Wysoka dostępność jest wymogiem dla prawie każdej firmy na całym świecie używającej PostgreSQL Powszechnie wiadomo, że PostgreSQL używa Streaming Replication jako metody replikacji. Replikacja strumieniowa PostgreSQL jest domyślnie asynchroniczna, więc możliwe jest zatwierdzenie niektórych transakcji w węźle podstawowym, które nie zostały jeszcze zreplikowane na serwer rezerwowy. Oznacza to, że istnieje możliwość potencjalnej utraty danych.
To opóźnienie w procesie zatwierdzania powinno być bardzo małe... jeśli serwer rezerwowy jest wystarczająco wydajny, aby nadążyć za obciążeniem. Jeśli to małe ryzyko utraty danych jest nie do zaakceptowania w firmie, możesz również użyć replikacji synchronicznej zamiast domyślnej.
W replikacji synchronicznej każde zatwierdzenie transakcji zapisu będzie czekać na potwierdzenie, że zatwierdzenie zostało zapisane w dzienniku zapisu z wyprzedzeniem na dysku zarówno serwera podstawowego, jak i rezerwowego.
Ta metoda minimalizuje możliwość utraty danych. Aby doszło do utraty danych, konieczne byłoby jednoczesne uszkodzenie głównego i rezerwowego.
Wada tej metody jest taka sama dla wszystkich metod synchronicznych, ponieważ przy tej metodzie zwiększa się czas odpowiedzi dla każdej transakcji zapisu. Wynika to z konieczności oczekiwania na wszystkie potwierdzenia, że transakcja została zatwierdzona. Na szczęście nie będzie to miało wpływu na transakcje tylko do odczytu, ale; tylko transakcje zapisu.
W tym blogu pokażesz, jak zainstalować klaster PostgreSQL od podstaw, przekonwertować replikację asynchroniczną (domyślnie) na synchroniczną. Pokażę Ci również, jak cofnąć, jeśli czas odpowiedzi nie jest akceptowalny, ponieważ możesz łatwo wrócić do poprzedniego stanu. Zobaczysz, jak łatwo wdrożyć, skonfigurować i monitorować synchroniczną replikację PostgreSQL za pomocą ClusterControl, używając tylko jednego narzędzia dla całego procesu.
Instalowanie klastra PostgreSQL
Zacznijmy instalować i konfigurować asynchroniczną replikację PostgreSQL, czyli zwykły tryb replikacji używany w klastrze PostgreSQL. Użyjemy PostgreSQL 11 na CentOS 7.
Instalacja PostgreSQL
Postępując zgodnie z oficjalnym przewodnikiem instalacji PostgreSQL, to zadanie jest całkiem proste.
Najpierw zainstaluj repozytorium:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmZainstaluj pakiety klienta i serwera PostgreSQL:
$ yum install postgresql11 postgresql11-serverZainicjuj bazę danych:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11W węźle gotowości można uniknąć ostatniego polecenia (uruchomienie usługi bazy danych), ponieważ przywrócisz kopię zapasową binarną w celu utworzenia replikacji strumieniowej.
Teraz zobaczmy konfigurację wymaganą przez asynchroniczną replikację PostgreSQL.
Konfigurowanie asynchronicznej replikacji PostgreSQL
Konfiguracja węzła głównego
W węźle podstawowym PostgreSQL należy użyć następującej podstawowej konfiguracji, aby utworzyć replikację asynchroniczną. Pliki, które zostaną zmodyfikowane, to postgresql.conf i pg_hba.conf. Ogólnie rzecz biorąc, znajdują się one w katalogu danych (/var/lib/pgsql/11/data/), ale możesz to potwierdzić po stronie bazy danych:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Zmień lub dodaj następujące parametry w pliku konfiguracyjnym postgresql.conf.
Tutaj musisz dodać adres(y) IP, na których będziesz nasłuchiwać. Wartość domyślna to „localhost”, a w tym przykładzie użyjemy „*” dla wszystkich adresów IP na serwerze.
listen_addresses = '*' Ustaw port serwera, na którym chcesz nasłuchiwać. Domyślnie 5432.
port = 5432 Określ, ile informacji jest zapisywanych na listach WAL. Możliwe wartości to minimalna, replika lub logiczna. Wartość hot_standby jest mapowana do repliki i służy do zachowania zgodności z poprzednimi wersjami.
wal_level = hot_standby Ustaw maksymalną liczbę procesów walsendera, które zarządzają połączeniem z serwerem rezerwowym.
max_wal_senders = 16Ustaw minimalną liczbę plików WAL, które mają być przechowywane w katalogu pg_wal.
wal_keep_segments = 32Zmiana tych parametrów wymaga ponownego uruchomienia usługi bazy danych.
