PostgreSQL 11 został wydany 10 października 2018 r. i zgodnie z harmonogramem, z okazji 23. rocznicy powstania coraz bardziej popularnej bazy danych open source.
Chociaż pełna lista zmian jest dostępna w zwykłych informacjach o wydaniu, warto sprawdzić odnowioną stronę zestawienia funkcji, która podobnie jak oficjalna dokumentacja została przerobiona od czasu swojej pierwszej wersji, co ułatwia wykrycie zmian przed zagłębieniem się w szczegóły .
Na przykład na stronie Informacje o wydaniu, „Powiązanie kanału dla uwierzytelniania SCAM” jest ukryte pod kodem źródłowym, podczas gdy macierz ma go w sekcji Bezpieczeństwo. Dla ciekawskich oto zrzut ekranu interfejsu:
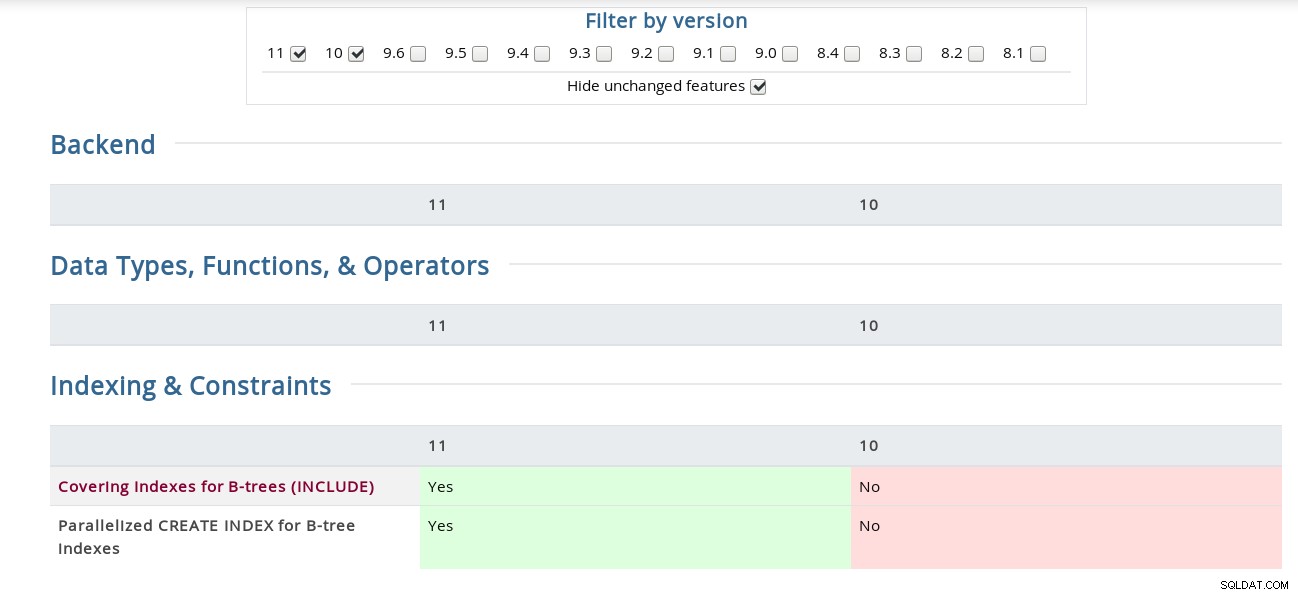 Macierz funkcji PostgreSQL
Macierz funkcji PostgreSQL Ponadto powyższa strona z informacjami o wydaniu Bucardo Postgres jest przydatna na swój sposób, ułatwiając wyszukiwanie słów kluczowych we wszystkich wersjach.
Co nowego? Z dosłownie setkami zmian, przejdę przez różnice wymienione w Tabeli funkcji.
Wskaźniki pokrycia dla B-drzewa (INCLUDE)
CREATE INDEX otrzymał klauzulę INCLUDE, która pozwala indeksom na dołączanie kolumn bez klucza . Jego przypadek użycia dla częstych identycznych zapytań jest dobrze opisany w zatwierdzeniu Toma Lane'a z 22 listopada, które aktualizuje dokumentację programistyczną (co oznacza, że aktualna dokumentacja PostgreSQL 11 jeszcze jej nie zawiera), więc pełny tekst znajduje się w sekcji 11.9. Skanuje tylko indeks i obejmuje indeksy w wersji rozwojowej.
Równoległy CREATE INDEX dla indeksów B-drzewa
Jak wspomniano w nazwie, ta funkcja jest zaimplementowana tylko dla indeksów B-drzewa, a z dziennika zatwierdzenia Roberta Haasa dowiadujemy się, że implementacja może zostać dopracowana w przyszłości. Jak zauważono w dokumentacji CREATE INDEX, podczas gdy zarówno równoległe, jak i współbieżne metody tworzenia indeksów wykorzystują wiele procesorów, w przypadku CONCURRENT tylko pierwsze skanowanie tabeli zostanie wykonane równolegle.
