Ten blog jest krótką prezentacją na temat Jenkinsa i pokazuje, jak używać tego narzędzia, aby pomóc w niektórych codziennych zadaniach administracyjnych i zarządzania PostgreSQL.
O Jenkinsie
Jenkins to oprogramowanie typu open source do automatyzacji. Jest opracowany w java i jest jednym z najpopularniejszych narzędzi do ciągłej integracji (CI) i ciągłego dostarczania (CD).
W 2010 roku, po przejęciu Sun Microsystems przez Oracle, oprogramowanie „Hudson” było w sporze ze swoją społecznością open source. Ten spór stał się podstawą do uruchomienia projektu Jenkins.
Obecnie „Hudson” (licencja publiczna Eclipse) i „Jenkins” (licencja MIT) to dwa aktywne i niezależne projekty o bardzo podobnym celu.
Jenkins ma tysiące wtyczek, których możesz użyć, aby przyspieszyć fazę rozwoju poprzez automatyzację całego cyklu życia; kompilacja, dokumentacja, testowanie, pakowanie, etap i wdrażanie.
Co robi Jenkins?
Chociaż głównym zastosowaniem Jenkinsa może być Continuous Integration (CI) i Continuous Delivery (CD), to open source ma zestaw funkcjonalności i może być używane bez żadnych zobowiązań lub zależności od CI lub CD, dlatego Jenkins prezentuje kilka interesujących funkcjonalności dla poznaj:
- Planowanie zadań okresowych (zamiast korzystania z tradycyjnego crontab )
- Monitorowanie zadań, ich dzienników i działań za pomocą czystego widoku (ponieważ mają opcję grupowania)
- Utrzymanie miejsc pracy można łatwo wykonać; zakładając, że Jenkins ma do tego zestaw opcji
- Konfiguracja i planowanie instalacji oprogramowania (przy użyciu Puppet) na tym samym lub innym hoście.
- Publikowanie raportów i wysyłanie powiadomień e-mail
Uruchamianie zadań PostgreSQL w Jenkins
Istnieją trzy typowe zadania, które programista PostgreSQL lub administrator bazy danych musi wykonywać na co dzień:
- Planowanie i wykonywanie skryptów PostgreSQL
- Wykonywanie procesu PostgreSQL złożonego z trzech lub więcej skryptów
- Ciągła integracja (CI) dla rozwoju PL/pgSQL
Do wykonania tych przykładów zakłada się, że serwery Jenkins i PostgreSQL (przynajmniej w wersji 9.5) są zainstalowane i działają poprawnie.
Planowanie i wykonywanie skryptu PostgreSQL
W większości przypadków implementacja codziennych (lub okresowych) skryptów PostgreSQL do wykonywania zwykłych zadań, takich jak...
- Generowanie kopii zapasowych
- Przetestuj przywracanie kopii zapasowej
- Wykonywanie zapytania do celów raportowania
- Oczyszczanie i archiwizowanie plików dziennika
- Wywołanie procedury PL/pgSQL w celu oczyszczenia tabel
jest zdefiniowany w crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shJako crontab nie jest najlepszym przyjaznym dla użytkownika narzędziem do zarządzania tego rodzaju harmonogramem, można to zrobić na Jenkins z następującymi zaletami...
- Bardzo przyjazny interfejs do monitorowania ich postępów i aktualnego stanu
- Dzienniki są natychmiast dostępne i nie wymagają specjalnej dotacji, aby uzyskać do nich dostęp
- Zadanie można wykonać ręcznie na Jenkinsie zamiast mieć harmonogram
- W przypadku niektórych zadań nie ma potrzeby definiowania użytkowników i haseł w plikach tekstowych, ponieważ Jenkins robi to w bezpieczny sposób
- Zadania można zdefiniować jako wykonanie API
Zatem dobrym rozwiązaniem może być migracja zadań związanych z zadaniami PostgreSQL do Jenkinsa zamiast do crontab.
Z drugiej strony większość administratorów i programistów baz danych ma duże umiejętności w zakresie języków skryptowych i łatwo byłoby im opracować małe interfejsy do obsługi tych skryptów w celu wdrożenia zautomatyzowanych procesów w celu poprawy ich zadań. Pamiętaj jednak, że Jenkins najprawdopodobniej ma już zestaw funkcji do tego, a te funkcje mogą ułatwić życie programistom, którzy zdecydują się ich używać.
