Zacząłem pisać o narzędziu (pglupgrade), które opracowałem do wykonywania automatycznych aktualizacji klastrów PostgreSQL z niemal zerowym czasem przestoju. W tym poście opowiem o narzędziu i omówię szczegóły dotyczące jego projektu.
Pierwszą część tej serii możesz sprawdzić tutaj:Zautomatyzowane aktualizacje klastrów PostgreSQL w chmurze z niemal zerowym czasem przestoju (część I).

Narzędzie jest napisane w Ansible. Mam wcześniejsze doświadczenie w pracy z Ansible i obecnie pracuję z nim również w 2. ćwiartce, dlatego była to dla mnie wygodna opcja. Mając to na uwadze, możesz zaimplementować logikę aktualizacji minimalnego przestoju, która zostanie wyjaśniona w dalszej części tego postu, za pomocą swojego ulubionego narzędzia do automatyzacji.
Dalsza lektura:posty na blogu Ansible Loves PostgreSQL , PostgreSQL Planet w Ansible Galaxy i prezentacja Zarządzanie PostgreSQL za pomocą Ansible.
Poradnik Pglupgrade
W Ansible poradniki to główne skrypty opracowane w celu automatyzacji procesów, takich jak udostępnianie instancji w chmurze i aktualizowanie klastrów baz danych. Poradniki mogą zawierać jedną lub więcej odtworzeń . Poradniki mogą również zawierać zmienne , role i programy obsługi jeśli zdefiniowano.
Narzędzie składa się z dwóch głównych podręczników. Pierwszy poradnik to provision.yml który automatyzuje proces tworzenia maszyn z systemem Linux w chmurze, zgodnie ze specyfikacjami (Jest to opcjonalny poradnik napisany wyłącznie w celu udostępniania instancji w chmurze i niezwiązany bezpośrednio z aktualizacją ). Drugi (i główny) podręcznik to pglupgrade.yml który automatyzuje proces aktualizacji klastrów baz danych.
Poradnik Pglupgrade zawiera osiem odtworzeń, które zaaranżują ulepszenie. Do każdego odtworzenia użyj jednego pliku konfiguracyjnego (config.yml ), wykonaj niektóre zadania na hostach lub grupach hostów, które są zdefiniowane w pliku spisu hosta (host.ini ).
Plik zasobów
Plik inwentarzowy informuje Ansible, z którymi serwerami musi się połączyć za pomocą SSH, jakich informacji o połączeniu wymaga i opcjonalnie, które zmienne są skojarzone z tymi serwerami. Poniżej znajduje się przykładowy plik inwentaryzacji, który został wykorzystany do wykonania automatycznych aktualizacji klastra dla jednego ze studiów przypadku zaprojektowanych dla narzędzia. Omówimy te studia przypadków w nadchodzących postach z tej serii.
[old-primary] 54.171.211.188 [new-primary] 54.246.183.100 [old-standbys] 54.77.249.81 54.154.49.180 [new-standbys:children] old-standbys [pgbouncer] 54.154.49.180
Plik zasobów (host.ini )
Przykładowy plik inwentarza zawiera pięć hostów poniżej pięciu grup hostów zawierające old-primary , new-primary , old-standbys , new-standbys i pgbouncer . Serwer może należeć do więcej niż jednej grupy. Na przykład old-standbys to grupa zawierająca new-standbys grupa, co oznacza hosty zdefiniowane w old-standbys grupa (54.77.249.81 i 54.154.49.180) również należy do new-standbys Grupa. Innymi słowy, new-standbys grupa jest dziedziczona z (dzieci) old-standbys Grupa. Osiąga się to za pomocą specjalnego :children przyrostek.
Gdy plik ekwipunku będzie gotowy, Ansible playbook można uruchomić za pomocą ansible-playbook poleceniem, wskazując na plik ekwipunku (jeśli plik ekwipunku nie znajduje się w domyślnej lokalizacji, w przeciwnym razie użyje domyślnego pliku ekwipunku), jak pokazano poniżej:
$ ansible-playbook -i hosts.ini pglupgrade.yml
Prowadzenie poradnika Ansible
Plik konfiguracyjny
Playbook Pglupgrade używa pliku konfiguracyjnego (config.yml ), który pozwala użytkownikom określić wartości logicznych zmiennych aktualizacji.
