Oto jesteśmy. Prawie dwie dekady XXI wieku i zapotrzebowanie na większą moc obliczeniową wciąż stanowi problem. Firmy technologiczne walą w chodnik, aby stawić czoła temu ogromnemu problemowi. Inżynierowie sprzętu znaleźli rozwiązanie, zmieniając sposób projektowania i produkcji jednostki centralnej (CPU) komputera. Zawierają teraz wiele rdzeni, co umożliwia współbieżność. Z kolei twórcy oprogramowania dostosowali sposób pisania programów, aby dostosować się do tej zmiany w sprzęcie.
Społeczność PostgreSQL w pełni wykorzystała te wielordzeniowe procesory, aby poprawić wydajność zapytań. Po prostu aktualizując do wersji 9.6 lub nowszej, można wykorzystać funkcję o nazwie równoległość zapytań do wykonywania różnych operacji. Dzieli zadania na mniejsze części i rozdziela każde zadanie na wiele rdzeni procesora. Każdy rdzeń może jednocześnie przetwarzać zadania. Ze względu na ograniczenia sprzętowe jest to jedyny sposób na poprawę wydajności komputera w przyszłości.
Przed użyciem funkcji równoległości w bazie danych PostgreSQL ważne jest, aby rozpoznać, w jaki sposób tworzy ona równoległe zapytanie. Będziesz mógł debugować i rozwiązywać wszelkie pojawiające się problemy.
Jak działa równoległość zapytań?
Aby lepiej zrozumieć, w jaki sposób wykonywany jest paralelizm, dobrym pomysłem jest rozpoczęcie od poziomu klienta. Aby uzyskać dostęp do PostgreSQL, klient musi wysłać żądanie połączenia do serwera bazy danych zwanego postmasterem. Postmaster zakończy uwierzytelnianie, a następnie rozwidlenie, aby utworzyć nowy proces serwera dla każdego połączenia. Odpowiada również za tworzenie obszaru pamięci współdzielonej, który zawiera pulę buforów. Pula buforów nadzoruje przesyłanie danych między pamięcią współdzieloną a pamięcią masową. Dlatego w momencie nawiązania połączenia pula buforów prześle dane i umożliwi równoległość zapytań.
Nie jest konieczne, aby wszystkie zapytania były równoległe. Zdarzają się sytuacje, w których potrzebna jest tylko niewielka ilość danych, które można szybko przetworzyć za pomocą tylko jednego rdzenia. Ta funkcja jest używana tylko wtedy, gdy wykonanie zapytania zajmie dużo czasu. Optymalizator bazy danych określa, czy należy wykonać równoległość. W razie potrzeby baza danych użyje dodatkowej części pamięci zwanej dynamiczną pamięcią współdzieloną (DSM). Pozwala to procesowi lidera i równoległym świadomym procesom roboczym podzielić zapytanie między wiele rdzeni i zebrać odpowiednie dane.
