Jak głęboko powinniśmy z tym zagłębić się? Zacznę od tego, że w chwili pisania tego tekstu mogłem znaleźć tylko 3 książki na Amazon o PostgreSQL w chmurze i 117 dyskusji na listach dyskusyjnych PostgreSQL na temat Aurora PostgreSQL. To nie wygląda na dużo i pozostawia mnie, ciekawego użytkownika końcowego PostgreSQL, z oficjalną dokumentacją jako jedynym miejscem, w którym mógłbym naprawdę dowiedzieć się więcej. Ponieważ nie mam ani umiejętności, ani wiedzy, aby przeżyć dużo głębsze przygody, jest AWS re:Invent 2018 dla tych, którzy szukają tego rodzaju dreszczyku emocji. Mogę zadowolić się artykułem Wernera o kworach.
Aby się rozgrzać, zacząłem od strony głównej Aurora PostgreSQL, gdzie zauważyłem, że benchmark pokazujący, że Aurora PostgreSQL jest trzy razy szybszy niż standardowy PostgreSQL działający na tym samym sprzęcie, pochodzi z PostgreSQL 9.6. Jak się później dowiedziałem, 9.6.9 jest obecnie domyślną opcją podczas konfigurowania nowego klastra. To bardzo dobra wiadomość dla tych, którzy nie chcą lub nie mogą od razu uaktualnić. A dlaczego tylko 99,99% dostępności? Jedno wyjaśnienie można znaleźć w artykule Bruce'a Momjiana.
Kompatybilność
Według AWS, Aurora PostgreSQL jest wpuszczanym zamiennikiem PostgreSQL, a dokumentacja stwierdza:
Kod, narzędzia i aplikacje, których używasz dzisiaj z istniejącymi bazami danych MySQL i PostgreSQL, mogą być używane z Aurora.
Potwierdzają to często zadawane pytania dotyczące Aurory:
Oznacza to, że większość kodu, aplikacji, sterowników i narzędzi, których już dzisiaj używasz w swoich bazach danych PostgreSQL, może być używana z Aurora z niewielkimi lub żadnymi zmianami. Silnik bazy danych Amazon Aurora został zaprojektowany tak, aby był kompatybilny z PostgreSQL 9.6 i 10 i obsługuje ten sam zestaw rozszerzeń PostgreSQL, które są obsługiwane przez RDS dla PostgreSQL 9.6 i 10, co ułatwia przenoszenie aplikacji między dwoma silnikami.
„Większość” w powyższym tekście sugeruje, że nie ma 100% gwarancji, w takim przypadku osoby poszukujące pewności powinny rozważyć zakup wsparcia technicznego od AWS Professional Services lub partnerów Aamazon Aurora. Na marginesie zauważyłem, że żaden z profesjonalnych dostawców hostingu PostgreSQL zatrudniających głównych współtwórców społeczności nie znajduje się na tej liście.
Ze strony FAQ Aurora dowiadujemy się również, że Aurora PostgreSQL obsługuje te same rozszerzenia co RDS, co z kolei zawiera listę większości rozszerzeń społeczności i kilka dodatków.
Koncepcje
Jako część Amazon RDS, Aurora PostgreSQL ma własną terminologię:
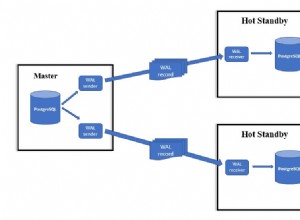
- Klaster:instancja podstawowej bazy danych w trybie odczytu/zapisu i zero lub więcej replik Aurora. Podstawowa baza danych jest często określana jako Master w `diagramach AWS`_ lub Writer w konsoli AWS. Na podstawie diagramu referencyjnego możemy poczynić ciekawą obserwację:Aurora pisze trzy razy. Ponieważ opóźnienie między punktami AZ jest zwykle wyższe niż w ramach tego samego punktu AZ, transakcja jest uważana za zatwierdzoną, gdy tylko zostanie zapisana w kopii danych w tym samym punkcie AZ, w przeciwnym razie opóźnienie i potencjalne przestoje między punktami AZ.
- Wolumen klastra:wolumin wirtualnej bazy danych obejmujący wiele stref od A.
