Replikacja strumieniowa PostgreSQL to świetny sposób na skalowanie klastrów PostgreSQL i zwiększanie ich dostępności. Jak w przypadku każdej replikacji, chodzi o to, że slave jest kopią mastera i że slave jest stale aktualizowany o zmiany, które zaszły na masterze, przy użyciu jakiegoś mechanizmu replikacji.
Może się zdarzyć, że slave z jakiegoś powodu straci synchronizację z masterem. Jak mogę przywrócić go z powrotem do łańcucha replikacji? Jak mogę się upewnić, że urządzenie podrzędne jest ponownie zsynchronizowane z urządzeniem nadrzędnym? Rzućmy okiem na ten krótki wpis na blogu.
Co jest bardzo pomocne, nie ma możliwości pisania na urządzeniu podrzędnym, jeśli jest on w trybie odzyskiwania. Możesz to przetestować w ten sposób:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionNadal może się zdarzyć, że slave nie będzie zsynchronizowany z masterem. Uszkodzenie danych — ani sprzęt, ani oprogramowanie nie są pozbawione błędów i problemów. Niektóre problemy z napędem dyskowym mogą powodować uszkodzenie danych na urządzeniu podrzędnym. Niektóre problemy z procesem „próżnia” mogą spowodować zmianę danych. Jak wyjść z tego stanu?
Odbudowa Slave za pomocą pg_basebackup
Głównym krokiem jest zaopatrzenie urządzenia podrzędnego przy użyciu danych z urządzenia nadrzędnego. Biorąc pod uwagę, że będziemy używać replikacji strumieniowej, nie możemy używać logicznej kopii zapasowej. Na szczęście istnieje gotowe narzędzie, które można wykorzystać do konfiguracji:pg_basebackup. Zobaczmy, jakie byłyby kroki, które musimy podjąć, aby udostępnić serwer podrzędny. Aby było jasne, używamy PostgreSQL 12 na potrzeby tego wpisu na blogu.
Stan początkowy jest prosty. Nasz niewolnik nie jest repliką swojego pana. Zawarte w nim dane są uszkodzone i nie można ich używać ani ufać. Dlatego pierwszym krokiem, który zrobimy, będzie zatrzymanie PostgreSQL na naszym serwerze podrzędnym i usunięcie zawartych w nim danych:
example@sqldat.com:~# systemctl stop postgresqlLub nawet:
example@sqldat.com:~# killall -9 postgresTeraz sprawdźmy zawartość pliku postgresql.auto.conf, możemy później użyć poświadczeń replikacji przechowywanych w tym pliku, dla pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Interesuje nas użytkownik i hasło używane do konfiguracji replikacji.
Nareszcie możemy usunąć dane:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Po usunięciu danych musimy użyć pg_basebackup, aby pobrać dane z mastera:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointUżyte przez nas flagi mają następujące znaczenie:
- -Xs: chcielibyśmy przesyłać strumieniowo WAL podczas tworzenia kopii zapasowej. Pomaga to uniknąć problemów z usuwaniem plików WAL, gdy masz duży zbiór danych.
- -P: chcielibyśmy zobaczyć postęp tworzenia kopii zapasowej.
- -R: chcemy, aby pg_basebackup utworzył plik standby.signal i przygotował plik postgresql.auto.conf z ustawieniami połączenia.
pg_basebackup poczeka na punkt kontrolny przed rozpoczęciem tworzenia kopii zapasowej. Jeśli trwa to zbyt długo, możesz skorzystać z dwóch opcji. Po pierwsze, można ustawić tryb punktu kontrolnego na szybki w pg_basebackup za pomocą opcji „-c fast”. Alternatywnie możesz wymusić zaznaczenie punktu kontrolnego, wykonując:
postgres=# CHECKPOINT;
CHECKPOINTW taki czy inny sposób uruchomi się pg_basebackup. Za pomocą flagi -P możemy śledzić postęp:
416906/1588478 kB (26%), 0/1 tablespaceceaceGdy kopia zapasowa jest gotowa, wszystko, co musimy zrobić, to upewnić się, że zawartość katalogu danych ma przypisanego właściwego użytkownika i grupę - wykonaliśmy pg_basebackup jako „root”, dlatego chcemy zmienić go na „postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/To wszystko, możemy uruchomić urządzenie podrzędne i powinno zacząć się replikować z urządzenia nadrzędnego.
example@sqldat.com:~# systemctl start postgresqlMożesz dwukrotnie sprawdzić postęp replikacji, wykonując następujące zapytanie na wzorcu:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Jak widać, oba urządzenia podrzędne replikują się poprawnie.