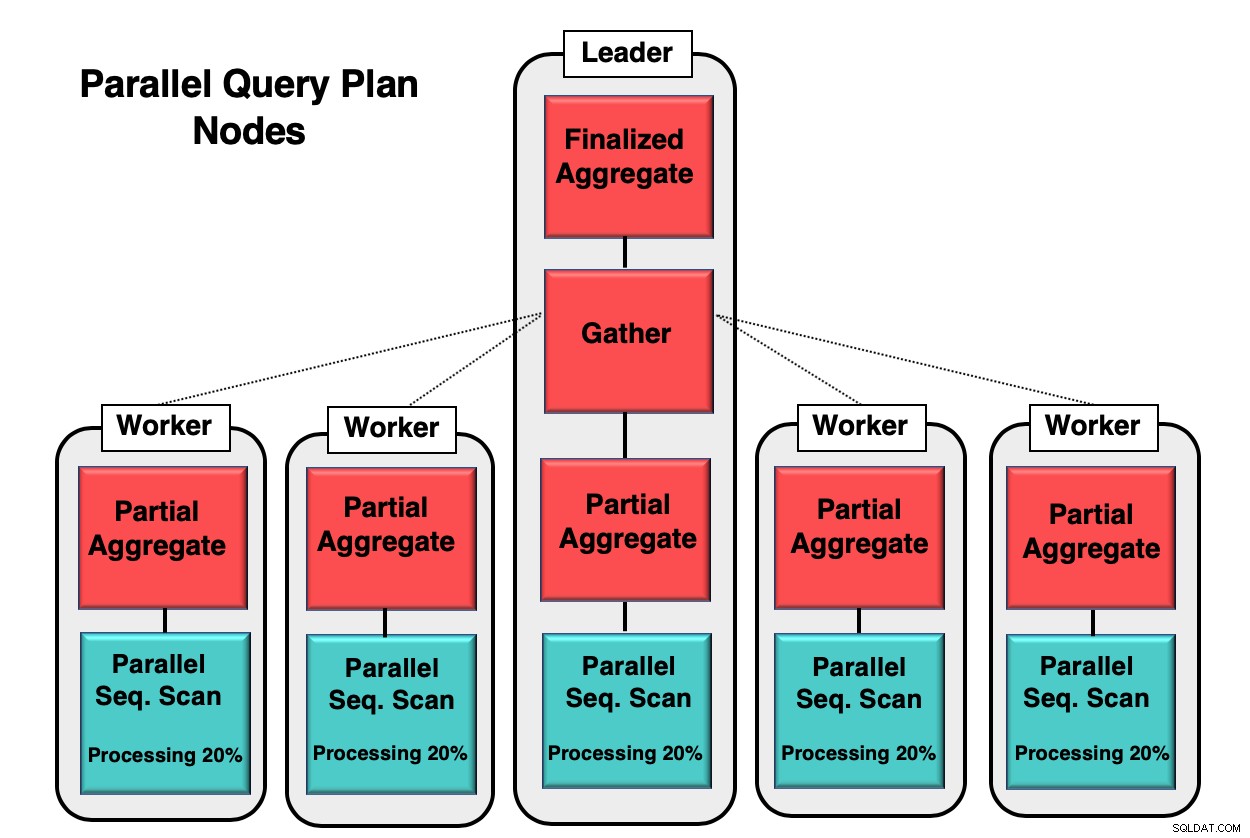
Rysunek 1 pokazuje przykład, w jaki sposób zachodzi paralelizm w bazie danych. Proces lidera uruchamia zapytanie początkowe, podczas gdy poszczególne procesy robocze inicjują kopię tego samego procesu. Częściowy węzeł zagregowany lub rdzeń procesora jest odpowiedzialny za implementację równoległego sekwencyjnego skanowania tabeli bazy danych.
W tym przypadku każdy sekwencyjny węzeł skanowania przetwarza 20% danych w blokach 8kb. Te same węzły mogą koordynować swoją aktywność za pomocą techniki zwanej równoległą świadomością. Każdy węzeł ma pełną wiedzę o tym, jakie dane zostały już przetworzone i jakie dane należy przeskanować w tabeli, aby zakończyć zapytanie. Gdy krotki zostaną zebrane w całości, są one wysyłane do węzła gromadzenia w celu skompilowania i sfinalizowania.
Operacje równoległe
Do pobierania danych z bazy danych w celu uzyskania zestawów wyników można użyć różnych typów zapytań. Oto konkretne operacje, które dają możliwość efektywnego wykorzystania wielu rdzeni.
Skanowanie sekwencyjne
Jest to operacja polegająca na odczytaniu danych w tabeli od początku do końca w celu zebrania danych. Równomiernie rozkłada obciążenie między wiele rdzeni, aby zwiększyć szybkość przetwarzania zapytań. Jest świadomy aktywności każdego rdzenia, co ułatwia ustalenie, czy całe zapytanie zostało zakończone. Węzeł zbierania otrzymuje następnie dane wyodrębnione na podstawie zapytania.
Agregacja
Standardowa operacja, która pobiera dużą ilość danych i kondensuje je do mniejszej liczby wierszy. Dzieje się tak podczas przetwarzania równoległego poprzez wyodrębnianie z tabeli lub indeksów tylko odpowiednich informacji na podstawie zapytania. Wykonywanie średniej określonych danych jest doskonałym przykładem agregacji.
Dołącz haszujący
Technika używana do łączenia danych między dwiema tabelami. Jest to najszybszy algorytm łączenia, który jest zwykle wykonywany z małą i dużą tabelą. Najpierw tworzysz tabelę mieszającą i ładujesz do niej wszystkie dane z jednej tabeli. Następnie możesz przeskanować wszystkie dane z hash i drugiej tabeli, używając równoległego skanowania sekwencyjnego. Każda krotka wyodrębniona ze skanowania jest porównywana z tabelą mieszającą, aby sprawdzić, czy istnieje dopasowanie. Jeśli zostanie zidentyfikowane dopasowanie, dane są łączone. Wraz z wydaniem PostgreSQL 11 użycie paralelizmu do zakończenia łączenia haszującego zajmuje około jednej trzeciej jego poprzedniego czasu przetwarzania.