- URL Aurora:para `host:port`.
- Punkt końcowy klastra:adres URL Aurora dla podstawowej bazy danych. Jest jeden punkt końcowy klastra.
- Punkt końcowy czytnika:adres URL Aurora dla zestawu replik. Dla porównania z DNS jest to alias (CNAME). Żądania odczytu są równoważone obciążeniem między dostępnymi replikami.
- Niestandardowy punkt końcowy:URL Aurora do grupy składającej się z jednej lub więcej instancji DB.
- Punkt końcowy instancji:adres URL Aurora do określonej instancji bazy danych.
- Wersja Aurora:Wersja produktu zwrócona przez `SELECT AURORA_VERSION();`.
Wydajność i monitorowanie PostgreSQL w AWS Aurora
Rozmiar
Aurora PostgreSQL stosuje konfigurację najlepszego zgadywania, opartą na rozmiarze instancji DB i pojemności pamięci, pozostawiając dalsze dostrajanie DBA poprzez użycie grup parametrów DB.
Wybierając instancję DB, oprzyj swój wybór na żądanej wartości dla max_connections.
Skalowanie
Aurora PostgreSQL oferuje automatyczne i ręczne skalowanie. Skalowanie w poziomie replik do odczytu jest zautomatyzowane dzięki wykorzystaniu metryk wydajności. Skalowanie w pionie można zautomatyzować za pomocą interfejsów API.
Skalowanie poziome przenosi tryb offline na kilka minut podczas wymiany silnika obliczeniowego i wykonywania wszelkich operacji konserwacyjnych (aktualizacje, poprawki). Dlatego AWS zaleca wykonywanie takich operacji podczas przerw konserwacyjnych.
Skalowanie w obu kierunkach to pestka:
 Skalowanie w pionie:modyfikowanie klasy instancji
Skalowanie w pionie:modyfikowanie klasy instancji  Skalowanie w poziomie:dodawanie repliki czytnika.
Skalowanie w poziomie:dodawanie repliki czytnika. Na poziomie pamięci miejsce jest dodawane w przyrostach 10G. Przydzielone miejsce nigdy nie jest odzyskiwane, zobacz poniżej, jak rozwiązać to ograniczenie.
Pamięć
Jak wspomniano powyżej, Aurora PostgreSQL została zaprojektowana tak, aby wykorzystać kworum w celu poprawy spójności wydajności.
Ponieważ bazowa pamięć masowa jest współużytkowana przez wszystkie instancje bazy danych w tym samym klastrze, nie są wymagane żadne dodatkowe zapisy w węzłach oczekujących. Ponadto dodawanie lub usuwanie instancji DB nie zmienia podstawowych danych.
Zastanawiasz się, co te Oś jednostki oznaczają na rachunku miesięcznym? Często zadawane pytania dotyczące Aurory ponownie pojawiają się na ratunek, aby wyjaśnić, co IO jest w kontekście monitorowania i rozliczeń. Read IO jako odpowiednik odczytanej strony bazy danych o wielkości 8 KB, a Write IO jako odpowiednik 4 KB zapisanego w warstwie pamięci masowej.
Wysoka współbieżność
Aby w pełni wykorzystać projekt Aurory o wysokiej współbieżności, zaleca się skonfigurowanie aplikacji do obsługi dużej liczby jednoczesnych zapytań i transakcji.
Aplikacje zaprojektowane do kierowania zapytań odczytu i zapisu do odpowiednio rezerwowych i głównych węzłów bazy danych będą korzystać z punktu końcowego repliki czytnika Aurora PostgreSQL.
Połączenia są równoważone w obciążeniu między replikami do odczytu.
Korzystając z niestandardowych instancji bazy danych punktów końcowych o większej pojemności, można grupować razem w celu uruchomienia intensywnego obciążenia, takiego jak analityka.
Punkty końcowe instancji DB mogą być używane do precyzyjnego równoważenia obciążenia lub szybkiego przełączania awaryjnego.
Pamiętaj, że aby punkty końcowe czytnika mogły równoważyć obciążenie poszczególnych zapytań, każde zapytanie musi zostać wysłane jako nowe połączenie.
