Jednym z kluczowych aspektów wysokiej dostępności jest możliwość szybkiego reagowania na awarie. Ręczne zarządzanie bazami danych nie jest niczym niezwykłym, a oprogramowanie monitorujące monitoruje stan bazy danych. W przypadku awarii oprogramowanie monitorujące wysyła alert do personelu dyżurującego. Oznacza to, że ktoś może potencjalnie potrzebować obudzić się, dostać się do komputera, zalogować się do systemów i przejrzeć logi — oznacza to, że zanim rozpocznie się naprawa, musi minąć sporo czasu. W idealnym przypadku cały proces powinien być zautomatyzowany.
W tym blogu przyjrzymy się, jak wdrożyć w pełni zautomatyzowany system, który wykrywa awarię podstawowej bazy danych i inicjuje procedury przełączania awaryjnego poprzez promowanie dodatkowej bazy danych. Użyjemy ClusterControl, aby wykonać automatyczne przełączanie awaryjne bazy danych Moodle PostgreSQL.
Zaleta automatycznego przełączania awaryjnego
- Mniej czasu na odzyskanie usługi bazy danych
- Dłuższy czas pracy systemu
- Mniejsze uzależnienie od administratora lub administratora, który konfiguruje wysoką dostępność bazy danych
Architektura
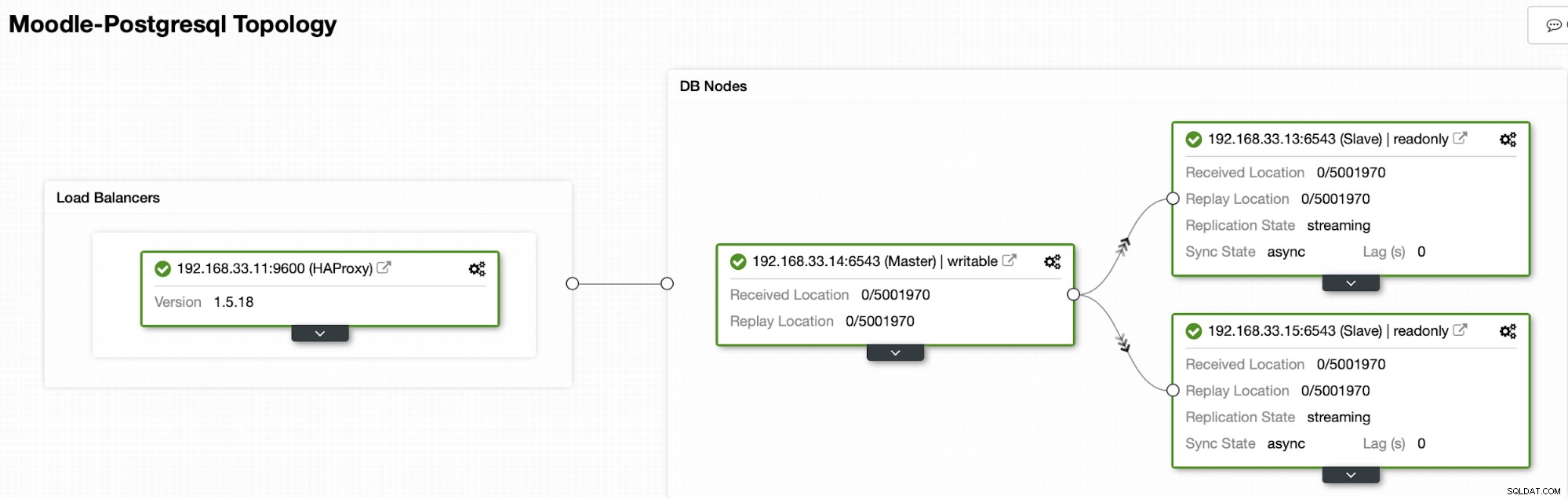
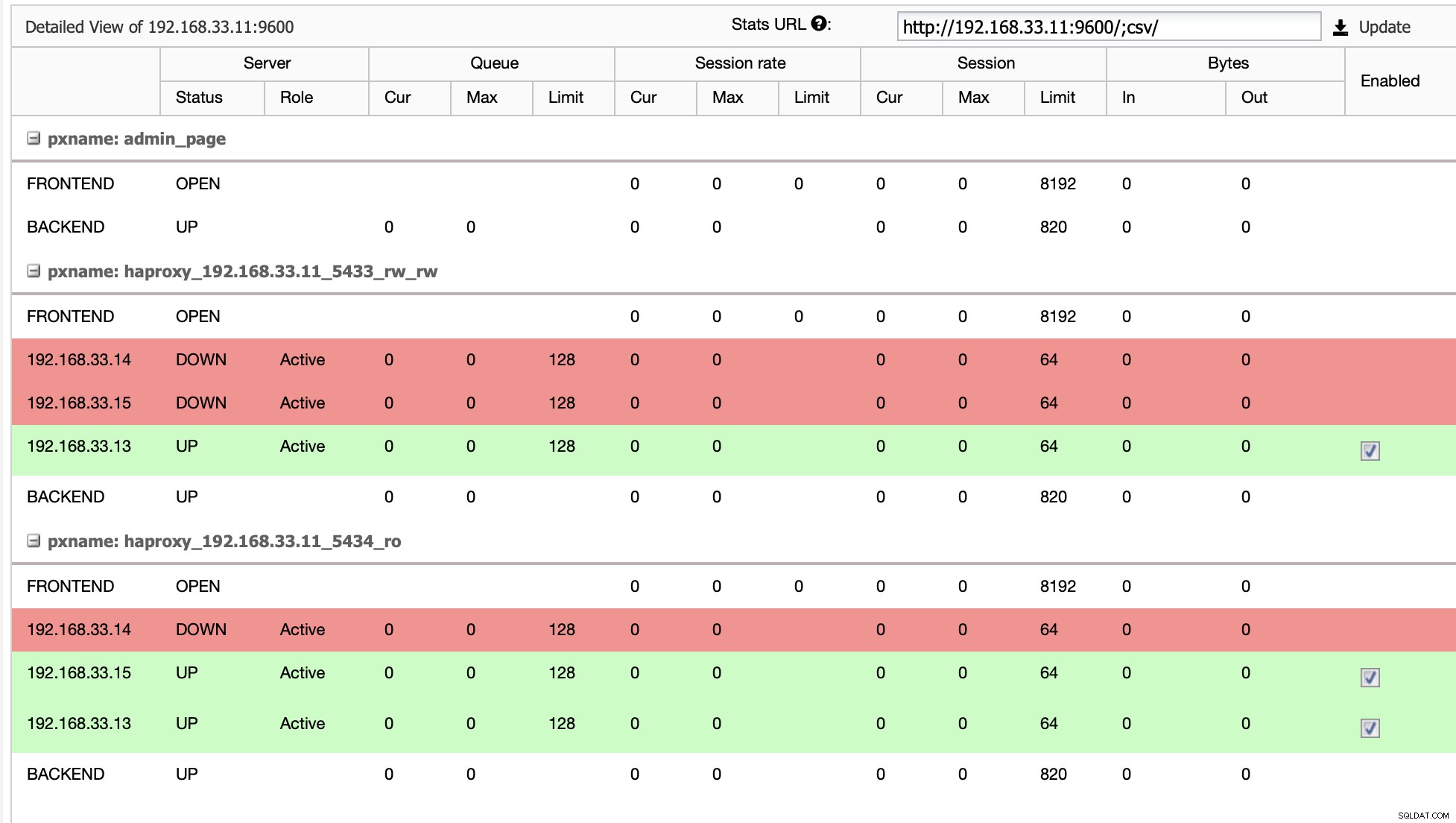
