PostgreSQL to jedna z baz danych, które można wdrożyć za pośrednictwem ClusterControl, wraz z MySQL, MariaDB i MongoDB. ClusterControl nie tylko upraszcza wdrażanie klastra bazy danych, ale ma również funkcję skalowalności w przypadku, gdy aplikacja się rozrasta i wymaga tej funkcjonalności.
Dzięki skalowaniu bazy danych aplikacja będzie działać znacznie płynniej i lepiej w przypadku wzrostu obciążenia aplikacji lub ruchu. W tym poście na blogu omówimy kroki dotyczące wdrażania i skalowania PostgreSQL v13 za pomocą ClusterControl 1.8.2.
Wdrażanie interfejsu użytkownika (UI)
Istnieją dwa sposoby wdrożenia w ClusterControl, webowy interfejs użytkownika (UI) oraz Command Line Interface (CLI). Użytkownik ma swobodę wyboru dowolnej opcji wdrożenia w zależności od swoich upodobań i potrzeb. Obie opcje są łatwe do naśladowania i dobrze udokumentowane w naszej dokumentacji. W tej sekcji przejdziemy przez proces wdrażania, korzystając z pierwszej opcji - internetowego interfejsu użytkownika.
Pierwszym krokiem jest zalogowanie się do ClusterControl i kliknięcie Wdróż:
