Opublikowałem wiele benchmarków porównujących różne wersje PostgreSQL, jak na przykład wykład archeologii wydajności (oceniający PostgreSQL 7.4 do 9.4), a wszystkie te benchmarki zakładały stałe środowisko (sprzęt, jądro,…). Co jest w porządku w wielu przypadkach (np. podczas oceny wpływu poprawki na wydajność), ale w produkcji te rzeczy zmieniają się w czasie – dostajesz aktualizacje sprzętu i od czasu do czasu otrzymujesz aktualizację z nową wersją jądra.
W przypadku aktualizacji sprzętu (lepsza pamięć masowa, więcej pamięci RAM, szybsze procesory itp.) wpływ jest zwykle dość łatwy do przewidzenia, a ponadto ludzie na ogół zdają sobie sprawę, że muszą ocenić wpływ, analizując wąskie gardła w produkcji, a być może nawet najpierw przetestować nowy sprzęt .
Ale co z aktualizacjami jądra? Niestety zazwyczaj nie robimy zbyt wiele benchmarkingu w tym obszarze. Zakłada się głównie, że nowe jądra są lepsze od starszych (szybsze, wydajniejsze, skalowalne do większej liczby rdzeni procesora). Ale czy to naprawdę prawda? A jak duża jest różnica? Na przykład, co się stanie, jeśli zaktualizujesz jądro z wersji 3.0 do 4.7 – czy wpłynie to na wydajność, a jeśli tak, czy wydajność poprawi się, czy nie?
Od czasu do czasu otrzymujemy raporty o poważnych regresjach z konkretną wersją jądra lub nagłych polepszeniach między wersjami jądra. Jasne jest więc, że wersje jądra mogą wpływać na wydajność.
Znam pojedynczy benchmark PostgreSQL porównujący różne wersje jądra, wykonany w 2014 roku przez Sergeya Konopleva w odpowiedzi na zalecenia unikania jąder 3.0 – 3.8. Ale ten benchmark jest dość stary (ostatnią wersją jądra dostępną około 18 miesięcy temu była 3.13, podczas gdy obecnie mamy 3.19 i 4.6), więc zdecydowałem się uruchomić kilka testów z obecnymi jądrami (i PostgreSQL 9.6beta1).
PostgreSQL a wersje jądra
Najpierw jednak omówię kilka istotnych różnic między politykami regulującymi zobowiązania w tych dwóch projektach. W PostgreSQL mamy koncepcję wersji głównych i pomocniczych – wersje główne (np. 9.5) są wypuszczane mniej więcej raz w roku i zawierają różne nowe funkcje. Drobne wersje (np. 9.5.2) zawierają jedynie poprawki błędów i są wydawane mniej więcej co trzy miesiące (lub częściej, gdy zostanie wykryty poważny błąd). Dlatego nie powinno być żadnych większych zmian wydajności ani zachowania między wersjami pomocniczymi, co sprawia, że wdrażanie wersji pomocniczych jest dość bezpieczne bez obszernych testów.
W przypadku wersji jądra sytuacja jest znacznie mniej jasna. Jądro Linuksa ma również gałęzie (np. 2.6, 3.0 lub 4.7), które w żadnym wypadku nie są równe „głównym wersjom” PostgreSQL, ponieważ nadal otrzymują nowe funkcje, a nie tylko poprawki błędów. Nie twierdzę, że polityka wersjonowania PostgreSQL jest w jakiś sposób automatycznie lepsza, ale konsekwencją jest to, że aktualizacja między mniejszymi wersjami jądra może łatwo znacząco wpłynąć na wydajność, a nawet wprowadzić błędy (np. 3.18.37 ma problemy z OOM z powodu takiej niepoprawki zatwierdź).
Oczywiście dystrybucje zdają sobie sprawę z tego ryzyka i często blokują wersję jądra i przeprowadzają dalsze testy w celu usunięcia nowych błędów. Ten post używa jednak długoterminowych jąder waniliowych, dostępnych na www.kernel.org.
