W świecie technologii informatycznych automatyzacja nie jest dla większości z nas nowością. W rzeczywistości większość organizacji używa go do różnych celów, w zależności od rodzaju pracy i celów. Na przykład analitycy danych używają automatyzacji do generowania raportów, administratorzy systemu używają automatyzacji do swoich powtarzalnych zadań, takich jak czyszczenie miejsca na dysku, a programiści używają automatyzacji do automatyzacji procesu rozwoju.
Obecnie dostępnych jest wiele narzędzi automatyzacji dla IT, które można wybrać dzięki erze DevOps. Jakie jest najlepsze narzędzie? Odpowiedź brzmi:„to zależy”, ponieważ zależy to od tego, co staramy się osiągnąć, a także od konfiguracji naszego środowiska. Niektóre z narzędzi automatyzacji to Terraform, Bolt, Chef, SaltStack, a bardzo modnym jest Ansible. Ansible to bezagentowy silnik IT typu open source, który może zautomatyzować wdrażanie aplikacji, zarządzanie konfiguracją i orkiestrację IT. Ansible powstał w 2012 roku i został napisany w najpopularniejszym języku, Python. Wykorzystuje podręcznik do implementacji całej automatyzacji, w którym wszystkie konfiguracje są napisane w języku czytelnym dla człowieka, YAML.
W dzisiejszym poście dowiemy się, jak używać Ansible do wdrażania bazy danych Postgresql.
Co sprawia, że Ansible jest wyjątkowy?
Powodem używania ansibla są głównie jego cechy. Te funkcje to:
-
Wszystko można zautomatyzować za pomocą prostego, czytelnego dla człowieka języka YAML
-
Żaden agent nie zostanie zainstalowany na zdalnym komputerze (architektura bez agenta)
-
Konfiguracja zostanie przesłana z twojego komputera lokalnego na serwer z twojego komputera lokalnego (model push)
-
Opracowany przy użyciu Pythona (jednego z popularnych obecnie używanych języków) i można z niego wybrać wiele bibliotek
-
Zbiór modułów Ansible starannie wybranych przez zespół inżynierów Red Had
Sposób działania Ansible
Zanim Ansible będzie mógł uruchamiać jakiekolwiek zadania operacyjne na zdalnych hostach, musimy zainstalować go na jednym hoście, który stanie się węzłem kontrolera. W tym węźle kontrolera będziemy organizować wszelkie zadania, które chcielibyśmy wykonać na zdalnych hostach, znanych również jako węzły zarządzane.
Węzeł kontrolera musi mieć spis zarządzanych węzłów i oprogramowanie Ansible, aby nim zarządzać. Wymagane dane, które mają być używane przez Ansible, takie jak nazwa hosta zarządzanego węzła lub adres IP, zostaną umieszczone w tym ekwipunku. Bez odpowiedniego ekwipunku Ansible nie mógł poprawnie wykonać automatyzacji. Zobacz tutaj, aby dowiedzieć się więcej o ekwipunku.
Ansible jest bezagentowy i używa SSH do wypychania zmian, co oznacza, że nie musimy instalować Ansible we wszystkich węzłach, ale wszystkie zarządzane węzły muszą mieć zainstalowane Pythona i wszelkie niezbędne biblioteki Pythona. Zarówno węzeł kontrolera, jak i węzły zarządzane muszą być ustawione jako bezhasła. Warto wspomnieć, że połączenie między wszystkimi węzłami kontrolera a węzłami zarządzanymi jest dobre i poprawnie przetestowane.
W tym demo udostępniłem 4 maszyny wirtualne Centos 8 za pomocą vagrant. Jeden będzie działał jako węzeł kontrolera, a pozostałe 2 maszyny wirtualne będą działać jako węzły bazy danych do wdrożenia. W tym poście na blogu nie będziemy szczegółowo omawiać instalacji Ansible, ale jeśli chcesz zapoznać się z przewodnikiem, odwiedź ten link. Należy zauważyć, że do skonfigurowania topologii replikacji strumieniowej używamy 3 węzłów, z jednym węzłem podstawowym i 2 węzłem rezerwowym. Obecnie wiele produkcyjnych baz danych jest w konfiguracji o wysokiej dostępności, a konfiguracja z trzema węzłami jest powszechna.