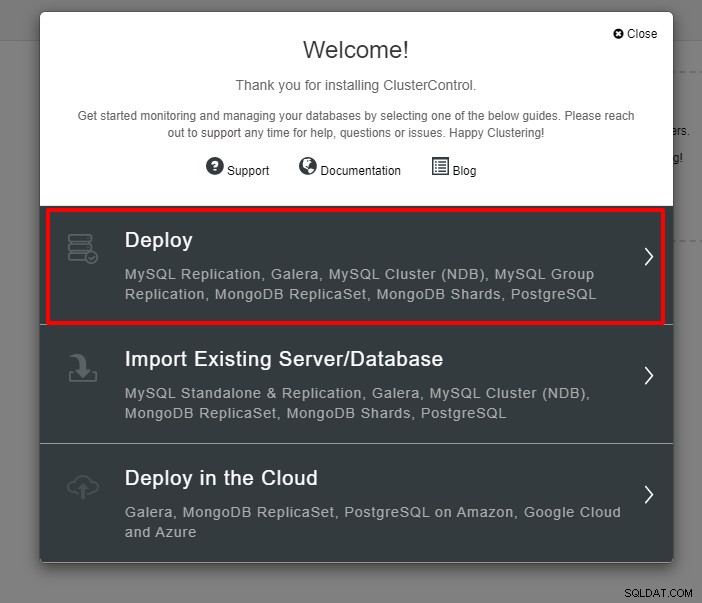
Zostanie wyświetlony poniższy zrzut ekranu przedstawiający kolejny krok wdrażania , wybierz zakładkę PostgreSQL, aby kontynuować:
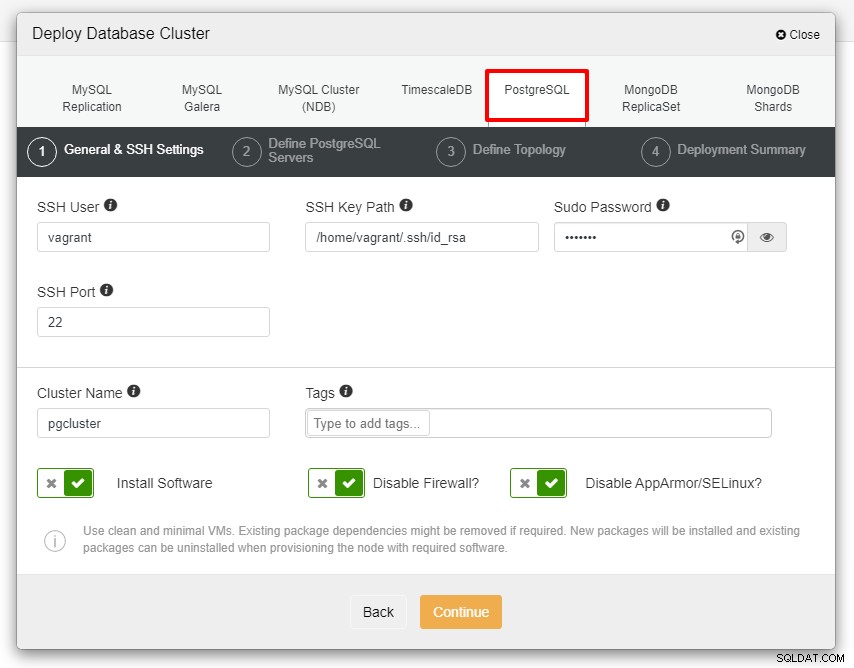
Zanim przejdziemy dalej, przypominam, że związek między węzeł ClusterControl i węzły baz danych muszą być pozbawione hasła. Przed wdrożeniem wystarczy wygenerować ssh-keygen z węzła ClusterControl, a następnie skopiować go do wszystkich węzłów. Wprowadź dane dla użytkownika SSH, hasła Sudo oraz nazwy klastra zgodnie z wymaganiami i kliknij przycisk Kontynuuj.
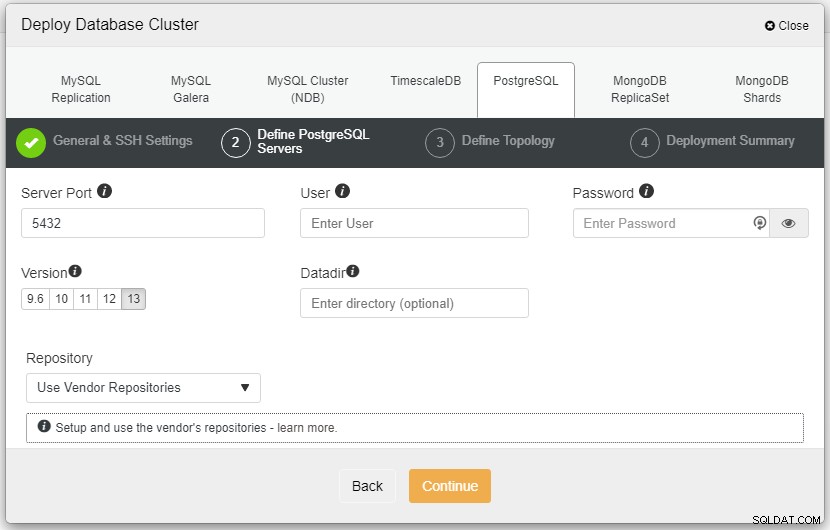
Na powyższym zrzucie ekranu musisz zdefiniować port serwera (w jeśli chcesz użyć innych), użytkownika, którego chcesz, a także hasło i upewnij się, że wybrałeś wersję 13, którą chcesz zainstalować.
 Autor zdjęciaOpis zdjęcia
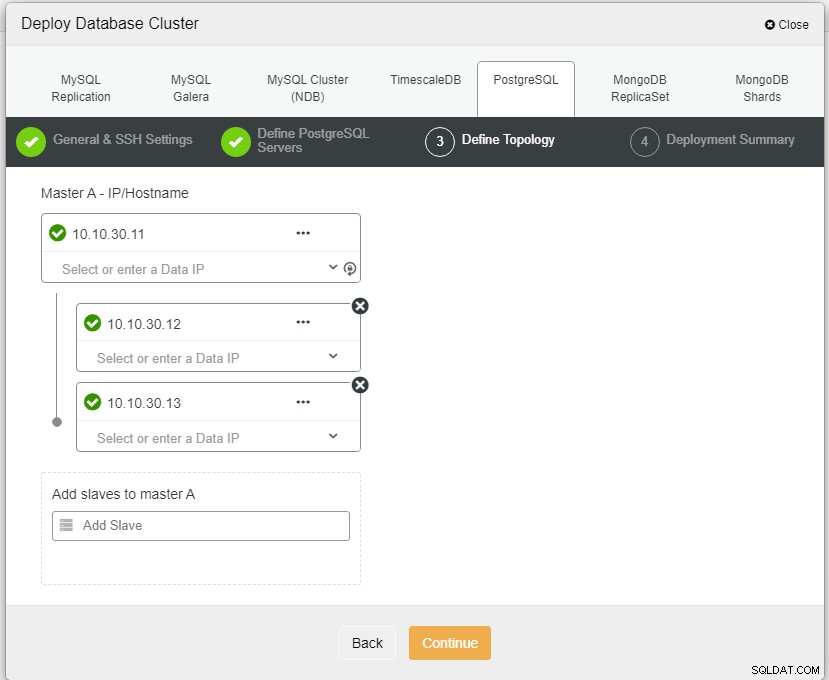
Autor zdjęciaOpis zdjęciaTutaj musimy zdefiniować serwery za pomocą nazwy hosta lub adres IP, jak w tym przypadku 1 master i 2 slave. Ostatnim krokiem jest wybór trybu replikacji dla naszego klastra.