Tak więc, aby zdefiniować wykonanie skryptu, konieczne jest utworzenie nowego zadania, wybierając opcję „Nowa pozycja”.
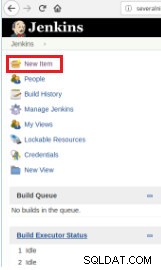 Rysunek 1 – „Nowa pozycja” w celu zdefiniowania zadania do wykonania skryptu PostgreSQL
Rysunek 1 – „Nowa pozycja” w celu zdefiniowania zadania do wykonania skryptu PostgreSQL Następnie, po nazwaniu go, wybierz typ „Projekty FreeStyle” i kliknij OK.
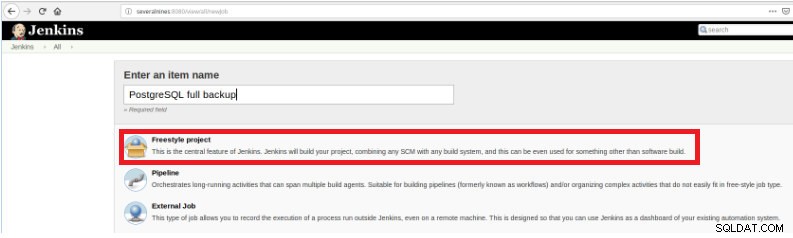 Rysunek 2 – Wybór typu pracy (przedmiotu)
Rysunek 2 – Wybór typu pracy (przedmiotu) Aby zakończyć tworzenie tego nowego zadania, w sekcji „Buduj” należy wybrać opcję „Wykonaj skrypt” oraz w polu wiersza poleceń ścieżkę i parametryzację skryptu, który zostanie wykonany:
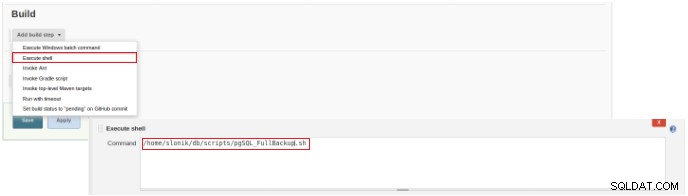 Rysunek 3 – Specyfikacja polecenia do wykonania
Rysunek 3 – Specyfikacja polecenia do wykonania W przypadku tego rodzaju pracy zaleca się weryfikację uprawnień skryptu, ponieważ przynajmniej wykonanie dla grupy, do której należy plik, i dla wszystkich musi być ustawione.
W tym przykładzie skrypt query.sh ma uprawnienia do odczytu i wykonywania dla wszystkich, uprawnienia do odczytu i wykonywania dla grupy oraz do odczytu, zapisu i wykonywania dla użytkownika:
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Ten skrypt ma bardzo prosty zestaw instrukcji, w zasadzie tylko wywołuje narzędzie psql w celu wykonania zapytań:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datWykonywanie procesu PostgreSQL złożonego z trzech lub więcej skryptów
W tym przykładzie opiszę, czego potrzebujesz, aby wykonać trzy różne skrypty, aby ukryć poufne dane, a w tym celu wykonamy poniższe kroki...
- Importuj dane z plików
- Przygotuj dane do zamaskowania
- Kopia zapasowa bazy danych z zamaskowanymi danymi
Tak więc, aby zdefiniować to nowe zadanie, należy wybrać opcję „Nowy element” na stronie głównej Jenkins, a następnie, po przypisaniu nazwy, należy wybrać opcję „Pipeline”:
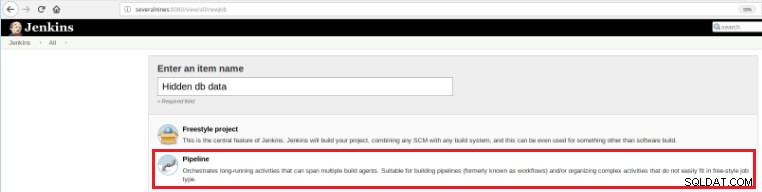 Rysunek 5 — Element potoku w Jenkins
Rysunek 5 — Element potoku w Jenkins Po zapisaniu zadania w sekcji „Pipeline”, na karcie „Zaawansowane opcje projektu”, pole „Definicja” musi być ustawione na „Skrypt potoku”, jak pokazano poniżej:
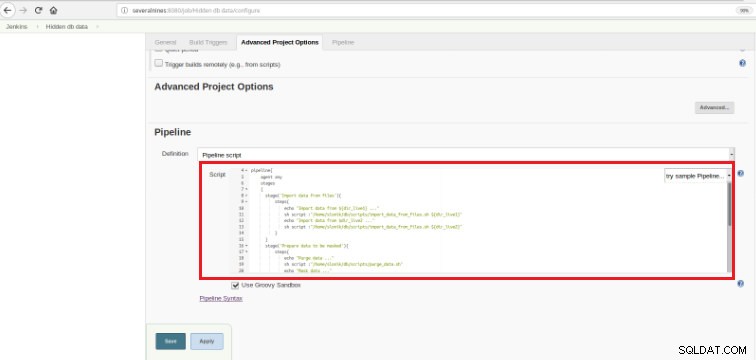 Rysunek 6 — Groovy skrypt w sekcji potoku
Rysunek 6 — Groovy skrypt w sekcji potoku Jak wspomniałem na początku rozdziału, użyty skrypt Groovy składa się z trzech etapów, co oznacza trzy odrębne części (etapy), jak przedstawiono w następującym skrypcie:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy to zgodny ze składnią Java język programowania obiektowego dla platformy Java. Jest to zarówno statyczny, jak i dynamiczny język z funkcjami podobnymi do tych z Pythona, Ruby, Perla i Smalltalka.
