Temat buforowania pojawił się w PostgreSQL już 22 lata temu i wtedy skupiano się na niezawodności bazy danych.
W 2020 roku talerze dysków są jeszcze głębiej ukryte w środowiskach zwirtualizowanych, hipernadzorcach i powiązanych urządzeniach pamięci masowej. Co więcej, połączone ze sobą, rozproszone aplikacje działające na skalę globalną wołają o połączenia o małych opóźnieniach i nagle dostrajają pamięć podręczną serwerów, a zapytania SQL konkurują o zapewnienie, że wyniki zostaną zwrócone klientom w ciągu milisekund. Powstają pamięci podręczne na poziomie aplikacji i pamięci podręczne, a zapytania odczytu są teraz zapisywane w pobliżu serwerów aplikacji. W rezultacie operacje we/wy są ograniczone tylko do zapisów, a opóźnienia w sieci są znacznie skrócone. Z jednym haczykiem. Implementacje są odpowiedzialne za własne zarządzanie pamięcią podręczną, co czasami prowadzi do obniżenia wydajności.
Buforowanie zapisów to znacznie bardziej skomplikowana sprawa, jak wyjaśniono w wiki PostgreSQL.
Ten blog jest przeglądem pamięci podręcznych zapytań w pamięci i systemów równoważenia obciążenia używanych z PostgreSQL.
Równoważenie obciążenia PostgreSQL
Pomysł równoważenia obciążenia pojawił się w tym samym czasie, co buforowanie, w 1999 roku, kiedy Bruce Momjiam napisał:
[...] możliwe, że w niedalekiej przyszłości będziemy _bardzo_ popularni.
Podstawą implementacji równoważenia obciążenia w PostgreSQL jest wbudowana funkcja Hot Standby. Jedynym wymaganiem jest, aby aplikacja obsługiwała przełączanie awaryjne i tutaj pojawiają się rozwiązania innych firm. Przyjrzymy się niektórym z tych rozwiązań w następnych sekcjach.
Kwerendy o zrównoważonym obciążeniu mogą zwracać spójne wyniki tylko pod warunkiem, że opóźnienie replikacji synchronicznej jest utrzymywane na niskim poziomie. W praktyce nawet najnowocześniejsza infrastruktura sieciowa, taka jak AWS, może wykazywać dziesiątki milisekund opóźnień:
Zazwyczaj obserwujemy opóźnienia w dziesiątkach milisekund. [...] Jednak w typowych warunkach, w ciągu minuty opóźnienia replikacji jest powszechne. [...]
Na repliki międzyregionalne korzystające z replikacji logicznej będą miały wpływ szybkość zmiany/zastosowania i opóźnienia w komunikacji sieciowej między określonymi wybranymi regionami. Repliki międzyregionalne korzystające z Aurora Global Database będą miały typowe opóźnienie poniżej sekundy.
Jak wspomniano wcześniej, rozwiązania innych firm opierają się na podstawowych funkcjach PostgreSQL. Na przykład równoważenie obciążenia zapytań odczytu uzyskuje się przy użyciu wielu synchronicznych stanów gotowości.
Rozwiązania
pgpool-II
pgpool-II to bogaty w funkcje produkt zapewniający zarówno równoważenie obciążenia, jak i buforowanie zapytań w pamięci. Jest to zamiennik typu drop-in, nie są wymagane żadne zmiany po stronie aplikacji.
Jako równoważnik obciążenia, pgpool-II sprawdza każde zapytanie SQL — w celu zrównoważenia obciążenia, zapytania SELECT muszą spełniać kilka warunków.
Konfiguracja może być tak prosta, jak jeden węzeł, poniżej pokazano klaster z dwoma węzłami:
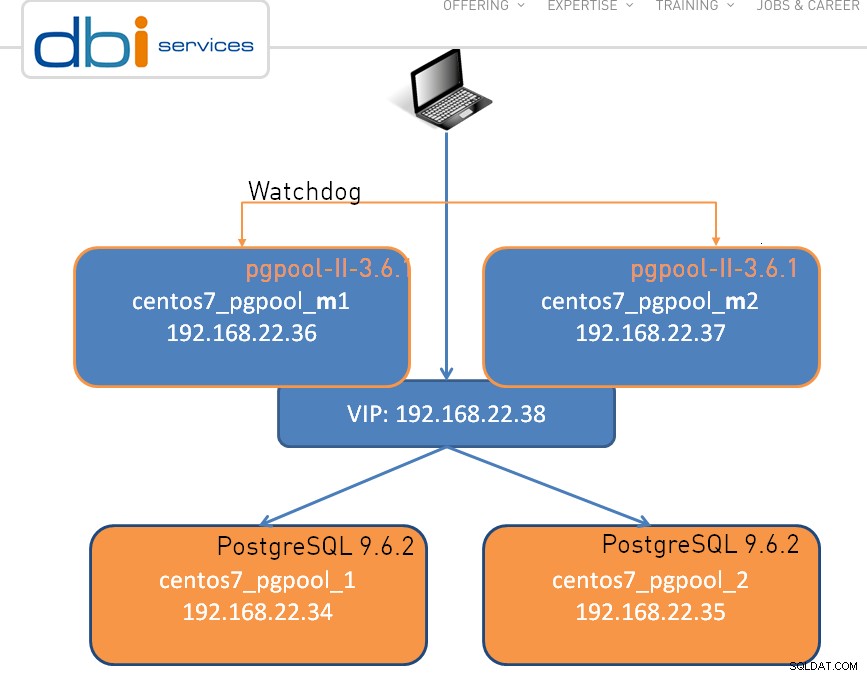
Tak jak w przypadku każdego świetnego oprogramowania, istnieją pewne ograniczenia , a pgpool-II nie robi wyjątku:
- Nie obsługuje zapytań wielowyrazowych.
