Z lotu ptaka wydaje się, że jeśli chodzi o migrację obciążeń PostgreSQL do chmury, wybór dostawcy chmury nie powinien mieć znaczenia. Po wyjęciu z pudełka PostgreSQL ułatwia replikację danych, bez przestojów, za pośrednictwem replikacji logicznej, choć z pewnymi ograniczeniami. Aby uatrakcyjnić oferowanie swoich usług dostawcy chmury mogą wypracować niektóre z tych ograniczeń. Kiedy zaczynamy myśleć o różnicach w dostępnych wersjach PostgreSQL, kompatybilności, limitach, ograniczeniach i wydajności, staje się jasne, że usługi migracji są kluczowymi czynnikami w całej ofercie usług. To już nie jest kwestia „oferujemy to, migrujemy to”. To bardziej przypomina „oferujemy to, migrujemy, z najmniejszymi ograniczeniami”.
Migracja jest ważna zarówno dla małych, jak i dużych organizacji. Nie chodzi tu tak bardzo o rozmiar klastra PostgreSQL, jak o akceptowalny czas przestoju i wysiłek po migracji.
Wybór strategii
Strategia migracji powinna uwzględniać rozmiar bazy danych, połączenie sieciowe między źródłem a celem, a także narzędzia migracji oferowane przez dostawcę chmury.
Sprzęt czy oprogramowanie?
Podobnie jak wysyłanie kluczy USB i dysków DVD w początkach Internetu, w przypadkach, gdy przepustowość sieci nie wystarcza do przesyłania danych z pożądaną szybkością, dostawcy chmury oferują rozwiązania sprzętowe, zdolne do przenoszenia do setek petabajtów danych. Poniżej znajdują się aktualne rozwiązania każdej z wielkiej trójki:
Podręczna tabela udostępniona przez Google przedstawiająca dostępne opcje:

Urządzenie GCP to urządzenie transferowe
Podobne zalecenie z platformy Azure na podstawie rozmiaru danych w porównaniu z przepustowością sieci:
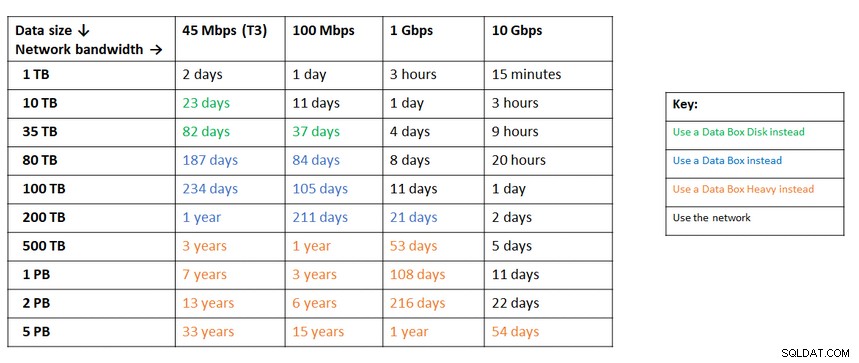
Urządzenie Azure to Data Box
Pod koniec swojej strony migracji danych, AWS daje wgląd w to, czego możemy się spodziewać, wraz z rekomendacją rozwiązania:

W przypadkach, gdy rozmiary bazy danych przekraczają 100 GB i ograniczona przepustowość sieci, AWS sugeruje rozwiązanie sprzętowe.
Urządzenie AWS to Snowball Edge
Eksport/Import danych
Organizacje, które tolerują przestoje, mogą korzystać z prostoty typowych narzędzi dostarczanych przez PostgreSQL zaraz po zainstalowaniu. Jednak podczas migracji danych od jednego dostawcy chmury (lub hostingu) do innego dostawcy chmury, uważaj na koszty wyjścia.
AWS
Do testowania migracji użyłem lokalnej instalacji mojej bazy danych Nextcloud działającej na jednym z serwerów mojej sieci domowej:
postgres=# select pg_size_pretty(pg_database_size('nextcloud_prod'));
pg_size_pretty
----------------
58 MB
(1 row)
nextcloud_prod=# \dt
List of relations
Schema | Name | Type | Owner
--------+-------------------------------+-------+-----------
public | awsdms_ddl_audit | table | s9sdemo
public | oc_accounts | table | nextcloud
public | oc_activity | table | nextcloud
public | oc_activity_mq | table | nextcloud
public | oc_addressbookchanges | table | nextcloud
public | oc_addressbooks | table | nextcloud
public | oc_appconfig | table | nextcloud
public | oc_authtoken | table | nextcloud
public | oc_bruteforce_attempts | table | nextcloud
public | oc_calendar_invitations | table | nextcloud
public | oc_calendar_reminders | table | nextcloud
public | oc_calendar_resources | table | nextcloud
public | oc_calendar_resources_md | table | nextcloud
public | oc_calendar_rooms | table | nextcloud
public | oc_calendar_rooms_md | table | nextcloud
...
public | oc_termsofservice_terms | table | nextcloud
public | oc_text_documents | table | nextcloud
public | oc_text_sessions | table | nextcloud
public | oc_text_steps | table | nextcloud
public | oc_trusted_servers | table | nextcloud
public | oc_twofactor_backupcodes | table | nextcloud
public | oc_twofactor_providers | table | nextcloud
public | oc_users | table | nextcloud
public | oc_vcategory | table | nextcloud
public | oc_vcategory_to_object | table | nextcloud
public | oc_whats_new | table | nextcloud
(84 rows)
The database is running PostgreSQL version 11.5:
postgres=# select version();
version
------------------------------------------------------------------------------------------------------------
PostgreSQL 11.5 on x86_64-redhat-linux-gnu, compiled by gcc (GCC) 9.1.1 20190503 (Red Hat 9.1.1-1), 64-bit
(1 row)Stworzyłem również użytkownika PostgreSQL do użycia przez AWS DMS, który jest usługą Amazona do importowania PostgreSQL do Amazon RDS:
postgres=# \du s9sdemo
List of roles
Role name | Attributes | Member of
-----------+------------+-------------
s9sdemo | | {nextcloud}AWS DMS zapewnia wiele korzyści, jakich można oczekiwać od rozwiązania zarządzanego w chmurze:
- automatyczne skalowanie (tylko do przechowywania, ponieważ instancja obliczeniowa musi mieć odpowiedni rozmiar)
- automatyczne udostępnianie
- model płatności zgodnie z rzeczywistym użyciem
- automatyczne przełączanie awaryjne
Jednak zachowanie spójności danych dla działającej bazy danych to najlepszy wysiłek. Spójność 100% jest osiągana tylko wtedy, gdy baza danych jest w trybie tylko do odczytu — jest to konsekwencja sposobu przechwytywania zmian w tabeli.
Innymi słowy, tabele mają różne przecięcia w określonym momencie:

Podobnie jak w przypadku wszystkiego w chmurze, istnieje koszt związany z usługa migracji.
Aby utworzyć środowisko migracji, postępuj zgodnie z przewodnikiem Pierwsze kroki, aby skonfigurować instancję replikacji, źródło, docelowy punkt końcowy oraz jedno lub więcej zadań.
Instancja replikacji
Tworzenie instancji replikacji jest proste dla każdego, kto zna instancje EC2 w AWS:
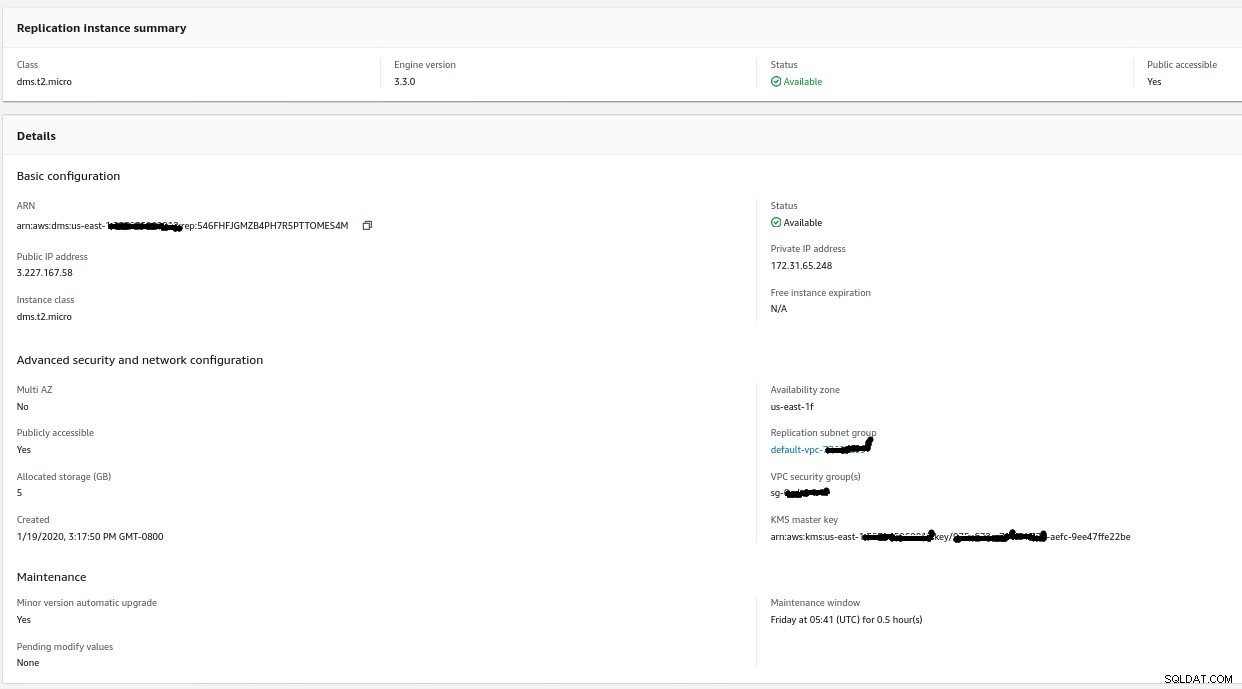
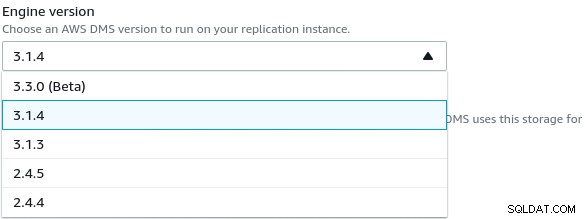
Jedyną zmianą w stosunku do wartości domyślnych było wybranie AWS DMS 3.3.0 lub później z powodu mojego lokalnego silnika PostgreSQL w wersji 11.5:

A oto lista aktualnie dostępnych wersji AWS DMS:
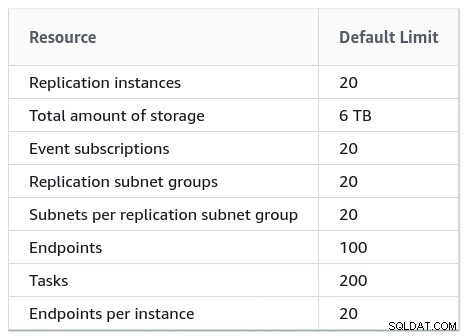
W przypadku dużych instalacji należy również uwzględnić limity AWS DMS:
Istnieje również zestaw ograniczeń, które są konsekwencją logicznej replikacji PostgreSQL ograniczenia. Na przykład AWS DMS nie będzie migrować obiektów drugorzędnych:

Warto wspomnieć, że w PostgreSQL wszystkie indeksy są indeksami drugorzędnymi i że nie jest złą rzeczą, jak zauważono w tej bardziej szczegółowej dyskusji.
Źródłowy punkt końcowy
Postępuj zgodnie z instrukcjami kreatora, aby utworzyć źródłowy punkt końcowy:
W scenariuszu konfiguracji Konfiguracja sieci do VPC Korzystanie z Internetu my sieć domowa wymagała kilku poprawek, aby umożliwić adresowi IP źródłowego punktu końcowego dostęp do mojego wewnętrznego serwera. Najpierw utworzyłem przekierowanie portów na routerze brzegowym (173.180.222.170), aby wysyłać ruch na porcie 30485 do mojej wewnętrznej bramy (10.11.11.241) na porcie 5432, gdzie mogę dostroić dostęp w oparciu o źródłowy adres IP za pomocą reguł iptables. Stamtąd ruch sieciowy przepływa przez tunel SSH do serwera WWW, na którym działa baza danych PostgreSQL. Przy opisanej konfiguracji client_addr w danych wyjściowych pg_stat_activity pojawi się jako 127.0.0.1.
Przed zezwoleniem na ruch przychodzący dzienniki iptables pokazują 12 prób z wystąpienia replikacji pod adresem ip=3.227.167.58):
Jan 19 17:35:28 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=23973 DF PROTO=TCP SPT=54662 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:35:29 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=23974 DF PROTO=TCP SPT=54662 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:35:31 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=23975 DF PROTO=TCP SPT=54662 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:35:35 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=23976 DF PROTO=TCP SPT=54662 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:35:48 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=4328 DF PROTO=TCP SPT=54667 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:35:49 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=4329 DF PROTO=TCP SPT=54667 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:35:51 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=4330 DF PROTO=TCP SPT=54667 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:35:55 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=4331 DF PROTO=TCP SPT=54667 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:36:08 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=8298 DF PROTO=TCP SPT=54670 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:36:09 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=8299 DF PROTO=TCP SPT=54670 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:36:11 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=8300 DF PROTO=TCP SPT=54670 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0
Jan 19 17:36:16 mha.can.local kernel: filter/INPUT: IN=enp0s29f7u2 OUT= MAC=00:24:9b:17:3a:fa:9c:1e:95:e5:ad:b0:08:00 SRC=3.227.167.58 DST=10.11.11.241 LEN=60 TOS=0x00 PREC=0x00 TTL=39 ID=8301 DF PROTO=TCP SPT=54670 DPT=5432 WINDOW=26880 RES=0x00 SYN URGP=0Po zezwoleniu na adres IP źródłowego punktu końcowego (3.227.167.58) test połączenia powiódł się i konfiguracja źródłowego punktu końcowego jest zakończona. Posiadamy również połączenie SSL w celu szyfrowania ruchu w sieciach publicznych. Można to potwierdzić na serwerze PostgreSQL za pomocą poniższego zapytania oraz w konsoli AWS:
postgres=# SELECT datname, usename, client_addr, ssl, cipher, query, query_start FROM pg_stat_activity a, pg_stat_ssl s where a.pid=s.pid and usename = 's9sdemo';
datname | usename | client_addr | ssl | cipher | query | query_start
---------+---------+-------------+-----+--------+-------+-------------
(0 rows)… a następnie obserwuj podczas uruchamiania połączenia z konsoli AWS. Wyniki powinny wyglądać podobnie do następujących:
postgres=# \watch
Sun 19 Jan 2020 06:50:51 PM PST (every 2s)
datname | usename | client_addr | ssl | cipher | query | query_start
----------------+---------+-------------+-----+-----------------------------+------------------------------------------------------------------------------------+-------------------------------
nextcloud_prod | s9sdemo | 127.0.0.1 | t | ECDHE-RSA-AES256-GCM-SHA384 | select cast(setting as integer) from pg_settings where name = 'server_version_num' | 2020-01-19 18:50:51.463496-08
(1 row)…podczas gdy konsola AWS powinna zgłosić sukces:
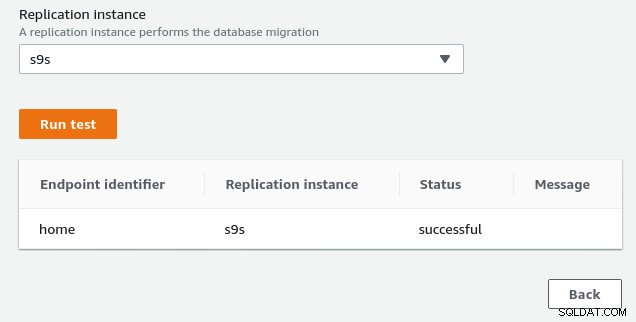
Jak wskazano w sekcji wymagań wstępnych, jeśli wybierzemy opcję migracji Pełne obciążenie , trwająca replikacja, będziemy musieli zmienić uprawnienia dla użytkownika PostgreSQL. Ta opcja migracji wymaga uprawnień superużytkownika, dlatego dostosowałem ustawienia dla utworzonego wcześniej użytkownika PostgreSQL:
nextcloud_prod=# \du s9sdemo
List of roles
Role name | Attributes | Member of
-----------+------------+-----------
s9sdemo | Superuser | {}Ten sam dokument zawiera instrukcje dotyczące modyfikacji postgresql.conf. Oto różnica w stosunku do oryginału:
--- a/var/lib/pgsql/data/postgresql.conf
+++ b/var/lib/pgsql/data/postgresql.conf
@@ -95,7 +95,7 @@ max_connections = 100 # (change requires restart)
# - SSL -
-#ssl = off
+ssl = on
#ssl_ca_file = ''
#ssl_cert_file = 'server.crt'
#ssl_crl_file = ''
@@ -181,6 +181,7 @@ dynamic_shared_memory_type = posix # the default is the first option
# - Settings -
+wal_level = logical
#wal_level = replica # minimal, replica, or logical
# (change requires restart)
#fsync = on # flush data to disk for crash safety
@@ -239,6 +240,7 @@ min_wal_size = 80MB
#max_wal_senders = 10 # max number of walsender processes
# (change requires restart)
#wal_keep_segments = 0 # in logfile segments; 0 disables
+wal_sender_timeout = 0
#wal_sender_timeout = 60s # in milliseconds; 0 disables
#max_replication_slots = 10 # max number of replication slots
@@ -451,6 +453,7 @@ log_rotation_size = 0 # Automatic rotation of logfiles will
#log_duration = off
#log_error_verbosity = default # terse, default, or verbose messagesNa koniec nie zapomnij dostosować ustawień pg_hba.conf, aby zezwolić na połączenie SSL z adresu IP instancji replikacji.
Jesteśmy teraz gotowi do następnego kroku.
Docelowy punkt końcowy
Postępuj zgodnie z instrukcjami kreatora, aby utworzyć docelowy punkt końcowy:
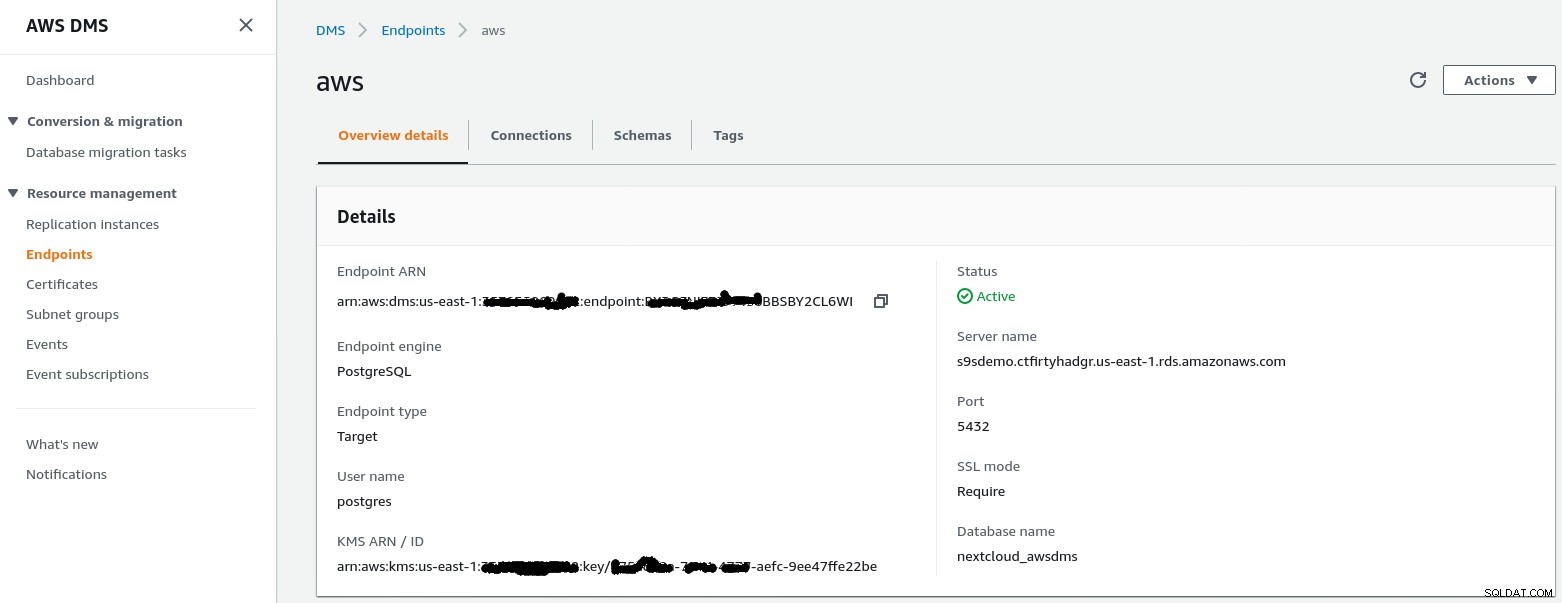
W tym kroku założono, że wystąpienie RDS z określonym punktem końcowym już istnieje wraz z pusta baza danych nextcloud_awsdms. Bazę danych można utworzyć podczas konfiguracji instancji RDS.
W tym momencie, jeśli sieć AWS jest poprawnie skonfigurowana, powinniśmy być gotowi do uruchomienia testu połączenia:
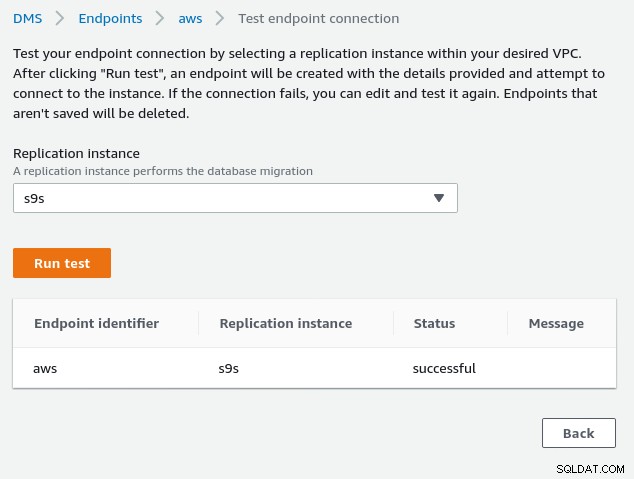
Po wdrożeniu środowiska nadszedł czas na utworzenie zadania migracji :
Zadanie migracji
Gdy kreator zakończy konfigurację, wygląda to tak:
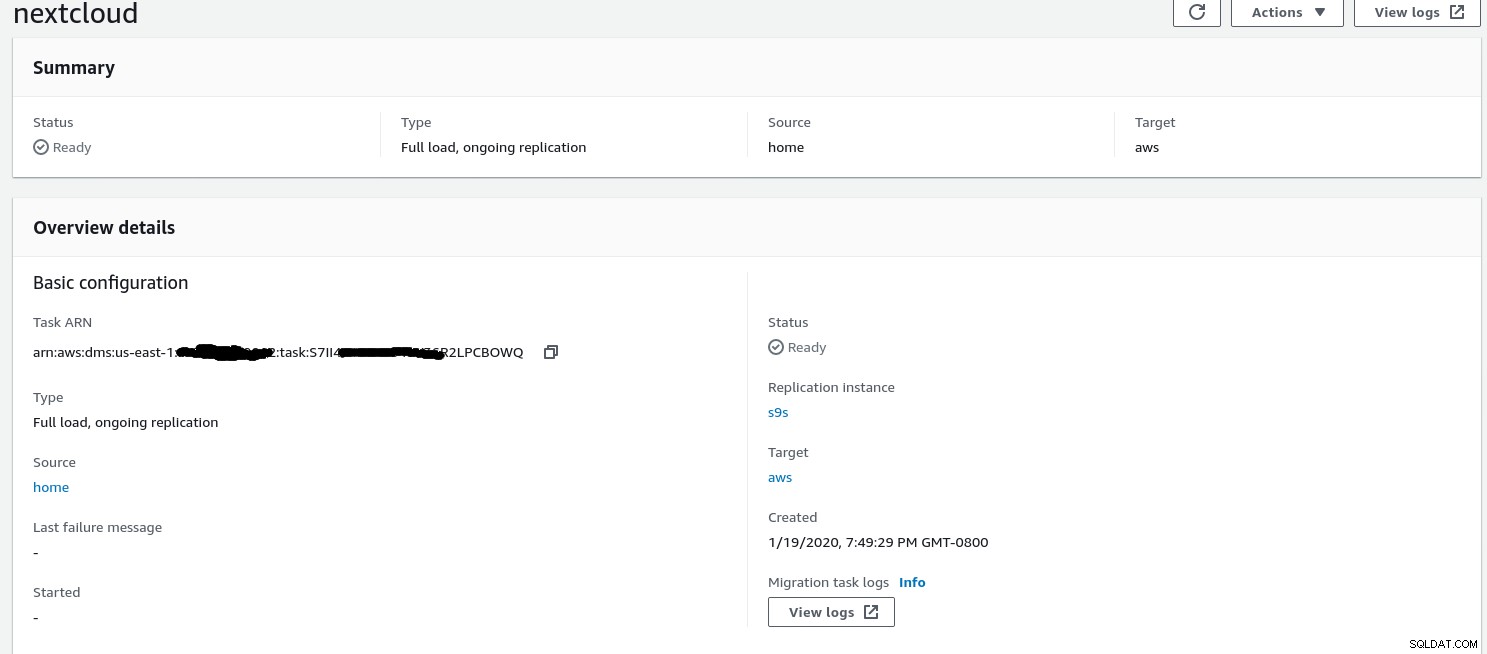
...i druga część tego samego widoku:
Po uruchomieniu zadania możemy monitorować postęp — otwórz zadanie szczegóły i przewiń w dół do statystyk tabeli:
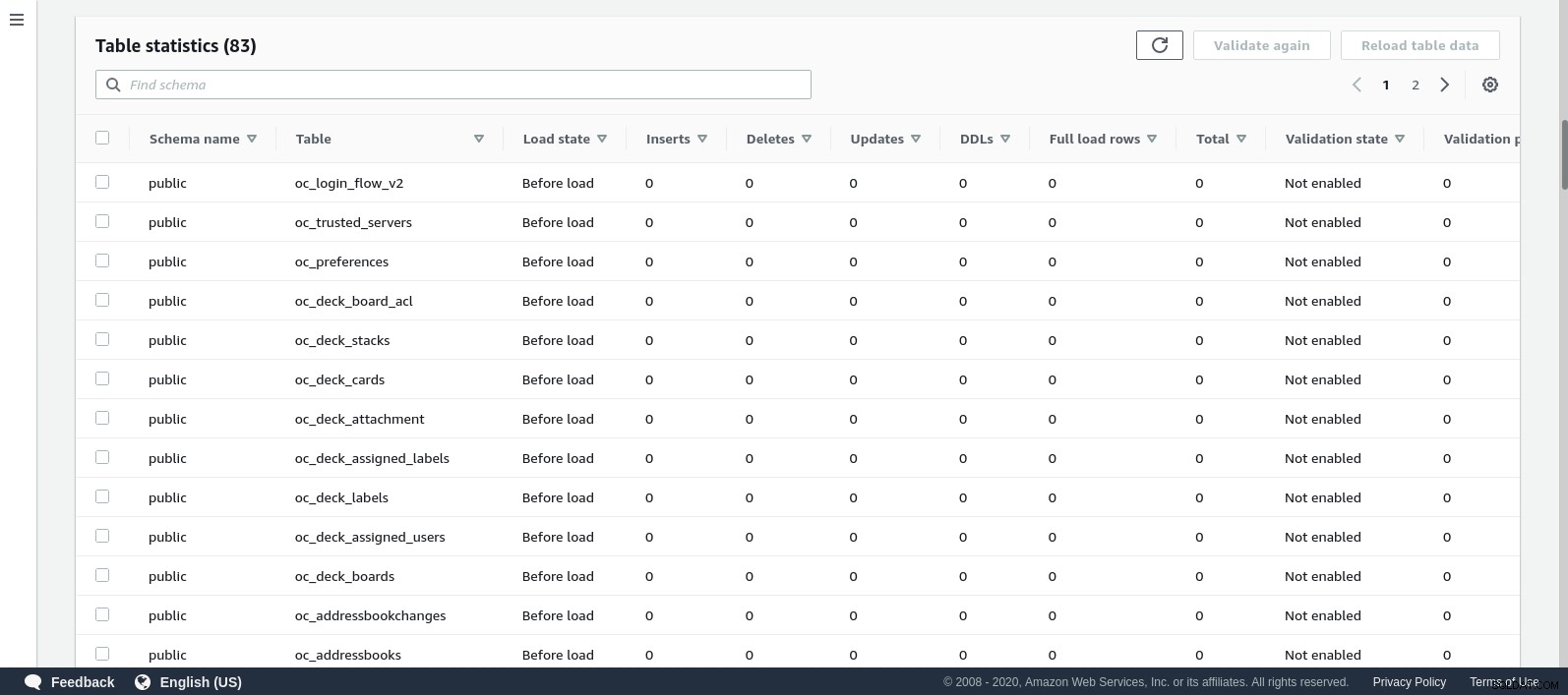
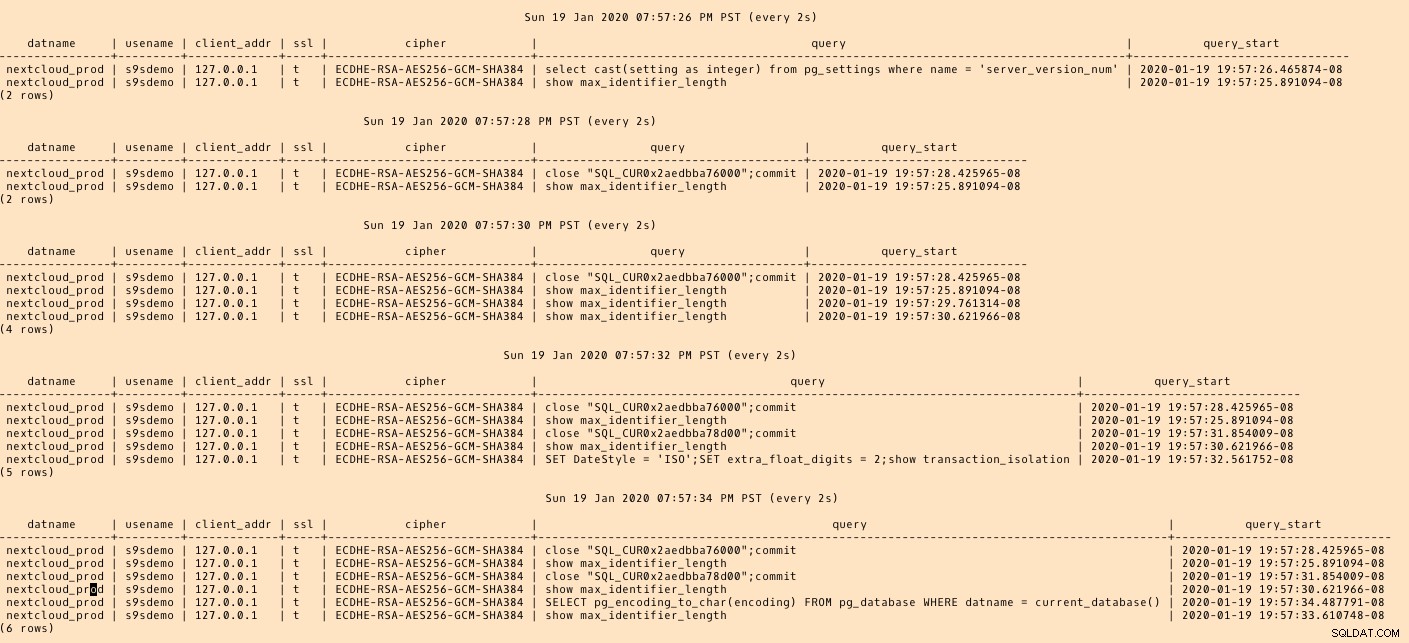
AWS DMS używa buforowanego schematu do migracji tabel bazy danych. W trakcie migracji, oprócz konsoli AWS, możemy nadal „obserwować” zapytania w źródłowej bazie danych i dziennik błędów PostgreSQL:
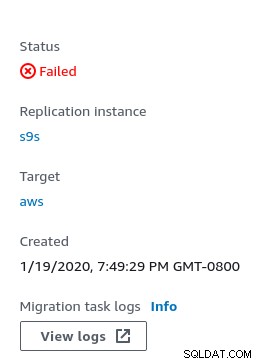
W przypadku błędów w konsoli wyświetlany jest stan awarii:
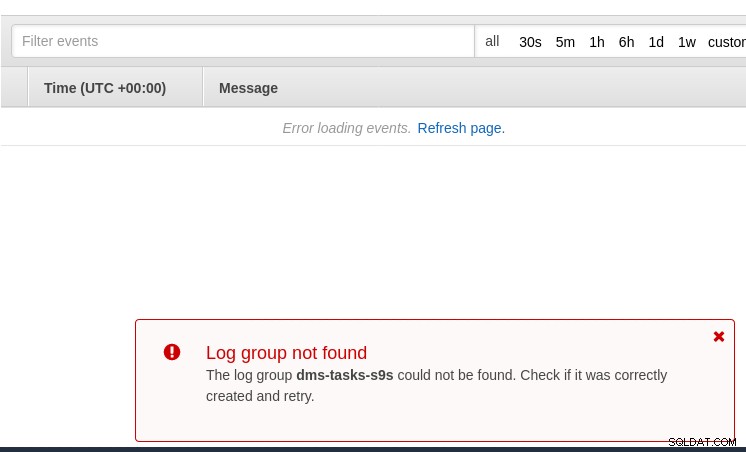
Jednym z miejsc do szukania wskazówek jest CloudWatch, chociaż podczas moich testów logi nie został opublikowany, co prawdopodobnie może być kolejną usterką w wersji beta AWS DMS 3.3.0, jak się okazało pod koniec tego ćwiczenia:
Postęp migracji jest ładnie wyświetlany w konsoli AWS DMS:

Po zakończeniu migracji jeszcze raz przejrzyj dziennik błędów PostgreSQL , ujawnia zaskakującą wiadomość:

Wydaje się, że w PostgreSQL 9.6, 10 tabela pg_class zawiera nazwaną kolumnę relhaspkey, ale tak nie jest w 11. I to jest usterka w wersji beta AWS DMS 3.3.0, o której mówiłem wcześniej.
GCP
Podejście Google opiera się na narzędziu open source PgBouncer. Ekscytacja była krótkotrwała, ponieważ oficjalna dokumentacja mówi o migracji PostgreSQL do środowiska silnika obliczeniowego.
Kolejne próby znalezienia rozwiązania migracji do Cloud SQL, które przypomina AWS DMS, nie powiodły się. Strategie migracji bazy danych nie zawierają odniesienia do PostgreSQL:

Lokalne instalacje PostgreSQL można migrować do Cloud SQL za pomocą usług jednego z partnerów Google Cloud.
Potencjalnym rozwiązaniem może być PgBouncer do Cloud SQL, ale nie jest to objęte zakresem tego bloga.
Microsoft Cloud Services (Azure)
W celu ułatwienia migracji obciążeń PostgreSQL ze środowiska lokalnego do zarządzanej bazy danych Azure dla PostgreSQL firma Microsoft udostępnia Azure DMS, który zgodnie z dokumentacją można wykorzystać do migracji przy minimalnym przestoju. Samouczek Migracja PostgreSQL do Azure Database for PostgreSQL online przy użyciu DMS szczegółowo opisuje te kroki.
Dokumentacja Azure DMS szczegółowo omawia problemy i ograniczenia związane z migracją obciążeń PostgreSQL na platformę Azure.
Jedną zauważalną różnicą w stosunku do AWS DMS jest wymóg ręcznego tworzenia schematu:

Demo tego będzie tematem przyszłego bloga. Bądź na bieżąco.