Łatwo to zrozumieć, ponieważ tego rodzaju skrypt opiera się na kilku stwierdzeniach…
Scena
Oznacza 3 procesy, które zostaną wykonane:„Importuj dane z plików”, „Przygotuj dane do zamaskowania”
i „Kopia zapasowa bazy danych z zamaskowanymi danymi”.
Krok
„Krok” (często nazywany „krokiem budowania”) to pojedyncze zadanie, które jest częścią sekwencji. Każdy etap może składać się z kilku kroków. W tym przykładzie pierwszy etap składa się z dwóch kroków.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'Dane są importowane z dwóch różnych źródeł.
W poprzednim przykładzie należy zauważyć, że na początku zdefiniowane są dwie zmienne o zasięgu globalnym:
dir_live1
dir_live2Skrypty użyte w tych trzech krokach wywołują psql , pg_restore i pg_dump narzędzia.
Po zdefiniowaniu zadania nadszedł czas, aby je wykonać, a do tego wystarczy kliknąć opcję „Buduj teraz”:
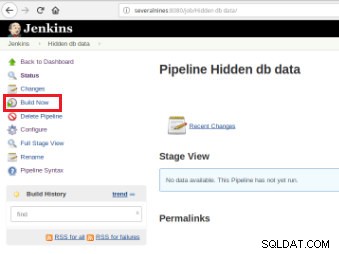 Rysunek 7 – Wykonanie zadania
Rysunek 7 – Wykonanie zadania Po rozpoczęciu kompilacji można zweryfikować jej postęp.
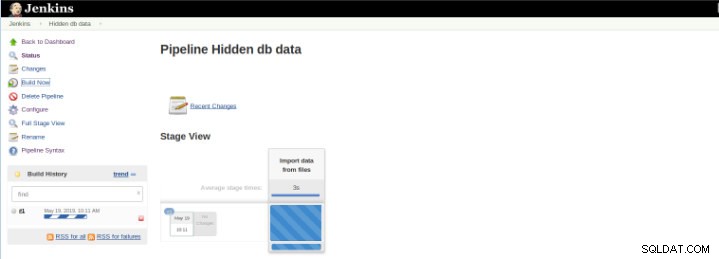 Rysunek 8 – Rozpoczęcie „kompilacji”
Rysunek 8 – Rozpoczęcie „kompilacji” Wtyczka Pipeline Stage View zawiera rozszerzoną wizualizację historii budowania Pipeline na stronie indeksu projektu przepływu w widoku Stage. Ten widok jest tworzony, gdy tylko zadania zostaną zakończone, a każde zadanie jest reprezentowane przez kolumnę od lewej do prawej i możliwe jest przeglądanie i porównywanie czasu, jaki upłynął dla wykonań serval (znanych jako Build in Jenkins).
Po zakończeniu wykonywania (zwanej również kompilacją) można uzyskać dodatkowe szczegóły, klikając gotowy wątek (czerwone pole).
