To jest druga część wieloserii Jak monitorować PostgreSQL działający w kontenerze Docker. W części 1 przedstawiłem przegląd kontenerów dockera, polityk i sieci. W tej części będziemy kontynuować konfigurację dockera i wreszcie włączyć monitorowanie za pomocą ClusterControl.
PostgreSQL to oldschoolowa baza danych typu open source, której popularność wciąż rośnie, jest szeroko stosowana i akceptowana w większości dzisiejszych środowisk chmurowych.
Kiedy jest używany w kontenerze, może być łatwo konfigurowany i zarządzany przez Docker, używając różnych tagów do tworzenia i wysyłany do dowolnego komputera na świecie z zainstalowanym Dockerem, ale to wszystko dotyczy Dockera.
Teraz omówimy PostgreSQL i na początek wypiszmy ich sześć głównych procesów działających jednocześnie w kontenerze przez użytkownika systemu operacyjnego o nazwie „postgres”, który jest inny niż użytkownik „postgres” w bazie danych, ten jest superużytkownikiem.
Pamiętaj, że niebieska strzałka na obrazach pokazuje polecenia wprowadzone do kontenera.
$ ps auxww Główne procesy PostgreSQL
Główne procesy PostgreSQL Pierwszym procesem na liście jest serwer PostgreSQL, a pozostałe są przez niego uruchamiane. Ich obowiązki polegają zasadniczo na analizowaniu tego, co dzieje się na serwerze, będąc podprocesami wprowadzającymi statystyki, piszący logi i tego typu rzeczy.
Użyjemy ClusterControl do monitorowania aktywności wewnątrz tego kontenera z serwerem PostgreSQL. Aby to zrobić, będziemy musieli mieć zainstalowany SSH, aby bezpiecznie się z nimi połączyć.
Bezpieczny serwer powłoki (SSH)
Aby zebrać informacje o kontenerze PostgreSQL, nic nie jest lepsze niż SSH. Daje zdalny dostęp dla jednego adresu IP do drugiego i to wszystko, czego ClusterControl potrzebuje do wykonania zadania.
SSH należy pobrać z repozytorium, a do tego musimy znajdować się w kontenerze.
$ docker container exec -it postgres-2 bash
$ apt-get update && apt-get install -y openssh-server openssh-client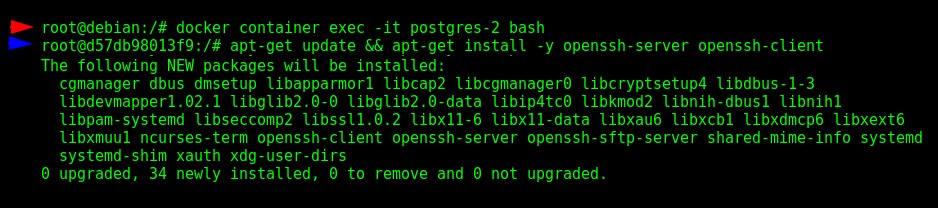 Instalacja SSH w kontenerze „postgres-2”
Instalacja SSH w kontenerze „postgres-2” Po instalacji edytujemy konfigurację, uruchamiamy usługę, ustawiamy hasło dla użytkownika root i ostatecznie opuszczamy kontener:
$ sed -i 's|^PermitRootLogin.*|PermitRootLogin yes|g' /etc/ssh/sshd_config
$ sed -i 's|^#PermitRootLogin.*|PermitRootLogin yes|g' /etc/ssh/sshd_config
$ service ssh start
$ passwd
$ exit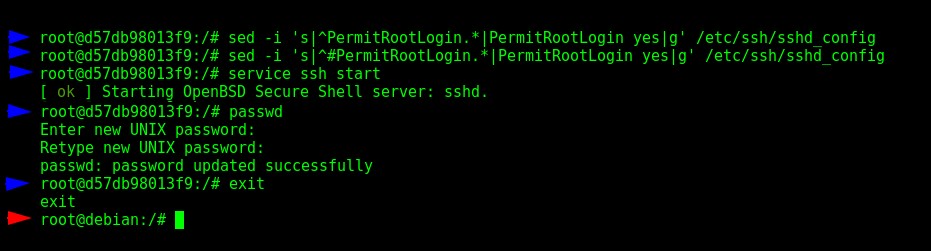 Konfiguracja SSH w kontenerze "postgres-2", część 1/2
Konfiguracja SSH w kontenerze "postgres-2", część 1/2 Monitorowanie za pomocą ClusterControl
ClusterControl ma dogłębny system integracji, który jest w stanie monitorować wszystkie procesy PostgreSQL w czasie rzeczywistym, a także zawiera bibliotekę Doradców, aby chronić dane, śledzić wydajność bazy danych i oczywiście dostarczać alerty w przypadku wystąpienia anomalii.
