Witamy w trzeciej – i ostatniej – części tej serii blogów, badającej ewolucję wydajności PostgreSQL na przestrzeni lat. Pierwsza część dotyczyła obciążeń OLTP, reprezentowanych przez testy pgbench. Druga część dotyczyła zapytań analitycznych / BI, wykorzystując podzbiór tradycyjnego testu porównawczego TPC-H (zasadniczo część testu mocy).
I ta końcowa część dotyczy wyszukiwania pełnotekstowego, czyli możliwości indeksowania i wyszukiwania w dużych ilościach danych tekstowych. Ta sama infrastruktura (zwłaszcza indeksy) może być przydatna do indeksowania częściowo ustrukturyzowanych danych, takich jak dokumenty JSONB itp., ale nie na tym koncentruje się ten test porównawczy.
Ale najpierw spójrzmy na historię wyszukiwania pełnotekstowego w PostgreSQL, które może wydawać się dziwną funkcją do dodania do RDBMS, tradycyjnie przeznaczonej do przechowywania uporządkowanych danych w wierszach i kolumnach.
Historia wyszukiwania pełnotekstowego
Kiedy Postgres był open-source w 1996 roku, nie miał niczego, co moglibyśmy nazwać wyszukiwaniem pełnotekstowym. Ale ludzie, którzy zaczęli używać Postgresa, chcieli przeprowadzać inteligentne wyszukiwania w dokumentach tekstowych, a zapytania LIKE nie były wystarczająco dobre. Chcieli mieć możliwość lematyzacji terminów za pomocą słowników, ignorowania słów stop, sortowania pasujących dokumentów według trafności, używania indeksów do wykonywania tych zapytań i wielu innych rzeczy. Rzeczy, których nie można racjonalnie zrobić z tradycyjnymi operatorami SQL.
Na szczęście niektórzy z tych ludzi byli również programistami, więc zaczęli nad tym pracować – i mogli, dzięki dostępności PostgreSQL jako open-source na całym świecie. Na przestrzeni lat było wielu współtwórców wyszukiwania pełnotekstowego, ale początkowo tym wysiłkiem kierowali Oleg Bartunov i Teodor Sigaev, pokazani na poniższym zdjęciu. Obaj nadal są głównymi współtwórcami PostgreSQL, pracującymi nad wyszukiwaniem pełnotekstowym, indeksowaniem, obsługą JSON i wieloma innymi funkcjami.

Teodor Sigaev i Oleg Bartunov
Początkowo funkcjonalność była rozwijana jako zewnętrzny moduł „contrib” (obecnie powiedzielibyśmy, że jest to rozszerzenie) o nazwie „tsearch”, wydany w 2002 roku. Później został on przestarzały przez tsearch2, znacznie poprawiając funkcję na wiele sposobów, a także w PostgreSQL 8.3 (wydany w 2008 r.) został w pełni zintegrowany z rdzeniem PostgreSQL (tj. bez konieczności instalowania jakiegokolwiek rozszerzenia, chociaż rozszerzenia nadal zapewniały kompatybilność wsteczną).
Od tego czasu wprowadzono wiele ulepszeń (a prace trwają, np. w celu obsługi typów danych, takich jak JSONB, zapytań za pomocą jsonpath itp.). ale te wtyczki wprowadziły większość funkcji pełnotekstowych, które mamy teraz w PostgreSQL – słowniki, funkcje indeksowania pełnotekstowego i zapytań itp.
Wzorzec
W przeciwieństwie do benchmarków OLTP/TPC-H, nie znam żadnego pełnotekstowego benchmarku, który mógłby być uznany za „standard branżowy” lub zaprojektowany dla wielu systemów baz danych. Większość znanych mi testów jest przeznaczona do użytku z pojedynczą bazą danych / produktem i trudno jest je sensownie przenieść, więc musiałem wybrać inną drogę i napisać własny, pełnotekstowy test porównawczy.
Lata temu napisałem archie – kilka skryptów Pythona, które umożliwiają pobieranie archiwów list mailingowych PostgreSQL i ładowanie przeanalizowanych wiadomości do bazy danych PostgreSQL, którą można następnie indeksować i przeszukiwać. Aktualna migawka wszystkich archiwów ma ~1 mln wierszy, a po załadowaniu jej do bazy danych tabela ma około 9,5 GB (nie licząc indeksów).
