otrzymywać. Jeśli mamy usługę, która nie jest krytyczna, prawdopodobnie nie chcemy wstawać o świcie, więc dobrze byłoby ostrzegać tylko w godzinach pracy, aby tego uniknąć.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Zobaczmy teraz, jak dodać alerty do naszych Nagios.
Zamierzamy monitorować nasze serwery PostgreSQL, więc najpierw dodamy je jako hosty w naszym katalogu obiektów. Stworzymy 3 nowe pliki:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Następnie musimy dodać je do pliku nagios.cfg i tutaj mamy 2 opcje.
Dodaj nasze hosty (pliki cfg) jeden po drugim za pomocą zmiennej cfg_file (opcja domyślna) lub dodaj wszystkie pliki cfg, które mamy w katalogu za pomocą zmiennej cfg_dir.
Będziemy dodawać pliki jeden po drugim zgodnie z domyślną strategią.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgDzięki temu mamy monitorowanych naszych gospodarzy. Teraz musimy tylko dodać, jakie usługi chcemy monitorować. W tym celu użyjemy kilku już zdefiniowanych kontroli (check_ssh i check_ping) i dodamy kilka podstawowych kontroli systemu operacyjnego, takich jak obciążenie i miejsce na dysku, między innymi za pomocą NRPE.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentCo to jest NRPE?
Zdalny wykonawca wtyczek Nagios. To narzędzie pozwala nam uruchamiać wtyczki Nagios na zdalnym hoście w tak przejrzysty sposób, jak to tylko możliwe.
Aby z niego korzystać, musimy zainstalować serwer w każdym węźle, który chcemy monitorować, a nasz Nagios połączy się jako klient z każdym z nich, wykonując odpowiednią wtyczkę (wtyczki).
Jak zainstalować NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpeNastępnie edytujemy plik konfiguracyjny /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>I ponownie uruchamiamy usługę NRPE:
[example@sqldat.com ~]# systemctl restart nrpeMożemy przetestować połączenie, uruchamiając następujące polecenie z naszego serwera Nagios:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Jak monitorować PostgreSQL?
Podczas monitorowania PostgreSQL należy wziąć pod uwagę dwa główne obszary:system operacyjny i bazy danych.
W przypadku systemu operacyjnego NRPE ma skonfigurowane podstawowe kontrole, takie jak między innymi miejsce na dysku i obciążenie. Te sprawdzenia można bardzo łatwo włączyć w następujący sposób.