Po skonfigurowaniu protokołu SSH, ClusterControl może monitorować aktywność sprzętową systemu operacyjnego i zapewniać wgląd zarówno w bazę danych, jak i warstwę zewnętrzną.
Uruchomimy nowy kontener i opublikujemy go na porcie 5000 naszego komputera, a następnie będziemy mogli uzyskać dostęp do systemu przez naszą przeglądarkę.
$ docker container run --name s9s-ccontrol --network bridge-docker -p 5000:80 -d severalnines/clustercontrol Uruchamianie kontenera „s9s-ccontrol” dla programu Manynines ClusterControl
Uruchamianie kontenera „s9s-ccontrol” dla programu Manynines ClusterControl Po wdrożeniu pozostaje tylko konfiguracja SSH i mamy dobre wieści, ponieważ jesteśmy w sieci mostów zdefiniowanej przez użytkownika, możemy używać DNS!
$ docker container exec -it s9s-ccontrol bash
$ ssh-copy-id postgres-2 Konfiguracja SSH w kontenerze "postgres-2", część 2/2
Konfiguracja SSH w kontenerze "postgres-2", część 2/2 Po wpisaniu „tak” i podaniu podanego wcześniej hasła możliwy jest dostęp do kontenera „postgres-2” jako root za pomocą SSH:
$ ssh postgres-2 Pomyślne sprawdzenie połączenia SSH
Pomyślne sprawdzenie połączenia SSH Ten nowy kolor, jasnoniebieski, będzie używany w dalszej części do reprezentowania aktywności w bazie danych. W powyższym przykładzie uzyskaliśmy dostęp do kontenera „postgres-2” z „s9s-ccontrol”, ale nadal jest to użytkownik root. Zachowaj swoją uwagę i krytykę ze mną.
Następnym krokiem jest przejście do przeglądarki i dostęp do https://localhost:5000/clustercontrol/users/welcome/ i zarejestruj konto lub jeśli już je masz, odwiedź https://localhost:5000/clustercontrol/users/login .
Następnie „Importuj istniejący serwer/klaster” i wprowadź wcześniejszą konfigurację. Karta „PostgreSQL &TimescaleDB” musi być zaznaczona. W polu „Użytkownik SSH” dla tej demonstracji wpisz „root”. Następnie wprowadź „Nazwę klastra” i może to być dowolna nazwa, która będzie po prostu zawierać tyle potrzebnych kontenerów PostgreSQL, które chcesz zaimportować i monitorować.