$ systemctl restart postgresql-11Pg_hba.conf
Zmień lub dodaj następujące parametry w pliku konfiguracyjnym pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Jak widać, tutaj musisz dodać uprawnienia dostępu użytkownika. Pierwsza kolumna to typ połączenia, które może być hostem lub lokalnym. Następnie należy określić bazę danych (replikację), użytkownika, źródłowy adres IP oraz metodę uwierzytelniania. Zmiana tego pliku wymaga ponownego załadowania usługi bazy danych.
$ systemctl reload postgresql-11Powinieneś dodać tę konfigurację zarówno w węźle podstawowym, jak i rezerwowym, ponieważ będzie ona potrzebna, jeśli węzeł rezerwowy zostanie promowany jako nadrzędny w przypadku awarii.
Teraz musisz utworzyć użytkownika replikacji.
Rola replikacji
ROLE (użytkownik) musi mieć uprawnienie REPLICATION, aby używać go w replikacji strumieniowej.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEPo skonfigurowaniu odpowiednich plików i utworzeniu użytkownika należy utworzyć spójną kopię zapasową z węzła podstawowego i przywrócić ją w węźle gotowości.
Konfiguracja węzła gotowości
W węźle gotowości przejdź do katalogu /var/lib/pgsql/11/ i przenieś lub usuń bieżący katalog danych:
$ cd /var/lib/pgsql/11/
$ mv data data.bkNastępnie uruchom polecenie pg_basebackup, aby uzyskać bieżący główny katalog danych i przypisać właściwego właściciela (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataTeraz musisz użyć następującej podstawowej konfiguracji, aby utworzyć replikację asynchroniczną. Plik, który zostanie zmodyfikowany, to postgresql.conf i musisz utworzyć nowy plik recovery.conf. Oba będą znajdować się w /var/lib/pgsql/11/.
Recovery.conf
Określ, że ten serwer będzie serwerem rezerwowym. Jeśli jest włączony, serwer będzie kontynuował odzyskiwanie, pobierając nowe segmenty WAL po osiągnięciu końca zarchiwizowanego WAL.
standby_mode = 'on'Określ ciąg połączenia, który ma być używany do połączenia serwera rezerwowego z węzłem podstawowym.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Określ odzyskiwanie na określonej osi czasu. Domyślnie odzyskiwanie odbywa się na tej samej osi czasu, która była aktualna podczas wykonywania podstawowej kopii zapasowej. Ustawienie tej opcji na „najnowsze” przywraca ostatnią oś czasu znalezioną w archiwum.
recovery_target_timeline = 'latest'Określ plik wyzwalacza, którego obecność kończy odzyskiwanie w trybie gotowości.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Zmień lub dodaj następujące parametry w pliku konfiguracyjnym postgresql.conf.
Określ ilość informacji zapisanych na listach WAL. Możliwe wartości to minimalna, replika lub logiczna. Wartość hot_standby jest mapowana do repliki i służy do zachowania zgodności z poprzednimi wersjami. Zmiana tej wartości wymaga ponownego uruchomienia usługi.
wal_level = hot_standbyZezwól na zapytania podczas odzyskiwania. Zmiana tej wartości wymaga ponownego uruchomienia usługi.
hot_standby = onUruchamianie węzła gotowości
Teraz masz już całą wymaganą konfigurację, wystarczy uruchomić usługę bazy danych w węźle gotowości.
$ systemctl start postgresql-11I sprawdź logi bazy danych w /var/lib/pgsql/11/data/log/. Powinieneś mieć coś takiego:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Możesz również sprawdzić stan replikacji w węźle podstawowym, uruchamiając następujące zapytanie:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Jak widać, używamy replikacji asynchronicznej.
Konwertowanie asynchronicznej replikacji PostgreSQL na replikację synchroniczną
Teraz nadszedł czas, aby przekonwertować tę replikację asynchroniczną na synchronizowaną, a do tego trzeba będzie skonfigurować zarówno węzeł podstawowy, jak i zapasowy.