Odbudowa Slave za pomocą ClusterControl
Jeśli jesteś użytkownikiem ClusterControl, możesz łatwo osiągnąć dokładnie to samo, wybierając opcję z interfejsu użytkownika.
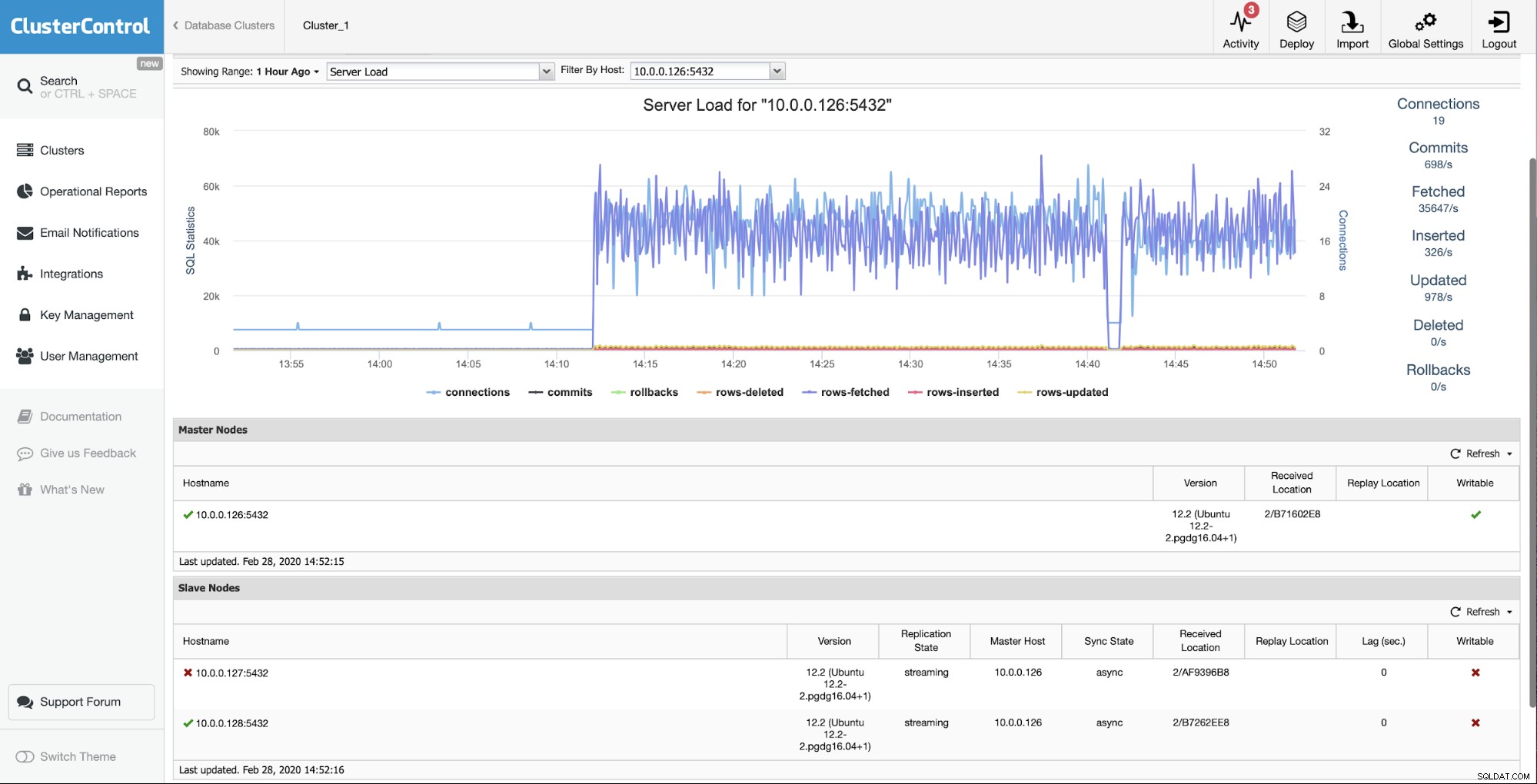
Wyjściowa sytuacja jest taka, że jeden z niewolników (10.0.0.127) jest nie działa i nie powiela się. Uznaliśmy, że przebudowa jest dla nas najlepszą opcją.