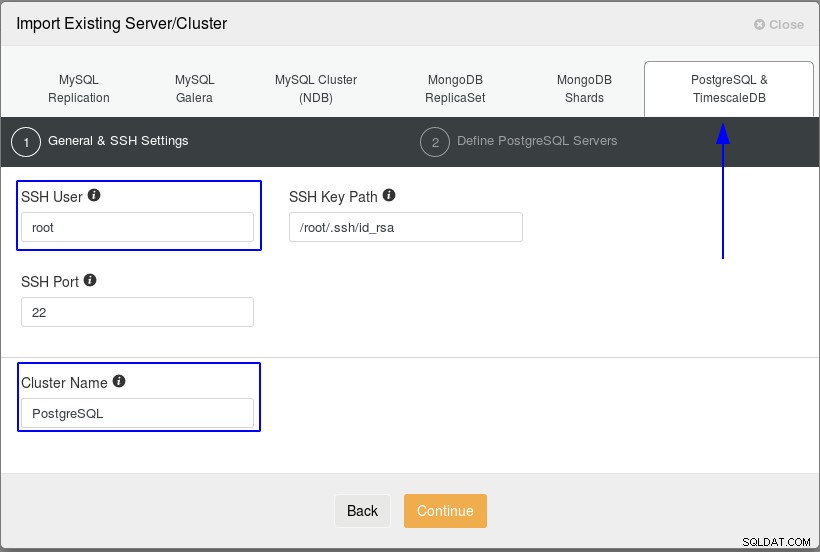 Import bazy danych "postgres-2", część 1/2
Import bazy danych "postgres-2", część 1/2 Teraz nadszedł czas na wprowadzenie informacji o kontenerze PostgreSQL, użytkowniku „postgres”, hasła „5af45Q4ae3Xa3Ff4” i żądanych kontenerach. Niezwykle ważne jest, aby pamiętać, że usługa SSH musi być aktywna w kontenerze PostgreSQL.
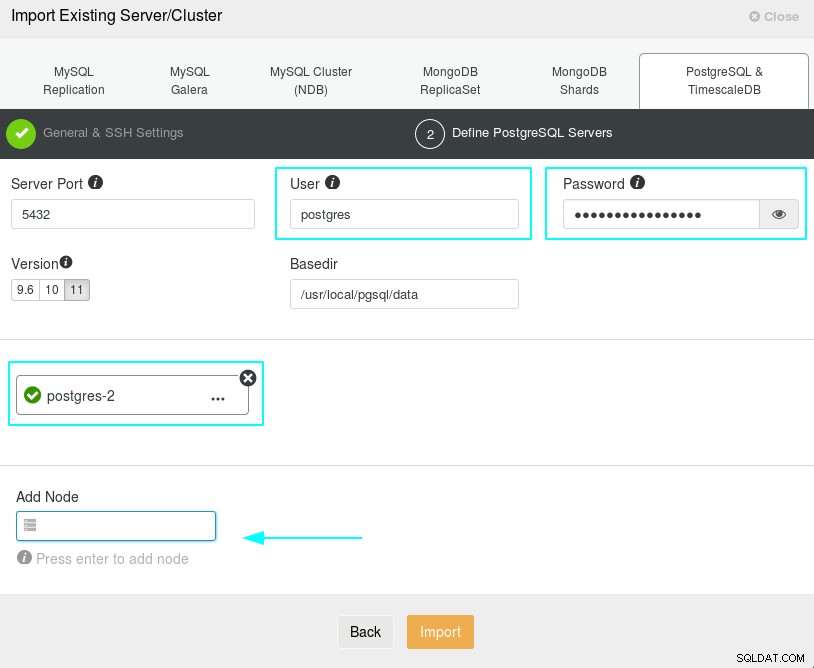 Importowanie kontenera „postgres-2”, część 2/2
Importowanie kontenera „postgres-2”, część 2/2 Po naciśnięciu przycisku „Importuj”, ClusterControl rozpocznie zarządzanie kontenerem PostgreSQL „postgres-2” wewnątrz klastra o nazwie „PostgreSQL” i poinformuje o zakończeniu procesu importowania.