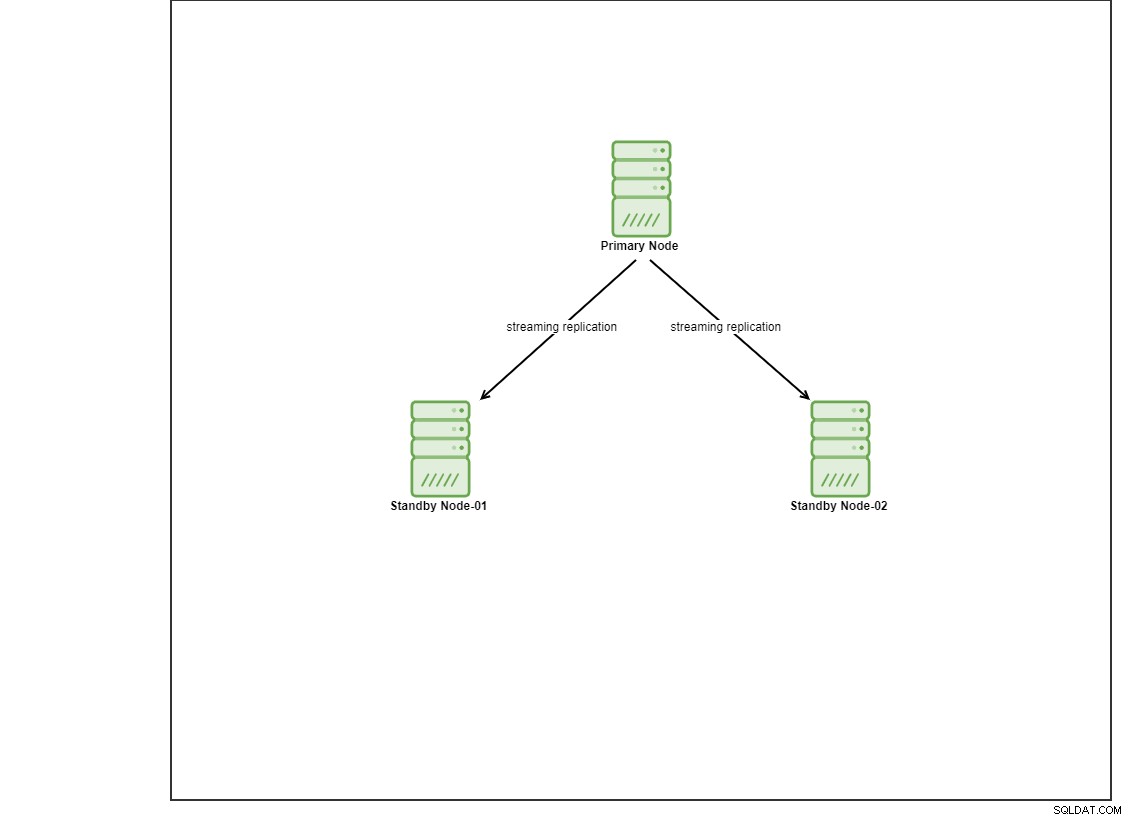
Instalowanie PostgreSQL
Istnieje kilka sposobów instalacji PostgreSQL przy użyciu Ansible. Dzisiaj będę używał ról Ansible, aby osiągnąć ten cel. Ansible Roles w skrócie to zestaw zadań służących do konfigurowania hosta do określonego celu, na przykład konfigurowania usługi. Role Ansible są definiowane za pomocą plików YAML ze wstępnie zdefiniowaną strukturą katalogów, które można pobrać z portalu Ansible Galaxy.
Ansible Galaxy z drugiej strony jest repozytorium ról Ansible, które można wrzucić bezpośrednio do Poradników w celu usprawnienia projektów automatyzacji.