Jak pokazano poniżej, config.yml przechowuje głównie zmienne specyficzne dla PostgreSQL, które są wymagane do skonfigurowania klastra PostgreSQL, takie jak postgres_old_datadir i postgres_new_datadir do przechowywania ścieżki do katalogu danych PostgreSQL dla starej i nowej wersji PostgreSQL; postgres_new_confdir do przechowywania ścieżki do katalogu konfiguracyjnego PostgreSQL dla nowej wersji PostgreSQL; postgres_old_dsn i postgres_new_dsn do przechowywania ciągu połączenia dla pglupgrade_user aby móc połączyć się z pglupgrade_database nowych i starych serwerów głównych. Sam ciąg połączenia składa się z konfigurowalnych zmiennych, dzięki czemu użytkownik (pglupgrade_user ) i bazę danych (pglupgrade_database ) informacje można zmienić dla różnych przypadków użycia.
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main" Plik konfiguracyjny (config.yml )
Jako kluczowy krok dla każdej aktualizacji, informacje o wersji PostgreSQL mogą być określone dla bieżącej wersji (postgres_old_version ) oraz wersję, która zostanie zaktualizowana do (postgres_new_version ). W przeciwieństwie do replikacji fizycznej, w której replikacja jest kopią systemu na poziomie bajtów/bloków, replikacja logiczna umożliwia replikację selektywną gdzie replikacja może kopiować dane logiczne, w tym określone bazy danych i tabele w tych bazach. Z tego powodu config.yml umożliwia skonfigurowanie bazy danych do replikacji przez pglupgrade_database zmienny. Ponadto użytkownik replikacji logicznej musi mieć uprawnienia do replikacji, dlatego pglupgrade_user zmienna powinna być określona w pliku konfiguracyjnym. Istnieją inne zmienne, które są związane z działającymi wewnętrznymi elementami pglogical, takimi jak subscription_name i replication_set które są używane w roli pglogicznej.
Projekt wysokiej dostępności narzędzia Pglupgrade
Narzędzie Pglupgrade zostało zaprojektowane tak, aby zapewnić użytkownikowi elastyczność pod względem właściwości wysokiej dostępności (HA) dla różnych wymagań systemowych. initial_standbys zmienna (zobacz config.yml ) jest kluczem do wyznaczania właściwości HA klastra podczas operacji aktualizacji.
Na przykład, jeśli initial_standbys jest ustawiona na 1 (może być ustawiona na dowolną liczbę, na którą pozwala pojemność klastra), oznacza to, że w uaktualnionym klastrze wraz z masterem zostanie utworzony 1 tryb gotowości przed rozpoczęciem replikacji. Innymi słowy, jeśli masz 4 serwery i ustawisz wartość Initial_standbys na 1, będziesz mieć 1 serwer główny i 1 serwer rezerwowy w zaktualizowanej nowej wersji, a także 1 serwer główny i 1 serwer rezerwowy w starej wersji.
Ta opcja pozwala na ponowne wykorzystanie istniejących serwerów podczas trwania aktualizacji. W przykładzie 4 serwerów, stare serwery podstawowe i rezerwowe mogą zostać odbudowane jako 2 nowe serwery rezerwowe po zakończeniu replikacji.
Gdy initial_standbys zmienna jest ustawiona na 0, w nowym klastrze nie zostaną utworzone żadne początkowe serwery w trybie gotowości przed rozpoczęciem replikacji.
Jeśli initial_standbys konfiguracja brzmi niejasno, nie martw się. Zostanie to wyjaśnione lepiej w następnym poście na blogu, kiedy będziemy omawiać dwa różne studia przypadków.
Wreszcie plik konfiguracyjny umożliwia określenie starych i nowych grup serwerów. Można to zapewnić na dwa sposoby. Po pierwsze, jeśli istnieje klaster, adresy IP serwerów (mogą to być serwery bare-metal lub serwery wirtualne ) należy wpisać w hosts.ini pliku, biorąc pod uwagę żądane właściwości HA podczas operacji aktualizacji.
Drugim sposobem jest uruchomienie provision.yml playbook (w ten sposób udostępniłem instancje w chmurze, ale możesz użyć własnych skryptów aprowizacji lub ręcznie aprowizować instancje ), aby udostępnić puste serwery Linux w chmurze (instancje AWS EC2) i pobrać adresy IP serwerów do hosts.ini plik. Tak czy inaczej, config.yml uzyska informacje o hoście przez hosts.ini plik.