Jeśli chodzi o zapytania, prawdopodobnie mógłbym wygenerować kilka losowych, ale nie jestem pewien, na ile byłoby to realistyczne. Na szczęście kilka lat temu uzyskałem próbkę 33 tys. rzeczywistych wyszukiwań ze strony PostgreSQL (tj. rzeczy, które ludzie faktycznie przeszukiwali w archiwach społeczności). Jest mało prawdopodobne, że udałoby mi się uzyskać coś bardziej realistycznego / reprezentatywnego.
Połączenie tych dwóch części (zestaw danych + zapytania) wydaje się dobrym punktem odniesienia. Możemy po prostu załadować dane i uruchomić wyszukiwanie za pomocą różnych typów zapytań pełnotekstowych z różnymi typami indeksów.
Zapytania
Istnieją różne kształty zapytań pełnotekstowych – zapytanie może po prostu wybrać wszystkie pasujące wiersze, może uszeregować wyniki (posortować je według trafności), zwrócić tylko niewielką liczbę lub najtrafniejsze wyniki itp. Przeprowadziłem benchmark z różnymi typów zapytań, ale w tym poście przedstawię wyniki dla dwóch prostych zapytań, które moim zdaniem całkiem ładnie reprezentują ogólne zachowanie.
- SELECT id, temat FROM wiadomości WHERE body_tsvector @@ $1
- SELECT id, temat FROM wiadomości WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
Pierwsze zapytanie po prostu zwraca wszystkie pasujące wiersze, podczas gdy drugie zwraca 100 najtrafniejszych wyników (jest to coś, czego prawdopodobnie użyjesz do wyszukiwania użytkowników).
Eksperymentowałem z różnymi innymi typami zapytań, ale ostatecznie wszystkie zachowywały się podobnie do jednego z tych dwóch typów zapytań.
Indeksy
Każda wiadomość ma dwie główne części, w których możemy przeszukiwać – temat i treść. Każdy z nich ma osobną kolumnę tsvector i jest osobno indeksowany. Tematy wiadomości są znacznie krótsze niż treści, więc indeksy są naturalnie mniejsze.
PostgreSQL ma dwa rodzaje indeksów przydatnych do wyszukiwania pełnotekstowego – GIN i GiST. Główne różnice wyjaśniono w dokumentacji, ale w skrócie:
- Indeksy GIN są szybsze dla wyszukiwań
- Indeksy GiST są stratne, tj. wymagają ponownego sprawdzenia podczas wyszukiwania (a więc są wolniejsze)
Kiedyś twierdziliśmy, że indeksy GiST są tańsze w aktualizacji (zwłaszcza w przypadku wielu jednoczesnych sesji), ale jakiś czas temu zostało to usunięte z dokumentacji ze względu na ulepszenia w kodzie indeksowania.
Ten benchmark nie testuje zachowania z aktualizacjami – po prostu ładuje tabelę bez indeksów pełnotekstowych, buduje je za jednym razem, a następnie wykonuje 33 tys. zapytań na danych. Oznacza to, że nie mogę składać żadnych oświadczeń o tym, jak te typy indeksów obsługują równoczesne aktualizacje w oparciu o ten test porównawczy, ale uważam, że zmiany w dokumentacji odzwierciedlają różne ostatnie ulepszenia GIN.
Powinno to również dość dobrze pasować do przypadku użycia archiwum list dyskusyjnych, w którym nowe e-maile dołączaliśmy tylko raz na jakiś czas (kilka aktualizacji, prawie brak współbieżności zapisu). Ale jeśli Twoja aplikacja wykonuje wiele jednoczesnych aktualizacji, musisz to zrobić samodzielnie.
Sprzęt
Zrobiłem benchmark na tych samych dwóch maszynach co poprzednio, ale wyniki/wnioski są prawie identyczne, więc przedstawię tylko liczby z mniejszej, tj.