W tym demo wybrałem role, które opiekował się dudefellah. Abyśmy mogli wykorzystać tę rolę, musimy ją pobrać i zainstalować w węźle kontrolera. Zadanie jest dość proste i można je wykonać, uruchamiając następujące polecenie, pod warunkiem, że Ansible został zainstalowany w węźle kontrolera:
$ ansible-galaxy install dudefellah.postgresqlPo pomyślnym zainstalowaniu roli w węźle kontrolera powinien pojawić się następujący wynik:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Abyśmy mogli zainstalować PostgreSQL używając tej roli, musimy wykonać kilka kroków. Oto Poradnik Ansible. Ansible Playbook to miejsce, w którym możemy napisać kod Ansible lub zbiór skryptów, które chcielibyśmy uruchomić na zarządzanych węzłach. Ansible Playbook używa YAML i składa się z jednego lub więcej odtworzeń uruchamianych w określonej kolejności. Możesz zdefiniować hosty, a także zestaw zadań, które chcesz uruchomić na przypisanych hostach lub węzłach zarządzanych.
Wszystkie zadania zostaną wykonane jako użytkownik ansible, który się zalogował. Abyśmy mogli wykonać zadania z innym użytkownikiem, w tym „root”, możemy użyć zostań. Rzućmy okiem na pg-play.yml poniżej:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Jak widać, zdefiniowałem hosty jako pgcluster i wykorzystałem funkcję staj się, aby Ansible uruchamiał zadania z uprawnieniami sudo. Użytkownik włóczęga jest już w grupie sudoer. Zdefiniowałem też rolę jaką zainstalowałem dudefellah.postgresql. pgcluster został zdefiniowany w utworzonym przeze mnie pliku hosts. Jeśli zastanawiasz się, jak to wygląda, możesz zajrzeć poniżej:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleOprócz tego stworzyłem inny niestandardowy plik (custom_var.yml), w którym zawarłem całą konfigurację i ustawienia dla PostgreSQL, które chciałbym zaimplementować. Szczegóły dotyczące pliku niestandardowego są następujące:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Aby uruchomić instalację, wystarczy wykonać następujące polecenie. Nie będziesz w stanie uruchomić polecenia ansible-playbook bez utworzonego pliku playbook (w moim przypadku jest to pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostPo wykonaniu tego polecenia uruchomi ono kilka zadań zdefiniowanych przez rolę i wyświetli ten komunikat, jeśli polecenie zostanie wykonane pomyślnie:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Gdy ansible wykonał zadania, zalogowałem się do slave'a (n2), zatrzymałem usługę PostgreSQL, usunąłem zawartość katalogu data (/var/lib/pgsql/13/data/) i uruchom następujące polecenie, aby zainicjować zadanie tworzenia kopii zapasowej:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Możemy również sprawdzić stan replikacji w trybie gotowości za pomocą następującego polecenia po ponownym uruchomieniu usługi PostgreSQL:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyJak widać, jest wiele pracy do wykonania, abyśmy mogli skonfigurować replikację dla PostgreSQL, mimo że zautomatyzowaliśmy niektóre zadania. Zobaczmy, jak można to osiągnąć za pomocą ClusterControl.
Wdrażanie PostgreSQL przy użyciu GUI ClusterControl
Teraz, gdy wiemy, jak wdrożyć PostgreSQL za pomocą Ansible, zobaczmy, jak możemy wdrożyć za pomocą ClusterControl. ClusterControl to oprogramowanie do zarządzania i automatyzacji klastrów baz danych, w tym MySQL, MariaDB, MongoDB oraz TimescaleDB. Pomaga wdrażać, monitorować, zarządzać i skalować klaster baz danych. Istnieją dwa sposoby wdrożenia bazy danych, w tym poście na blogu pokażemy, jak wdrożyć ją za pomocą graficznego interfejsu użytkownika (GUI), zakładając, że masz już zainstalowany ClusterControl w swoim środowisku.