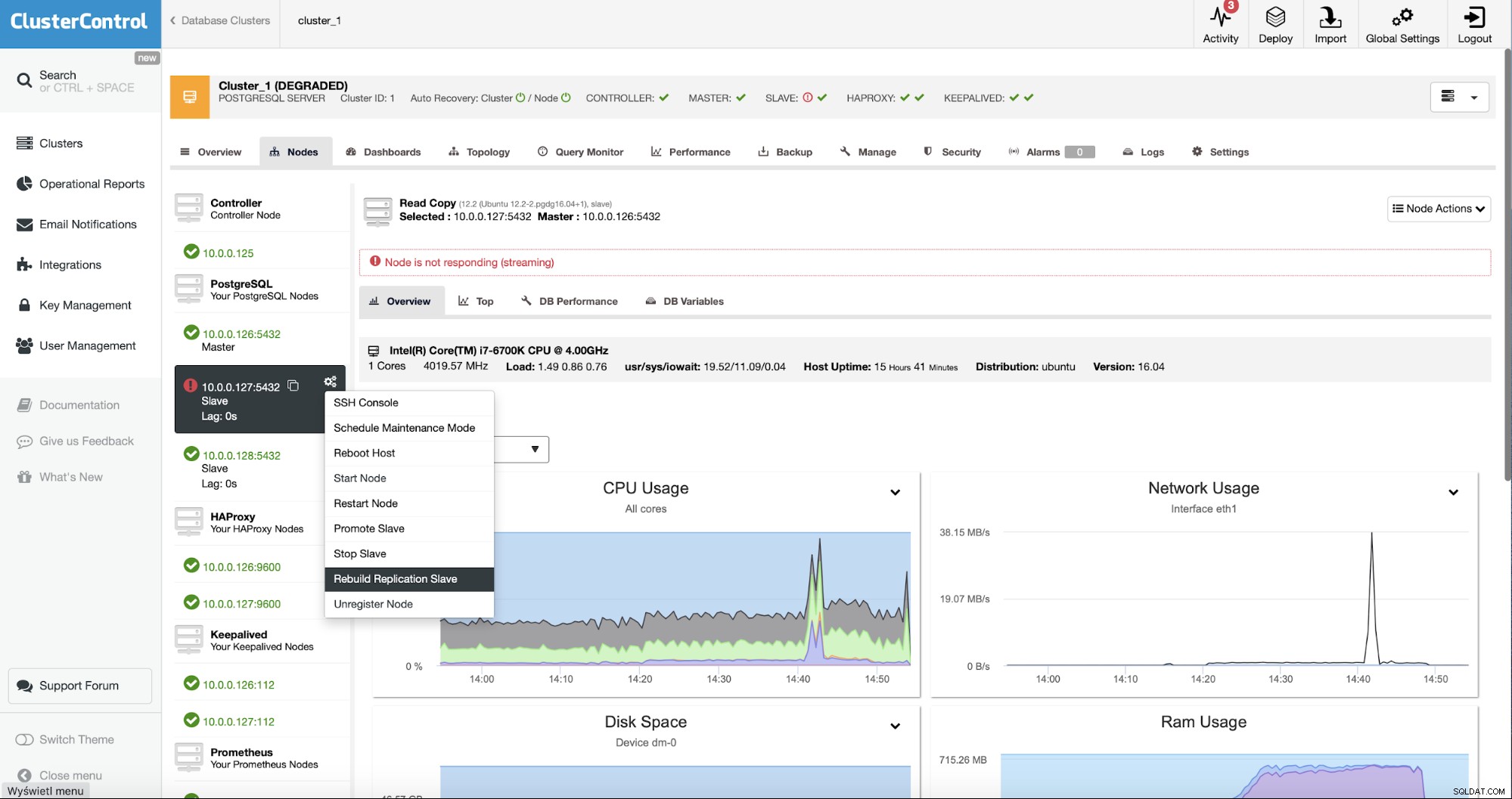
Jako użytkownicy ClusterControl wszystko, co musimy zrobić, to przejść do „Węzłów ” i uruchom zadanie „Rebuild Replication Slave”.