Obecnie mamy jeden serwer główny Postgres i dwa serwery pomocnicze w systemie równoważenia obciążenia HAProxy który wysyła ruch Moodle do głównego węzła PostgreSQL. Odzyskiwanie klastra i automatyczne odzyskiwanie węzłów w ClusterControl to ważne ustawienia do przeprowadzenia automatycznego procesu przełączania awaryjnego.

Kontrolowanie, na który serwer przełączać się awaryjnie
ClusterControl oferuje białą i czarną listę zestawu serwerów, które chcesz wziąć udział w przełączaniu awaryjnym lub wykluczyć jako kandydata.
W konfiguracji cmon można ustawić dwie zmienne,
- replication_failover_whitelist :zawiera listę adresów IP lub nazw hostów serwerów pomocniczych, które powinny być używane jako potencjalni kandydaci podstawowi. Jeśli ta zmienna jest ustawiona, tylko te hosty będą brane pod uwagę.
- replication_failover_blacklist :zawiera listę hostów, które nigdy nie będą uważane za głównego kandydata. Można go użyć do wyświetlenia listy serwerów pomocniczych, które są używane do tworzenia kopii zapasowych lub zapytań analitycznych. Jeśli sprzęt różni się między serwerami pomocniczymi, możesz umieścić tutaj serwery, które używają wolniejszego sprzętu.