Pierwszym krokiem jest zalogowanie się do ClusterControl i kliknięcie Wdróż:
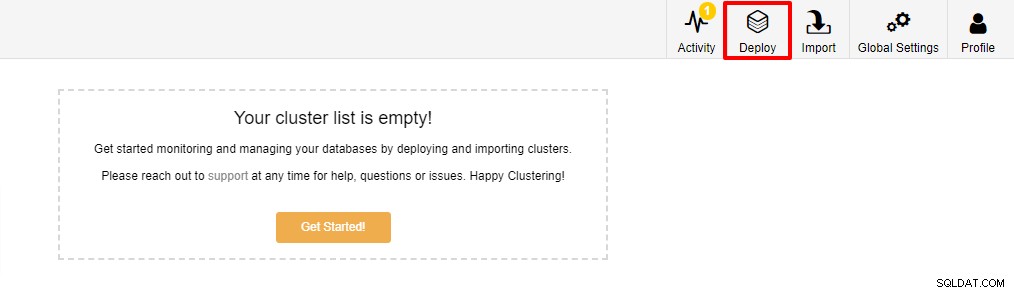
Zostanie wyświetlony poniższy zrzut ekranu przedstawiający kolejny krok wdrażania , wybierz zakładkę PostgreSQL, aby kontynuować:
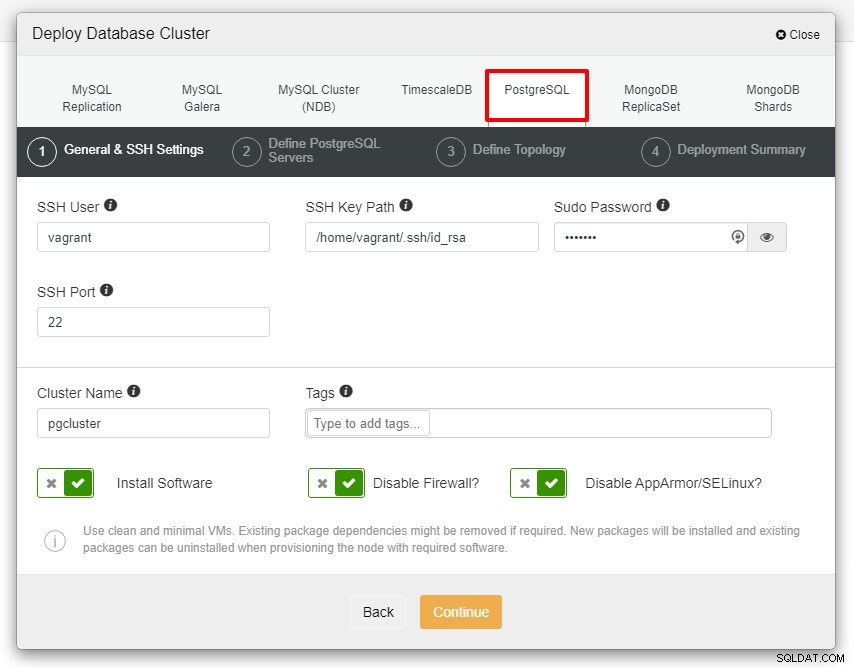
Zanim przejdziemy dalej, chciałbym przypomnieć, że połączenie między węzłem ClusterControl a węzłami baz danych musi być bezhasłowe. Przed wdrożeniem wystarczy wygenerować ssh-keygen z węzła ClusterControl, a następnie skopiować go do wszystkich węzłów. Wprowadź dane dla użytkownika SSH, hasła Sudo oraz nazwy klastra zgodnie z wymaganiami i kliknij przycisk Kontynuuj.
