Wszystkie nowoczesne systemy baz danych obsługują moduł Query Optimizer, który automatycznie identyfikuje najbardziej wydajną strategię wykonywania zapytań SQL. Skuteczna strategia nosi nazwę „Plan” i jest mierzona kosztem, który jest wprost proporcjonalny do „Czasu wykonania/odpowiedzi zapytania”. Plan jest reprezentowany w postaci drzewa danych wyjściowych Optymalizatora zapytań. Węzły drzewa planu można zasadniczo podzielić na następujące 3 kategorie:
- Skanuj węzły :Jak wyjaśniono w moim poprzednim blogu „Przegląd różnych metod skanowania w PostgreSQL”, wskazuje on sposób, w jaki należy pobrać dane z tabeli bazowej.
- Dołącz do węzłów :Jak wyjaśniono w moim poprzednim blogu „Przegląd metod JOIN w PostgreSQL”, wskazuje on, w jaki sposób należy połączyć dwie tabele, aby uzyskać wynik z dwóch tabel.
- Węzły Materializacji :Nazywane również węzłami pomocniczymi. Poprzednie dwa rodzaje węzłów dotyczyły sposobu pobierania danych z tabeli podstawowej i łączenia danych pobranych z dwóch tabel. Węzły w tej kategorii są nakładane na dane pobierane w celu dalszej analizy lub przygotowania raportu itp. Sortowanie danych, agregacja danych itp.
Rozważ prosty przykład zapytania, taki jak...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Załóżmy wygenerowany plan odpowiadający zapytaniu, jak poniżej:
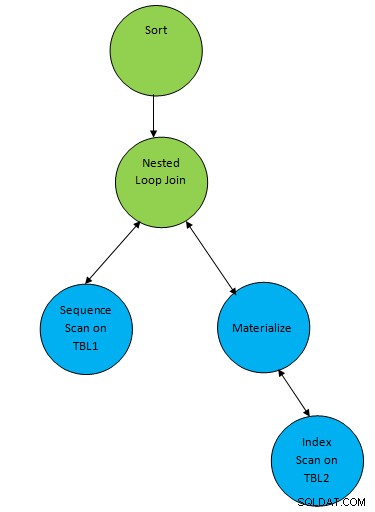
Więc tutaj jeden węzeł pomocniczy „Sortuj” jest dodawany na górze wyniku join, aby posortować dane w wymaganej kolejności.
Niektóre z węzłów pomocniczych generowanych przez optymalizator zapytań PostgreSQL są następujące:
- Sortuj
- Agregacja
- Grupuj według agregatu
- Limit
- Unikalny
- Zablokuj wiersze
- SetOp
Zrozummy każdy z tych węzłów.
Sortuj
Jak sama nazwa wskazuje, ten węzeł jest dodawany jako część drzewa planu, gdy zachodzi potrzeba sortowania danych. Posortowane dane mogą być wymagane w sposób jawny lub niejawny, jak poniżej w dwóch przypadkach:
Scenariusz użytkownika wymaga posortowanych danych jako danych wyjściowych. W takim przypadku węzeł sortowania może znajdować się na szczycie pobierania całych danych, w tym wszystkich innych procesów przetwarzania.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Uwaga: Mimo że użytkownik wymagał końcowego wyniku w kolejności posortowanej, węzeł sortowania nie może zostać dodany do ostatecznego planu, jeśli w odpowiedniej tabeli i kolumnie sortowania znajduje się indeks. W takim przypadku może wybrać skanowanie indeksu, co spowoduje niejawnie posortowaną kolejność danych. Na przykład utwórzmy indeks w powyższym przykładzie i zobaczmy wynik:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Jak wyjaśniono w moim poprzednim blogu Przegląd metod JOIN w PostgreSQL, łączenie przez scalanie wymaga posortowania danych obu tabel przed dołączeniem. Może się więc zdarzyć, że Merge Join okaże się tańszy niż jakakolwiek inna metoda łączenia, nawet z dodatkowym kosztem sortowania. Tak więc w tym przypadku węzeł Sort zostanie dodany pomiędzy metodą join i scan tabeli, aby posortowane rekordy mogły zostać przekazane do metody join.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Agregacja
Węzeł agregujący jest dodawany jako część drzewa planu, jeśli istnieje funkcja agregująca używana do obliczania pojedynczych wyników z wielu wierszy wejściowych. Niektóre z używanych funkcji agregujących to LICZBA, SUMA, ŚREDNIA (ŚREDNIA), MAX (MAKSIMUM) i MIN (MINIMUM).
Węzeł zagregowany może znaleźć się na szczycie podstawowego skanowania relacji lub (i) na połączeniu relacji. Przykład:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Tego rodzaju węzły są rozszerzeniami węzła „Agregacja”. Jeśli funkcje agregujące są używane do łączenia wielu wierszy wejściowych zgodnie z ich grupą, to tego rodzaju węzły są dodawane do drzewa planu. Jeśli więc zapytanie zawiera jakąkolwiek używaną funkcję agregującą, a wraz z nią znajduje się klauzula GROUP BY w zapytaniu, do drzewa planu zostanie dodany węzeł HashAggregate lub GroupAggregate.
Ponieważ PostgreSQL używa Cost Based Optimizer do wygenerowania optymalnego drzewa planów, prawie niemożliwe jest odgadnięcie, który z tych węzłów zostanie użyty. Ale zrozummy, kiedy i jak jest używany.
HashAggregate
HashAggregate działa poprzez budowanie tablicy skrótów danych w celu ich pogrupowania. Tak więc HashAggregate może być używany przez agregat na poziomie grupy, jeśli agregat ma miejsce na nieposortowanym zestawie danych.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Tutaj dane schematu tabeli demo1 są takie, jak w przykładzie pokazanym w poprzedniej sekcji. Ponieważ do zgrupowania jest tylko 1000 wierszy, zasób wymagany do zbudowania tablicy mieszającej jest mniejszy niż koszt sortowania. Planer zapytań decyduje się wybrać HashAggregate.
Grupa Agregatu
GroupAggregate działa na posortowanych danych, więc nie wymaga żadnej dodatkowej struktury danych. GroupAggregate może być używany przez agregację na poziomie grupy, jeśli agregacja dotyczy posortowanego zestawu danych. W celu pogrupowania posortowanych danych może albo jawnie sortować (poprzez dodanie węzła sortowania) albo może działać na danych pobranych przez indeks, w którym to przypadku są sortowane niejawnie.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Tutaj dane schematu tabeli demo2 są takie, jak w przykładzie pokazanym w poprzedniej sekcji. Ponieważ tutaj jest 100000 wierszy do zgrupowania, więc zasób wymagany do zbudowania tablicy mieszającej może być droższy niż koszt sortowania. Dlatego planista zapytań decyduje się wybrać GroupAggregate. Zwróć uwagę, że rekordy wybrane z tabeli „demo2” są wyraźnie posortowane i dla których dodano węzeł w drzewie planu.
Zobacz poniżej inny przykład, w którym dane są już pobierane posortowane z powodu skanowania indeksu:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Zobacz poniżej jeszcze jeden przykład, który mimo że ma funkcję skanowania indeksu, nadal musi jawnie posortować, ponieważ kolumna, w której znajduje się indeks i kolumna grupująca, nie są takie same. Więc nadal musi posortować zgodnie z kolumną grupowania.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Uwaga: GroupAggregate/HashAggregate może być używany dla wielu innych zapytań pośrednich, nawet jeśli agregacja z grupą nie występuje w zapytaniu. To zależy od tego, jak planista zinterpretuje zapytanie. Np. Załóżmy, że musimy uzyskać odrębną wartość z tabeli, a następnie można ją zobaczyć jako grupę w odpowiedniej kolumnie, a następnie pobrać jedną wartość z każdej grupy.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Więc tutaj HashAggregate jest używany, nawet jeśli nie ma agregacji i grupowania według zaangażowanych.
Limit
Węzły limitu są dodawane do drzewa planu, jeśli w zapytaniu SELECT zostanie użyta klauzula „limit/offset”. Ta klauzula służy do ograniczania liczby wierszy i opcjonalnie zapewnia przesunięcie, aby rozpocząć odczytywanie danych. Przykład poniżej:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Wyjątkowy
Ten węzeł jest wybierany w celu uzyskania odrębnej wartości z podstawowego wyniku. Zauważ, że w zależności od zapytania, selektywności i innych informacji o zasobach, odrębną wartość można pobrać za pomocą HashAggregate/GroupAggregate również bez użycia węzła Unique. Przykład:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)Zablokuj wiersze
PostgreSQL zapewnia funkcjonalność blokowania wszystkich wybranych wierszy. Wiersze można wybrać w trybie „Współdzielone” lub „Ekskluzywne” w zależności od klauzuli „DO UDOSTĘPNIANIA” i „DO AKTUALIZACJI”. Nowy węzeł „LockRows” zostaje dodany do drzewa planów w celu wykonania tej operacji.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL zapewnia funkcjonalność łączenia wyników dwóch lub więcej zapytań. Tak więc, gdy typ węzła Join zostanie wybrany do połączenia dwóch tabel, podobnie typ węzła SetOp zostanie wybrany do połączenia wyników dwóch lub więcej zapytań. Rozważmy na przykład tabelę z pracownikami z ich imieniem, nazwiskiem, wiekiem i pensją, jak poniżej:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Teraz poprośmy pracowników w wieku powyżej 25 lat:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Teraz zdobądźmy pracowników z pensją powyżej 95 mln:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Teraz, aby pozyskać pracowników w wieku powyżej 25 lat i zarobkach powyżej 95 mln, możemy napisać poniżej zapytanie przecinające:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Więc tutaj dodano nowy rodzaj węzła HashSetOp, aby ocenić przecięcie tych dwóch indywidualnych zapytań.
Zauważ, że dodano tutaj dwa inne rodzaje nowego węzła:
Dołącz
Ten węzeł jest dodawany w celu połączenia wielu zestawów wyników w jeden.
Skanowanie podzapytań
Ten węzeł jest dodawany w celu oceny dowolnego podzapytania. W powyższym planie podzapytanie jest dodawane w celu oceny jednej dodatkowej stałej wartości kolumny, która wskazuje, który zestaw wejściowy wniósł określony wiersz.
HashedSetop działa przy użyciu skrótu bazowego wyniku, ale możliwe jest wygenerowanie operacji SetOp opartej na sortowaniu przez optymalizator zapytań. Węzeł Setop oparty na sortowaniu jest oznaczony jako „Setop”.
Uwaga:możliwe jest osiągnięcie tego samego wyniku, co w powyższym wyniku za pomocą jednego zapytania, ale tutaj pokazano go za pomocą przecięcia tylko dla łatwej demonstracji.
Wnioski
Wszystkie węzły PostgreSQL są przydatne i są wybierane na podstawie charakteru zapytania, danych itp. Wiele klauzul jest mapowanych jeden do jednego z węzłami. W przypadku niektórych klauzul istnieje wiele opcji dla węzłów, które są ustalane na podstawie podstawowych obliczeń kosztów danych.