Automatyczny proces przełączania awaryjnego
Krok 1
Rozpoczęliśmy ładowanie danych na głównym serwerze (192.168.33.14) za pomocą narzędzia sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Krok 2
Zatrzymamy główny serwer Postgres (192.168.33.14). W ClusterControl parametr (enable_cluster_autorecovery) jest włączony, więc będzie promować następną odpowiednią podstawową.
# service postgresql-12 stopKrok 3
ClusterControl wykrywa awarie w głównym i promuje drugi z najbardziej aktualnymi danymi jako nowy główny. Działa również na pozostałych serwerach pomocniczych, aby były replikowane z nowego serwera podstawowego.

W naszym przypadku (192.168.33.13) jest nowym serwerem podstawowym i serwery pomocnicze są teraz replikowane z nowego serwera głównego. Teraz HAProxy kieruje ruch bazy danych z serwerów Moodle do najnowszego serwera głównego.
Od (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Od (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Aktualna topologia
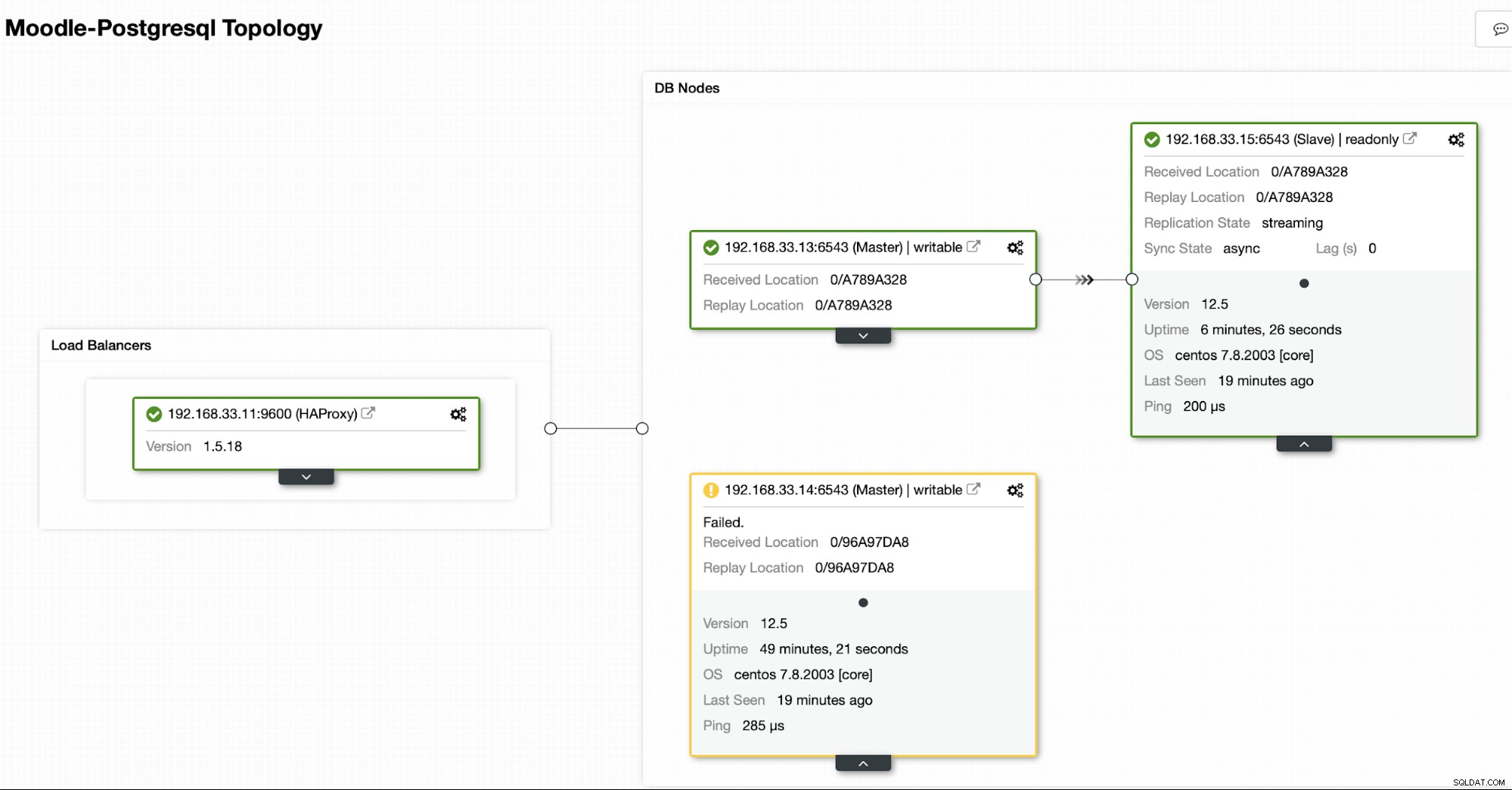
Gdy HAProxy wykryje, że jeden z naszych węzłów, podstawowy lub replika, jest niedostępny, automatycznie oznacza go jako offline. HAProxy nie będzie wysyłać do niego żadnego ruchu z aplikacji Moodle. To sprawdzenie odbywa się za pomocą skryptów sprawdzających kondycję, które są konfigurowane przez ClusterControl w czasie wdrażania.