Buforowanie
Aurora PostgreSQL wykorzystuje technikę Survivable Cache Warming, która zapewnia zachowanie daty w buforze, eliminując potrzebę ponownego zapełniania lub rozgrzewania pamięci podręcznej po ponownym uruchomieniu bazy danych.
Replikacja
Opóźnienie replikacji między replikami jest utrzymywane w zakresie jednocyfrowych milisekund. Chociaż nie jest to dostępne dla PostgreSQL, dobrze jest wiedzieć, że opóźnienie replikacji między regionami jest utrzymywane w ciągu 10 milisekund.
Zgodnie z dokumentacją opóźnienie repliki wzrasta w okresach dużych żądań zapisu.
Zapytanie o plany wykonania
Opierając się na założeniu, że wydajność zapytań spada z czasem z powodu różnych zmian w bazie danych, rolą tego komponentu Aurora PostgreSQL jest utrzymywanie listy zatwierdzonych lub odrzuconych planów wykonania zapytań.
Plany są zatwierdzane lub odrzucane przy użyciu metod proaktywnych lub reaktywnych.
Gdy plan wykonania zostanie oznaczony jako odrzucony, plan wykonania zapytania zastępuje decyzje optymalizatora PostgreSQL i zapobiega wykonaniu „złego” planu.
Ta funkcja wymaga Aurora 2.1.0 lub nowszej.
Wysoka dostępność i replikacja PostgreSQL w AWS Aurora
W warstwie pamięci masowej Aurora PostgreSQL zapewnia trwałość, replikując każde 10 GB woluminu pamięci masowej sześciokrotnie w 3 strefach AZ (każdy region składa się zwykle z 3 AZ) przy użyciu fizycznej replikacji synchronicznej. Dzięki temu zapisy w bazie danych mogą kontynuować pracę nawet po utracie 2 kopii danych. Dostępność odczytu pozwala przetrwać utratę 3 kopii danych.
Repliki do odczytu zapewniają, że niesprawną instancję podstawową można szybko zastąpić, promując jedną z 15 dostępnych replik. Po wybraniu wdrożenia multi-AZ automatycznie tworzona jest jedna replika do odczytu. Przełączanie awaryjne nie wymaga interwencji użytkownika, a operacje bazy danych są wznawiane w mniej niż 30 sekund.
W przypadku wdrożeń z jednym systemem AZ procedura odzyskiwania obejmuje przywracanie z ostatniej znanej dobrej kopii zapasowej. Według często zadawanych pytań Aurora proces kończy się w mniej niż 15 minut, jeśli baza danych musi zostać przywrócona w innym AZ. Dokumentacja nie jest tak szczegółowa, twierdząc, że proces przywracania zajmuje mniej niż 10 minut.
Po stronie aplikacji nie są wymagane żadne zmiany, aby połączyć się z nową instancją bazy danych, ponieważ punkt końcowy klastra nie zmienia się podczas promocji repliki lub przywracania instancji.
Krok 1:usuń instancję podstawową, aby wymusić przełączenie awaryjne:
 Automatyczne przełączanie awaryjne Krok 1:usuń podstawowy
Automatyczne przełączanie awaryjne Krok 1:usuń podstawowy Krok 2:automatyczne przełączanie awaryjne zakończone
 Automatyczne przełączanie awaryjne Krok 2:przełączanie awaryjne zakończone.
Automatyczne przełączanie awaryjne Krok 2:przełączanie awaryjne zakończone. W przypadku obciążonych baz danych czas odzyskiwania po ponownym uruchomieniu lub awarii jest znacznie skrócony, ponieważ Aurora PostgreSQL nie musi odtwarzać dzienników transakcji.
W ramach usługi w pełni zarządzanej uszkodzone bloki danych i dyski są automatycznie zastępowane.
Przełączanie awaryjne, gdy istnieją repliki, zajmuje do 120 sekund, często poniżej 60 sekund. Szybsze czasy przywracania można osiągnąć, jeśli z góry zostaną określone warunki przełączania awaryjnego, w którym to przypadku replikom można przypisać priorytety przełączania awaryjnego.
Aurora PostgreSQL dobrze współpracuje z Amazon RDS – instancja Aurora może działać jako replika do odczytu dla podstawowej instancji RDS.