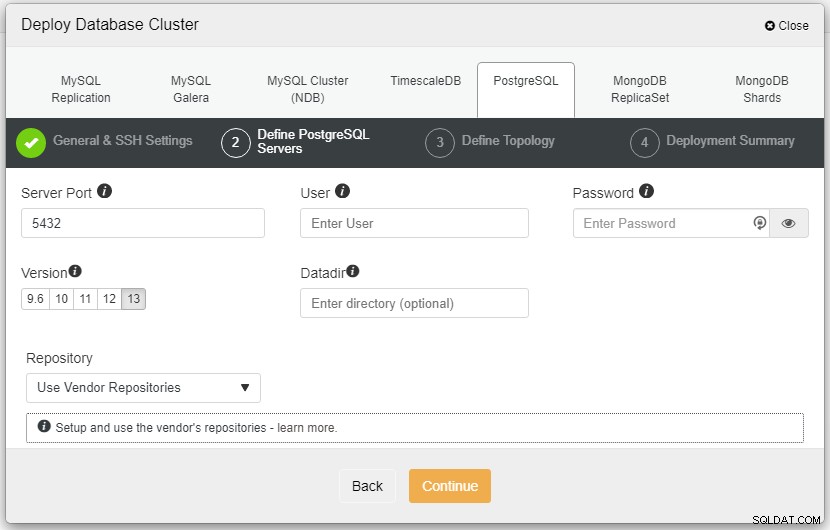
Na powyższym zrzucie ekranu musisz zdefiniować port serwera (w przypadku, gdy chcesz użyć innych), użytkownika, którego chcesz, a także hasło i wersję, którą chcesz zainstalować.
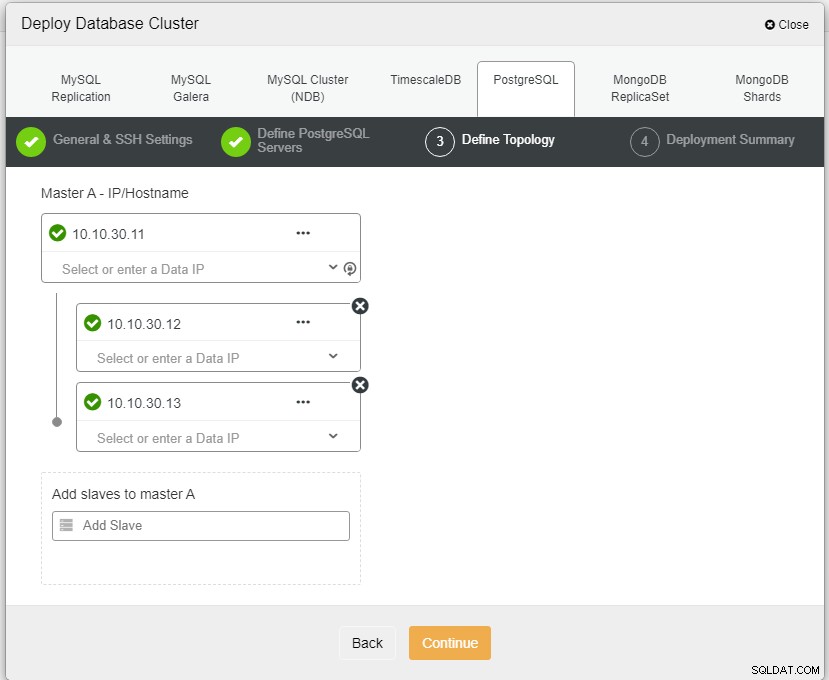
Tutaj musimy zdefiniować serwery za pomocą nazwy hosta lub adresu IP, tak jak w tym przypadku 1 master i 2 slave. Ostatnim krokiem jest wybór trybu replikacji dla naszego klastra.
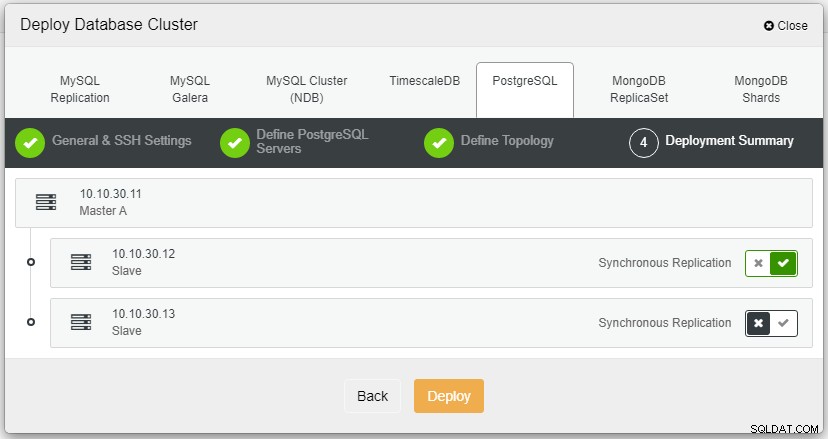
Gdy klikniesz Wdróż, rozpocznie się proces wdrażania i będziemy mogli monitorować postęp na karcie Aktywność.
