Wcześniej zaczęliśmy rozmawiać o problemach z replikacją transakcyjną programu SQL Server. Teraz zamierzamy kontynuować kilka praktycznych demonstracji, aby zrozumieć często napotykane problemy z wydajnością replikacji i jak je prawidłowo rozwiązywać.
Omówiliśmy już takie problemy, jak problemy z konfiguracją, problemy z uprawnieniami, problemy z łącznością i problemy z integralnością danych wraz z rozwiązywaniem problemów i ich naprawianiem. Teraz skupimy się na różnych problemach z wydajnością i korupcją wpływających na replikację SQL Server.
Ponieważ problemy z korupcją to ogromny temat, omówimy ich wpływ tylko w tym artykule i nie będziemy wchodzić w szczegóły. Na podstawie mojego doświadczenia wybrałem kilka scenariuszy, które mogą wchodzić w zakres problemów z wydajnością i korupcją:
- Problemy z wydajnością
- Długotrwałe aktywne transakcje w bazie danych wydawcy
- Zbiorcze operacje INSERT/UPDATE/DELETE na artykułach
- Ogromne zmiany danych w ramach jednej transakcji
- Blokowania w bazie danych dystrybucji
- Kwestie związane z korupcją
- Uszkodzenia bazy danych wydawców
- Uszkodzenia bazy danych dystrybucji
- Uszkodzenia bazy danych subskrybentów
- Uszkodzenia bazy danych MSDB
Problemy z wydajnością
Replikacja transakcyjna SQL Server to skomplikowana architektura, która obejmuje kilka parametrów, takich jak baza danych wydawcy, baza danych dystrybutora (dystrybucja), baza danych subskrybenta i kilku agentów replikacji działających jako zadania agenta SQL Server.
Ponieważ szczegółowo omówiliśmy wszystkie te elementy w naszych poprzednich artykułach, wiemy, jak ważny jest każdy z nich dla funkcjonalności replikacji. Wszystko, co ma wpływ na te komponenty, może wpłynąć na wydajność replikacji SQL Server.
Na przykład wystąpienie bazy danych Publisher przechowuje krytyczną bazę danych z dużą liczbą transakcji na sekundę. Jednak zasoby serwera mają wąskie gardło, takie jak stałe użycie procesora powyżej 90% lub zużycie pamięci powyżej 90%. Z pewnością wpłynie to na wydajność zadania Log Reader Agent, które odczytuje dane o zmianach z dzienników transakcyjnych bazy danych Publishera.
Podobnie dowolne takie scenariusze w wystąpieniach bazy danych dystrybutora lub subskrybenta mogą mieć wpływ na agenta migawki lub agenta dystrybucji. Tak więc, jako DBA, musisz upewnić się, że zasoby serwera, takie jak procesor, pamięć fizyczna i przepustowość sieci, są efektywnie skonfigurowane dla instancji bazy danych wydawcy, dystrybutora i subskrybenta.
Zakładając, że serwery baz danych wydawcy, subskrybenta i dystrybutora są poprawnie skonfigurowane, nadal możemy mieć problemy z wydajnością replikacji, gdy napotkamy poniższe scenariusze.
Długotrwałe aktywne transakcje w bazie danych wydawców
Jak sama nazwa wskazuje, długoterminowe transakcje aktywne pokazują, że istnieje wywołanie aplikacji lub operacja użytkownika w zakresie transakcji wykonywana przez długi czas.
Znalezienie długotrwałej aktywnej transakcji oznacza, że transakcja nie została jeszcze zatwierdzona i może zostać wycofana lub zatwierdzona przez aplikację. Zapobiegnie to obcinaniu dziennika transakcji, co spowoduje ciągły wzrost rozmiaru pliku dziennika transakcji.
Agent czytnika dzienników skanuje wszystkie zatwierdzone rekordy, które są oznaczone do replikacji z dzienników transakcyjnych w kolejności serializowanej na podstawie numeru sekwencji dziennika (LSN), pomijając wszystkie inne zmiany zachodzące w przypadku artykułów, które nie są replikowane. Jeśli polecenia długoterminowej aktywnej transakcji nie zostały jeszcze zatwierdzone, replikacja pominie wysyłanie tych poleceń i wyśle wszystkie inne zatwierdzone transakcje do bazy danych dystrybucji. Po zatwierdzeniu długotrwałej aktywnej transakcji rekordy zostaną wysłane do bazy danych dystrybucji i do tego czasu nieaktywna część pliku dziennika transakcji bazy danych wydawcy nie zostanie wyczyszczona, powodując w ten sposób zwiększenie rozmiaru bazy danych pliku dziennika transakcji wydawcy.