Węzeł główny
W głównym węźle PostgreSQL musisz użyć tej podstawowej konfiguracji oprócz poprzedniej konfiguracji asynchronicznej.
Postgresql.conf
Określ listę serwerów rezerwowych, które mogą obsługiwać replikację synchroniczną. Ta nazwa serwera w trybie gotowości jest ustawieniem nazwa_aplikacji w pliku recovery.conf w trybie gotowości.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Określa, czy zatwierdzanie transakcji będzie czekać na zapisanie rekordów WAL na dysku, zanim polecenie zwróci klientowi wskazanie „sukcesu”. Prawidłowe wartości to on, remote_apply, remote_write, local i off. Domyślna wartość jest włączona.
synchronous_commit = onKonfiguracja węzła gotowości
W węźle gotowości PostgreSQL musisz zmienić plik recovery.conf, dodając wartość 'application_name w parametrze primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Uruchom ponownie usługę bazy danych zarówno w węźle podstawowym, jak i węzłowym:
$ service postgresql-11 restartTeraz powinieneś mieć uruchomioną i uruchomioną replikację strumieniową synchronizacji:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Cofnięcie z synchronicznej do asynchronicznej replikacji PostgreSQL
Jeśli chcesz wrócić do asynchronicznej replikacji PostgreSQL, wystarczy cofnąć zmiany wprowadzone w pliku postgresql.conf na węźle podstawowym:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onI ponownie uruchom usługę bazy danych.
$ service postgresql-11 restartWięc teraz powinieneś mieć ponownie asynchroniczną replikację.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Jak wdrożyć synchroniczną replikację PostgreSQL za pomocą ClusterControl
Dzięki ClusterControl możesz wykonywać zadania wdrażania, konfiguracji i monitorowania wszystko w jednym z tego samego zadania i będziesz mógł nimi zarządzać z tego samego interfejsu użytkownika.
Zakładamy, że masz zainstalowany ClusterControl i może on uzyskać dostęp do węzłów bazy danych przez SSH. Aby uzyskać więcej informacji na temat konfigurowania dostępu do ClusterControl, zapoznaj się z naszą oficjalną dokumentacją.
Przejdź do ClusterControl i użyj opcji „Wdróż”, aby utworzyć nowy klaster PostgreSQL.
Wybierając PostgreSQL, musisz określić użytkownika, klucz lub hasło oraz port do połączenia przez SSH z naszymi serwerami. Potrzebujesz również nazwy dla nowego klastra i jeśli chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
Po skonfigurowaniu informacji dostępu SSH należy wprowadzić dane, aby uzyskać dostęp Twoja baza danych. Możesz także określić, którego repozytorium chcesz użyć.