Gdy ClusterControl zmieni serwer replik na podstawowy, nasz HAProxy oznaczy stary serwer podstawowy jako offline i przestawi promowany węzeł w tryb online.
Gdy stary serwer podstawowy będzie ponownie w trybie online, nie zostanie automatycznie zsynchronizowany z nowym serwerem głównym. Musimy wpuścić go z powrotem do topologii i można to zrobić za pomocą interfejsu ClusterControl. Pozwoli to uniknąć możliwości utraty danych lub niespójności, na wypadek gdybyśmy chcieli najpierw zbadać, dlaczego ten serwer uległ awarii.
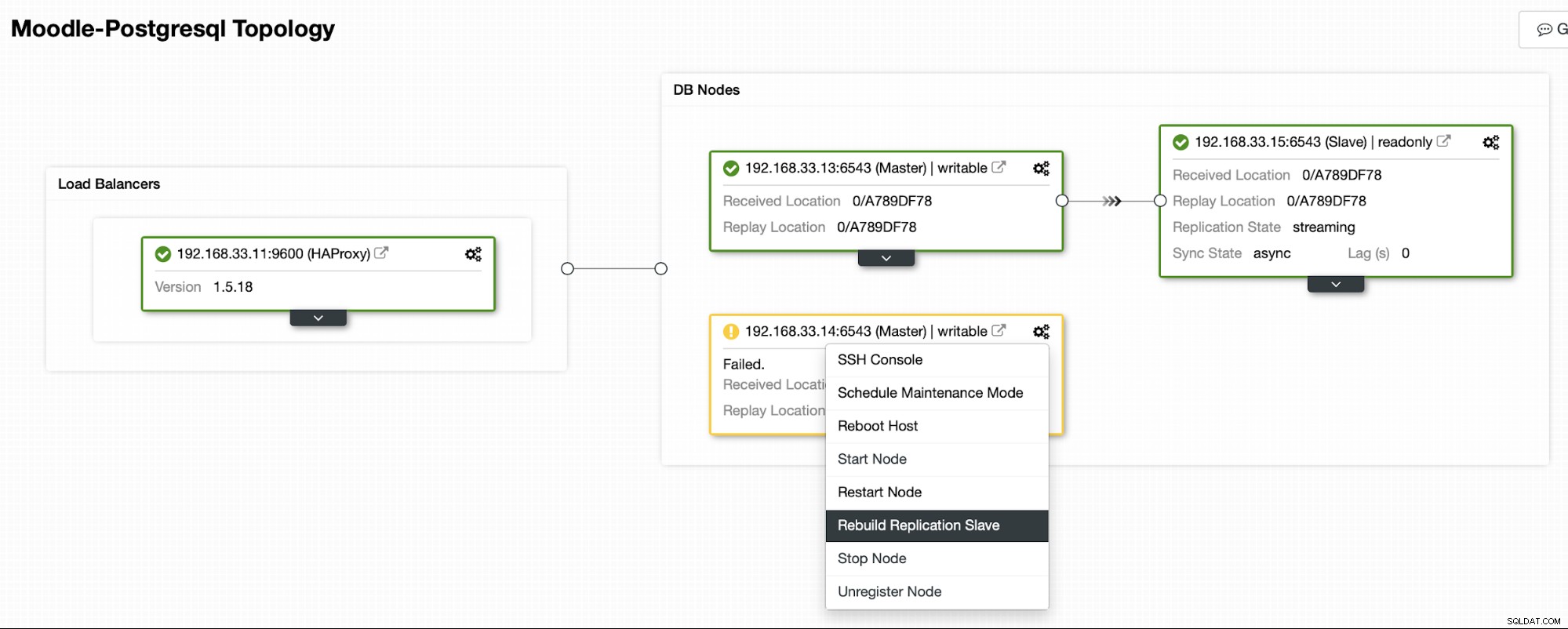
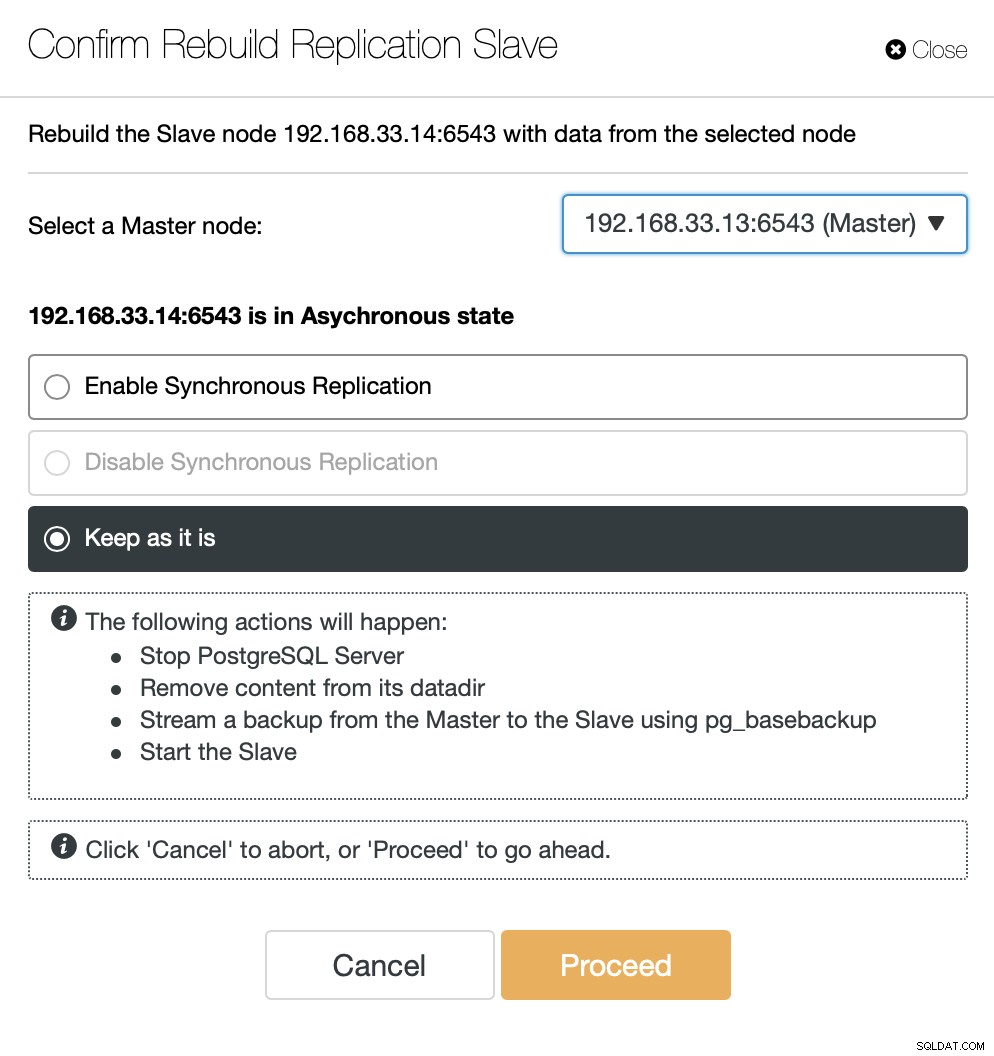
ClusterControl będzie przesyłać strumieniowo kopie zapasowe z nowego serwera podstawowego i skonfiguruje replikację.
Wnioski
Automatyczne przełączanie awaryjne jest ważną częścią każdej produkcyjnej bazy danych Moodle. Może skrócić przestoje w przypadku awarii serwera, ale także podczas wykonywania typowych zadań konserwacyjnych lub migracji. Ważne jest, aby zrobić to dobrze, ponieważ ważne jest, aby oprogramowanie do przełączania awaryjnego podejmowało właściwe decyzje.