Kiedy musisz wdrożyć system analityczny dla firmy, często pojawia się pytanie, gdzie dane powinny być przechowywane. Nie zawsze istnieje idealna opcja dla wszystkich wymagań i zależy to od budżetu, ilości danych i potrzeb firmy.
PostgreSQL, jako najbardziej zaawansowana baza danych typu open source, jest na tyle elastyczna, że może służyć jako prosta relacyjna baza danych, baza danych szeregów czasowych, a nawet jako wydajne, tanie rozwiązanie do hurtowni danych. Możesz również zintegrować go z kilkoma narzędziami analitycznymi.
Jeśli szukasz szeroko kompatybilnej, taniej i wydajnej hurtowni danych, najlepszą opcją bazy danych może być PostgreSQL, ale dlaczego? W tym blogu zobaczymy, czym jest hurtownia danych, dlaczego jest potrzebna i dlaczego PostgreSQL może być tutaj najlepszą opcją.
Co to jest hurtownia danych
Hurtownia Danych to system wystandaryzowanych, spójnych i zintegrowanych, który zawiera bieżące lub historyczne dane z jednego lub więcej źródeł, który służy do raportowania i analizy danych. Jest uważany za podstawowy element analizy biznesowej, która jest strategią i technologią wykorzystywaną przez firmę w celu lepszego zrozumienia jej kontekstu komercyjnego.
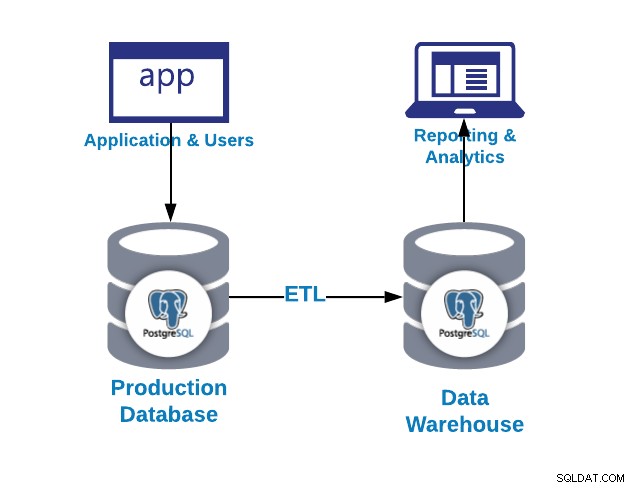
Pierwsze pytanie, które możesz zadać, to dlaczego potrzebuję hurtowni danych?
- Integracja:Integruj/scentralizuj dane z wielu systemów/baz danych
- Standaryzuj:Standaryzuj wszystkie dane w tym samym formacie
- Analityka:analizuj dane w kontekście historycznym
Niektóre z zalet hurtowni danych mogą być...
- Zintegruj dane z wielu źródeł w jedną bazę danych
- Unikaj blokowania lub ładowania produkcji z powodu długotrwałych zapytań
- Przechowuj informacje historyczne
- Zrestrukturyzuj dane, aby pasowały do wymagań analitycznych
Jak widzieliśmy na poprzednim obrazku, możemy używać PostgreSQL zarówno dla OLAP, jak i OLTP. Zobaczmy różnicę.
- OLTP:Przetwarzanie transakcji online. Generalnie posiada dużą liczbę krótkich transakcji on-line (INSERT, UPDATE, DELETE) generowanych przez aktywność użytkownika. Systemy te kładą nacisk na bardzo szybkie przetwarzanie zapytań i zachowanie integralności danych w środowiskach wielodostępowych. Tutaj skuteczność mierzy się liczbą transakcji na sekundę. Bazy danych OLTP zawierają szczegółowe i aktualne dane.
- OLAP:Przetwarzanie analityczne online. Ogólnie rzecz biorąc, ma niewielką liczbę złożonych transakcji generowanych przez duże raporty. Czas odpowiedzi jest miarą skuteczności. Te bazy danych przechowują zagregowane, historyczne dane w wielowymiarowych schematach. Bazy danych OLAP są używane do analizowania wielowymiarowych danych z wielu źródeł i perspektyw.
Mamy dwa sposoby ładowania danych do naszej bazy danych analitycznych:
- ETL:wyodrębnianie, przekształcanie i ładowanie. W ten sposób generujemy naszą hurtownię danych. Najpierw wyodrębnij dane z produkcyjnej bazy danych, przekształć dane zgodnie z naszymi wymaganiami, a następnie załaduj dane do naszej hurtowni danych.
- ELT:Wyodrębnij, załaduj i przekształć. Najpierw wyodrębnij dane z produkcyjnej bazy danych, załaduj je do bazy danych, a następnie przekształć dane. Ten sposób nazywa się Data Lake i jest to nowa koncepcja zarządzania naszymi dużymi danymi.