W naszych węzłach edytujemy plik /usr/local/nagios/etc/nrpe.cfg i przechodzimy do miejsca, w którym znajdują się następujące wiersze:
Poleceniecommand[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Nazwy w nawiasach kwadratowych to te, których użyjemy na naszym serwerze Nagios, aby umożliwić te sprawdzenia.
W naszym Nagios edytujemy pliki 3 węzłów:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgDodajemy te sprawdzenia, które widzieliśmy wcześniej, pozostawiając nasze pliki w następujący sposób:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}I ponownie uruchamiamy usługę nagios:
[example@sqldat.com ~]# systemctl start nagiosW tym momencie, jeśli przejdziemy do sekcji usług w interfejsie internetowym naszego Nagios, powinniśmy mieć coś takiego:
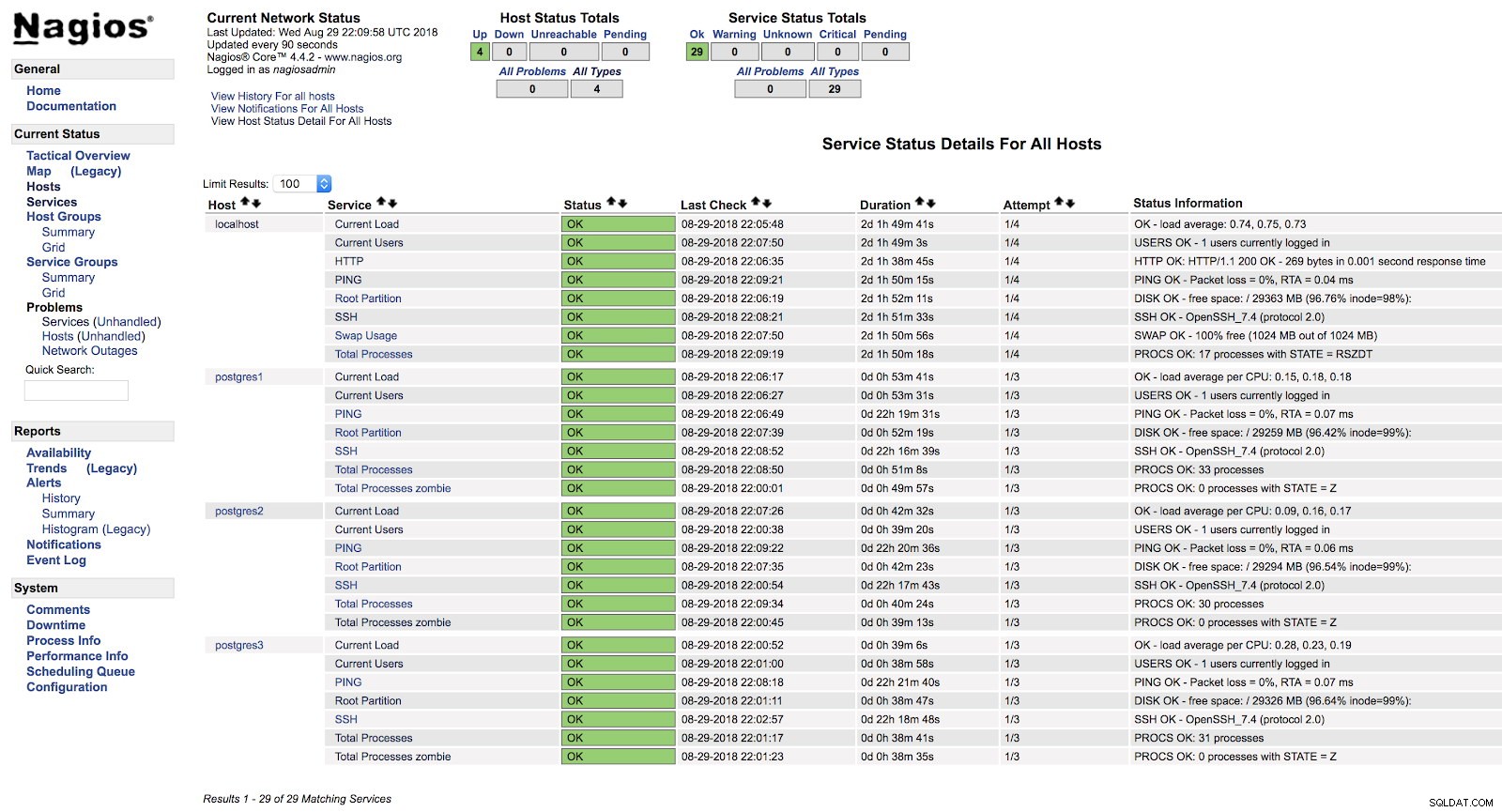 Alerty hosta Nagios
Alerty hosta Nagios W ten sposób omówimy podstawowe kontrole naszego serwera na poziomie systemu operacyjnego.
Mamy o wiele więcej sprawdzeń, które możemy dodać, a nawet możemy tworzyć własne sprawdzenia (przykład zobaczymy później).
Zobaczmy teraz, jak monitorować nasz silnik bazy danych PostgreSQL za pomocą dwóch głównych wtyczek zaprojektowanych do tego zadania.
Check_postgres
Jedną z najpopularniejszych wtyczek do sprawdzania PostgreSQL jest check_postgres firmy Bucardo.
Zobaczmy, jak go zainstalować i jak go używać z naszą bazą danych PostgreSQL.
Wymagane pakiety
[example@sqldat.com ~]# yum install perl-develInstalacja
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksTo ostatnie polecenie tworzy łącza umożliwiające korzystanie ze wszystkich funkcji tego sprawdzenia, takich jak między innymi check_postgres_connection, check_postgres_last_vacuum lub check_postgres_replication_slots.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Dodajemy w naszym pliku konfiguracyjnym NRPE (/usr/local/nagios/etc/nrpe.cfg) linię do wykonania sprawdzania, którego chcemy użyć:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100W naszym przykładzie dodaliśmy 4 podstawowe testy dla PostgreSQL. Będziemy monitorować blokady, wzdęcia, połączenia i backendy.