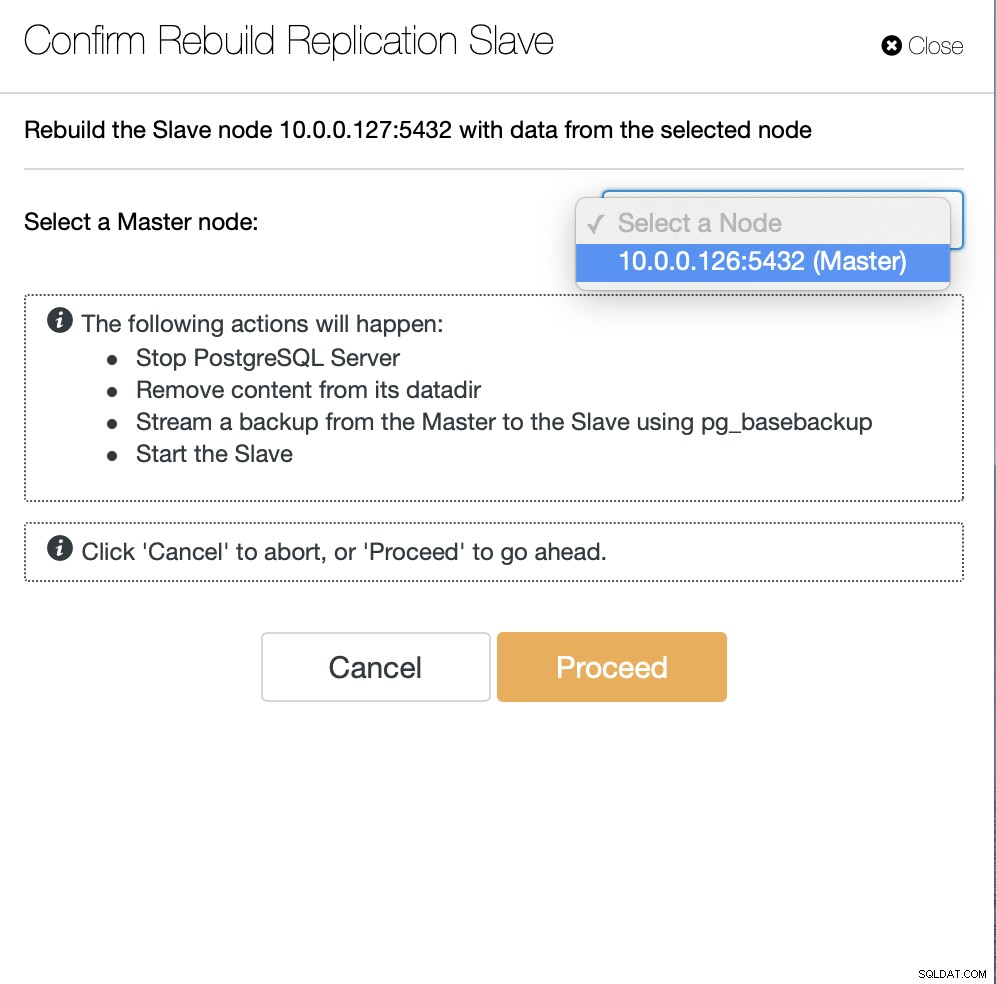
Następnie musimy wybrać węzeł, z którego odbudujemy slave'a i to jest wszystko. ClusterControl użyje pg_basebackup do skonfigurowania urządzenia podrzędnego replikacji i skonfigurowania replikacji natychmiast po przesłaniu danych.
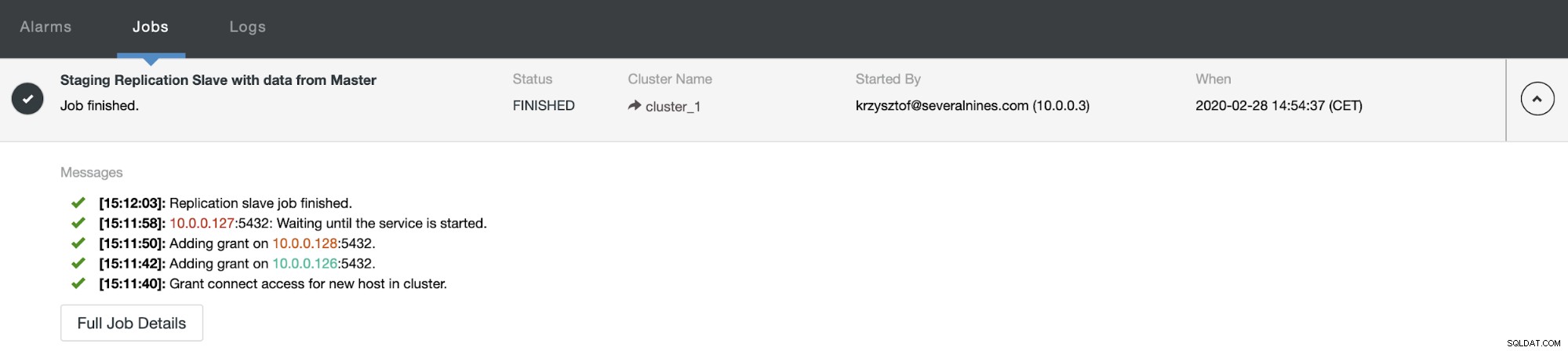