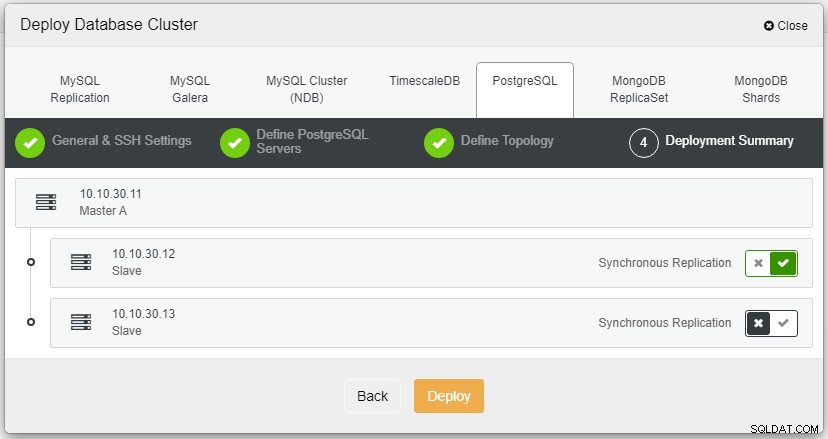
Po kliknięciu przycisku Wdróż rozpocznie się proces wdrażania i będziemy mogli monitorować postęp w zakładce Aktywność.
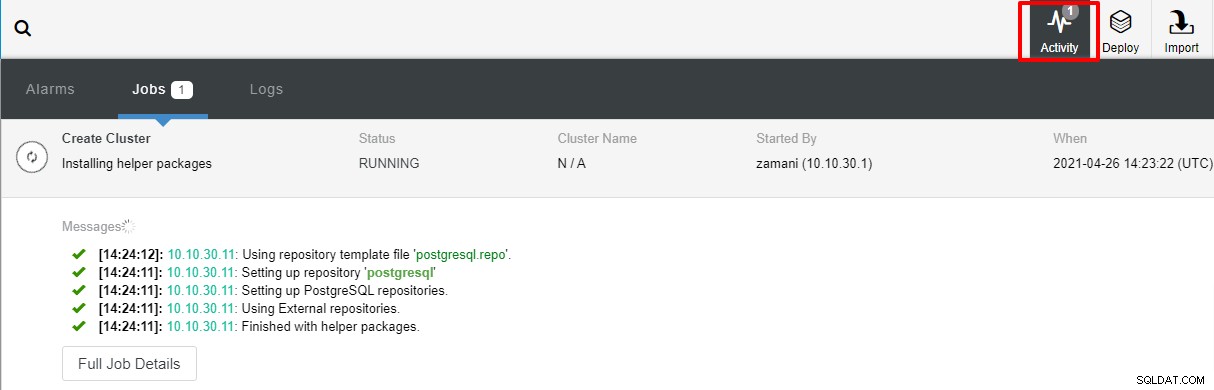
Wdrożenie zajmie zwykle kilka minut, wydajność zależy głównie od sieci i specyfikacji serwera.