Aurora PostgreSQL obsługuje replikację logiczną, która, podobnie jak w wersji społecznościowej, może zostać wykorzystana do pokonania wbudowanych ograniczeń replikacji. Nie ma automatyzacji ani interfejsu konsoli AWS.
Bezpieczeństwo PostgreSQL na AWS Aurora
Na poziomie sieci Aurora PostgreSQL wykorzystuje podstawowe komponenty AWS, VPC do izolacji sieci w chmurze i grupy bezpieczeństwa do kontroli dostępu do sieci.
Nie ma dostępu superużytkownika. Podczas tworzenia klastra Aurora PostgreSQL tworzy konto główne z podzbiorem uprawnień superużytkownika:
example@sqldat.com:5432 postgres> \du+ postgres
List of roles
Role name | Attributes | Member of | Description
-----------+-------------------------------+-----------------+-------------
postgres | Create role, Create DB +| {rds_superuser} |
| Password valid until infinity | |Aby zabezpieczyć przesyłane dane, Aurora PostgreSQL zapewnia natywną obsługę SSL/TLS, którą można skonfigurować dla instancji bazy danych.
Wszystkie dane w spoczynku mogą być szyfrowane przy minimalnym wpływie na wydajność. Dotyczy to również kopii zapasowych, migawek i replik.
 Szyfrowanie w spoczynku.
Szyfrowanie w spoczynku. Uwierzytelnianie jest kontrolowane przez zasady uprawnień, a tagowanie umożliwia dalszą kontrolę nad tym, co użytkownicy mogą robić i jakie zasoby.
Wywołania API używane przez wszystkie usługi w chmurze są rejestrowane w CloudTrail.
Ograniczone zarządzanie hasłami po stronie klienta jest dostępne za pośrednictwem parametru rds.restrict_password_commands.
Kopia zapasowa i odzyskiwanie PostgreSQL na AWS Aurora
Kopie zapasowe są domyślnie włączone i nie można ich wyłączyć. Zapewniają odzyskiwanie do określonego momentu przy użyciu pełnej dziennej migawki jako podstawowej kopii zapasowej.
Przywracanie z automatycznej kopii zapasowej ma kilka wad:czas przywracania może wynosić kilka godzin, a utrata danych może trwać do 5 minut przed awarią. Wdrożenia Amazon RDS Multi-AZ rozwiązują ten problem, promując replikę do odczytu jako podstawową, bez utraty danych.
Migawki bazy danych są szybkie i nie wpływają na wydajność klastra. Można je kopiować lub udostępniać innym użytkownikom.
Wykonanie migawki jest prawie natychmiastowe:
 Czas migawki.
Czas migawki. Przywracanie migawki jest również szybkie. Porównaj z PITR:
Kopie zapasowe i migawki są przechowywane w S3, który oferuje jedenaście dziewiątek trwałości.
Oprócz tworzenia kopii zapasowych i migawek, Aurora PostgreSQL umożliwia klonowanie baz danych. Jest to wydajna metoda tworzenia kopii dużych zbiorów danych. Na przykład klonowanie wielu terabajtów danych zajmuje tylko kilka minut i nie ma wpływu na wydajność.
Aurora PostgreSQL — demonstracja odzyskiwania do punktu w czasie
Łączenie z klastrem:
~ $ export PGUSER=postgres PGPASSWORD=postgres PGHOST=s9s-us-east-1.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
~ $ psql
Pager usage is off.
psql (11.3, server 10.7)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.Wypełnij tabelę danymi:
example@sqldat.com:5432 postgres> create table s9s (id serial not null, msg text, created timestamptz not null default now());
CREATE TABLE
example@sqldat.com:5432 postgres> select * from s9s;
id | msg | created
----+------+-------------------------------
1 | test | 2019-06-25 07:57:40.022125+00
2 | test | 2019-06-25 07:57:57.666222+00
3 | test | 2019-06-25 07:58:05.593214+00
4 | test | 2019-06-25 07:58:08.212324+00
5 | test | 2019-06-25 07:58:10.156834+00
6 | test | 2019-06-25 07:59:58.573371+00
7 | test | 2019-06-25 07:59:59.5233+00
8 | test | 2019-06-25 08:00:00.318474+00
9 | test | 2019-06-25 08:00:11.153298+00
10 | test | 2019-06-25 08:00:12.287245+00
(10 rows)Rozpocznij przywracanie:
 Przywracanie do punktu w czasie:rozpocznij przywracanie.