Po pewnym czasie zadanie zostanie zakończone i urządzenie podrzędne wróci do łańcucha replikacji:
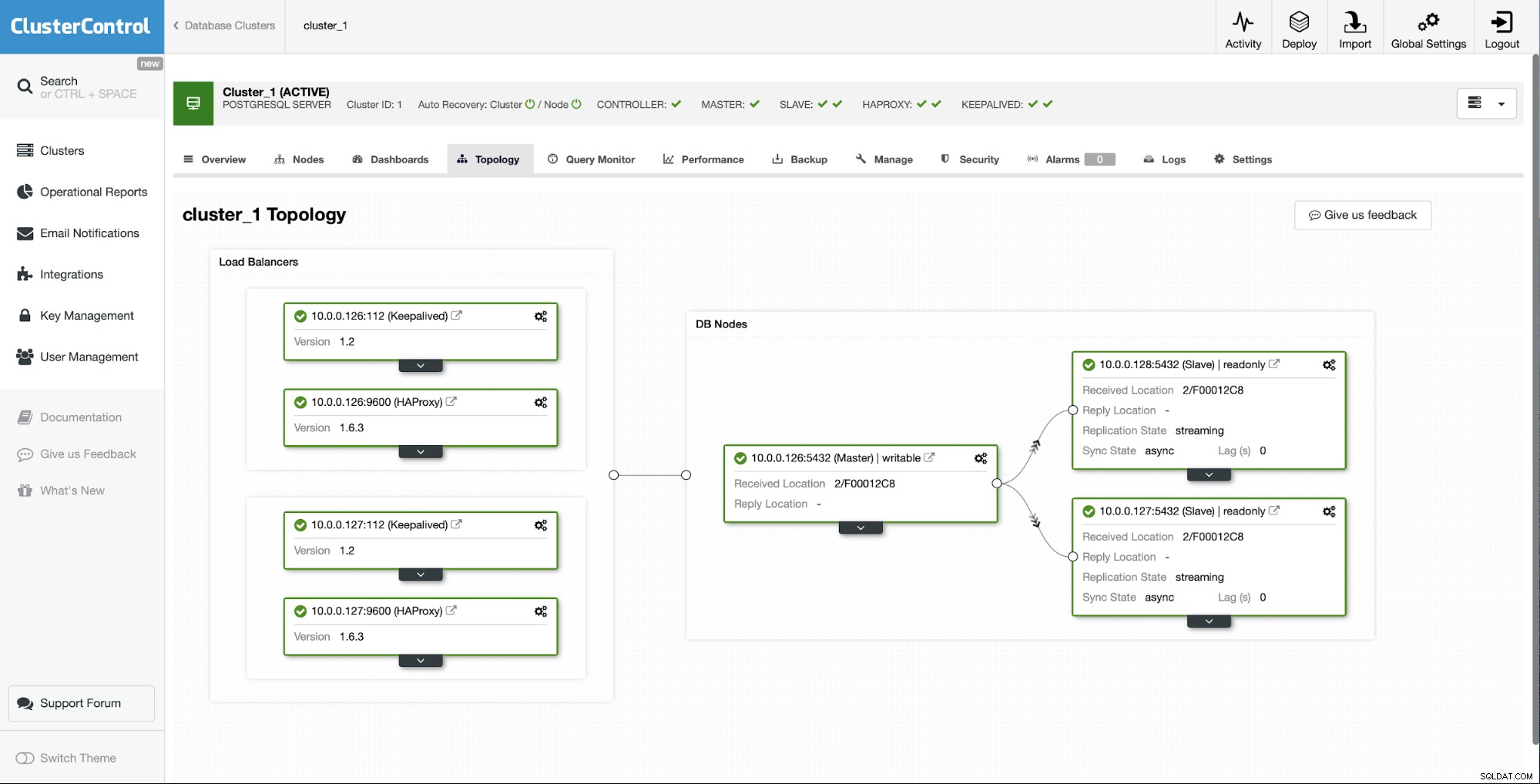
Jak widać, za pomocą zaledwie kilku kliknięć, dzięki ClusterControl, udało nam się odbudować nasze uszkodzone urządzenie podrzędne i przenieść je z powrotem do klastra.