- CPU i5-2500K (4 rdzenie/wątki)
- 8 GB pamięci RAM
- 6 x 100 GB SSD RAID0
- jądro 5.6.15, system plików ext4
Wspomniałem wcześniej, że po załadowaniu zestaw danych ma prawie 10 GB, więc jest większy niż pamięć RAM. Ale indeksy są nadal mniejsze niż pamięć RAM, co ma znaczenie dla testu porównawczego.
Wyniki
OK, czas na kilka liczb i wykresów. Przedstawię wyniki zarówno dla ładowania danych, jak i zapytań, najpierw z indeksami GIN, a następnie z indeksami GiST.
WZ / ładowanie danych
Myślę, że ładunek nie jest szczególnie interesujący. Po pierwsze, większość z nich (część niebieska) nie ma nic wspólnego z pełnym tekstem, ponieważ dzieje się to przed utworzeniem dwóch indeksów. Większość tego czasu spędza się na analizowaniu wiadomości, odbudowie wątków pocztowych, utrzymywaniu listy odpowiedzi i tak dalej. Część tego kodu jest zaimplementowana w wyzwalaczach PL/pgSQL, część poza bazą danych. Jedyną częścią potencjalnie związaną z pełnym tekstem jest budowanie wektorów tsvectorów, ale nie można wyodrębnić czasu, który na to poświęcono.
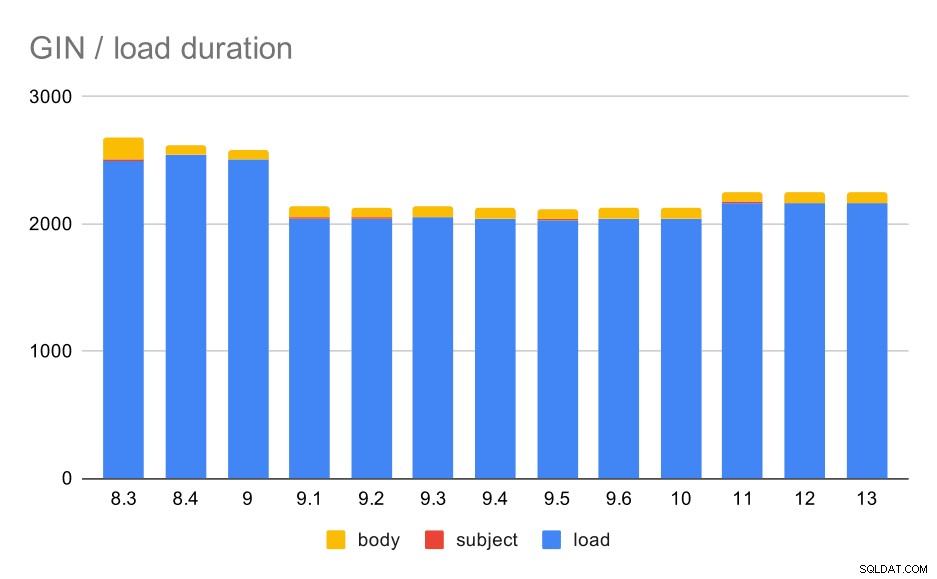
Operacje ładowania danych z tabelą i indeksami GIN.
Poniższa tabela przedstawia dane źródłowe dla tego wykresu — wartości to czas trwania w sekundach. LOAD obejmuje parsowanie archiwów mbox (ze skryptu Python), wstawianie do tabeli oraz różne dodatkowe zadania (przebudowywanie wątków e-mail itp.). SUBJECT/BODY INDEX odnosi się do tworzenia pełnotekstowego indeksu GIN w kolumnach tematu/treści po załadowaniu danych.
| ZAŁADUJ | INDEKS TEMATU | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9,5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Najwyraźniej wydajność jest dość stabilna – nastąpiła dość znaczna poprawa (około 20%) między 9,0 a 9,1. Nie jestem do końca pewien, która zmiana może być odpowiedzialna za to ulepszenie – nic w informacjach o wydaniu 9.1 nie wydaje się wyraźnie istotne. Jest też wyraźna poprawa w budowaniu indeksów GIN w 8.4, co skraca czas o połowę. Co jest oczywiście miłe. Co ciekawe, nie widzę też żadnych wyraźnie powiązanych informacji o wydaniu.