Możemy przetestować scenariusz długotrwałej aktywnej transakcji, wykonując następujące kroki:
Domyślnie Agent dystrybucji czyści wszystkie zatwierdzone zmiany w bazie danych subskrybentów, zachowując ostatni rekord w celu monitorowania nowych zmian na podstawie numeru sekwencji dziennika (LSN).
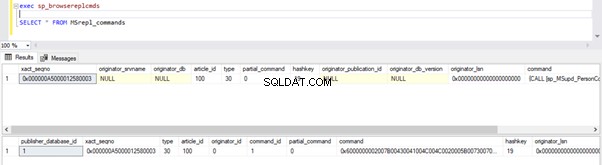
Możemy wykonać poniższe zapytania, aby sprawdzić stan rekordów dostępnych w MSRepl_Commands tabel lub przy użyciu sp_browsereplcmds procedura w bazie danych dystrybucji:
exec sp_browsereplcmds
GO
SELECT * FROM MSrepl_commands
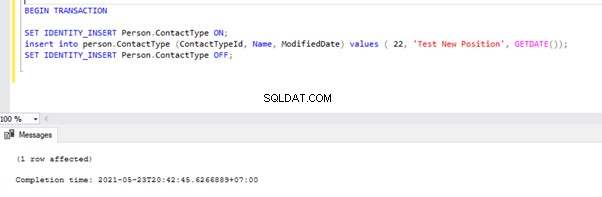
Teraz otwórz nowe okno zapytania i wykonaj poniższy skrypt, aby utworzyć długotrwałą aktywną transakcję w AdventureWorks Baza danych. Zauważ, że poniższy skrypt nie zawiera żadnych poleceń ROLLBACK ani COMMIT TRANSACTION. Dlatego odradzamy uruchamianie tego rodzaju poleceń w produkcyjnej bazie danych.
BEGIN TRANSACTION
SET IDENTITY_INSERT Person.ContactType ON;
insert into person.ContactType (ContactTypeId, Name, ModifiedDate) values ( 22, 'Test New Position', GETDATE());
SET IDENTITY_INSERT Person.ContactType OFF;
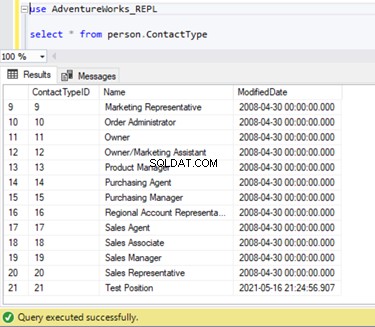
Możemy sprawdzić, czy ten nowy rekord nie został zreplikowany do bazy danych subskrybentów. W tym celu wykonamy instrukcję SELECT na Person.ContactType tabela w bazie danych subskrybentów:
Sprawdźmy, czy powyższe polecenie INSERT zostało odczytane przez agenta odczytu dziennika i zapisane w bazie danych dystrybucji.
Wykonaj ponownie skrypty z części Kroku 1. Wyniki nadal pokazują ten sam stary status, co potwierdza, że rekord nie został odczytany z dzienników transakcji bazy danych wydawcy.
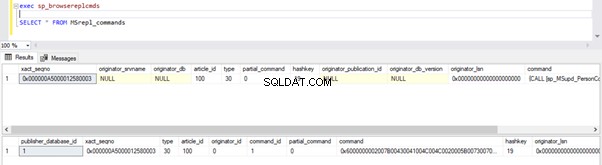
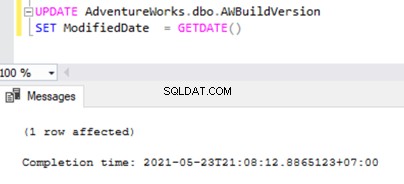
Teraz otwórz nowe zapytanie i uruchom poniższy skrypt UPDATE, aby sprawdzić, czy Agent czytnika dzienników był w stanie pominąć długotrwałą aktywną transakcję i odczytać zmiany wprowadzone przez tę instrukcję UPDATE.
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
Sprawdź bazę danych dystrybucji, czy agent czytnika dzienników może przechwycić tę zmianę. Uruchom skrypt w ramach kroku 1:
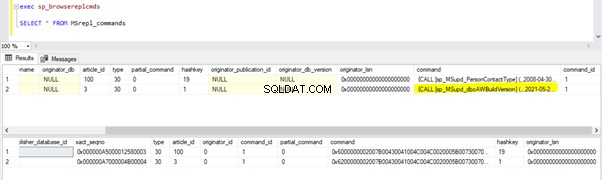
Ponieważ powyższa instrukcja UPDATE została zatwierdzona w bazie danych wydawcy, agent czytnika dzienników może zeskanować tę zmianę i wstawić ją do bazy danych dystrybucji. Następnie zastosował tę zmianę do bazy danych subskrybentów, jak pokazano poniżej:
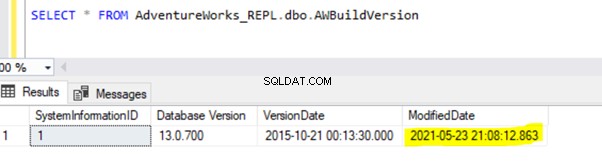
WSTAW w Person.ContactType zostaną zreplikowane do bazy danych Subskrybentów dopiero po zatwierdzeniu transakcji INSERT w bazie danych Wydawcy. Zanim zatwierdzimy, możemy szybko sprawdzić, jak zidentyfikować długotrwałą aktywną transakcję, zrozumieć ją i efektywnie obsłużyć.