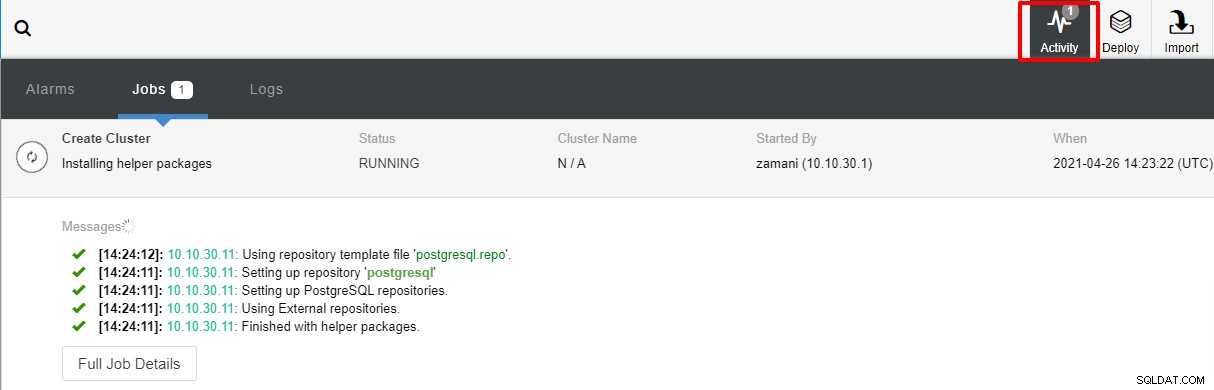
Wdrożenie zajmie zwykle kilka minut, wydajność zależy głównie od sieci i specyfikacji serwera.

Teraz mamy zainstalowany PostgreSQL przy użyciu ClusterControl.
Wdrażanie PostgreSQL przy użyciu ClusterControl CLI
Innym alternatywnym sposobem wdrożenia PostgreSQL jest użycie CLI. pod warunkiem, że skonfigurowaliśmy już połączenie bez hasła, możemy po prostu wykonać następujące polecenie i pozwolić mu się zakończyć.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logPowinieneś zobaczyć poniższy komunikat po pomyślnym zakończeniu procesu i możesz zalogować się do sieci ClusterControl, aby zweryfikować:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Wnioski
Jak widać, istnieje kilka sposobów wdrożenia PostgreSQL. W tym poście na blogu dowiedzieliśmy się, jak wdrożyć go za pomocą Ansible, a także za pomocą naszego ClusterControl. Oba sposoby są łatwe do naśladowania i można je osiągnąć przy minimalnej krzywej uczenia się. Dzięki ClusterControl konfigurację replikacji strumieniowej można uzupełnić o HAProxy, VIP i PGBouncer, aby dodać do konfiguracji przełączanie awaryjne połączenia, wirtualny adres IP i pulę połączeń.
Pamiętaj, że wdrożenie to tylko jeden aspekt środowiska produkcyjnej bazy danych. Utrzymanie go w dobrym stanie, automatyzacja przełączania awaryjnego, odzyskiwanie uszkodzonych węzłów i inne aspekty, takie jak monitorowanie, alarmowanie, tworzenie kopii zapasowych są niezbędne.
Mam nadzieję, że ten wpis na blogu przyniesie korzyści niektórym z Was i podpowie, jak zautomatyzować wdrożenia PostgreSQL.