A co z rozmiarami indeksów WZ? Istnieje znacznie większa zmienność, przynajmniej do 9.4, kiedy to rozmiar indeksów spada z ~1 GB do tylko około 670 MB (około 30%).
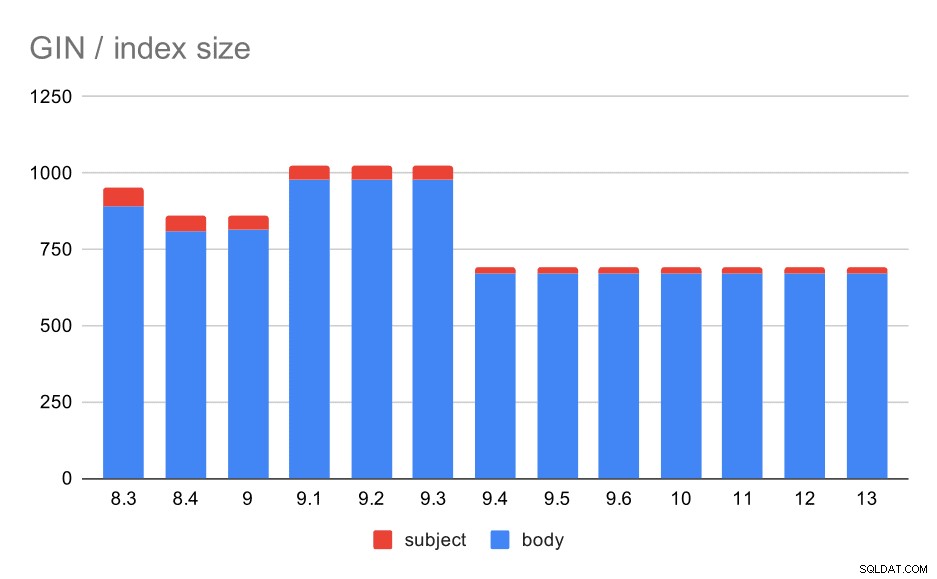
Rozmiar indeksów GIN w temacie/treści wiadomości. Wartości są w megabajtach.
W poniższej tabeli przedstawiono rozmiary indeksów GIN w treści i temacie wiadomości. Wartości są w megabajtach.
| BODY | TEMAT | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9,5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
W tym przypadku myślę, że możemy bezpiecznie założyć, że to przyspieszenie jest związane z tym elementem w informacjach o wydaniu 9.4:
- Zmniejsz wielkość indeksu WZ (Alexander Korotkov, Heikki Linnakangas)
Zmienność wielkości między 8,3 a 9,1 wydaje się wynikać ze zmian w lematyzacji (w jaki sposób słowa są przekształcane do formy „podstawowej”). Oprócz różnic w wielkości, zapytania w tych wersjach zwracają na przykład nieco inną liczbę wyników.
WZ / zapytania
Teraz główna część tego benchmarku – wydajność zapytań. Wszystkie przedstawione tutaj liczby dotyczą jednego klienta – o skalowalności klienta już mówiliśmy w części związanej z wydajnością OLTP, ustalenia dotyczą również tych zapytań. (Ponadto, ta konkretna maszyna ma tylko 4 rdzenie, więc i tak nie zaszlibyśmy zbyt daleko, jeśli chodzi o testowanie skalowalności).
SELECT id, temat FROM wiadomości WHERE tsvector @@ $1
Najpierw zapytanie wyszukujące wszystkie pasujące dokumenty. W przypadku wyszukiwań w kolumnie „temat” możemy wykonać około 800 zapytań na sekundę (i faktycznie trochę spada w 9,1), ale w 9,4 nagle wystrzeliwuje do 3000 zapytań na sekundę. W przypadku kolumny „body” jest to w zasadzie ta sama historia – początkowo 160 zapytań, spadek do ~90 zapytań w 9.1, a następnie wzrost do 300 w 9.4.