Wzorzec
Benchmarków, z których możemy skorzystać, jest wiele – ten post przedstawia zestaw testów pgbench, czyli dość prosty benchmark OLTP (podobny do TPC-B). Planuję przeprowadzić dodatkowe testy z innymi typami benchmarków (zwłaszcza zorientowanych na DWH/DSS) i przedstawię je na tym blogu w przyszłości.
Wracając do pgbench – kiedy mówię „zbiór testów”, mam na myśli kombinacje
- tylko do odczytu a do odczytu i zapisu
- rozmiar zestawu danych – aktywny zestaw (nie) mieści się we wspólnych buforach / RAM
- liczba klientów – pojedynczy klient kontra wielu klientów (blokowanie/planowanie)
Wartości oczywiście zależą od używanego sprzętu, więc zobaczmy, na jakim sprzęcie działała ta runda testów porównawczych:
- Procesor:Intel i5-2500k @ 3,3 GHz (3,7 GHz turbo)
- RAM:8 GB (DDR3 @ 1333 MHz)
- Pamięć:6x Intel SSD DC S3700 w RAID-10 (system Linux raid)
- system plików:ext4 z domyślnym harmonogramem we/wy (cfq)
Jest to więc ta sama maszyna, której używałem w wielu poprzednich testach – dość mała maszyna, niezupełnie najnowszy procesor itp., ale uważam, że to nadal rozsądny „mały” system.
Parametry testu porównawczego to:
- Skale zestawu danych:30, 300 i 1500 (czyli około 450 MB, 4,5 GB i 22,5 GB)
- liczba klientów:1, 4, 16 (maszyna ma 4 rdzenie)
Dla każdej kombinacji były 3 przebiegi tylko do odczytu (po 15 minut) i 3 przebiegi odczytu i zapisu (po 30 minut). Rzeczywisty skrypt sterujący testem porównawczym jest dostępny tutaj (wraz z wynikami i innymi przydatnymi danymi).
Uwaga :Jeśli masz znacząco inny sprzęt (np. napędy obrotowe), możesz zobaczyć bardzo różne wyniki. Jeśli masz system, który chciałbyś przetestować, daj mi znać, a pomogę Ci w tym (zakładając, że będę mógł opublikować wyniki).
Wersje jądra
Jeśli chodzi o wersje jądra, testowałem najnowsze wersje we wszystkich gałęziach długoterminowych od 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 i 4.7). Nadal istnieje wiele systemów działających na jądrach 2.6.x, więc warto wiedzieć, ile wydajności można zyskać (lub stracić) po aktualizacji do nowszego jądra. Ale kompilowałem wszystkie jądra samodzielnie (tj. Używając jąder waniliowych, bez łatek specyficznych dla dystrybucji), a pliki konfiguracyjne znajdują się w repozytorium git.
Wyniki
Jak zwykle wszystkie dane są dostępne na Bitbucket, w tym
- plik .config jądra
- skrypt porównawczy (run-pgbench.sh)
- Konfiguracja PostgreSQL (z podstawowym dostrojeniem sprzętu)
- Dzienniki PostgreSQL
- różne logi systemowe (dmesg, sysctl, mount, …)
Poniższe wykresy pokazują średnie tps dla każdego testu porównawczego – wyniki dla trzech przebiegów są dość spójne, z ~2% różnicą między min i max w większości przypadków.
tylko do odczytu
W przypadku najmniejszego zestawu danych występuje wyraźny spadek wydajności między 3,4 a 3,10 dla wszystkich klientów. Wyniki dla 16 klientów (4x liczba rdzeni), jednak więcej niż odzyskuje w 3.12.