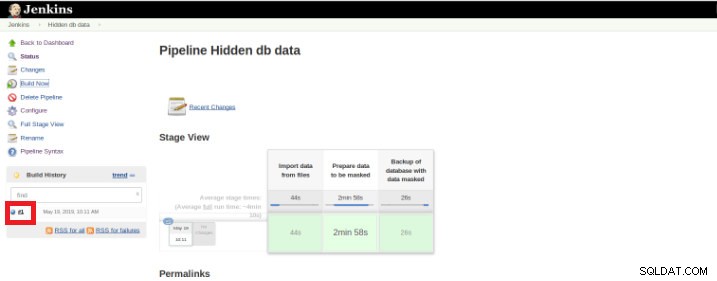 Rysunek 9 – Rozpoczęcie „kompilacji”
Rysunek 9 – Rozpoczęcie „kompilacji” a następnie w opcji „Wyjście konsoli”.
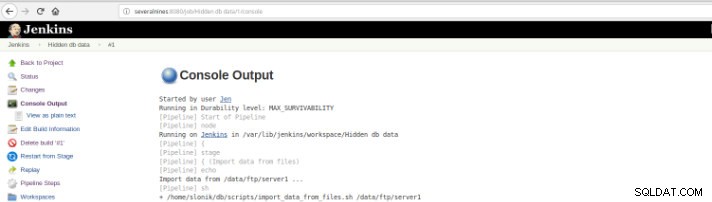 Rysunek 10 – Dane wyjściowe konsoli
Rysunek 10 – Dane wyjściowe konsoli Poprzednie widoki są niezwykle użyteczne, ponieważ pozwalają na wyobrażenie sobie wymaganego czasu działania na każdym etapie.
Pipelines, znane również jako przepływ pracy, to wtyczka umożliwiająca zdefiniowanie cyklu życia aplikacji i jest to funkcja używana w Jenkins do ciągłego dostarczania (CD). na uwadze.
Ten przykład ma na celu ukrycie poufnych danych, ale na pewno istnieje wiele innych przykładów na co dzień administratora bazy danych PostgreSQL, które można wykonać w zadaniu potoku.
Pipeline jest dostępny na Jenkins od wersji 2.0 i jest to niesamowite rozwiązanie!

Ciągła integracja (CI) dla rozwoju PL/pgSQL
Ciągła integracja dla rozwoju bazy danych nie jest tak łatwa jak w przypadku innych języków programowania ze względu na dane, które mogą zostać utracone, więc nie jest łatwo utrzymać bazę danych pod kontrolą źródła i wdrożyć ją na dedykowanym serwerze, szczególnie gdy pojawią się skrypty które zawierają instrukcje DDL (Data Definition Language) i DML (Data Manipulation Language). Dzieje się tak, ponieważ tego rodzaju instrukcje modyfikują bieżący stan bazy danych i w przeciwieństwie do innych języków programowania nie ma kodu źródłowego do skompilowania.
Z drugiej strony istnieje zestaw instrukcji bazy danych, dla których możliwa jest ciągła integracja, podobnie jak w przypadku innych języków programowania.
Ten przykład opiera się tylko na tworzeniu procedur i ilustruje uruchamianie zestawu testów (napisanych w Pythonie) przez Jenkinsa po zatwierdzeniu w repozytorium kodu skryptów PostgreSQL, na których przechowywany jest kod poniższych funkcji.
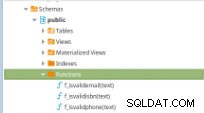 Rysunek 11 – Funkcje PLpg/SQL
Rysunek 11 – Funkcje PLpg/SQL Te funkcje są proste, a ich zawartość zawiera tylko kilka logiki lub zapytania w PLpg/SQL lub plperlu język jako funkcja f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Wszystkie zaprezentowane tu funkcje nie są od siebie zależne, a więc nie ma precedensu ani w jego rozwoju, ani w jego wdrażaniu. Ponadto, ponieważ zostanie to zweryfikowane z wyprzedzeniem, nie ma zależności od ich walidacji.