- Kwerendy SELECT dotyczące tabel tymczasowych wymagają komentarza SQL /*NO LOAD BALANCE*/.
Aplikacje działające w środowiskach o wysokiej wydajności skorzystają na mieszanej konfiguracji, w której pgBouncer jest pulą połączeń, a pgpool-II obsługuje równoważenie obciążenia i buforowanie. Rezultatem jest imponujący 4-krotny wzrost przepustowości i 40-procentowe zmniejszenie opóźnień:
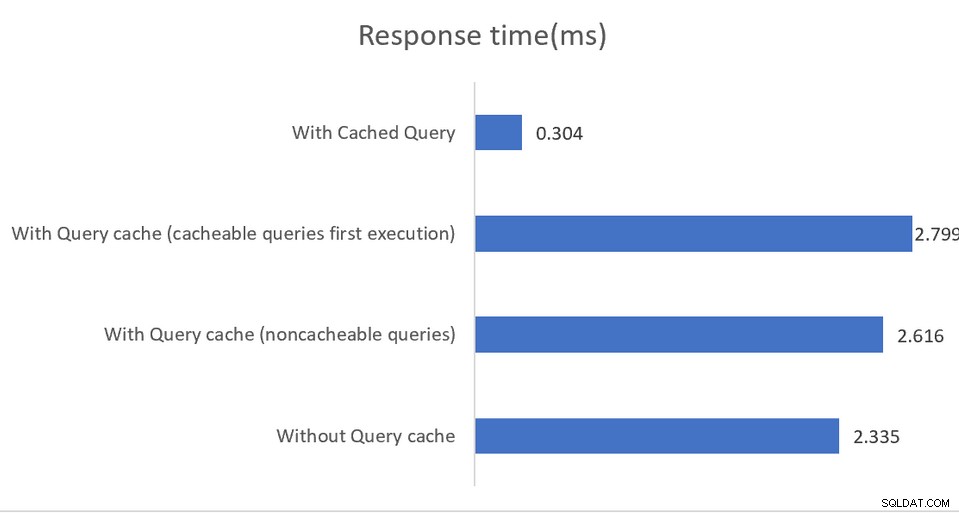
Buforowanie w pamięci działa ponownie tylko w przypadku zapytań odczytu, z buforowaniem dane są zapisywane w pamięci współdzielonej lub w zewnętrznej instalacji memcached. Chociaż dokumentacja jest całkiem dobra w wyjaśnianiu różnych opcji konfiguracyjnych, pośrednio sugeruje, że implementacje muszą monitorować dane wyjściowe SHOW POOL CACHE, aby ostrzegać o współczynnikach trafień spadających poniżej 70%, w którym to momencie następuje utrata wydajności zapewnianej przez buforowanie.
Bucardo
Bucardo to narzędzie do replikacji PostgreSQL napisane w Perlu i PL/Perl.
Wspomniałem o Bucardo, ponieważ równoważenie obciążenia jest jedną z jego funkcji, według wiki PostgreSQL, jednak wyszukiwanie w Internecie nie daje odpowiednich wyników. Aby wyjaśnić, udałem się do oficjalnej dokumentacji, która zawiera szczegóły dotyczące tego, jak faktycznie działa oprogramowanie:

To dość jasne, że Bucardo nie jest systemem równoważenia obciążenia, tak jak został wskazany przez ludzi z Database Soup.
HAProxy
HAProxy to system równoważenia obciążenia ogólnego przeznaczenia, który działa na poziomie TCP (na potrzeby połączeń z bazą danych). Kontrole stanu zapewniają, że zapytania są wysyłane tylko do aktywnych węzłów.
W porównaniu z pgpool-II, aplikacje używające HAProxy jako równoważnika obciążenia, muszą być świadome, że punkt końcowy wysyła żądania do węzłów czytników.
Zapalenie Apache
Apache Ignite to pamięć podręczna drugiego poziomu, która rozumie SQL ANSI-99 i zapewnia obsługę transakcji ACID. Apache Ignite nie rozumie protokołu PostgreSQL Frontend/Backend i dlatego aplikacje muszą korzystać z warstwy trwałości, takiej jak Hibernate ORM. Jako alternatywę dla modyfikowania aplikacji, Apache Ignite zapewnia `memcached integration`_, które wymaga rozszerzenia memcached PostgreSQL. Niestety ta druga opcja nie jest kompatybilna z najnowszymi wersjami PostgreSQL, ponieważ rozszerzenie pgmemcache zostało ostatnio zaktualizowane w 2017 roku.
Dane Heimdalla
Jako produkt komercyjny, Heimdall Data zaznacza oba pola:równoważenie obciążenia i buforowanie. To dojrzały produkt, który był prezentowany na konferencjach PostgreSQL już na PGCon 2017:

Więcej informacji i prezentacja produktu można znaleźć na blogu Azure for PostgreSQL .
Wnioski
W dzisiejszym przetwarzaniu rozproszonym buforowanie zapytań i równoważenie obciążenia są tak samo ważne dla dostrajania wydajności PostgreSQL, jak dobrze znane GUC, jądro systemu operacyjnego, pamięć masowa i optymalizacja zapytań. Podczas gdy pgpool-II i Heimdall Data są rozwiązaniami typu open source i odpowiednio preferowanymi rozwiązaniami komercyjnymi, istnieją przypadki, w których celowo wykonane narzędzia mogą zostać użyte jako elementy konstrukcyjne do osiągnięcia podobnych wyników.