Przywracanie do punktu w czasie:rozpocznij przywracanie. 
Po zakończeniu przywracania zaloguj się i sprawdź:
~ $ psql -h pg107-dbt3medium-restored-cluster.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com
Pager usage is off.
psql (11.3, server 10.7)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
example@sqldat.com:5432 postgres> select * from s9s;
id | msg | created
----+------+-------------------------------
1 | test | 2019-06-25 07:57:40.022125+00
2 | test | 2019-06-25 07:57:57.666222+00
3 | test | 2019-06-25 07:58:05.593214+00
4 | test | 2019-06-25 07:58:08.212324+00
5 | test | 2019-06-25 07:58:10.156834+00
6 | test | 2019-06-25 07:59:58.573371+00
(6 rows)Najlepsze praktyki
Monitorowanie i audyt
- Zintegruj strumienie aktywności bazy danych z monitorowaniem stron trzecich w celu monitorowania aktywności bazy danych pod kątem zgodności i wymagań prawnych.
- W pełni zarządzana usługa bazy danych nie oznacza braku odpowiedzialności — zdefiniuj metryki do monitorowania procesora, pamięci RAM, miejsca na dysku, sieci i połączeń z bazą danych.
- Aurora PostgreSQL integruje się ze standardowym narzędziem monitorującym AWS CloudWatch, a także zapewnia dodatkowe monitory dla Aurora Metrics, Aurora Enhanced Metrics, Performance Insight Counters, Aurora PostgreSQL Replication, a także dla wskaźników RDS, które można dalej grupować według wymiarów RDS.
- Monitoruj średnie obciążenie bazy danych aktywnych sesji według oczekiwania na oznaki narzutu połączeń, zapytania SQL wymagające dostrojenia, rywalizację o zasoby lub niewymiarową klasę instancji bazy danych.
- Skonfiguruj powiadomienia o zdarzeniach.
- Skonfiguruj parametry dziennika błędów.
- Monitoruj zmiany konfiguracji komponentów klastra bazy danych:instancji, grup podsieci, migawek, grup bezpieczeństwa.
Replikacja
- Użyj natywnego partycjonowania tabeli dla obciążeń, które przekraczają maksymalną klasę instancji DB i pojemność pamięci
Szyfrowanie
- Zaszyfrowana baza danych musi mieć włączone kopie zapasowe, aby zapewnić możliwość przywrócenia danych w przypadku unieważnienia klucza szyfrowania.
Konto główne
- Nie używaj psql do zmiany hasła użytkownika głównego.
Rozmiar
- Rozważ użycie różnych klas instancji w klastrze, aby obniżyć koszty.
Grupy parametrów
- Dostrój za pomocą grup parametrów, aby zaoszczędzić $$$.
Prezentacja grup parametrów
Bieżące ustawienia:
example@sqldat.com:5432 postgres> show shared_buffers ;
shared_buffers
----------------
10112136kB
(1 row)Utwórz nową grupę parametrów i ustaw nową wartość dla całego klastra:
 Aktualizacja całego klastra shared_buffers.
Aktualizacja całego klastra shared_buffers. Powiąż grupę parametrów niestandardowych z klastrem:

Uruchom ponownie program piszący i sprawdź wartość:
example@sqldat.com:5432 postgres> show shared_buffers ;
shared_buffers
----------------
1GB
(1 row)- Ustaw lokalną strefę czasową
Domyślnie strefa czasowa to UTC:
example@sqldat.com:5432 postgres> show timezone;
TimeZone
----------
UTC
(1 row)Ustawianie nowej strefy czasowej:
Konfigurowanie strefy czasowej A następnie sprawdź:
example@sqldat.com:5432 postgres> show timezone;
TimeZone
------------
US/Pacific
(1 row)Zauważ, że lista wartości stref czasowych akceptowanych przez Amazon Aurora nie jest zestawami stref czasowych znalezionymi we wcześniejszym PostgreSQL.