Zidentyfikuj długotrwałą aktywną transakcję
Aby sprawdzić jakiekolwiek długotrwałe aktywne transakcje w dowolnej bazie danych, otwórz nowe okno zapytania i połączyć się z odpowiednią bazą danych, którą musimy sprawdzić. Wykonaj DBCC OPENTRAN polecenie konsoli – jest to polecenie konsoli bazy danych umożliwiające przeglądanie transakcji otwartych w bazie danych w czasie wykonywania.
USE AdventureWorks
GO
DBCC OPENTRAN
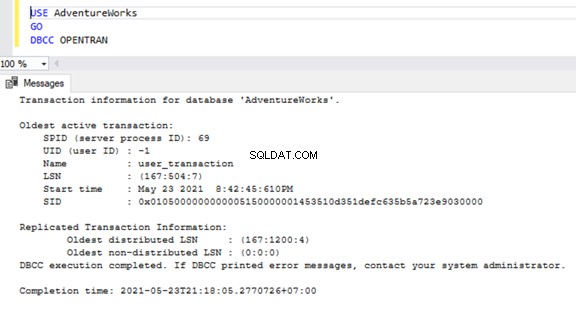
Teraz wiemy, że istniał SPID (Identyfikator procesu serwera ) 69 działa przez długi czas. Sprawdźmy, które polecenie zostało wykonane na tej transakcji za pomocą DBCC INPUTBUFFER console command (polecenie konsoli bazy danych używane do identyfikacji polecenia lub operacji wykonywanej na wybranym identyfikatorze procesu serwera).
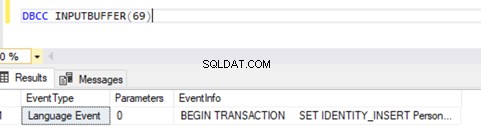
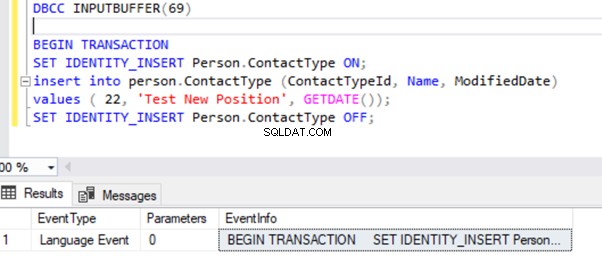
Aby zapewnić czytelność, kopiuję EventInfo wartość pola i sformatowanie go, aby pokazać polecenie, które wykonaliśmy wcześniej.
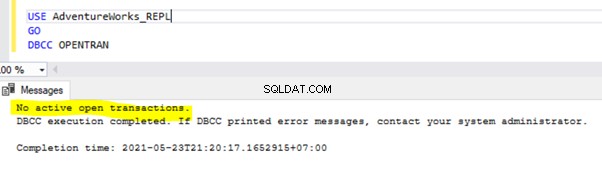
Jeśli w wybranej bazie danych nie ma żadnych długo działających aktywnych transakcji, otrzymamy poniższy komunikat:
Podobne do DBCC OPENTRAN polecenie konsoli, możemy WYBIERZ z DMV o nazwie sys.dm_tran_database_transactions aby uzyskać bardziej szczegółowe wyniki (więcej danych można znaleźć w artykule MSDN).
Teraz wiemy, jak zidentyfikować długotrwałą transakcję. Możemy zatwierdzić transakcję i zobaczyć, jak instrukcja INSERT zostanie zreplikowana.