Teraz mamy zainstalowany PostgreSQL v13 przy użyciu ClusterControl GUI, co jest całkiem proste .
Wdrożenie interfejsu wiersza poleceń (CLI) PostgreSQL
Z powyższego widać, że wdrożenie jest dość proste przy użyciu internetowego interfejsu użytkownika. Ważną informacją jest to, że wszystkie węzły muszą mieć połączenia SSH bez hasła przed wdrożeniem. W tej sekcji zobaczymy, jak wdrożyć za pomocą wiersza poleceń ClusterControl CLI lub narzędzi „s9s”.
Założyliśmy, że ClusterControl został zainstalowany wcześniej, zacznijmy od wygenerowania ssh-keygen. W węźle ClusterControl uruchom następujące polecenia:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3Gdy wszystkie powyższe polecenia zostaną wykonane pomyślnie, możemy zweryfikować połączenie bez hasła za pomocą następującego polecenia:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordJeśli powyższe polecenie działa pomyślnie, wdrożenie klastra można rozpocząć z serwera ClusterControl za pomocą następującego wiersza polecenia:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logZaraz po uruchomieniu powyższego polecenia zobaczysz coś takiego, co oznacza, że zadanie zostało uruchomione:
Klaster zostanie utworzony w 3 węzłach danych.
Weryfikacja parametrów zadania.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
Możesz to również zweryfikować, logując się do konsoli internetowej przy użyciu utworzonej nazwy użytkownika. Teraz mamy klaster PostgreSQL wdrożony przy użyciu 3 węzłów. Jeśli chcesz dowiedzieć się więcej o powyższym poleceniu wdrażania, oto najlepsze źródło dla Ciebie.
Skalowanie PostgreSQL w górę za pomocą interfejsu użytkownika ClusterControl
PostgreSQL jest relacyjną bazą danych i wiemy, że skalowanie tego typu bazy danych nie jest łatwe w porównaniu z nierelacyjną bazą danych. Obecnie większość aplikacji wymaga skalowalności, aby zapewnić lepszą wydajność i szybkość. Istnieje wiele sposobów na wdrożenie tego w zależności od infrastruktury i środowiska.