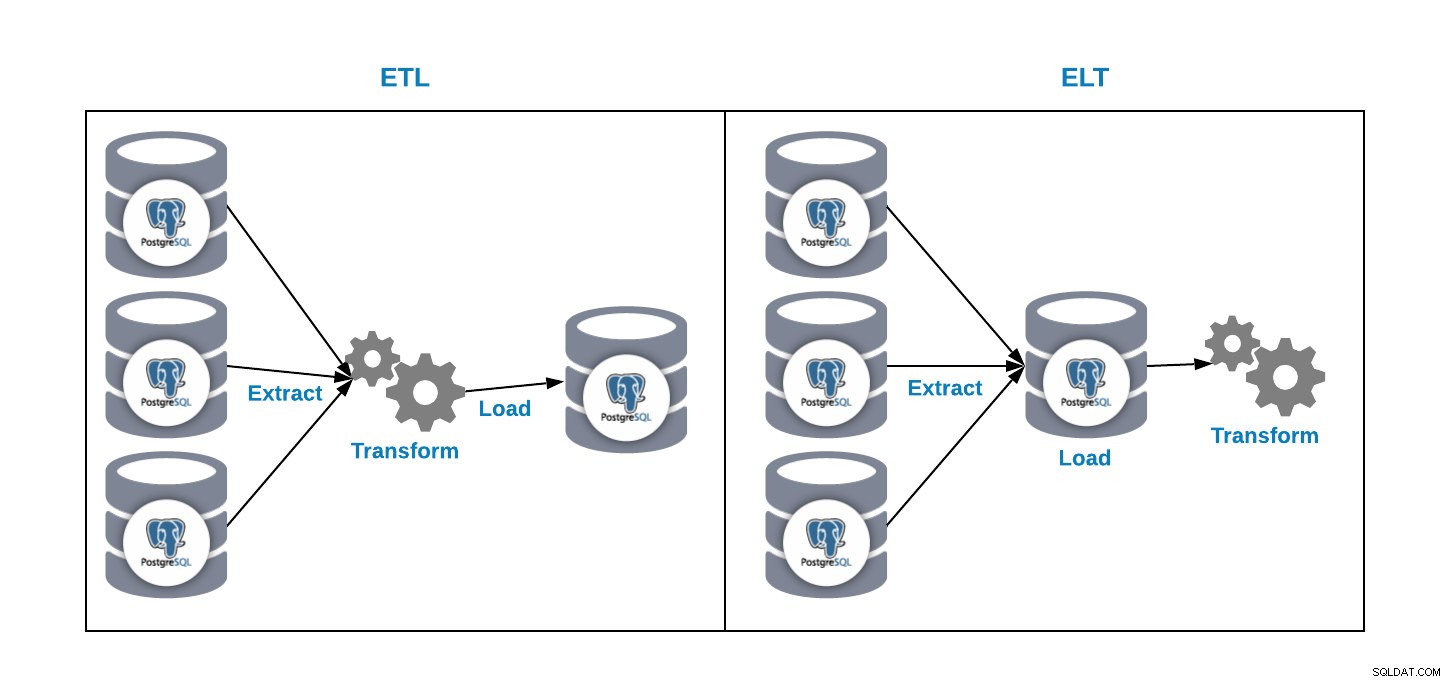
A teraz drugie pytanie i, dlaczego powinienem używać PostgreSQL w mojej hurtowni danych?
Zalety PostgreSQL jako hurtowni danych
Przyjrzyjmy się niektórym korzyściom płynącym z używania PostgreSQL jako hurtowni danych...
- Koszt:Jeśli korzystasz ze środowiska lokalnego, koszt samego produktu wyniesie 0 USD, nawet jeśli używasz jakiegoś produktu w chmurze, prawdopodobnie koszt produktu opartego na PostgreSQL będzie niższy niż pozostałe produkty.
- Skala:Możesz skalować odczyty w prosty sposób, dodając tyle węzłów replik, ile chcesz.
- Wydajność:Przy prawidłowej konfiguracji PostgreSQL ma naprawdę dobrą wydajność w różnych scenariuszach.
- Kompatybilność:Możesz zintegrować PostgreSQL z zewnętrznymi narzędziami lub aplikacjami do eksploracji danych, OLAP i raportowania.
- Rozszerzalność:PostgreSQL ma typy danych i funkcje zdefiniowane przez użytkownika.
Istnieje również kilka funkcji PostgreSQL, które mogą nam pomóc w zarządzaniu informacjami z naszych hurtowni danych...