Z tą nową funkcją związane są parametry konfiguracyjne maintenance_work_mem i maintenance_parallel_maintenance_workers .
Na koniec, liczbę równoległych procesów roboczych można ustawić na tabelę za pomocą polecenia ALTER TABLE i określając wartość dla parallel_workers .
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentKompilacja Just-In-Time (JIT) do oceny wyrażeń i deformacji krotek
Z własnym rozdziałem JIT w dokumentacji, ta nowa funkcja opiera się na kompilacji PostgreSQL z obsługą LLVM (użyj pg_config do weryfikacji).
Temat JIT w PostgreSQL jest na tyle złożony (patrz odniesienie do JIT README w dokumentacji), że wymaga dedykowanego bloga. /P>
Równoległe łączenia haszujące
Ta poprawa wydajności zapytań równoległych jest wynikiem dodania współdzielonej tabeli mieszającej, która, jak wyjaśnia Thomas Munro w swoim blogu Parallel Hash for PostgreSQL, pozwala uniknąć partycjonowania tabeli mieszającej, pod warunkiem, że mieści się ona w work_mem , który jak dotąd dla PostgreSQL wydaje się być lepszym rozwiązaniem niż algorytm partycjonowania. Ten sam blog opisuje przeszkody w architekturze PostgreSQL, które autor musiał pokonać w swoich dążeniach do dodania paralelizacji do połączeń mieszających, co świadczy o złożoności pracy wymaganej do zaimplementowania tej funkcji.
Partycja domyślna
Jest to partycja typu catch all do przechowywania wierszy, które nie pasują do żadnej innej zdefiniowanej partycji. W przypadku dodania nowej partycji zalecane jest ograniczenie CHECK, aby uniknąć skanowania partycji domyślnej, które może być powolne, gdy partycja domyślna zawiera dużą liczbę wierszy.
Domyślne zachowanie partycji jest wyjaśnione w dokumentacji ALTER TABLE i CREATE TABLE.
Partycjonowanie za pomocą klucza skrótu
Nazywana również partycjonowaniem mieszającym i jak wskazano w komunikacie o zatwierdzeniu, funkcja ta umożliwia partycjonowanie tabel w taki sposób, aby partycje miały podobną liczbę wierszy. Osiąga się to poprzez zapewnienie modułu, który w prostszym scenariuszu jest zalecany jako równy liczbie partycji, a reszta powinna być inna dla każdej partycji.
Więcej szczegółów i przykład można znaleźć na stronie dokumentacji CREATE TABLE.
Obsługa klucza podstawowego, klucza obcego, indeksów i wyzwalaczy w tabelach podzielonych na partycje
Partycjonowanie tabel jest już dużym krokiem w poprawie wydajności dużych tabel, a dodanie tych funkcji rozwiązuje ograniczenia, które partycjonowane tabele miały od czasu PostgreSQL 10, kiedy wprowadzono nowoczesne „partycjonowanie deklaratywne”.
Trwają prace Alvaro Herrery nad umożliwieniem kluczom obcym odwoływania się do kluczy podstawowych i są planowane w następnej głównej wersji PostgreSQL 12.
AKTUALIZACJA na kluczu partycji
Jak wyjaśniono w dzienniku zatwierdzania poprawek, ta aktualizacja zapobiega zgłaszaniu przez PostgreSQL błędu, gdy aktualizacja klucza partycji unieważnia wiersz, a zamiast tego wiersz zostanie przeniesiony do odpowiedniej partycji.
Powiązanie kanałów dla uwierzytelniania SCRAM
Jest to środek bezpieczeństwa mający na celu zapobieganie atakom typu man-in-the-middle w uwierzytelnianiu SASL i jest szczegółowo opisany na blogu autora. Ta funkcja wymaga minimum OpenSSL 1.0.2.
CREATE PROCEDURE i składnia CALL dla procedur składowanych SQL
PostgreSQL posiada funkcję CREATE FUNCTION od 1996 roku w wersji 1.0.1 , jednak funkcje nie obsługują transakcji. Jak wspomniano w dokumentacji, polecenie CREATE PROCEDURE nie jest w pełni zgodne ze standardem SQL.
Uwaga:czekaj na nadchodzący blog, który będzie szczegółowo omawiał tę funkcję
Wniosek
Główne aktualizacje PostgreSQL 11 koncentrują się na poprawie wydajności poprzez równoległe wykonywanie, partycjonowanie i kompilację Just-In-Time. Procedury składowane pozwalają na pełną kontrolę transakcji i mogą być napisane w różnych językach PL.