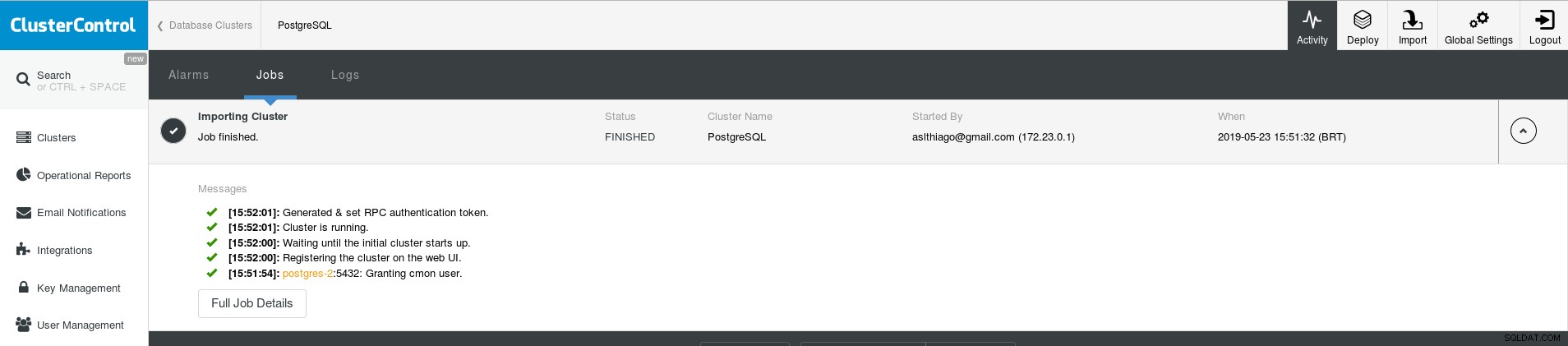 Dziennik dotyczący procesu importowania kontenera „postgres-2”
Dziennik dotyczący procesu importowania kontenera „postgres-2” Po zakończeniu system zostanie wyświetlony w zakładce Klastry, ostatnio utworzony klaster i różne opcje rozdzielone w sekcjach
Naszym pierwszym krokiem wizualizacji będzie opcja Przegląd.
 Pomyślnie zaimportowano klaster PostgreSQL
Pomyślnie zaimportowano klaster PostgreSQL Jak możesz sobie wyobrazić, nasza baza danych jest pusta i dla naszej zabawy nie mamy tu żadnego chaosu, ale grafika nadal działa na małą skalę zawierającą statystyki dotyczące procesów SQL i bazy danych.
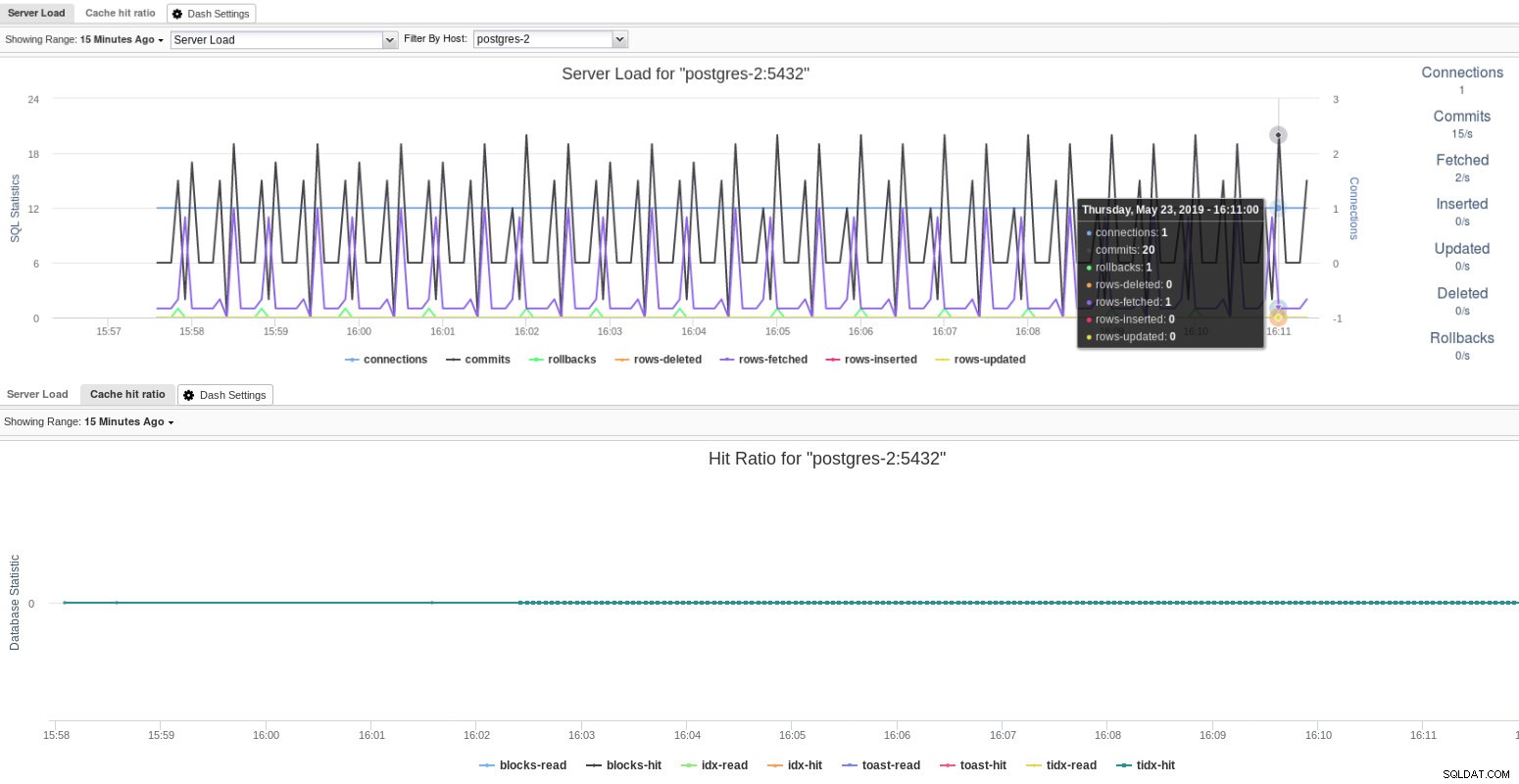 Wyświetlanie statystyk dotyczących aktywności SQL i bazy danych
Wyświetlanie statystyk dotyczących aktywności SQL i bazy danych Symulacja scenariusza w świecie rzeczywistym
Aby dać trochę akcji, utworzyłem plik CSV za pomocą Pythona, eksplorując repozytorium GitHub firmy Socratica, która zapewnia niesamowite kursy na YouTube, i udostępnia te pliki za darmo.
Podsumowując, utworzony plik CSV zawiera 9 milionów, 999 tysięcy i 999 rekordów o osobach, z których każdy zawiera dowód osobisty, imię, nazwisko i datę urodzenia. Rozmiar pliku to 324 MB:
$ du -s -h persons.csv Sprawdzanie rozmiaru pliku CSV
Sprawdzanie rozmiaru pliku CSV Skopiujemy ten plik CSV do kontenera PostgreSQL, następnie skopiujemy go ponownie, ale tym razem do bazy danych, a na koniec sprawdzimy statystyki w ClusterControl.