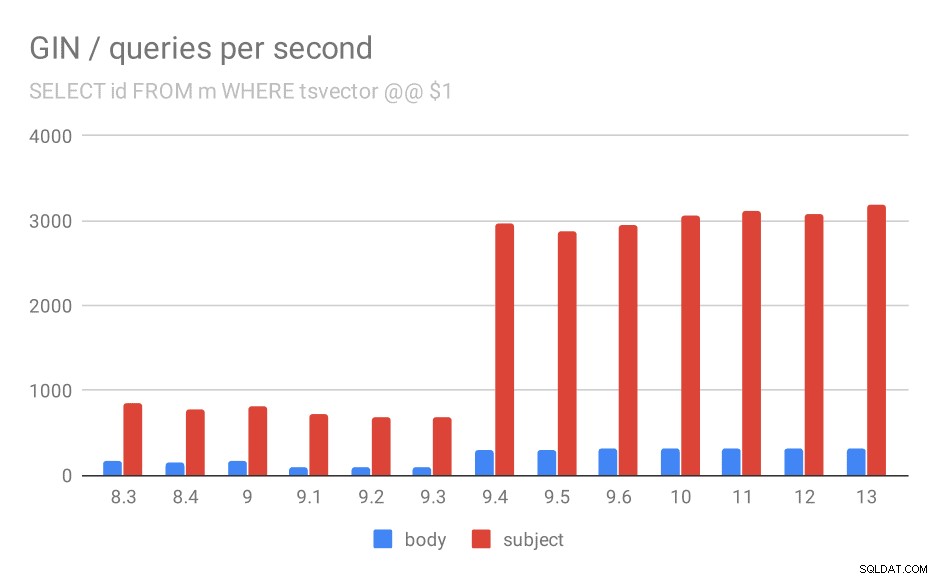
Liczba zapytań na sekundę dla pierwszego zapytania (pobieranie wszystkich pasujących wierszy).
I znowu dane źródłowe – liczby to przepustowość (zapytania na sekundę).
| BODY | TEMAT | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9,5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Myślę, że możemy spokojnie założyć, że ulepszenie w wersji 9.4 jest związane z tym elementem w informacjach o wydaniu:
- Poprawa szybkość wyszukiwania GIN za pomocą wielu kluczy (Alexander Korotkov, Heikki Linnakangas)
Tak więc kolejne ulepszenie GIN w wersji 9.4 od tych samych dwóch programistów – wyraźnie Alexander i Heikki wykonali dużo dobrej pracy nad indeksami GIN w wersji 9.4 😉
SELECT id, temat FROM wiadomości WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
W przypadku zapytania klasyfikującego wyniki według trafności za pomocą ts_rank i LIMIT, ogólne zachowanie jest prawie takie samo, myślę, że nie ma potrzeby szczegółowego opisywania wykresu.
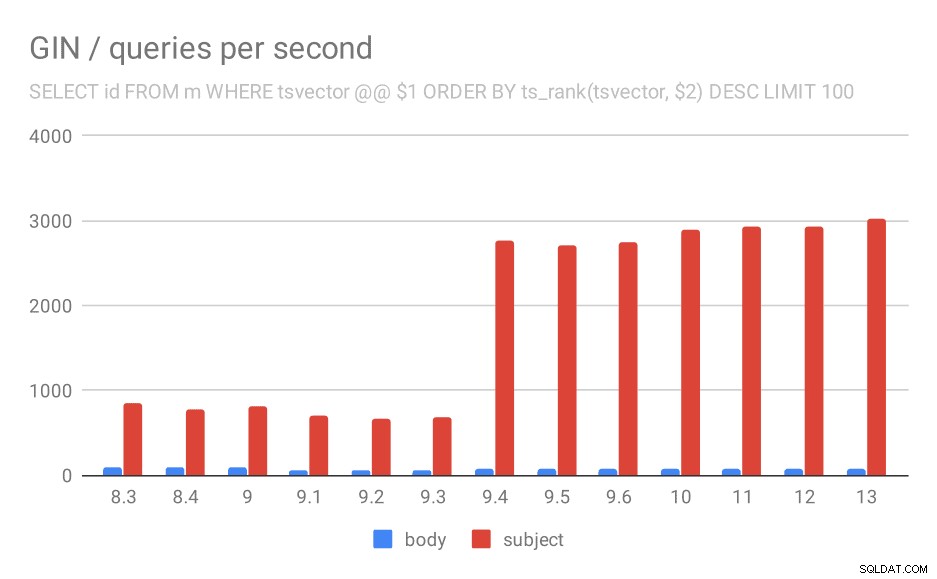
Liczba zapytań na sekundę dla drugiego zapytania (pobieranie najbardziej odpowiednich wierszy).