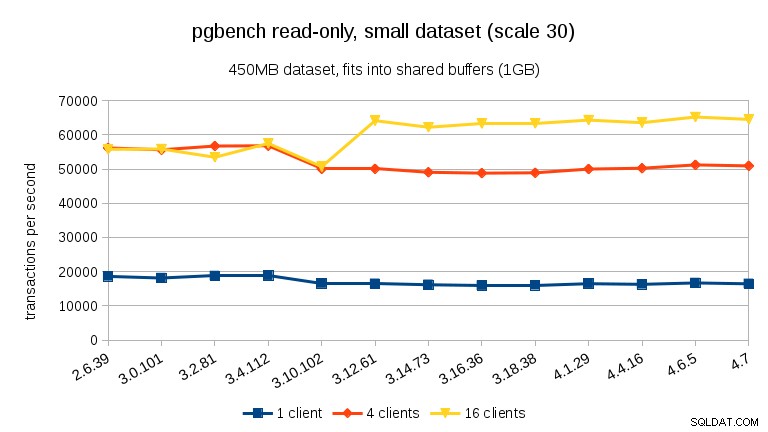
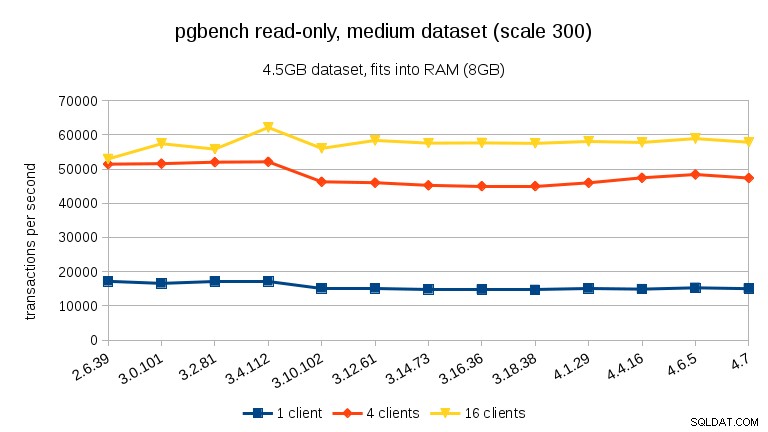
W przypadku średniego zestawu danych (pasuje do pamięci RAM, ale nie do współdzielonych buforów), widzimy ten sam spadek między 3.4 a 3.10, ale nie odzyskiwanie w 3.12.
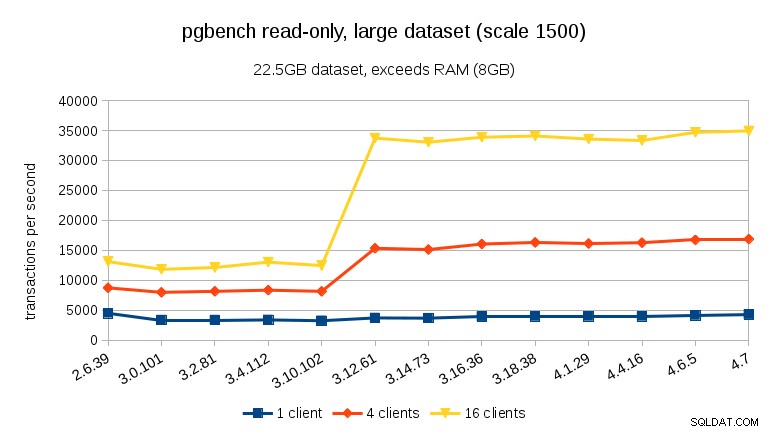
W przypadku dużych zestawów danych (przekraczających pamięć RAM, tak mocno powiązane z I/O) wyniki są bardzo różne – nie jestem pewien, co się stało między 3.10 a 3.12, ale poprawa wydajności (szczególnie w przypadku większej liczby klientów) jest dość zaskakująca.
odczyt-zapis
W przypadku obciążenia odczytu i zapisu wyniki są dość podobne. W przypadku małych i średnich zestawów danych możemy zaobserwować ten sam ~10% spadek między 3.4 a 3.10, ale niestety brak poprawy w 3.12.