W następnym kroku musisz dodać serwery do klastra, który zamierzasz stworzyć. Podczas dodawania serwerów możesz podać adres IP lub nazwę hosta.
I na koniec, w ostatnim kroku, możesz wybrać metodę replikacji, który może być replikacją asynchroniczną lub synchroniczną.
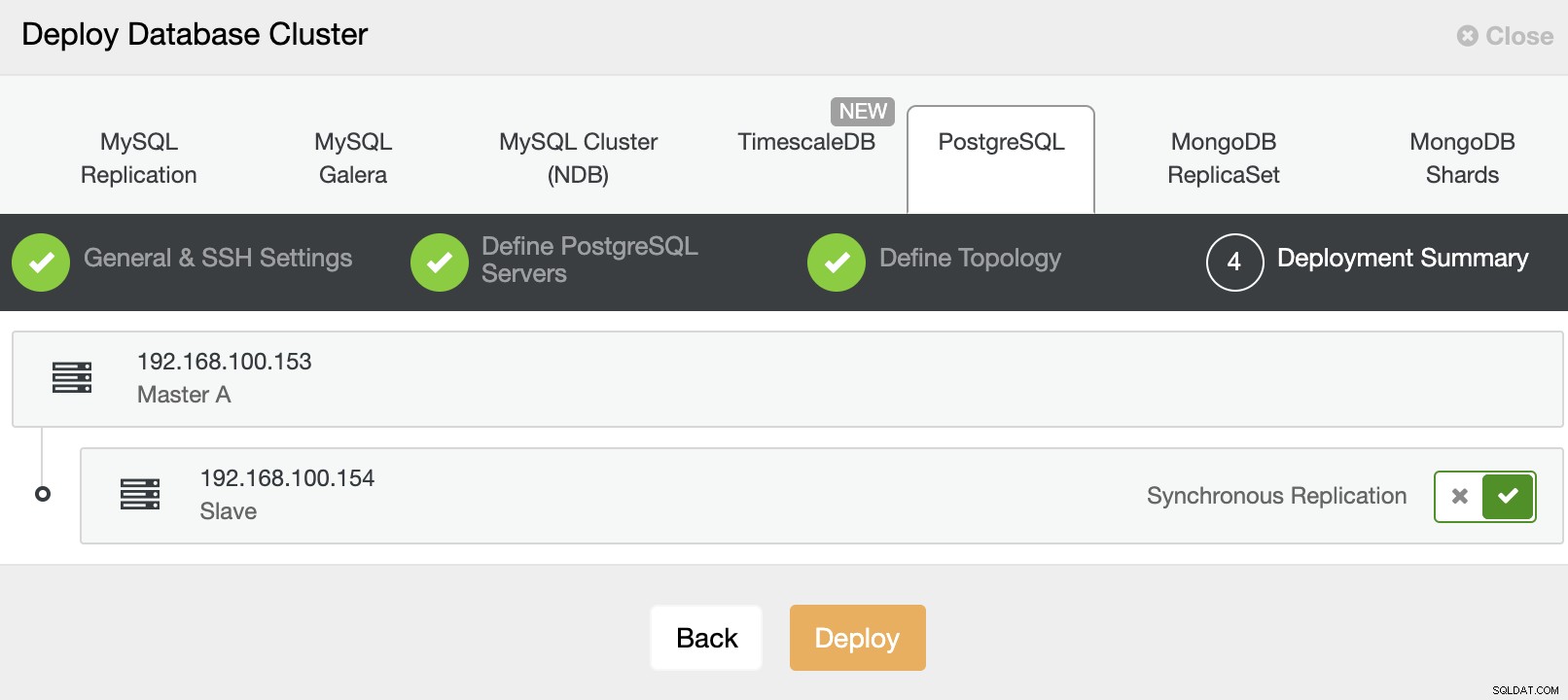
To wszystko. Możesz monitorować status zadania w sekcji aktywności ClusterControl.
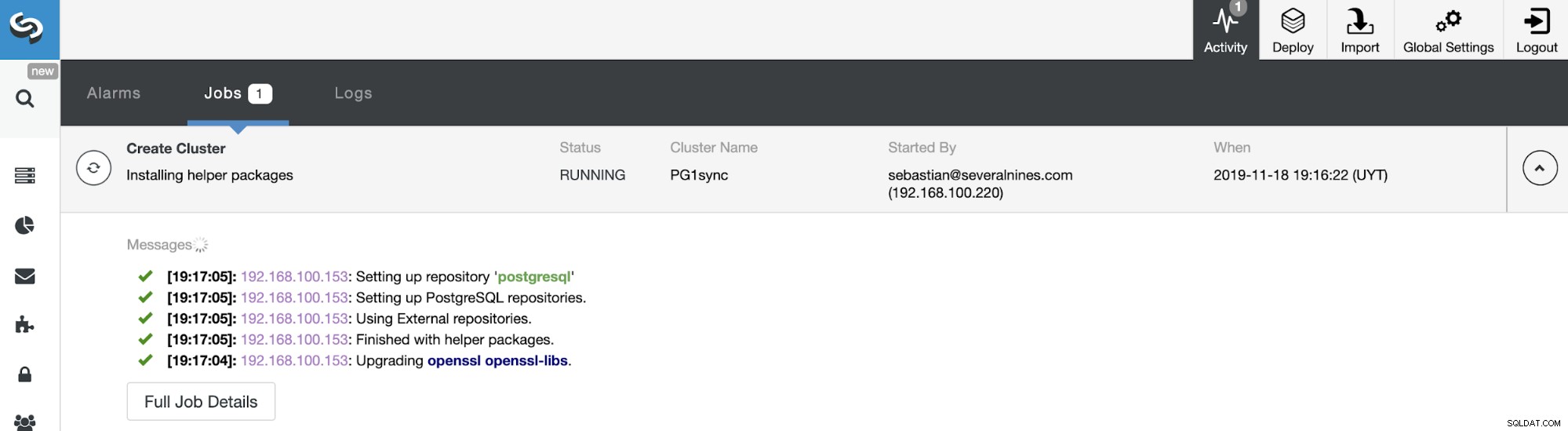
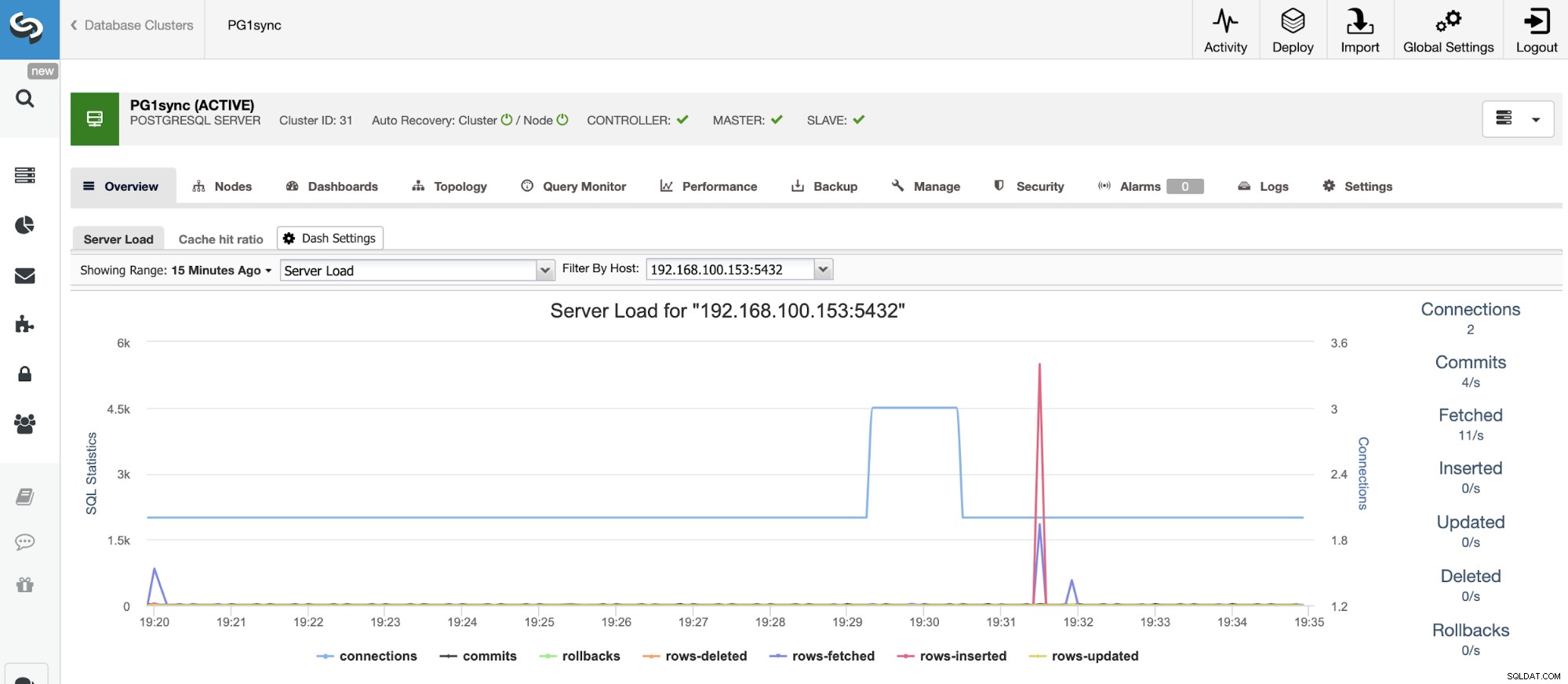
A kiedy to zadanie się zakończy, będziesz miał zainstalowany klaster synchroniczny PostgreSQL, skonfigurowane i monitorowane przez ClusterControl.
Wnioski
Jak wspomnieliśmy na początku tego bloga, wysoka dostępność jest wymogiem dla wszystkich firm, więc powinieneś znać dostępne opcje, aby to osiągnąć dla każdej używanej technologii. W przypadku PostgreSQL możesz użyć synchronicznej replikacji strumieniowej jako najbezpieczniejszego sposobu jej implementacji, ale ta metoda nie działa we wszystkich środowiskach i obciążeniach.
Uważaj na opóźnienia generowane przez oczekiwanie na potwierdzenie każdej transakcji, które może stanowić problem zamiast rozwiązania wysokiej dostępności.