- Tabele tymczasowe:to krótkotrwała tabela, która istnieje na czas trwania sesji bazy danych. PostgreSQL automatycznie usuwa tymczasowe tabele na koniec sesji lub transakcji.
- Procedury przechowywane:możesz ich używać do tworzenia procedur lub funkcji w wielu językach (PL/pgSQL, PL/Perl, PL/Python itp.).
- Partycjonowanie:jest to naprawdę przydatne do konserwacji bazy danych, zapytań przy użyciu klucza partycji i wydajności INSERT.
- Widok zmaterializowany:wyniki zapytania są wyświetlane w formie tabeli.
- Przestrzenie tabel:Możesz zmienić lokalizację danych na inny dysk. W ten sposób będziesz mieć równoległy dostęp do dysku.
- Zgodny z PITR:Możesz tworzyć kopie zapasowe kompatybilne z odzyskiwaniem do punktu w czasie, więc w przypadku awarii możesz przywrócić stan bazy danych w określonym czasie.
- Ogromna społeczność:I wreszcie, PostgreSQL ma ogromną społeczność, w której możesz znaleźć wsparcie w wielu różnych sprawach.
Konfigurowanie PostgreSQL do użycia hurtowni danych
Nie ma najlepszej konfiguracji do użycia we wszystkich przypadkach i we wszystkich technologiach baz danych. Zależy to od wielu czynników, takich jak sprzęt, sposób użytkowania i wymagania systemowe. Poniżej znajduje się kilka wskazówek, jak skonfigurować bazę danych PostgreSQL, aby działała jako hurtownia danych we właściwy sposób.
Na podstawie pamięci
- max_connections:Jako baza danych hurtowni danych nie potrzebujesz dużej liczby połączeń, ponieważ będzie ona używana do raportowania i pracy analitycznej, więc możesz ograniczyć maksymalną liczbę połączeń za pomocą tego parametru.
- shared_buffers:Ustawia ilość pamięci używanej przez serwer bazy danych na bufory pamięci współdzielonej. Rozsądna wartość może wynosić od 15% do 25% pamięci RAM.
- Effective_cache_size:Ta wartość jest używana przez planer zapytań do uwzględniania planów, które mogą lub nie mogą zmieścić się w pamięci. Jest to brane pod uwagę w szacunkach kosztów stosowania indeksu; wysoka wartość zwiększa prawdopodobieństwo użycia skanowania indeksu, a niska wartość zwiększa prawdopodobieństwo użycia skanowania sekwencyjnego. Rozsądna wartość to około 75% pamięci RAM.
- pamięć robocza:Określa ilość pamięci, która będzie używana przez wewnętrzne operacje tablic ORDER BY, DISTINCT, JOIN i hash przed zapisaniem do plików tymczasowych na dysku. Konfigurując tę wartość, musimy wziąć pod uwagę, że kilka sesji wykonuje te operacje w tym samym czasie, a każda operacja będzie mogła wykorzystać tyle pamięci, ile określa ta wartość, zanim zacznie zapisywać dane w plikach tymczasowych. Rozsądna wartość może wynosić około 2% pamięci RAM.
- maintenance_work_mem:Określa maksymalną ilość pamięci używanej przez operacje konserwacji, takie jak ODKURZACZ, CREATE INDEX i ALTER TABLE ADD FOREIGN KEY. Rozsądna wartość może wynosić około 15% pamięci RAM.
Na podstawie procesora
- Max_worker_processes:Ustawia maksymalną liczbę procesów w tle obsługiwanych przez system. Rozsądną wartością może być liczba procesorów.
- Max_parallel_workers_per_gather:Ustawia maksymalną liczbę pracowników, które mogą być uruchomione przez pojedynczy węzeł Gather lub Gather Merge. Rozsądna wartość może wynosić 50% liczby procesorów.
- Max_parallel_workers:Ustawia maksymalną liczbę procesów roboczych, które system może obsługiwać dla zapytań równoległych. Rozsądną wartością może być liczba procesorów.
Ponieważ dane załadowane do naszej hurtowni danych nie powinny się zmieniać, możemy również wyłączyć Autovacuum, aby uniknąć dodatkowego obciążenia bazy danych PostgreSQL. Procesy próżni i analizy mogą być częścią procesu ładowania wsadowego.
Wniosek
Jeśli szukasz szeroko kompatybilnej, taniej i wydajnej hurtowni danych, zdecydowanie powinieneś rozważyć PostgreSQL jako opcję dla swojej bazy danych hurtowni danych. PostgreSQL ma wiele zalet i funkcji przydatnych do zarządzania naszą hurtownią danych, takich jak partycjonowanie lub procedury składowane, a nawet więcej.