Tak więc, aby wykonać zestaw skryptów walidacyjnych po wykonaniu zatwierdzenia w repozytorium kodu, konieczne jest utworzenie zadania budowania (nowy element) w Jenkins:
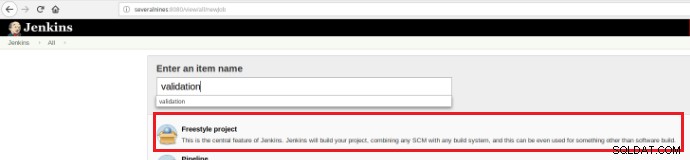 Rysunek 12 – Projekt „Freestyle” dla ciągłej integracji
Rysunek 12 – Projekt „Freestyle” dla ciągłej integracji To nowe zadanie budowania powinno zostać utworzone jako projekt „Freestyle” i w sekcji „Repozytorium kodu źródłowego” należy zdefiniować adres URL repozytorium i jego dane uwierzytelniające (pomarańczowe pole):
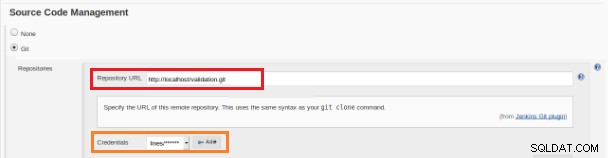 Rysunek 13 – Repozytorium kodu źródłowego
Rysunek 13 – Repozytorium kodu źródłowego W sekcji „Wyzwalacze kompilacji” należy zaznaczyć opcję „Wyzwalacz haka GitHub dla odpytywania GITScm”:
 Rysunek 14 – Sekcja „Wyzwalacze kompilacji”
Rysunek 14 – Sekcja „Wyzwalacze kompilacji” Na koniec w sekcji „Buduj” należy wybrać opcję „Wykonaj powłokę” iw polu poleceń skrypty, które wykonają walidację opracowanych funkcji:
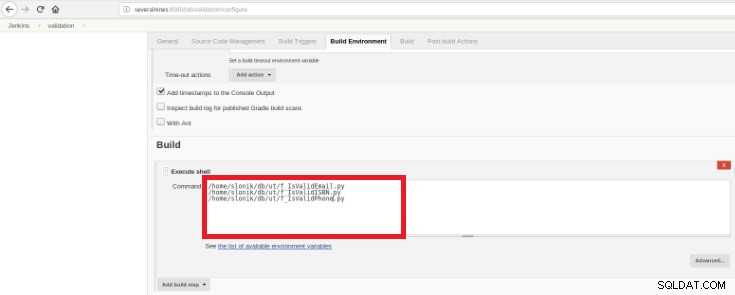 Rysunek 15 – Sekcja „Środowisko budowania”
Rysunek 15 – Sekcja „Środowisko budowania” Celem jest posiadanie jednego skryptu walidacji dla każdej opracowanej funkcji.
Ten skrypt w języku Python zawiera prosty zestaw instrukcji, które wywołają te procedury z bazy danych z pewnymi predefiniowanymi oczekiwanymi wynikami:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Ten skrypt przetestuje prezentowane PLpg/SQL lub plperlu funkcji i zostanie wykonany po każdym zatwierdzeniu w repozytorium kodu, aby uniknąć regresji w rozwoju.
Po wykonaniu tej kompilacji zadania można zweryfikować wykonanie dziennika.
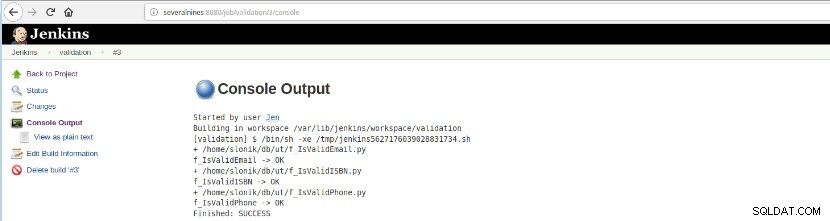 Rysunek 16 – „Wyjście konsoli”
Rysunek 16 – „Wyjście konsoli” Ta opcja przedstawia stan końcowy:SUKCES lub NIEPOWODZENIE, obszar roboczy, wykonane pliki/skrypt, utworzone pliki tymczasowe i komunikaty o błędach (w przypadku niepowodzeń)!
Wniosek
Podsumowując, Jenkins jest znany jako doskonałe narzędzie do ciągłej integracji (CI) i ciągłego dostarczania (CD), jednak może być używany do różnych funkcji, takich jak
- Planowanie zadań
- Wykonywanie skryptów
- Procesy monitorowania
Dla wszystkich tych celów przy każdym wykonaniu (Build on słownik Jenkinsa) można analizować logi i upływający czas.
Ze względu na dużą liczbę dostępnych wtyczek może uniknąć pewnych zmian w określonym celu, prawdopodobnie istnieje wtyczka, która robi dokładnie to, czego szukasz, wystarczy przeszukać centrum aktualizacji lub Zarządzaj Jenkinsem>>Zarządzaj wtyczkami w środku aplikacja internetowa.