| BODY | TEMAT | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9,5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Jest jednak jedno pytanie – dlaczego wydajność spadła między 9,0 a 9,1? Wydaje się, że nastąpił dość znaczny spadek przepustowości – o około 50% w przypadku wyszukiwania treści i 20% w przypadku wyszukiwania tematów wiadomości. Nie mam jasnego wyjaśnienia, co się stało, ale mam dwie obserwacje…
Po pierwsze, zmienił się rozmiar indeksu – jeśli spojrzysz na pierwszy wykres „GIN / rozmiar indeksu” i tabelę, zobaczysz, że indeks treści wiadomości wzrósł z 813 MB do około 977 MB. To znaczny wzrost i może wyjaśniać część spowolnienia. Problem polega jednak na tym, że indeks tematów w ogóle nie wzrósł, ale zapytania również stawały się wolniejsze.
Po drugie, możemy sprawdzić, ile wyników zwróciły zapytania. Zindeksowany zestaw danych jest dokładnie taki sam, więc wydaje się rozsądne oczekiwanie takiej samej liczby wyników we wszystkich wersjach PostgreSQL, prawda? W praktyce wygląda to tak:
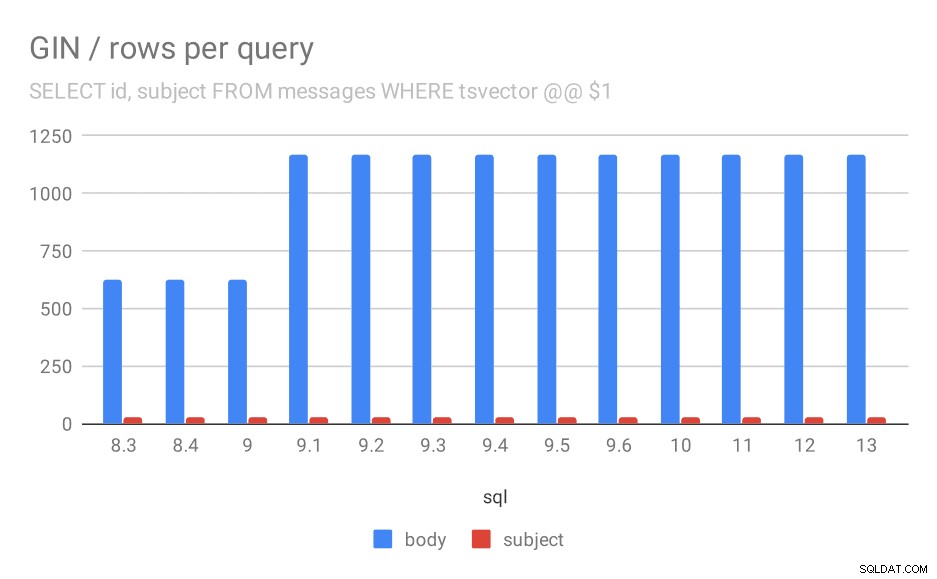
Średnia liczba wierszy zwróconych dla zapytania.
| BODY | TEMAT | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9,5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Najwyraźniej w wersji 9.1 średnia liczba wyników wyszukiwania w treści wiadomości nagle się podwaja, co jest prawie idealnie proporcjonalne do spowolnienia. Jednak liczba wyników wyszukiwania tematów pozostaje taka sama. Nie mam na to zbyt dobrego wytłumaczenia, poza tym, że indeksowanie zmieniło się w sposób, który pozwala na dopasowanie większej liczby wiadomości, ale spowalnia je. Jeśli masz lepsze wyjaśnienia, chciałbym je usłyszeć!
GiST / ładowanie danych
Teraz inny rodzaj indeksów pełnotekstowych – GiST. Wskaźniki te są stratne, tzn. wymagają ponownego sprawdzenia wyników przy użyciu wartości z tabeli. Możemy więc spodziewać się niższej przepustowości w porównaniu z indeksami GIN, ale poza tym rozsądne jest oczekiwanie mniej więcej tego samego wzorca.
