Próżnia jest jedną z najważniejszych funkcji odzyskiwania usuniętych krotek w tabelach i indeksach. Bez próżni tabele i indeksy rosłyby bez ograniczeń. Ten wpis na blogu opisuje opcję RÓWNOLEGŁY dla polecenia VACUUM, która została niedawno wprowadzona do PostgreSQL13.
Fazy przetwarzania próżniowego
Przed szczegółowym omówieniem nowej opcji przejrzyjmy szczegóły działania próżni.
Próżnia (bez opcji FULL) składa się z pięciu faz. Na przykład dla tabeli z dwoma indeksami działa to następująco:
- Faza skanowania stosu
- Przeskanuj tabelę od góry i zbierz w pamięci krotki śmieci.
- Wskaźnik fazy próżni
- Odkurzaj oba indeksy jeden po drugim.
- Faza podciśnienia hałdy
- Odkurz stos (stół).
- Faza czyszczenia indeksu
- Wyczyść oba indeksy jeden po drugim.
- Faza obcinania stosu
- Obetnij puste strony na końcu tabeli.
W fazie skanowania sterty próżnia może użyć mapy widoczności, aby pominąć przetwarzanie stron, o których wiadomo, że nie zawierają żadnych śmieci, podczas gdy zarówno w fazie próżni indeksu, jak i fazie czyszczenia indeksu, w zależności od metod dostępu do indeksu, skanowanie całego indeksu jest wymagane.
Na przykład indeksy btree, najpopularniejszy typ indeksu, wymagają skanowania całego indeksu w celu usunięcia krotek śmieci i oczyszczenia indeksu. Ponieważ próżnia jest zawsze wykonywana w jednym procesie, indeksy są przetwarzane jeden po drugim. Dłuższy czas wykonywania próżni na szczególnie dużym stole często irytuje użytkowników.
Opcja RÓWNOLEGŁA
Aby rozwiązać ten problem, zaproponowałem łatkę, która zrównoleglała próżnię w 2016 roku. Po długim procesie recenzowania i wielu reformach, w PostgreSQL 13 wprowadzono opcję RÓWNOLEGŁOŚĆ. Dzięki tej opcji próżnia może wykonać fazę podciśnienia indeksu i fazę czyszczenia indeksu za pomocą pracowników równoległych. Równolegle pracownicy próżni są uruchamiani przed wejściem do fazy indeksowania próżni lub fazy czyszczenia indeksu i wychodzą na końcu fazy. Pracownik indywidualny jest przypisany do indeksu. Odkurzanie równoległe jest zawsze wyłączone w trybie automatycznego odkurzania.
Opcja RÓWNOLEGŁY bez argumentu liczby całkowitej automatycznie obliczy stopień równoległy na podstawie liczby indeksów w tabeli.
VACUUM (PARALLEL) tbl;
Ponieważ proces lider zawsze przetwarza jeden indeks, maksymalna liczba pracowników równoległych będzie wynosić (liczba indeksów w tabeli – 1), która jest dodatkowo ograniczona do max_parallel_maintenance_workers. Indeks docelowy musi być większy lub równy min_parallel_index_scan_size.
Opcja RÓWNOLEGŁY pozwala nam określić stopień równoległy przez przekazanie niezerowej wartości całkowitej. Poniższy przykład wykorzystuje trzech pracowników, w sumie cztery procesy równolegle.
VACUUM (PARALLEL 3) tbl;
Opcja RÓWNOLEGŁY jest domyślnie włączona; aby wyłączyć równoległą próżnię, ustaw max_parallel_maintenance_workers na 0 lub określ PARALLEL 0 .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Patrząc na wynik VACUUM VERBOSE, widzimy, że pracownik przetwarza indeks.
Informacje wydrukowane jako „przez pracownika równoległego” są zgłaszane przez pracownika.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Metody dostępu do indeksu a stopień równoległości
Próżnia nie zawsze musi wykonywać równolegle fazę podciśnienia indeksu i fazę czyszczenia indeksu. Jeśli rozmiar indeksu jest mały lub jeśli wiadomo, że proces można zakończyć szybko, koszt uruchomienia i zarządzania równoległymi procesami roboczymi dla równoległości powoduje zamiast tego koszty. W zależności od metod dostępu do indeksu i jego rozmiaru, lepiej nie wykonywać tych faz w równoległym procesie roboczym próżni.
Na przykład podczas odkurzania odpowiednio dużego indeksu btree, faza indeksowania próżni indeksu może być wykonywana przez równoległego pracownika próżni, ponieważ zawsze wymaga to skanowania całego indeksu, podczas gdy faza czyszczenia indeksu jest wykonywana przez równoległego pracownika próżni, jeśli indeks próżnia nie jest wykonywana (np. na stole nie ma śmieci). Dzieje się tak, ponieważ indeksy btree wymagają w fazie czyszczenia indeksu gromadzenia statystyk indeksu, które są również gromadzone podczas fazy podciśnienia indeksu. Z drugiej strony, indeksy haszujące zawsze nie wymagają skanowania indeksu w fazie czyszczenia indeksu.
Aby obsługiwać różne typy strategii podciśnienia indeksu, twórcy metod dostępu do indeksu mogą określić te zachowania, ustawiając flagi na amparallelvacuumoptions pole IndexAmRoutine Struktura. Dostępne flagi są następujące:
- VACUUM_OPTION_NO_PARALLEL (domyślnie)
- podciśnienie równoległe jest wyłączone w obu fazach.
- VACUUM_OPTION_PARALLEL_BULKDEL
- faza podciśnienia indeksu może być wykonywana równolegle.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- Faza czyszczenia indeksu może być wykonywana równolegle, jeśli faza podciśnienia indeksu nie została jeszcze wykonana.
- VACUUM_OPTION_PARALLEL_CLEANUP
- Faza czyszczenia indeksu może być wykonywana równolegle, nawet jeśli faza podciśnienia indeksu już przetworzyła indeks.
Poniższa tabela pokazuje, w jaki sposób indeks AMs wbudowany w PostgreSQL obsługuje równoległą próżnię.
| nbtree | hasz | gin | gist | spgist | brin | rozkwit | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Zobacz „src/include/command/vacuum.h”, aby uzyskać więcej informacji.
Weryfikacja wydajności
Oceniłem wydajność równoległej próżni na moim laptopie (Core i7 2,6 GHz, 16 GB RAM, 512 GB SSD). Rozmiar tabeli wynosi 6 GB i ma osiem indeksów 3 GB. Całkowita relacja wynosi 30 GB, co nie mieści się w pamięci RAM maszyny. Do każdej oceny zrobiłem kilka procent stołu zabrudzonego równomiernie po odkurzaniu, następnie wykonałem odkurzanie zmieniając jednocześnie stopień. Poniższy wykres pokazuje czas wykonania próżni.
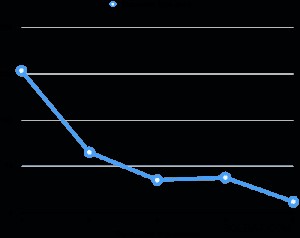
We wszystkich ocenach czas wykonania próżni indeksu stanowił ponad 95% całkowitego czasu wykonania. Dlatego zrównoleglenie fazy wskaźnika próżni pomogło znacznie skrócić czas wykonywania próżni.
Dzięki
Specjalne podziękowania dla Amita Kapili za oddanie recenzji, udzielanie porad i wprowadzanie tej funkcji w PostgreSQL 13. Doceniam wszystkich programistów zaangażowanych w tę funkcję za recenzowanie, testowanie i dyskusję.