W pliku odpowiadającym naszej bazie danych na serwerze Nagios (/usr/local/nagios/etc/objects/postgres1.cfg) dodajemy następujące wpisy:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}A po ponownym uruchomieniu obu usług (NRPE i Nagios) na obu serwerach, możemy zobaczyć skonfigurowane alerty.
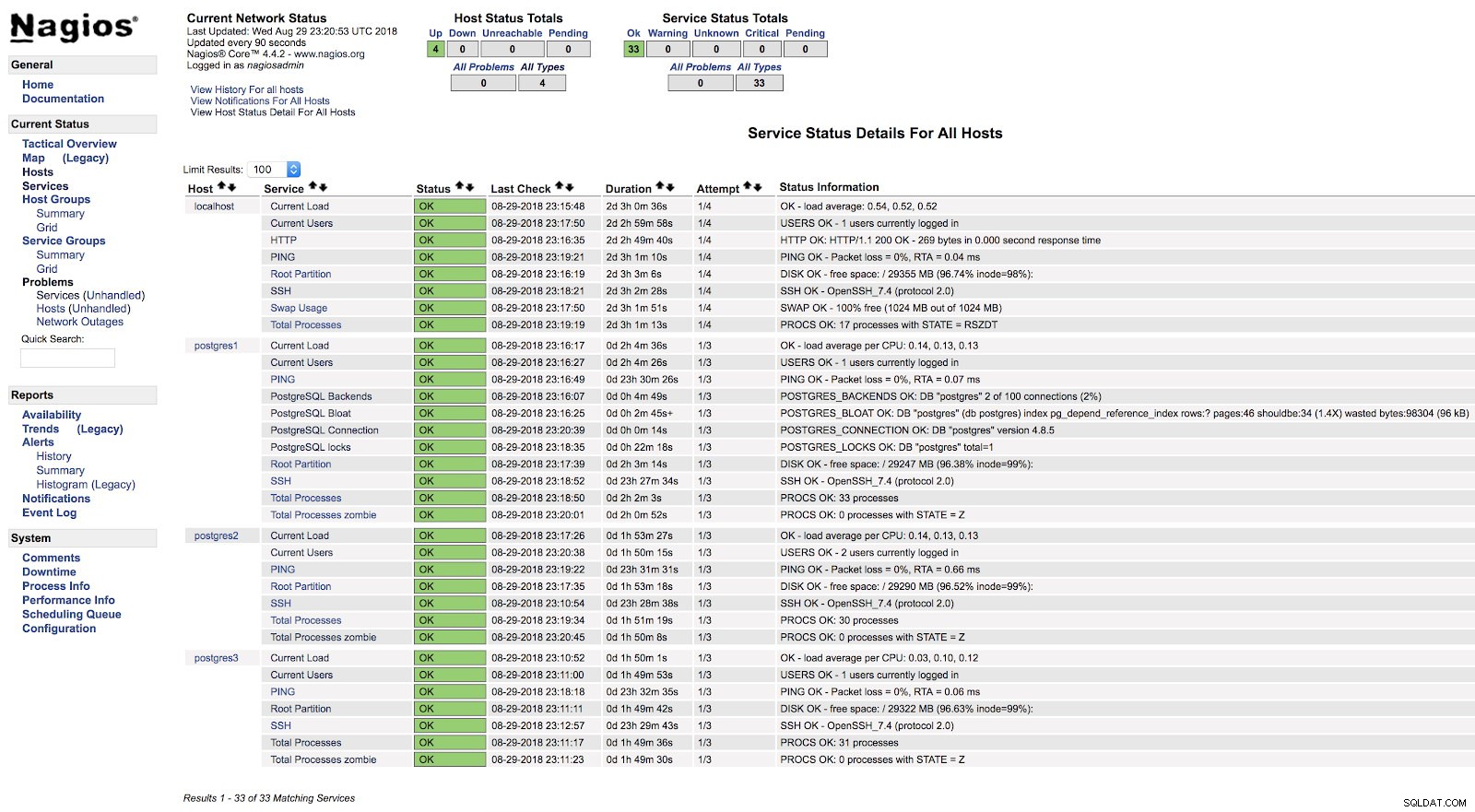 Alerty Nagios check_postgres
Alerty Nagios check_postgres W oficjalnej dokumentacji wtyczki check_postgres możesz znaleźć informacje o tym, co jeszcze monitorować i jak to zrobić.