Czasy ładowania rzeczywiście prawie idealnie pasują do GIN – czasy tworzenia indeksu są różne, ale ogólny wzór jest taki sam. Przyspieszenie w 9.1, małe spowolnienie w 11.
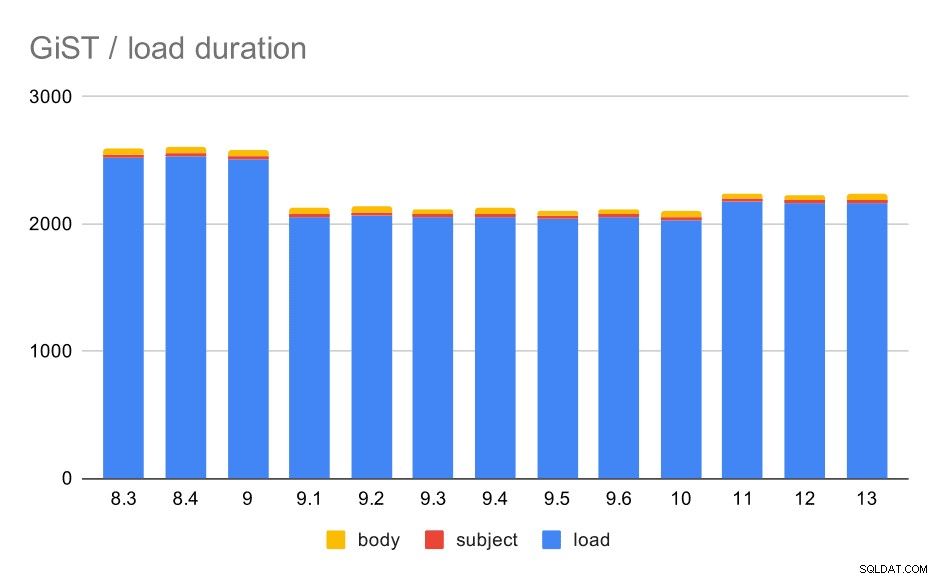
Operacje ładowania danych z tabelą i indeksami GiST.
| ZAŁADUJ | TEMAT | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9,5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Jednak wielkość indeksu pozostała prawie stała – nie było poprawy GiST podobnej do GIN w 9.4, co zmniejszyło wielkość o ~30%. W wersji 9.1 nastąpił wzrost, co jest kolejnym znakiem, że indeksowanie pełnotekstowe zmieniło się w tej wersji, aby indeksować więcej słów.
Jest to dodatkowo wspierane przez średnią liczbę wyników, przy czym GiST jest dokładnie taki sam jak w przypadku GIN (ze wzrostem o 9,1).
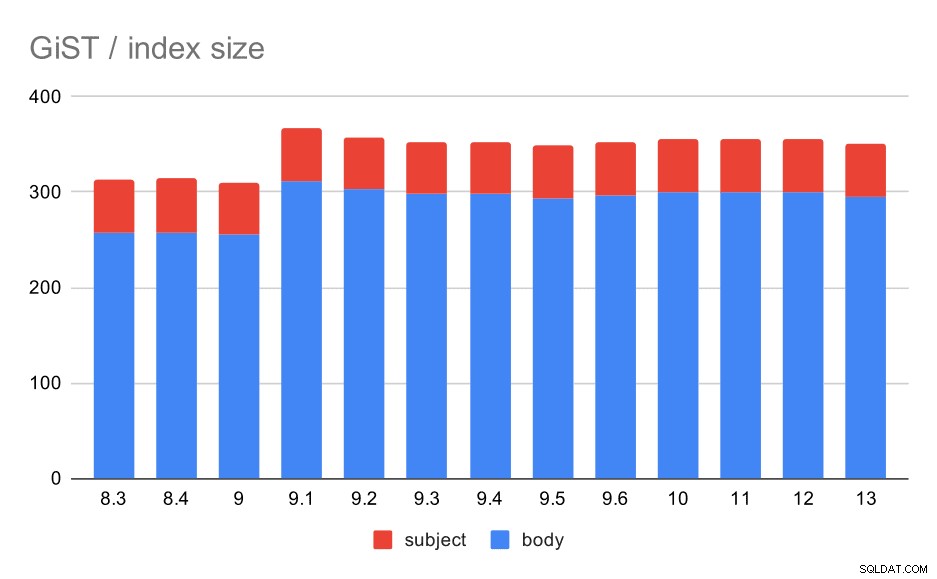
Rozmiar indeksów GiST w temacie/treści wiadomości. Wartości są w megabajtach.