- Sprawdź parametry instancji, które są zastępowane przez parametry klastra
- Użyj narzędzia do porównywania grup parametrów.
Migawki
- Unikaj dodatkowych opłat za przechowywanie, udostępniając migawki innym kontom, aby umożliwić przywracanie w odpowiednich środowiskach.
Konserwacja
- Zmień domyślne okno konserwacji zgodnie z harmonogramem organizacji.
Awaryjne
- Skróć czas odzyskiwania, konfigurując zarządzanie pamięcią podręczną klastra.
- Obniż wartości utrzymywania aktywności protokołu TCP jądra na kliencie i skonfiguruj pamięć podręczną DNS aplikacji oraz ciągi TTL i połączenia PostgreSQL.
DBA Uwaga!
Oprócz znanych ograniczeń unikaj lub pamiętaj o następujących kwestiach:
Szyfrowanie
- Po utworzeniu bazy danych nie można zmienić stanu szyfrowania.
Aurora bezserwerowa
- W tej chwili wersja PostgreSQL Aurora Serverless jest dostępna tylko w ograniczonym podglądzie.
Zapytanie równoległe
- Amazon Parallel Query nie jest dostępny, chociaż funkcja o tej samej nazwie jest dostępna od wersji PostgreSQL 9.6.
Punkty końcowe
Z zarządzania połączeniami Amazon:
- 5 niestandardowych punktów końcowych na klaster
- Nazwy niestandardowego punktu końcowego nie mogą przekraczać 63 znaków
- Nazwy punktów końcowych klastra są unikalne w obrębie tego samego regionu
- Jak widać na powyższym zrzucie ekranu (aurora-custom-endpoint-details) READER i DOWOLNE niestandardowe typy punktów końcowych nie są dostępne, użyj CLI
- Niestandardowe punkty końcowe nie są świadome, że repliki są tymczasowo niedostępne
Replikacja
- W przypadku promowania repliki do poziomu podstawowego połączenia za pośrednictwem punktu końcowego czytnika mogą być przez krótki czas nadal kierowane do promowanej repliki.
- Repliki międzyregionalne nie są obsługiwane
- Podczas wydania pod koniec listopada 2017 r. wersja zapoznawcza Amazon Aurora Multi-Master nadal nie jest dostępna dla PostgreSQL
- Obserwuj pogorszenie wydajności, gdy w klastrze włączona jest replikacja logiczna.
- Replikacja logiczna wymaga opublikowanego działającego silnika PostgreSQL 10.6 lub nowszego.
Pamięć
- Maksymalna przydzielona pamięć nie zmniejsza się po usunięciu danych, a miejsce nie jest odzyskiwane przez przywracanie z migawek. Jedynym sposobem na odzyskanie miejsca jest wykonanie logicznego zrzutu do nowego klastra.
Kopia zapasowa i odzyskiwanie
- Przechowywanie kopii zapasowych nie jest przedłużane, gdy klaster jest zatrzymany.
- Maksymalny okres przechowywania to 35 dni — używaj ręcznych migawek, aby wydłużyć okres przechowywania.
- Odzyskiwanie do punktu w czasie przywraca do nowego klastra DB.
- krótkie przerwanie odczytów podczas przełączania awaryjnego do replik.
- Scenariusze odzyskiwania po awarii nie są dostępne w różnych regionach.
Migawki
- Przywracanie ze zrzutu tworzy nowy punkt końcowy (migawki można przywrócić tylko do nowego klastra).
- Po przywróceniu migawki niestandardowe punkty końcowe muszą zostać odtworzone.
- Przywracanie z migawek resetuje lokalną strefę czasową do UTC.
- Przywracanie z migawek nie zachowuje niestandardowych grup zabezpieczeń.
- Migawki można udostępniać maksymalnie 20 identyfikatorom kont AWS.
- Migawki nie mogą być udostępniane między regionami.
- Przyrostowe zrzuty są zawsze kopiowane jako pełne zrzuty między regionami i w ramach tego samego regionu.
- Kopiowanie migawek między regionami nie zachowuje grup parametrów innych niż domyślne.
Płatności
- Rachunek za 10 minut dotyczy nowych instancji, a także po zmianie pojemności (liczba obliczeniowa lub pamięć masowa).