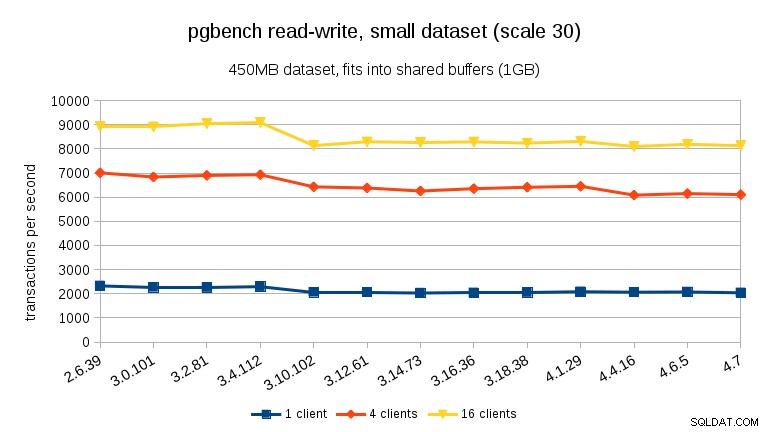
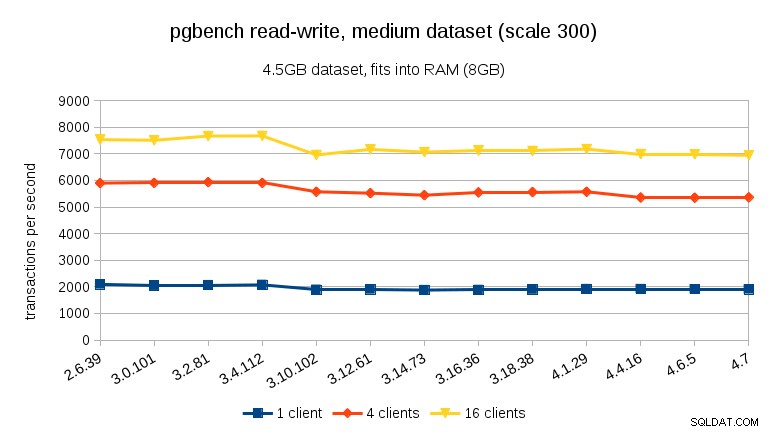
W przypadku dużego zestawu danych (ponownie, znacznie ograniczonego we/wy) możemy zauważyć podobną poprawę w wersji 3.12 (nie tak znaczącą, jak w przypadku obciążenia tylko do odczytu, ale nadal znaczące):
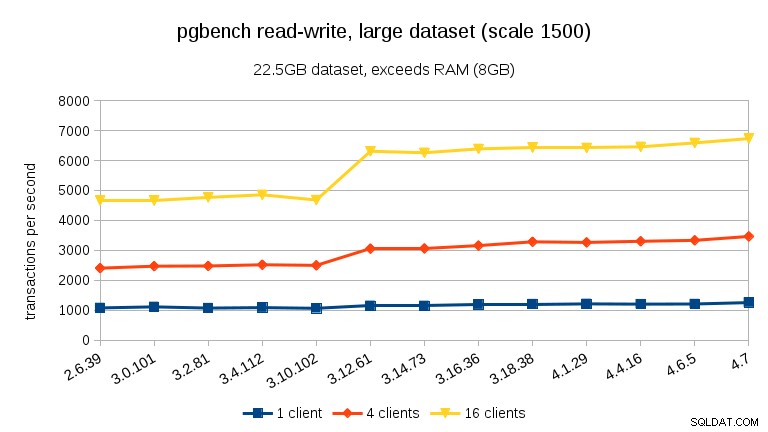
Podsumowanie
Nie odważę się wyciągać wniosków z jednego testu porównawczego na jednej maszynie, ale myślę, że można bezpiecznie powiedzieć:
- Ogólna wydajność jest dość stabilna, ale możemy zauważyć pewne znaczące zmiany wydajności (w obu kierunkach).
- W przypadku zestawów danych, które mieszczą się w pamięci (albo w shared_buffers, albo przynajmniej w pamięci RAM), widzimy wymierny spadek wydajności między 3.4 a 3.10. W teście tylko do odczytu to częściowo przywraca się w wersji 3.12 (ale tylko dla wielu klientów).
- Zestawy danych przekraczające pamięć, a więc przede wszystkim związane z we/wy, nie widzimy takich spadków wydajności, ale zamiast tego znaczną poprawę w wersji 3.12.
Co do powodów, dla których następują te nagłe zmiany, nie jestem do końca pewien. Istnieje wiele potencjalnie istotnych zatwierdzeń między wersjami, ale nie jestem pewien, jak zidentyfikować właściwą bez obszernych (i czasochłonnych) testów. Jeśli masz inne pomysły (np. jesteś świadomy takich zatwierdzeń), daj mi znać.