$ docker container cp persons.csv postgres-2:/persons.csv
$ docker container exec -it postgres-2 bash
$ du -s -h persons.csv
$ su - postgres
$ psql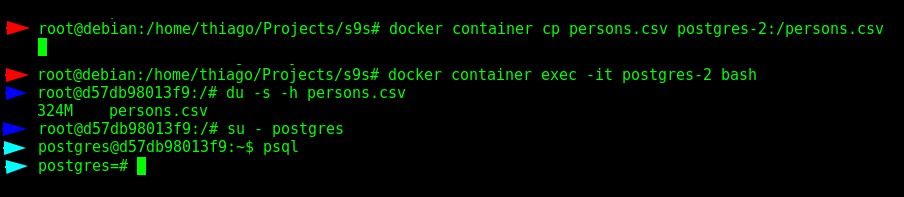 Przeniesienie pliku CSV do kontenera i wprowadzenie do bazy danych
Przeniesienie pliku CSV do kontenera i wprowadzenie do bazy danych Ok, więc jesteśmy teraz w bazie danych, jako superużytkownik „postgres”, zwróć uwagę na różne kolory strzałek.
Teraz musimy utworzyć bazę danych, tabelę i wypełnić ją danymi zawartymi w pliku CSV, a na koniec sprawdzić, czy wszystko działa poprawnie.
$ CREATE DATABASE severalnines;
$ \c severalnines;
$ CREATE TABLE persons (id SERIAL NOT NULL, first_name VARCHAR(50), last_name VARCHAR(50), birthday DATE, CONSTRAINT persons_pkey PRIMARY KEY (id));
$ COPY persons (id, first_name, last_name, birthday) FROM '/persons.csv' DELIMITER ',' CSV HEADER;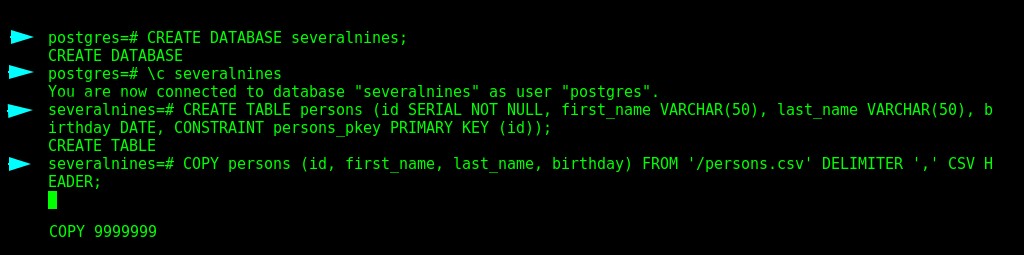 Łączenie z nową bazą danych i importowanie pliku CSV
Łączenie z nową bazą danych i importowanie pliku CSV Ten proces zajmuje kilka minut.
Ok, więc teraz wprowadźmy kilka zapytań:
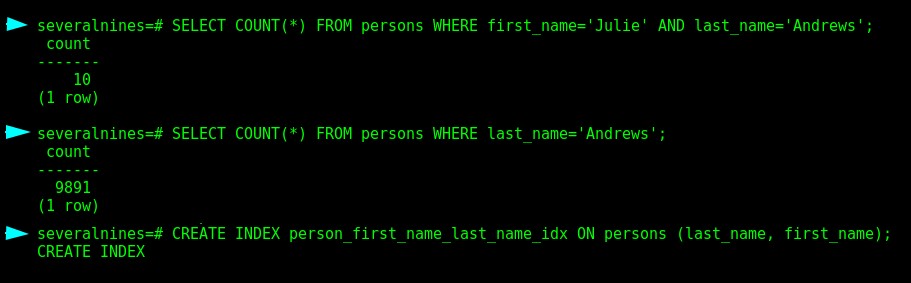 Zapytania w bazie danych „kilkadziesiąt”
Zapytania w bazie danych „kilkadziesiąt” Jeśli spojrzysz teraz na ClusterControl, wystąpiły pewne zmiany w statystykach dotyczących sprzętu:
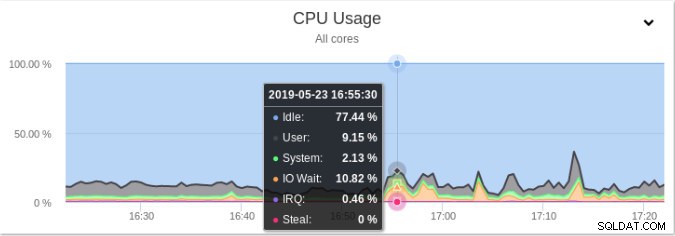 Wyświetlanie statystyk dotyczących procesora w ClusterControl
Wyświetlanie statystyk dotyczących procesora w ClusterControl Cała sekcja do monitorowania zapytań jest dostępna z łatwym w użyciu interfejsem użytkownika:
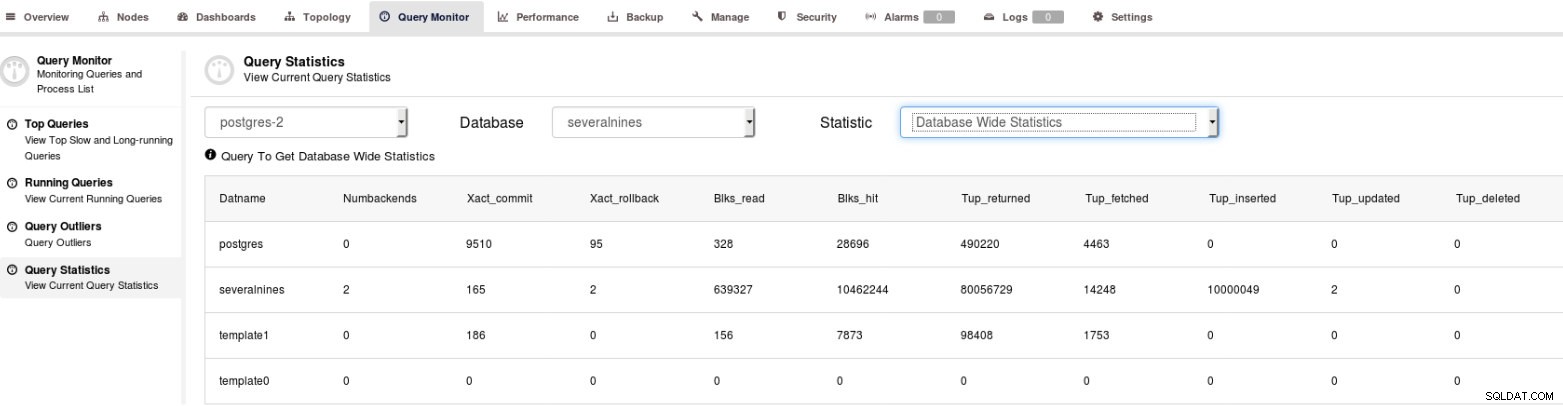 Wyświetlanie statystyk dotyczących zapytań wewnątrz ClusterControl
Wyświetlanie statystyk dotyczących zapytań wewnątrz ClusterControl Statystyki dotyczące bazy danych PostgreSQL służą najlepszym administratorom baz danych do wykonywania całego ich potencjału w zakresie ich głównych obowiązków, a ClusterControl to kompletny system do analizowania każdej czynności zachodzącej w czasie rzeczywistym, dostarczając informacji na podstawie wszystkich danych zebranych z procesów bazy danych.
Dzięki ClusterControl administratorzy baz danych mogą również łatwo poszerzyć swoje umiejętności, korzystając z pełnego zestawu narzędzi do tworzenia kopii zapasowych lokalnie lub w chmurze, replikacji, systemów równoważenia obciążenia, integracji z usługami, LDAP, ChatOps, Prometheus i wielu innych.
Wniosek
W tym artykule konfigurujemy PostgreSQL w Dockerze i integrujemy się z ClusterControl za pomocą User-Defined Bridge Network i SSH, symulując scenariusz zapełniania bazy danych plikiem CSV, a następnie przeprowadzamy ogólne szybkie sprawdzenie w interfejsie użytkownika ClusterControl .