Sprawdź_pgaktywność
Teraz przyszła kolej na check_pgactivity, popularną również do monitorowania naszej bazy danych PostgreSQL.
Instalacja
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityDodajemy w naszym pliku konfiguracyjnym NRPE (/usr/local/nagios/etc/nrpe.cfg) linię do wykonania sprawdzania, którego chcemy użyć:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10W naszym przykładzie dodamy 4 podstawowe testy dla PostgreSQL. Będziemy monitorować backendy, połączenia, nieprawidłowe indeksy i blokady.
W pliku odpowiadającym naszej bazie danych na serwerze Nagios (/usr/local/nagios/etc/objects/postgres2.cfg) dodajemy następujące wpisy:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}A po ponownym uruchomieniu obu usług (NRPE i Nagios) na obu serwerach, możemy zobaczyć skonfigurowane alerty.
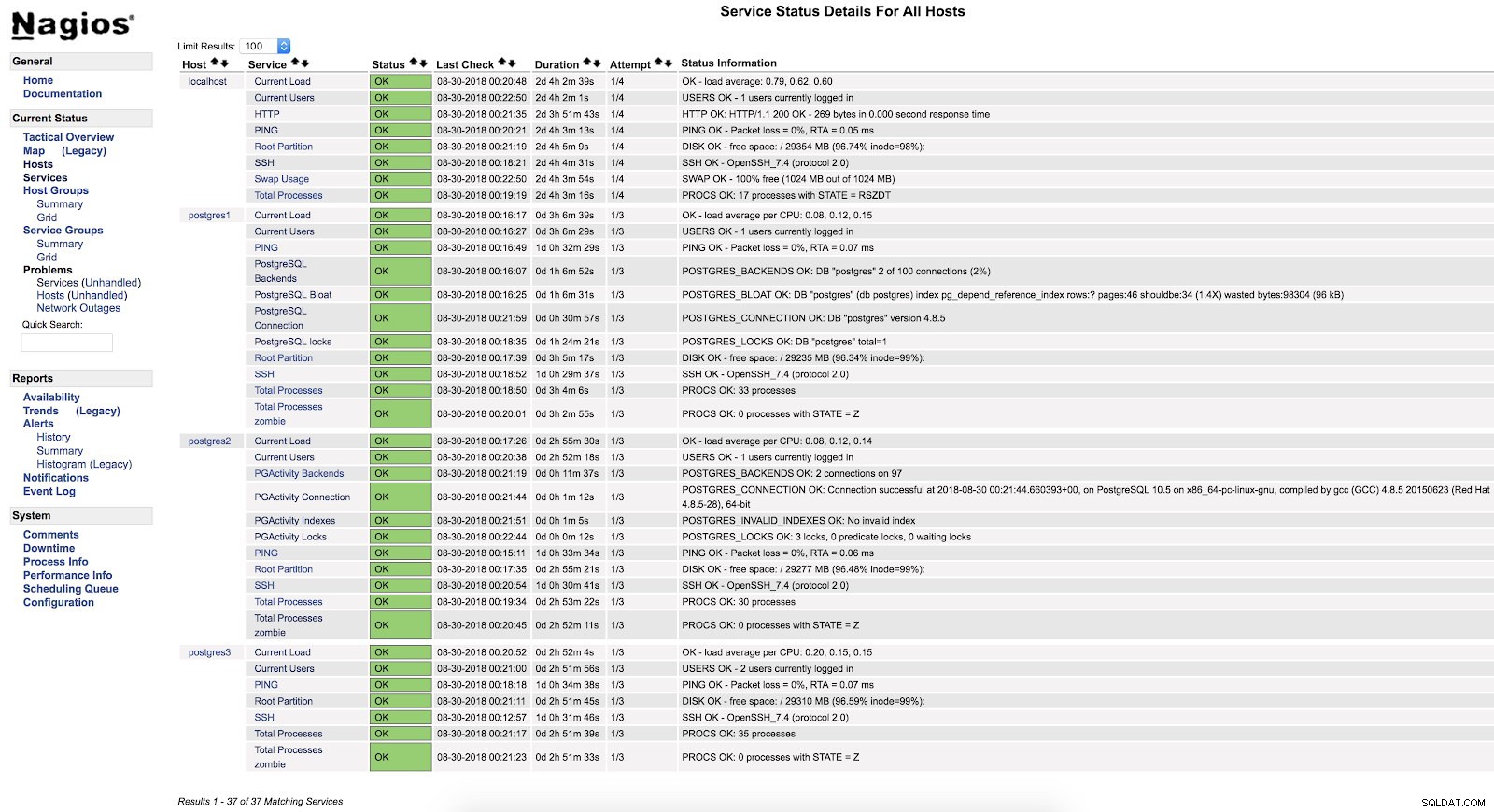 Nagios check_pgactivity Alerty
Nagios check_pgactivity Alerty Sprawdź dziennik błędów
Jednym z najważniejszych lub najważniejszym z nich jest sprawdzenie naszego dziennika błędów.