| BODY | TEMAT | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
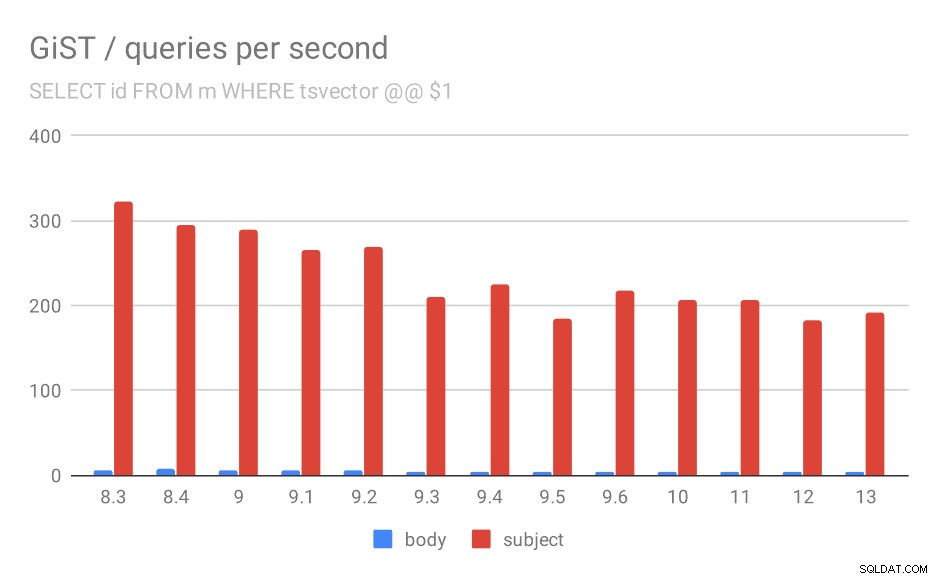
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
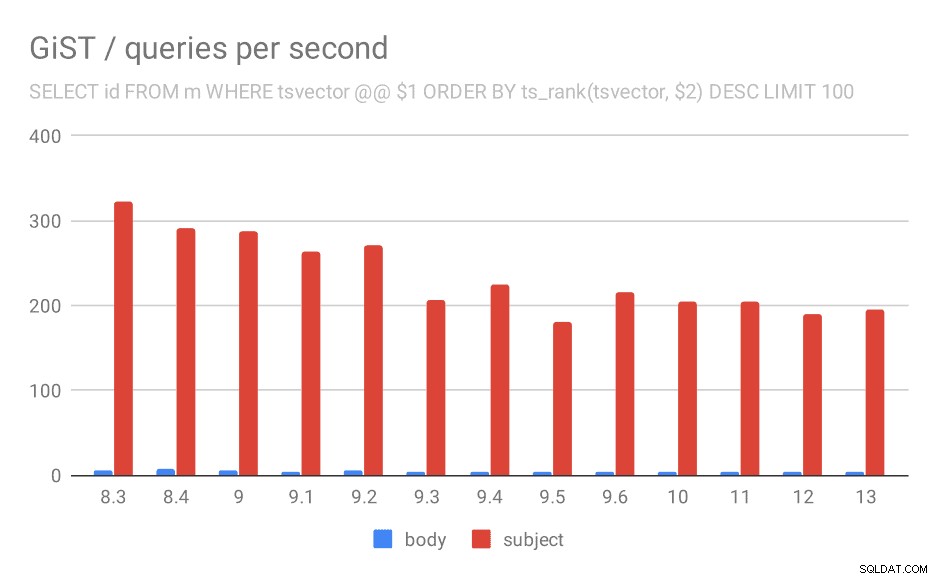
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).