Uwierzytelnianie
- Korzystanie z uwierzytelniania bazy danych IAM nakłada ograniczenie liczby połączeń na sekundę.
- Konto główne ma cofnięte pewne uprawnienia superużytkownika.
Uruchamianie i zatrzymywanie
Z przeglądu zatrzymywania i uruchamiania klastra Aurora DB:
- Klastrów nie można pozostawić zatrzymanych na czas nieokreślony, ponieważ są uruchamiane automatycznie po 7 dniach.
- Poszczególne instancje DB nie mogą być zatrzymane.
Aktualizacje
- Aktualizacje głównych wersji w miejscu nie są obsługiwane.
- Propagacja zmian grup parametrów zarówno dla instancji DB, jak i klastra DB zajmuje co najmniej 5 minut.
Klonowanie
- 15 klonów na bazę danych (oryginalnych lub kopii).
- Klony nie są usuwane podczas usuwania źródłowej bazy danych.
Skalowanie
- Automatyczne skalowanie wymaga, aby wszystkie repliki były dostępne.
- Może istnieć tylko `jedna polityka automatycznego skalowania`_ na metrykę na klaster.
- Skalowanie poziome podstawowej instancji bazy danych (klasy instancji) nie jest w pełni automatyczne. Przed skalowaniem klastra wyzwala automatyczne przełączenie awaryjne do jednej z replik. Po zakończeniu skalowania nowa instancja musi być ręcznie promowana z czytelnika na pisarza:
 Nowa instancja pozostawiona w trybie czytnika po zmianie klasy instancji DB.
Nowa instancja pozostawiona w trybie czytnika po zmianie klasy instancji DB.
Monitorowanie
- Publikowanie dzienników PostgreSQL do CloudWatch wymaga minimalnej wersji silnika bazy danych 9.6.6 i 10.4.
- Tylko niektóre metryki Aurora są dostępne w konsoli RDS, a inne metryki mają różne nazwy i jednostki miary.
- Domyślnie dzienniki ulepszonego monitorowania są przechowywane w CloudWatch przez 30 dni.
- Wskaźniki Cloudwatch i Enhanced Monitoring będą się różnić, ponieważ gromadzą dane z hipernadzorcy i odpowiednio agenta działającego na instancji.
- Performance Insights_ agreguje metryki we wszystkich bazach danych w ramach instancji DB.
- Wyrażenia SQL są ograniczone do 500 znaków podczas przeglądania w interfejsie CLI i API AWS Performance Insights.
Migracja
- Tylko nieszyfrowane migawki bazy danych RDS mogą być szyfrowane w spoczynku.
- Migracje przy użyciu techniki Aurora Read Replica zajmują kilka godzin na TiB.
Rozmiar
- Najmniejsza dostępna klasa instancji to db.t3.medium, a największa db.r5.24xlarge. Dla porównania, silnik MySQL oferuje db.t2.small i db.t2.medium, jednak nie ma db.r5.24xlarge w górnym zakresie.
- Górny limit max_connections to 262,143.
Zarządzanie planem zapytań
- Stwierdzenia wewnątrz funkcji PL/pgSQL są nieobsługiwane.
Migracja
Aurora PostgreSQL nie zapewnia usług bezpośredniej migracji, a zadanie jest przenoszone na wyspecjalizowany produkt AWS, a mianowicie AWS DMS.
Wniosek
Jako w pełni zarządzany zamiennik upstream PostgreSQL, Amazon Aurora PostgreSQL wykorzystuje technologie, które napędzają chmurę AWS, aby usunąć złożoność wymaganą do konfiguracji usług, takich jak automatyczne skalowanie, równoważenie obciążenia zapytań, dane niskiego poziomu replikacja, przyrostowe kopie zapasowe i szyfrowanie.
Architektura i konserwatywne podejście do aktualizacji silnika PostgreSQL zapewnia wydajność i stabilność, których poszukują organizacje od małych do dużych.
Nieodłączne ograniczenia są tylko dowodem na to, że budowanie bazy danych jako usługi na dużą skalę jest złożonym zadaniem, pozostawiając wysoce wyspecjalizowanym dostawcom hostingu PostgreSQL niszę rynkową, do której mogą się dostać.