Tutaj możemy znaleźć różne rodzaje błędów, takie jak FATAL lub zakleszczenie, i jest to dobry punkt wyjścia do analizy każdego problemu, który mamy w naszej bazie danych.
Aby sprawdzić nasz dziennik błędów, stworzymy własny skrypt monitorujący i zintegrujemy go z naszym Nagios (to tylko przykład, ten skrypt będzie prosty i ma dużo miejsca na ulepszenia).
Skrypt
Utworzymy plik /usr/local/nagios/libexec/check_postgres_log.sh na naszym serwerze PostgreSQL3.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiWażną rzeczą w skrypcie jest poprawne tworzenie wyjść odpowiadających każdemu stanowi. Te wyjścia są odczytywane przez Nagios, a każda liczba odpowiada stanowi:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNW naszym przykładzie użyjemy tylko 2 stanów, OK i CRITICAL, ponieważ interesuje nas tylko wiedza, czy w naszym dzienniku błędów w bieżącej godzinie występują błędy typu FATAL.
Tekst, którego użyjemy przed wyjściem, zostanie wyświetlony w interfejsie internetowym naszego Nagios, więc powinno być jak najbardziej jasne, aby użyć go jako przewodnika po problemie.
Gdy zakończymy nasz skrypt monitorujący, przystąpimy do nadawania mu uprawnień do wykonywania, przypisujemy go użytkownikowi nagios i dodamy go do naszego serwera bazy danych NRPE, a także do naszego Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Zrestartuj NRPE i Nagios. Następnie możemy zobaczyć nasz czek w interfejsie Nagios:
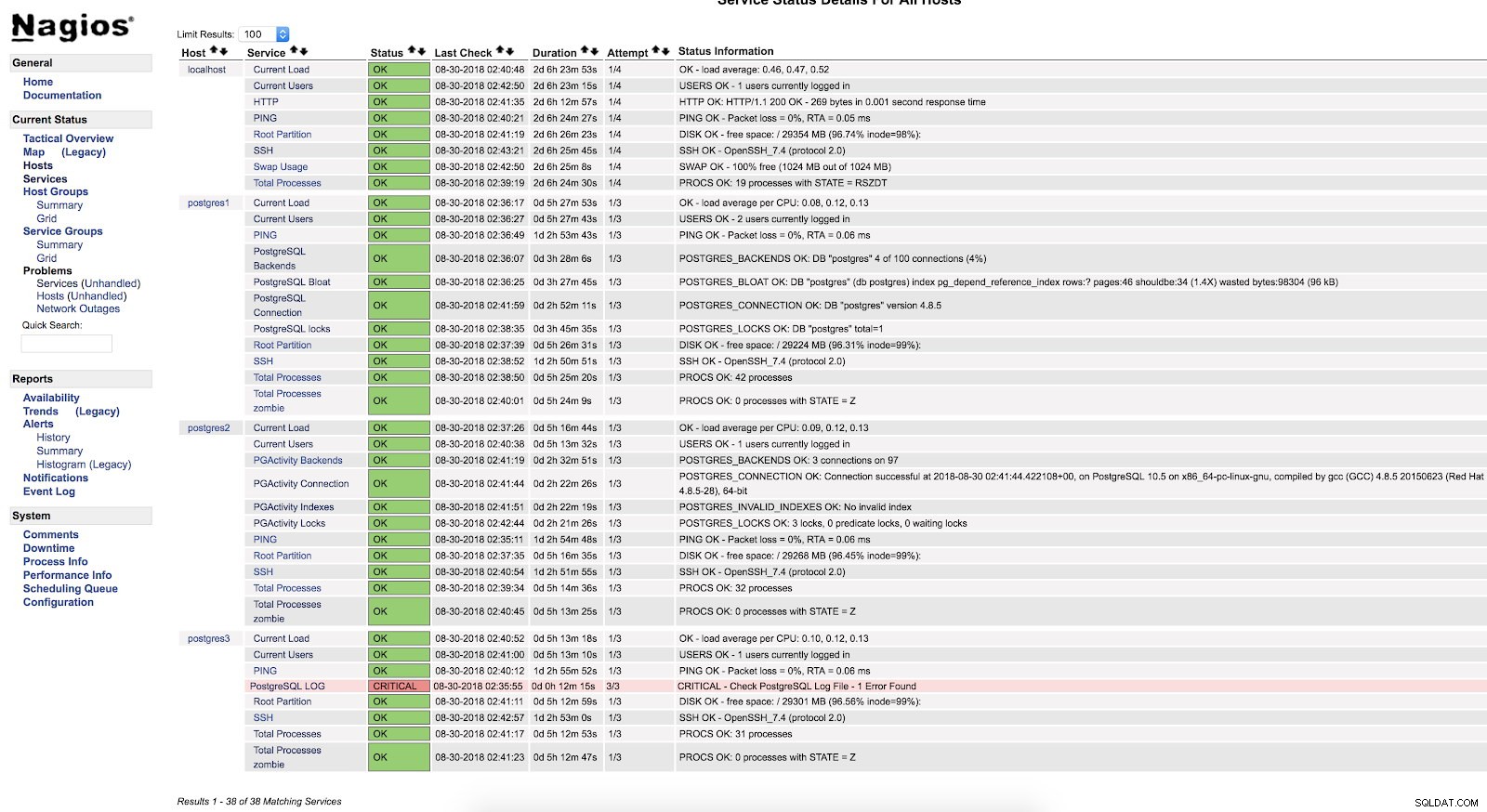 Ostrzeżenia skryptu Nagios
Ostrzeżenia skryptu Nagios Jak widzimy jest w stanie KRYTYCZNYM, więc jeśli przejdziemy do dziennika, zobaczymy:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Aby uzyskać więcej informacji o tym, co możemy monitorować w naszej bazie danych PostgreSQL, zalecamy sprawdzenie naszych blogów dotyczących wydajności i monitorowania lub tego webinaru Postgres Performance.