Skalowalność jest jedną z funkcji, którą może ułatwić ClusterControl i można ją osiągnąć zarówno za pomocą interfejsu użytkownika, jak i CLI. W tej sekcji zobaczymy, jak możemy skalować PostgreSQL za pomocą interfejsu użytkownika ClusterControl. Pierwszym krokiem jest zalogowanie się do interfejsu użytkownika i wybranie klastra, po wybraniu klastra można kliknąć opcję zgodnie z poniższym zrzutem ekranu:
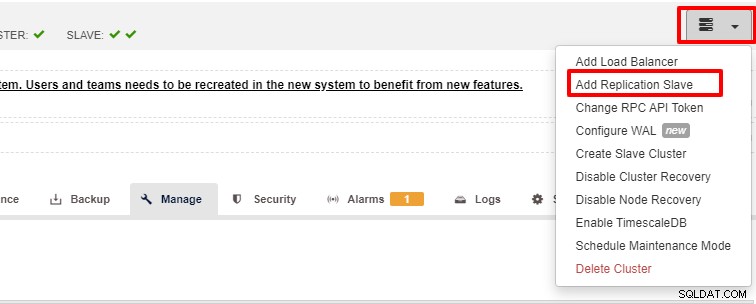
Po kliknięciu przycisku „Dodaj moduł replikacji” zostanie wyświetlona następująca strona . Możesz wybrać „Dodaj nowy…” lub „Importuj…” w zależności od sytuacji. W tym przykładzie wybierzemy pierwszą opcję:
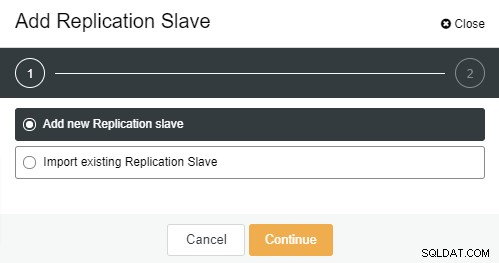
Po kliknięciu zostanie wyświetlony następujący ekran:
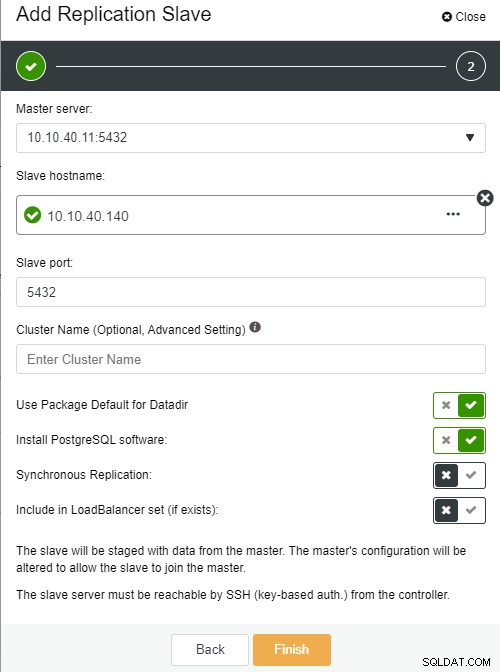 Autor zdjęciaOpis zdjęcia
Autor zdjęciaOpis zdjęcia-
Nazwa hosta urządzenia podrzędnego:nazwa hosta/adres IP nowego urządzenia podrzędnego lub węzła
-
Port Slave:port PostgreSQL urządzenia Slave, domyślnie 5432
-
Nazwa klastra:nazwa klastra, którą możesz dodać lub pozostawić pustą
-
Użyj domyślnego pakietu dla Datadir:możesz zaznaczyć tę opcję po odznaczeniu, jeśli chcesz mieć inną lokalizację dla katalogu danych
-
Zainstaluj oprogramowanie PostgreSQL:możesz pozostawić tę opcję zaznaczoną
-
Replikacja synchroniczna:możesz wybrać typ replikacji, który chcesz w tym przypadku
-
Uwzględnij w zestawie LoadBalancer (jeśli istnieje):tę opcję należy zaznaczyć, jeśli masz skonfigurowany LoadBalancer dla klastra
Kluczową ważną uwagą jest to, że przed uruchomieniem tej konfiguracji musisz skonfigurować nowy host podrzędny tak, aby nie zawierał hasła. Gdy wszystko zostanie potwierdzone, możemy kliknąć przycisk „Zakończ”, aby zakończyć konfigurację. W tym przykładzie dodałem adres IP „10.10.40.140”.
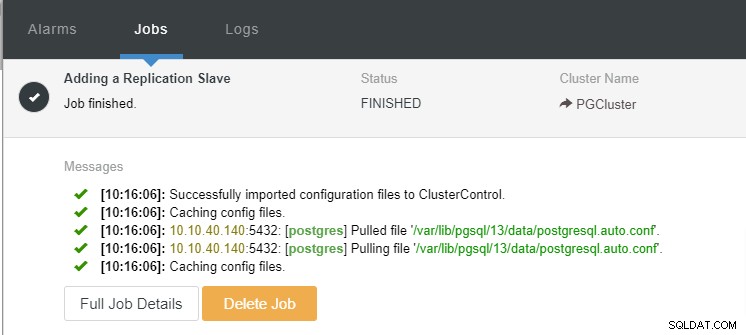
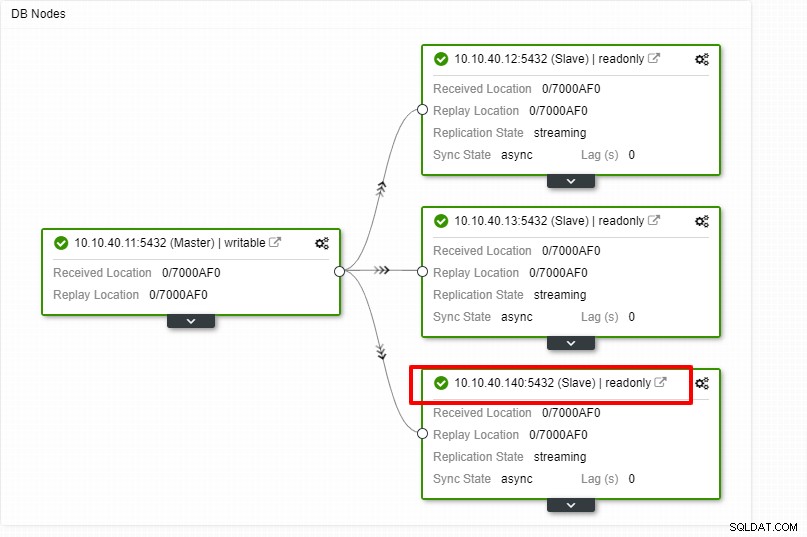