Połącz, dołącz
Jeśli optymalizator ustali, że złączenie haszujące przekroczy pojemność pamięci, wykona zamiast tego złączenie scalające. Proces ten polega na jednoczesnym skanowaniu dwóch posortowanych list i łączeniu tych samych elementów. Jeśli elementy nie są równe, dane nie zostaną połączone.
Zagnieżdżone łączenie pętli
Ta operacja jest używana, gdy musisz połączyć dwie tabele zawierające różne języki programowania, takie jak Quick Basic, Python itp. Każda tabela jest skanowana i przetwarzana przy użyciu wielu rdzeni. Jeśli dane są zgodne, są wysyłane do węzła gromadzenia w celu dołączenia. Skanowane są również indeksy, dlatego proces ten zawiera wiele pętli do pobierania danych. Średnio ukończenie łączenia za pomocą procesu równoległego zajmuje tylko jedną trzecią czasu.
Skanowanie indeksu B-drzewa
Ta operacja skanuje drzewo posortowanych danych w celu zlokalizowania określonych informacji. Ten proces trwa dłużej niż typowe skanowanie sekwencyjne, ponieważ podczas wyszukiwania rekordów trzeba dużo czekać. Jednak praca polegająca na skanowaniu odpowiednich danych jest podzielona między wiele procesorów.
Skanowanie stosu mapy bitowej
Za pomocą tej operacji można scalić wiele indeksów. Najpierw chcesz utworzyć równoważną liczbę bitmap, ponieważ masz indeksy. Na przykład, jeśli masz trzy indeksy, musisz najpierw utworzyć trzy mapy bitowe. Każda bitmapa będzie pobierać i kompilować krotki na podstawie zapytania.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentRównoległość partycji
Istnieje inna forma paralelizmu, która może mieć miejsce w bazie danych PostgreSQL. Jednak nie wynika to ze skanowania tabel i dzielenia zadań. Możesz podzielić lub podzielić dane według określonych wartości. Na przykład możesz wziąć nabywców wartości i mieć jeden rdzeń przetwarzający dane tylko w ramach tej wartości. W ten sposób wiesz dokładnie, co każdy rdzeń przetwarza w danym momencie.
Partycjonowanie haszujące
Ta operacja jest używana przez rozłożenie wierszy tabeli na podtabele. Ponownie, podział ogólnie określany przez odrębną wartość lub listę wartości z tabeli. Jest to doskonała metoda do użycia, jeśli nie masz wydajnej techniki zarządzania pamięcią masową na wszystkich swoich urządzeniach. Chciałbyś użyć partycjonowania do losowej dystrybucji danych, aby zapobiec wąskim gardłom we/wy.
Dołączanie do partycji
Technika używana do dzielenia tabel według partycji i łączenia ich przez dopasowywanie podobnych partycji. Na przykład możesz mieć dużą tabelę kupujących z całych Stanów Zjednoczonych. Możesz najpierw podzielić tabelę według różnych miast, a następnie połączyć kilka miast na podstawie regionu w każdym stanie. Łączenie partycji upraszcza dane i umożliwia manipulację tabelami.
Równoległe niebezpieczne
PostgreSQL 11 automatycznie wykonuje równoległość zapytań, jeśli optymalizator stwierdzi, że jest to najszybszy sposób zakończenia zapytania. Im wyższa wersja PostgreSQL, której używasz, tym więcej możliwości równoległych będzie miała twoja baza danych. Niestety nie wszystkie zapytania powinny być wykonywane równolegle, nawet jeśli ma taką możliwość. Typ zapytania, które wykonujesz, może mieć określone ograniczenia i będzie wymagać, aby tylko jeden rdzeń wykonał całe przetwarzanie. Spowoduje to spowolnienie działania systemu, ale zagwarantuje, że otrzymane dane będą kompletne.
Aby zapewnić, że Twoje zapytania nigdy nie będą zagrożone, programiści stworzyli funkcję zwaną równoległym niebezpiecznym. Możesz ręcznie przesłonić optymalizator bazy danych i zażądać, aby zapytanie nigdy nie było równoległe. Proces równoległości nie zostanie wykonany.
Równoległość w bazie danych PostgreSQL to funkcja, która staje się coraz lepsza z każdą wersją bazy danych. Mimo że przyszłość technologii jest niepewna, wydaje się, że korzystanie z tej funkcji nie zniknie.
Aby uzyskać więcej informacji, zapoznaj się z następującymi...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-„dziel-i-zwyciężaj-połączenia-między-partycjonowaną-tablicą