Bezpieczeństwo i wydajność
Podczas konfigurowania dowolnego monitorowania, czy to za pomocą wtyczek, czy naszego własnego skryptu, musimy być bardzo ostrożni z 2 bardzo ważnymi rzeczami - bezpieczeństwem i wydajnością.
Kiedy przypisujemy niezbędne uprawnienia do monitorowania, musimy być tak restrykcyjni, jak to możliwe, ograniczając dostęp tylko lokalnie lub z naszego serwera monitorującego, używając bezpiecznych kluczy, szyfrując ruch, umożliwiając połączenie do minimum niezbędnego do działania monitorowania.
W odniesieniu do wydajności monitorowanie jest konieczne, ale konieczne jest również bezpieczne korzystanie z niego w naszych systemach.
Musimy uważać, aby nie generować nadmiernie wysokiego dostępu do dysku ani nie uruchamiać zapytań, które negatywnie wpływają na wydajność naszej bazy danych.
Jeśli mamy dużo transakcji na sekundę generujących gigabajty logów i ciągle szukamy błędów, to prawdopodobnie nie jest to najlepsze dla naszej bazy danych. Dlatego musimy zachować równowagę między tym, co monitorujemy, jak często i wpływem na wydajność.
Wniosek
Istnieje wiele sposobów na zaimplementowanie lub skonfigurowanie monitorowania. Możemy to zrobić tak skomplikowane lub tak proste, jak tylko chcemy. Celem tego bloga było wprowadzenie Cię w monitorowanie PostgreSQL przy użyciu jednego z najczęściej używanych narzędzi open source. Widzieliśmy również, że konfiguracja jest bardzo elastyczna i może być dostosowana do różnych potrzeb.
I nie zapominaj, że zawsze możemy polegać na społeczności, więc zostawiam kilka linków, które mogą być bardzo pomocne.
Forum pomocy:https://support.nagios.com/forum/
Znane problemy:https://github.com/NagiosEnterprises/nagioscore/issues
Wtyczki Nagios:https://exchange.nagios.org/directory/Plugins
Wtyczka Nagios do ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol