Moodle to najpopularniejszy system zarządzania nauką (LMS), który umożliwia nauczycielom tworzenie własnej witryny internetowej z kursami lub treściami poszerzającymi wiedzę. Tego rodzaju platformy stają się coraz ważniejsze, aby umożliwić Ci kontynuowanie nauki na odległość, gdy tradycyjny system edukacji nie jest dostępny lub jest tylko jego uzupełnieniem, więc wzrost ruchu lub użytkowników wymaga skalowania środowiska, aby zapewnić niską reakcję czas.
Skalowalność to właściwość systemu/bazy danych umożliwiająca obsługę rosnącej liczby wymagań poprzez dodawanie zasobów. Dostępne są różne podejścia do skalowania bazy danych w zależności od sposobu, w jaki trzeba ją skalować, a w środowisku produkcyjnym najprawdopodobniej długi czas przestoju nie jest pożądany, więc należy to również wziąć pod uwagę.
W tym blogu przyjrzymy się, jakie opcje skalowania są dostępne i jak skalować bazę danych Moodle PostgreSQL w łatwy sposób bez wpływu na działający system.
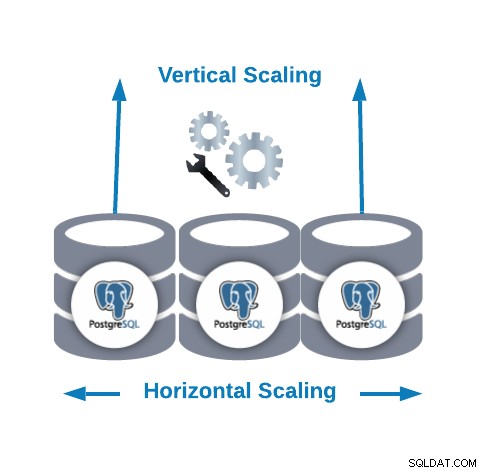
Skalowanie w poziomie i w pionie
Istnieją dwa główne sposoby skalowania bazy danych:
- Skalowanie poziome (skalowanie w poziomie):Jest wykonywane przez dodanie większej liczby węzłów bazy danych, tworząc lub zwiększając klaster bazy danych.
- Skalowanie w pionie (skalowanie w górę):Jest wykonywane przez dodanie większej ilości zasobów sprzętowych (procesor, pamięć, dysk) do istniejącego węzła bazy danych.
Do skalowania w poziomie , można dodać więcej węzłów bazy danych jako węzłów rezerwowych. Może pomóc poprawić wydajność odczytu, równoważąc ruch między węzłami. W takim przypadku konieczne będzie dodanie modułu równoważenia obciążenia, aby dystrybuować ruch do właściwego węzła w zależności od zasad i stanu węzła. Należy również rozważyć dodanie dwóch lub więcej węzłów systemu równoważenia obciążenia, aby uniknąć pojedynczego punktu awarii, i użyć narzędzia takiego jak „Keepalived”, aby zapewnić dostępność. Keepalived to usługa, która umożliwia skonfigurowanie wirtualnego adresu IP w ramach aktywnej/pasywnej grupy serwerów. Ten wirtualny adres IP jest przypisany do aktywnego serwera (aktywny Load Balancer). Jeśli ten serwer ulegnie awarii, adres IP zostanie automatycznie przeniesiony do „dodatkowego” serwera pasywnego, umożliwiając mu dalszą pracę z tym samym adresem IP w sposób przejrzysty dla systemów.
Do skalowania w pionie , może być konieczna zmiana niektórych parametrów konfiguracyjnych, aby umożliwić PostgreSQL korzystanie z nowego lub lepszego zasobu sprzętowego. Zobaczmy niektóre z tych parametrów z dokumentacji PostgreSQL.
- work_mem:Określa ilość pamięci, która ma być używana przez wewnętrzne operacje sortowania i tablice mieszające przed zapisaniem do tymczasowych plików dyskowych. Kilka uruchomionych sesji może wykonywać takie operacje jednocześnie, więc całkowita użyta pamięć może być wielokrotnie większa niż wartość work_mem.
- maintenance_work_mem:Określa maksymalną ilość pamięci, która ma być używana przez operacje konserwacyjne, takie jak VACUUM, CREATE INDEX i ALTER TABLE ADD FOREIGN KEY. Większe ustawienia mogą poprawić wydajność odkurzania i przywracania zrzutów bazy danych.
- autovacuum_work_mem:Określa maksymalną ilość pamięci, która ma być używana przez każdy proces roboczy autovacuum.
- autovacuum_max_workers:Określa maksymalną liczbę procesów autovacuum, które mogą być uruchomione w dowolnym momencie.
- max_worker_processes:Ustawia maksymalną liczbę procesów w tle obsługiwanych przez system. Określ limit procesu, taki jak odkurzanie, punkty kontrolne i więcej prac konserwacyjnych.
- max_parallel_workers:Ustawia maksymalną liczbę pracowników obsługiwanych przez system dla operacji równoległych. Pracownicy równolegli są pobierani z puli procesów roboczych ustanowionych przez poprzedni parametr.
- max_parallel_maintenance_workers:Ustawia maksymalną liczbę równoległych procesów roboczych, które można uruchomić za pomocą pojedynczego polecenia narzędzia. Obecnie jedynym poleceniem narzędzia równoległego, które obsługuje użycie procesów roboczych równoległych, jest CREATE INDEX i to tylko podczas budowania indeksu B-drzewa.
- Effective_cache_size:Ustawia założenie planisty dotyczące efektywnego rozmiaru pamięci podręcznej dysku, która jest dostępna dla pojedynczego zapytania. Jest to uwzględniane w szacunkowych kosztach korzystania z indeksu; wyższa wartość sprawia, że bardziej prawdopodobne jest, że zostaną użyte skany indeksu, niższa wartość sprawia, że będzie bardziej prawdopodobne, że zostaną użyte skany sekwencyjne.
- shared_buffers:Ustawia ilość pamięci używanej przez serwer bazy danych dla buforów pamięci współdzielonej. Aby uzyskać dobrą wydajność, zwykle potrzebne są ustawienia znacznie wyższe niż minimum.
- temp_buffers:Ustawia maksymalną liczbę tymczasowych buforów używanych przez każdą sesję bazy danych. Są to lokalne bufory sesji używane tylko do dostępu do tabel tymczasowych.
- Effective_io_concurrency:Ustawia liczbę jednoczesnych operacji we/wy dysku, które według PostgreSQL mogą być wykonywane jednocześnie. Zwiększenie tej wartości zwiększy liczbę operacji I/O, które każda pojedyncza sesja PostgreSQL próbuje równolegle zainicjować. Obecnie to ustawienie wpływa tylko na skanowanie sterty bitmap.
- max_connections:Określa maksymalną liczbę jednoczesnych połączeń z serwerem bazy danych. Zwiększenie tego parametru pozwala PostgreSQL na jednoczesne uruchamianie większej liczby procesów backendu.
Wyzwaniem może być to, jak dowiedzieć się, czy musisz skalować bazę danych Moodle iw jaki sposób, a odpowiedzią jest monitorowanie.
Monitorowanie PostgreSQL dla Moodle
Skalowanie bazy danych to złożony proces, dlatego powinieneś sprawdzić niektóre metryki, aby móc określić najlepszą strategię jej skalowania.
Możesz monitorować użycie procesora, pamięci i dysku, aby określić, czy występuje jakiś problem z konfiguracją lub czy rzeczywiście potrzebujesz skalować bazę danych. Na przykład, jeśli widzisz duże obciążenie serwera, ale aktywność bazy danych jest niska, prawdopodobnie nie ma potrzeby jej skalowania, wystarczy sprawdzić parametry konfiguracyjne, aby dopasować je do zasobów sprzętowych.
Sprawdzenie miejsca na dysku używanego przez węzeł PostgreSQL na bazę danych może pomóc w ustaleniu, czy potrzebujesz więcej dysku lub nawet partycji tabeli. Aby sprawdzić miejsce na dysku używane przez bazę danych/tabele, możesz użyć funkcji PostgreSQL, takiej jak pg_database_size lub pg_table_size.
Od strony bazy danych należy sprawdzić:
- Ilość połączenia
- Wykonywanie zapytań
- Użycie indeksu
- Wzdęcia
- Opóźnienie replikacji
Mogą to być jasne wskaźniki potwierdzające, czy potrzebne jest skalowanie bazy danych.
ClusterControl jako system skalowania i monitorowania
ClusterControl może pomóc w radzeniu sobie z obydwoma sposobami skalowania, o których wspominaliśmy wcześniej, oraz w monitorowaniu wszystkich niezbędnych metryk w celu potwierdzenia wymagania skalowania.
Jeśli jeszcze nie używasz ClusterControl, możesz go zainstalować i wdrożyć lub zaimportować aktualną bazę danych PostgreSQL, wybierając opcję „Importuj” i postępuj zgodnie z instrukcjami, aby skorzystać ze wszystkich funkcji ClusterControl, takich jak kopie zapasowe, automatyczne przełączanie awaryjne, alerty, monitorowanie i nie tylko.
Skalowanie poziome
W przypadku skalowania poziomego, jeśli przejdziesz do działań klastrowych i wybierzesz „Dodaj podrzędną replikację”, możesz albo utworzyć nową replikę od zera, albo dodać istniejącą bazę danych PostgreSQL jako replikę.
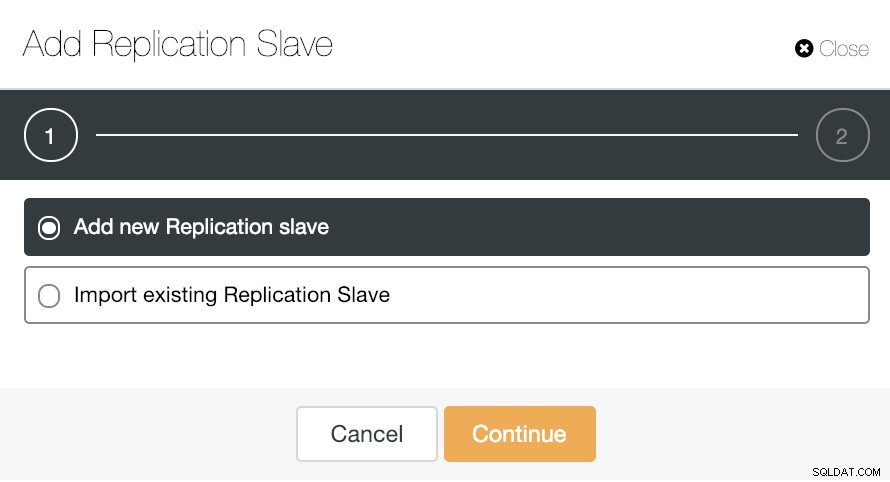
Zobaczmy, jak dodanie nowego urządzenia podrzędnego replikacji może być naprawdę łatwym zadaniem.
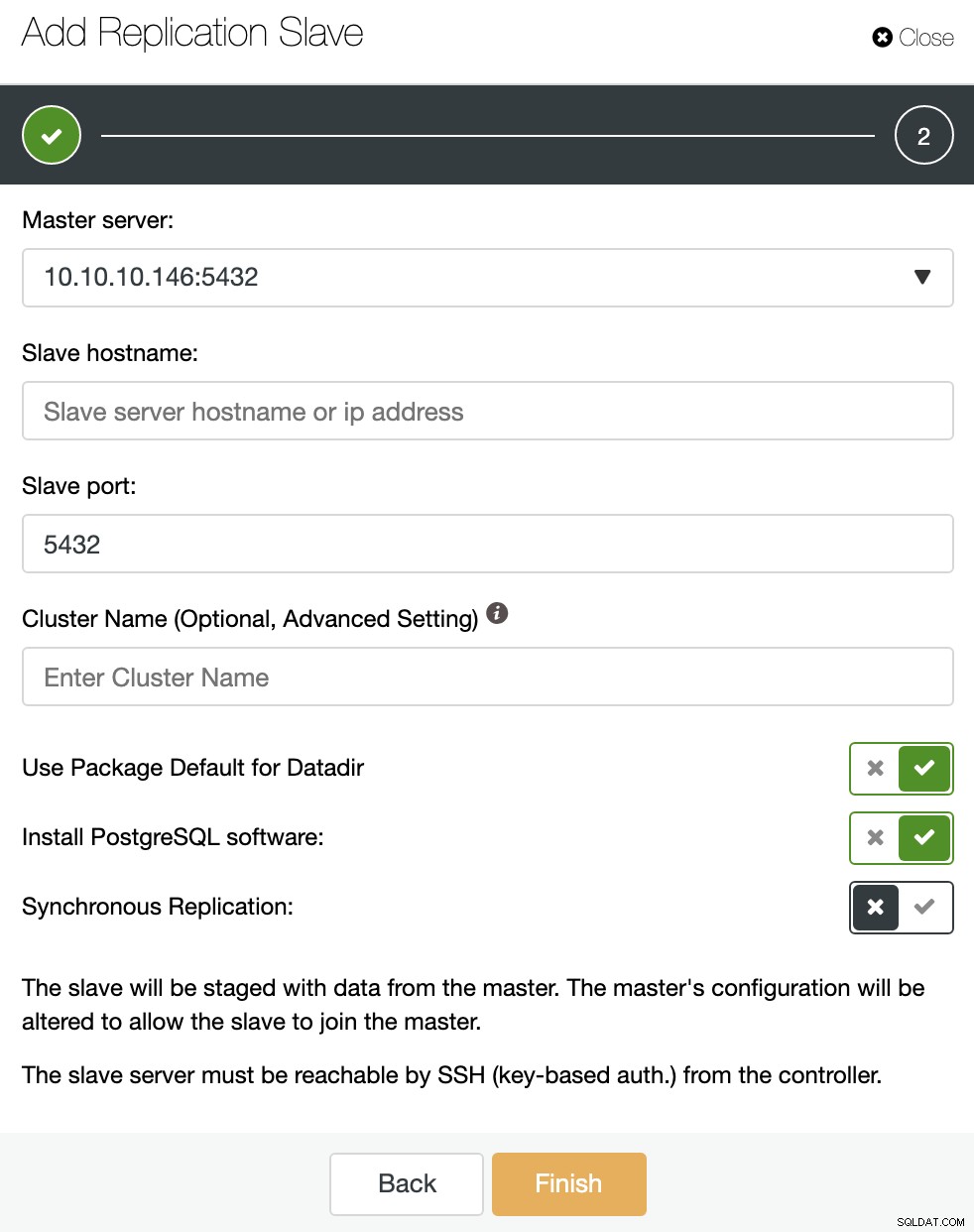
Jak widać na obrazku, wystarczy wybrać swojego Mistrza serwer, wprowadź adres IP nowego serwera podrzędnego i port bazy danych. Następnie możesz wybrać, czy chcesz, aby ClusterControl zainstalował oprogramowanie za Ciebie i czy urządzenie podrzędne replikacji powinno być synchroniczne czy asynchroniczne.
W ten sposób możesz dodać dowolną liczbę replik i rozłożyć między nimi ruch odczytu za pomocą modułu równoważenia obciążenia, który możesz również zaimplementować za pomocą ClusterControl.
Teraz, jeśli przejdziesz do działań klastra i wybierzesz „Dodaj Load Balancer”, możesz wdrożyć nowy HAProxy Load Balancer lub dodać istniejący.
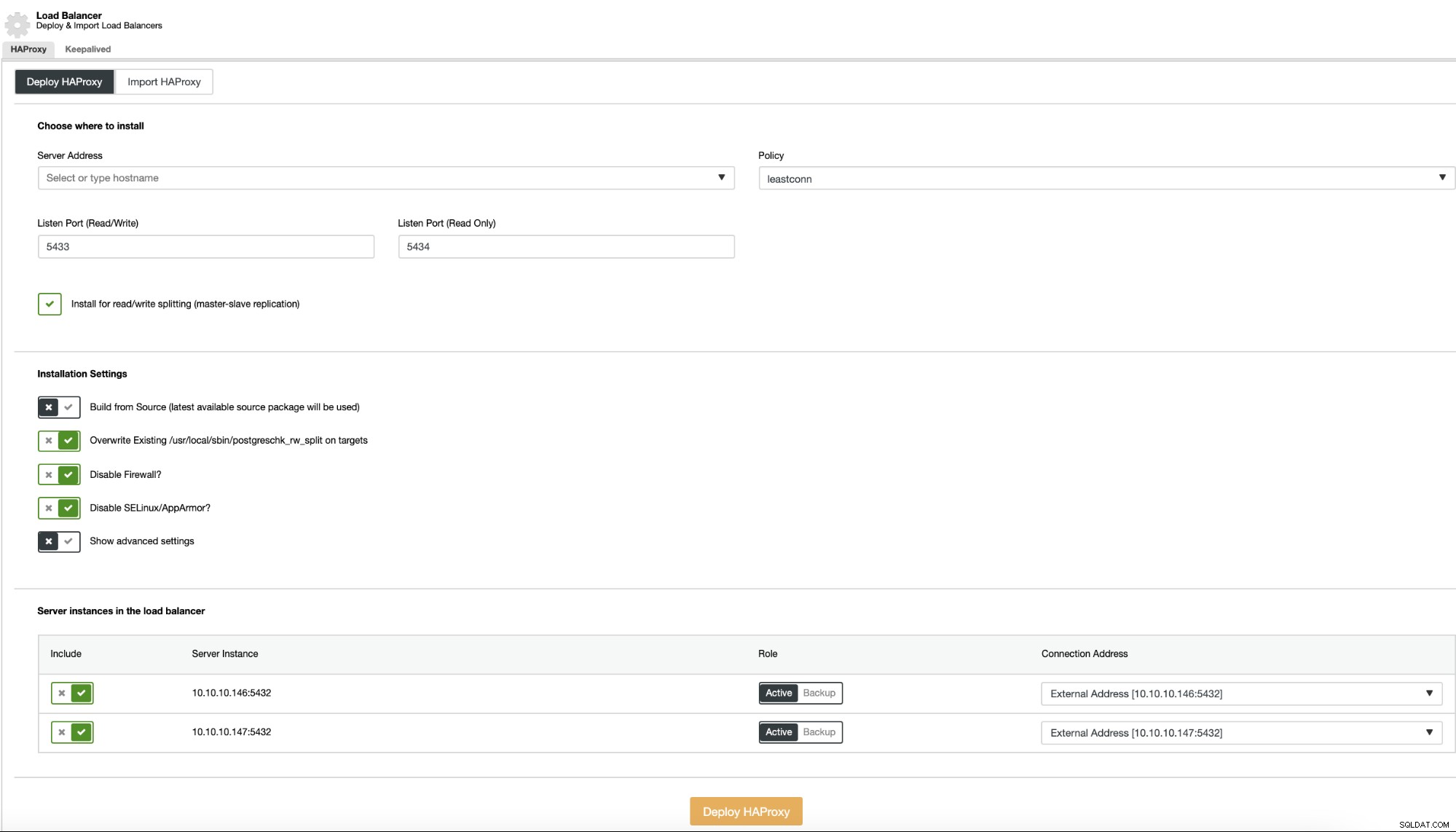
A następnie, w tej samej sekcji równoważenia obciążenia, możesz dodać Keepalived usługa, która będzie działać na węzłach systemu równoważenia obciążenia w celu poprawy środowiska wysokiej dostępności.
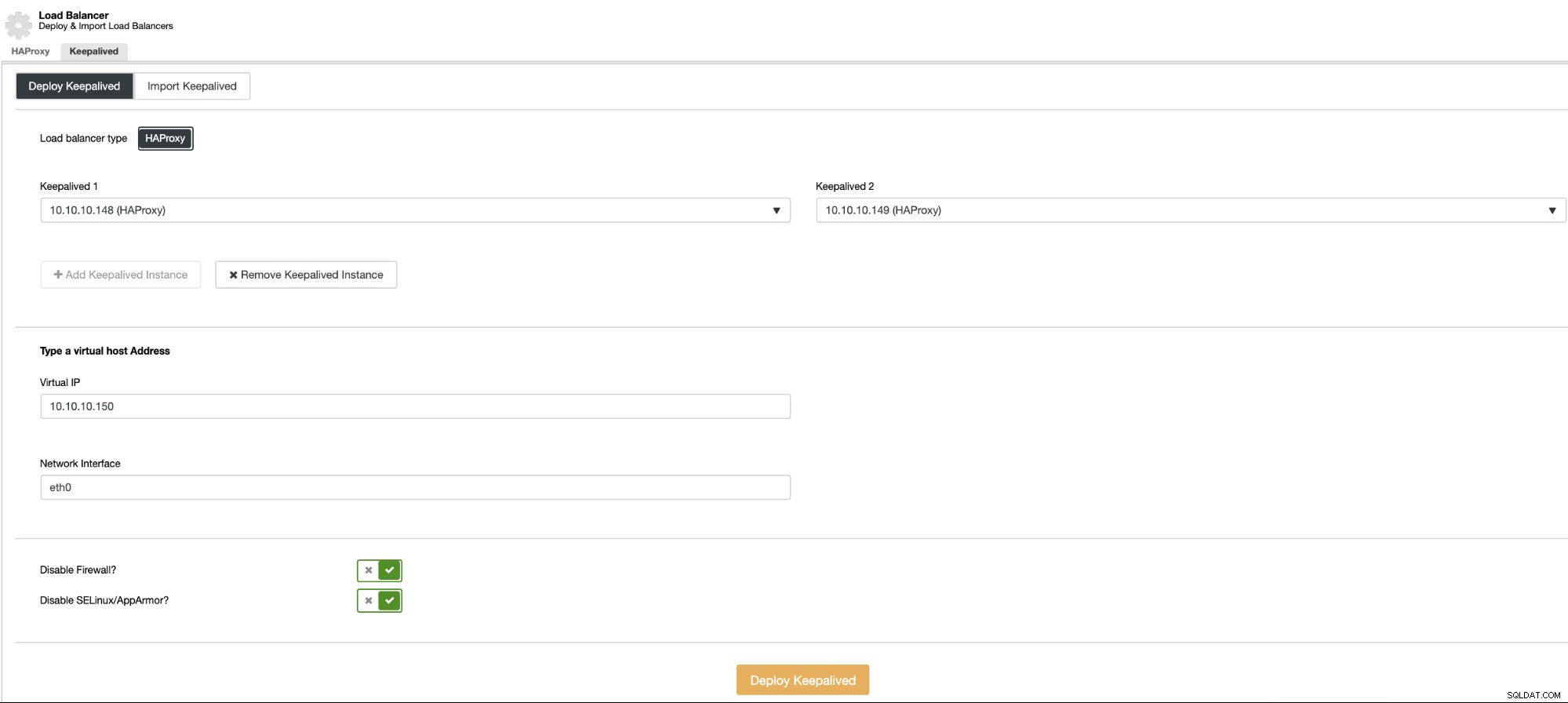
Po dodaniu Load Balancera lub użyciu wirtualnego adresu IP z usługą Keepalived w miejsce, musisz zaktualizować konfigurację Moodle, aby używać nowego punktu końcowego bazy danych. W tym celu przejdź do katalogu głównego Moodle i zmodyfikuj plik config.php przy użyciu nowego adresu IP:
$CFG->dbhost = 'IP_ADDRESS';
$CFG->dbname = 'moodle';
$CFG->dbuser = 'mdluser';
$CFG->dbpass = '********';
$CFG->prefix = 'mdl_';
$CFG->dboptions = array (
'dbpersist' => 0,
'dbport' => PORT,
'dbsocket' => '',
);Upewnij się, że możesz uzyskać dostęp do bazy danych przez Load Balancer lub wirtualny adres IP, lub jeśli musisz zaktualizować plik PostgreSQL pg_hba.conf, aby na to zezwolić.
Skalowanie w pionie
W przypadku skalowania pionowego za pomocą ClusterControl można monitorować węzły bazy danych zarówno po stronie systemu operacyjnego, jak i bazy danych. Możesz sprawdzić niektóre metryki, takie jak użycie procesora, pamięć, połączenia, najpopularniejsze zapytania, uruchomione zapytania, a nawet więcej. Możesz także włączyć sekcję Pulpit nawigacyjny, która pozwala zobaczyć dane w bardziej szczegółowy i przyjazny sposób.