Przepływ pracy procesu aktualizacji
Po wyjaśnieniu pliku konfiguracyjnego (config.yml ), który jest używany przez pglupgrade playbook, możemy wyjaśnić przebieg procesu aktualizacji.
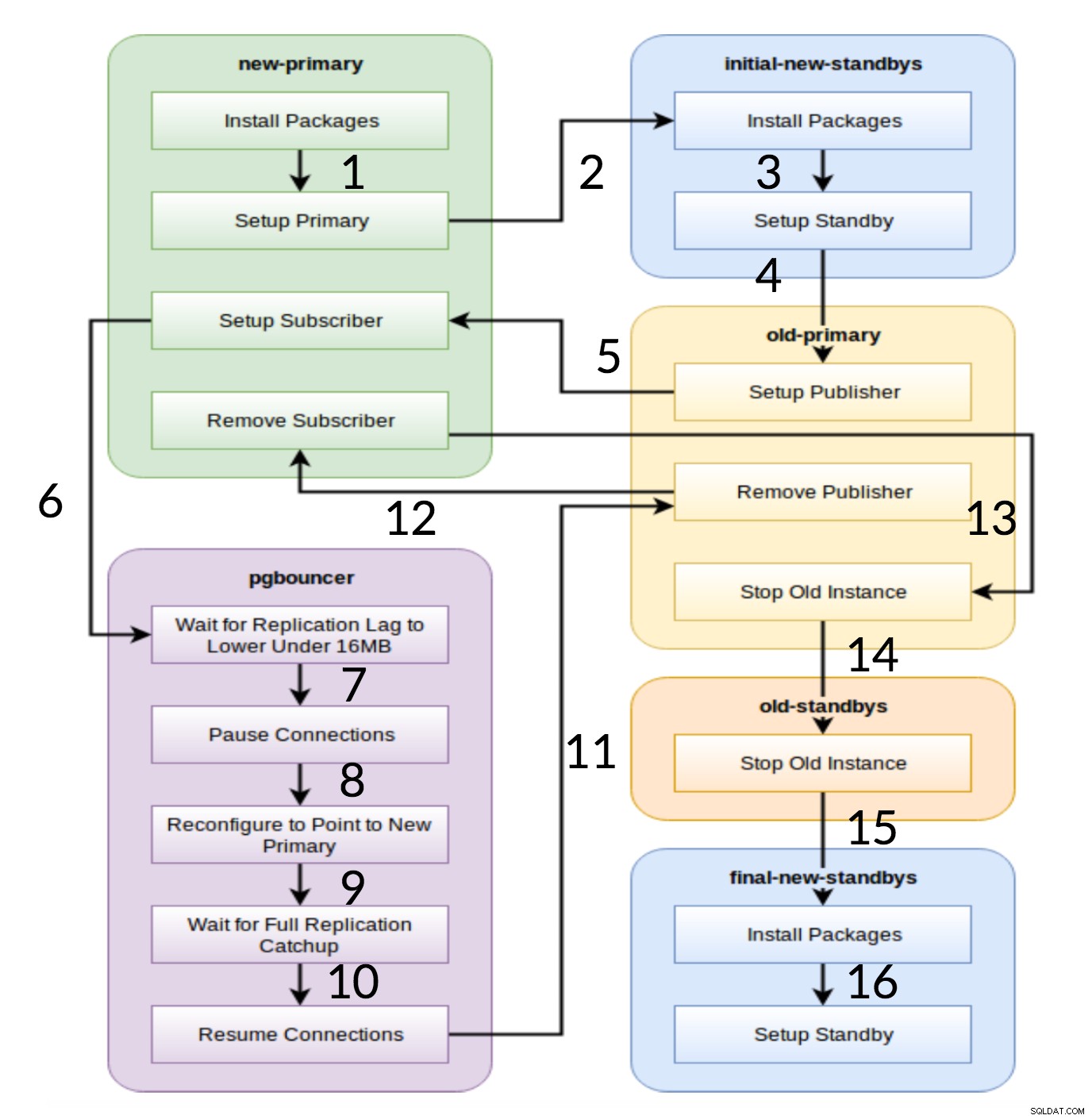
Przepływ pracy Pglupgrade
Jak widać na powyższym diagramie, istnieje sześć grup serwerów, które są generowane na początku na podstawie konfiguracji (obie hosts.ini i config.yml ). new-primary i old-primary grupy zawsze będą miały jeden serwer, pgbouncer grupa może mieć jeden lub więcej serwerów, a wszystkie grupy rezerwowe mogą mieć zero lub więcej serwerów. Jeśli chodzi o wdrożenie, cały proces jest podzielony na osiem kroków. Każdy krok odpowiada zagrywce w playbooku pglupgrade, która wykonuje wymagane zadania na przydzielonych grupach hostów. Proces aktualizacji wyjaśniono w następujących sztukach:
- Buduj hosty na podstawie konfiguracji: Zabawa przygotowawcza, która buduje wewnętrzne grupy serwerów na podstawie konfiguracji. Wynik tej gry (w połączeniu z
hosts.inizawartość) to sześć grup serwerów (zilustrowanych różnymi kolorami na diagramie przepływu pracy), które będą używane przez siedem kolejnych odtworzeń. - Skonfiguruj nowy klaster z początkowym trybem gotowości: Konfiguruje pusty klaster PostgreSQL z nowym podstawowym i początkowym trybem gotowości (jeśli są zdefiniowane). Zapewnia to, że nie ma pozostałości po instalacjach PostgreSQL z poprzedniego użycia.