Możemy teraz monitorować aktywność zadania i pozwolić na zakończenie instalacji. Aby potwierdzić konfigurację, możemy przejść do zakładki „Topologia”, aby zobaczyć nowe urządzenie podrzędne:
Skalowanie PostgreSQL za pomocą ClusterControl CLI
Dodanie nowych węzłów do istniejącego klastra jest bardzo proste przy użyciu CLI. Z węzła kontrolera wykonujesz następujące polecenie. Pierwszym poleceniem jest zidentyfikowanie klastra, do którego chcielibyśmy dodać nowy węzeł:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.W tym przykładzie widzimy, że identyfikator węzła to „1” dla nazwy klastra „PGCluster”. Zobaczmy pierwszą opcję polecenia dotyczącą dodawania nowego węzła do istniejącego klastra PostgreSQL:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logSkrótowe „--log” na końcu wiersza pozwoli nam zobaczyć, jakie jest bieżące zadanie uruchomione po wykonaniu polecenia zgodnie z poniższym:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…Następne dostępne polecenie, którego możesz użyć, to:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitDodaj węzeł do klastra
\ Job 9 RUNNING [▋ ] 5% Installing packagesZauważ, że w wierszu jest skrót „--czekaj”, a wynik, który zobaczysz, zostanie wyświetlony jak powyżej. Po zakończeniu procesu możemy potwierdzić nowe węzły na karcie „Przegląd” klastra z interfejsu użytkownika:
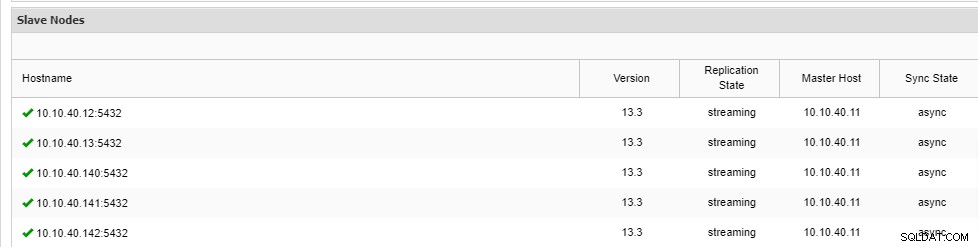
Wnioski
W tym poście na blogu omówiliśmy dwie opcje skalowania PostgreSQL w ClusterControl. Jak możesz zauważyć, skalowanie PostgreSQL jest łatwe dzięki ClusterControl. ClusterControl nie tylko zapewnia skalowalność, ale także umożliwia konfigurację wysokiej dostępności dla klastra bazy danych. Funkcje takie jak HAProxy, PgBouncer i Keepalived są dostępne i gotowe do wdrożenia w klastrze, gdy tylko poczujesz potrzebę tych opcji. Dzięki ClusterControl klaster bazy danych jest łatwy w zarządzaniu i monitorowaniu w tym samym czasie.
Mamy nadzieję, że ten wpis na blogu pomoże Ci w skalowaniu konfiguracji PostgreSQL.