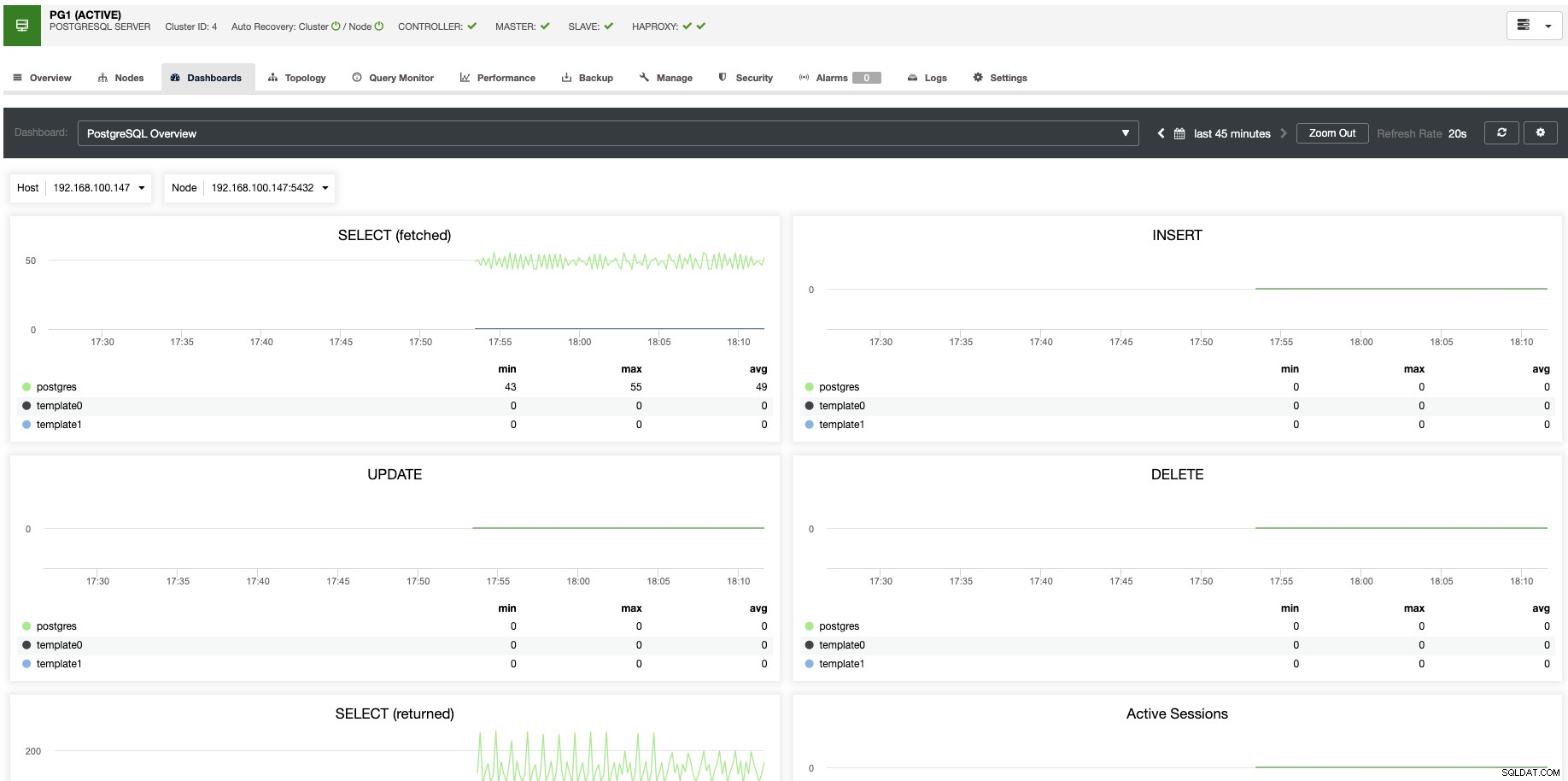
Z ClusterControl można również wykonywać różne zadania zarządzania, takie jak Reboot Host, Rebuild Replication Slave lub Promuj Slave jednym kliknięciem.
Wnioski
Skalowanie bazy danych Moodle PostgreSQL może być trudnym zadaniem, ponieważ będziesz musiał wiedzieć, jak skalować i jak to zrobić bez wpływu na systemy. Posiadanie dobrego systemu monitorowania to pierwszy krok, aby wiedzieć, kiedy i jak należy skalować bazę danych Moodle. Dodanie Load Balancer pomoże uniknąć niepotrzebnych przestojów, a także poprawi wysoką dostępność w środowisku LMS.
Wszystkie te rzeczy, o których wspomnieliśmy, można wykonać za pomocą ClusterControl, co ułatwi pracę. ClusterControl zapewnia całą gamę funkcji, takich jak monitorowanie, alarmowanie, automatyczne przełączanie awaryjne, tworzenie kopii zapasowych, przywracanie do określonego punktu w czasie, weryfikacja kopii zapasowej, skalowanie i wiele innych.