- Zmodyfikuj starą wersję podstawową, aby obsługiwała replikację logiczną: Instaluje rozszerzenie pglogical. Następnie ustawia wydawcę, dodając wszystkie tabele i sekwencje do replikacji.
- Replikuj na nowy podstawowy: Konfiguruje subskrybenta na nowym serwerze głównym, który działa jako wyzwalacz do rozpoczęcia replikacji logicznej. Ta gra kończy replikację istniejących danych i zaczyna nadrabiać to, co się zmieniło od czasu rozpoczęcia replikacji.
- Przełącz pgbouncer (i aplikacje) na nowy podstawowy: Gdy opóźnienie replikacji zbliża się do zera, wstrzymuje pgbouncer, aby stopniowo przełączać aplikację. Następnie wskazuje konfigurację pgbouncer na nową podstawową i czeka, aż różnica replikacji osiągnie zero. Na koniec pgbouncer jest wznawiany, a wszystkie oczekujące transakcje są propagowane do nowego podstawowego i tam rozpoczynają przetwarzanie. Początkowe tryby gotowości są już w użyciu i odpowiadają na żądania odczytu.
- Wyczyść konfigurację replikacji między starym i nowym podstawowym: Przerywa połączenie między starym a nowym serwerem głównym. Ponieważ wszystkie aplikacje są przenoszone na nowy serwer główny, a aktualizacja jest zakończona, replikacja logiczna nie jest już potrzebna. Replikacja między serwerami podstawowymi i rezerwowymi jest kontynuowana z replikacją fizyczną.
- Zatrzymaj stary klaster: Usługa Postgres została zatrzymana na starych hostach, aby żadna aplikacja nie mogła się już z nią połączyć.
- Ponownie skonfiguruj pozostałe tryby gotowości dla nowego podstawowego: Odbudowuje inne rezerwy, jeśli istnieją inne hosty niż początkowe rezerwy. W drugim studium przypadku nie ma pozostałych serwerów rezerwowych do odbudowania. Ten krok daje możliwość odbudowania starego serwera podstawowego jako nowego rezerwowego, jeśli zostanie wskazany w grupie new-standbys w hosts.ini. Możliwość ponownego wykorzystania istniejących serwerów (nawet starych serwerów podstawowych) jest osiągana dzięki dwuetapowemu projektowi konfiguracji w trybie gotowości narzędzia pglupgrade. Użytkownik może określić, które serwery powinny stać się rezerwami nowego klastra przed aktualizacją, a które po aktualizacji.
Wniosek
W tym poście omówiliśmy szczegóły implementacji i projekt wysokiej dostępności narzędzia pglupgrade. Czyniąc to, wspomnieliśmy również o kilku kluczowych koncepcjach rozwoju Ansible (tj. playbook, ekwipunku i plikach konfiguracyjnych) na przykładzie narzędzia. Zilustrowaliśmy przebieg procesu ulepszania i podsumowaliśmy, jak każdy krok działa z odpowiednią grą. Będziemy kontynuować wyjaśnianie pglupgrade, pokazując studia przypadków w nadchodzących postach z tej serii.
Dziękujemy za przeczytanie!