Przejdź do okna, w którym wstawiliśmy rekord do Person.ContactType tabeli w zakresie Transakcji i wykonaj TRANSAKCJĘ ZATWIERDZĄC, jak pokazano poniżej:
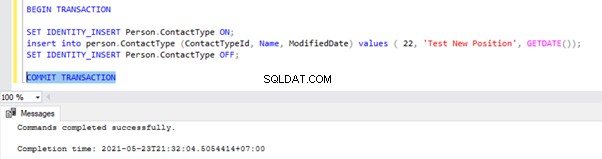
Wykonanie polecenia COMMIT TRANSACTION zatwierdziło rekord do bazy danych Wydawcy. Dlatego powinien być widoczny w bazie danych Dystrybucji i bazie danych Abonentów:
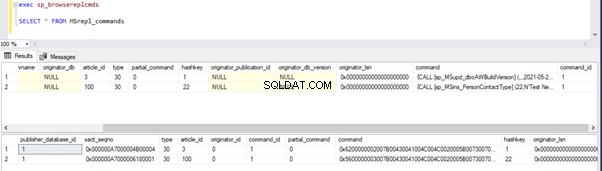
Jeśli zauważyłeś, starsze rekordy z bazy danych dystrybucji zostały wyczyszczone przez zadanie oczyszczania agenta dystrybucji. Nowy rekord dla INSERT na Person.ContactType tabela była widoczna w MSRepl_cmds tabela.
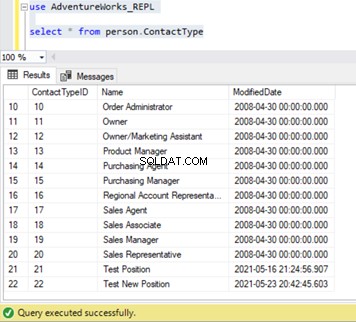
Z naszych testów dowiedzieliśmy się następujących rzeczy:
- Zadanie agenta odczytującego dzienniki replikacji transakcyjnej programu SQL Server będzie skanować w poszukiwaniu zatwierdzonych rekordów tylko z bazy danych dzienników transakcyjnych wydawcy i INSERT do bazy danych subskrybenta.
- Kolejność zmienionych danych w bazie danych Wydawcy przesłana do Subskrybenta będzie oparta na statusie Zobowiązania i czasie w bazie danych Wydawcy, nawet jeśli zreplikowane dane będą miały taki sam czas jak w bazie danych Wydawcy.
- Identyfikacja długotrwałych aktywnych transakcji może pomóc w rozwiązaniu problemu wzrostu pliku dziennika transakcji wydawcy, dystrybutora, subskrybenta lub dowolnych baz danych.
Zbiorcze operacje SQL INSERT/UPDATE/DELETE na artykułach
W przypadku ogromnych ilości danych znajdujących się w bazie danych wydawców, często kończymy się koniecznością WSTAWIANIA, AKTUALIZACJI lub USUWANIA ogromnych rekordów do zreplikowanych tabel.
Jeśli operacje INSERT, UPDATE lub DELETE są wykonywane w jednej transakcji, na pewno zakończy się to zablokowaniem replikacji na długi czas.
Załóżmy, że musimy WSTAWIĆ 10 milionów rekordów do zreplikowanej tabeli. Wstawienie tych rekordów w jednym ujęciu spowoduje problemy z wydajnością.
INSERT INTO REplicated_table
SELECT * FROM Source_table
Zamiast tego możemy WSTAWIĆ rekordy w partiach po 0,1 lub 0,5 miliona rekordów w ciągu WHILE pętla lub Pętla KURSORA i zapewni szybszą replikację. Możemy nie otrzymać poważnych problemów dotyczących instrukcji INSERT, chyba że w innym przypadku odpowiednia tabela ma wiele indeksów. Będzie to jednak miało ogromny wpływ na wydajność instrukcji UPDATE lub DELETE.
Załóżmy, że dodaliśmy nową kolumnę do tabeli Replikowane, która zawiera około 10 milionów rekordów. Chcemy zaktualizować tę nową kolumnę o wartość domyślną.
Idealnie, poniższe polecenie będzie działać dobrze, aby UAKTUALNIĆ wszystkie rekordy 10 milionów z domyślną wartością Abc :
-- UPDATE 10 Million records on Replicated Table with some DEFAULT values
UPDATE Replicated_table
SET new_column = 'Abc'
Jednak, aby uniknąć wpływu na replikację, powinniśmy wykonać powyższą operację UPDATE w partiach po 0,1 lub 0,5 miliona rekordów, aby uniknąć problemów z wydajnością.
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
UPDATE TOP(100000) Replicated_Table
SET new_Column = 'Abc'
WHERE new_column is NULL
IF @@ROWCOUNT = 0
BREAK
END
Podobnie, jeśli musimy USUNĄĆ około 10 milionów rekordów z tabeli zreplikowanej, możemy to zrobić partiami:
-- DELETE 10 Million records on Replicated Table with some DEFAULT values
DELETE FROM Replicated_table
-- UPDATE in batches to avoid performance impacts on Replication
WHILE 1 = 1
BEGIN
DELETE TOP(100000) Replicated_Table
IF @@ROWCOUNT = 0
BREAK
END
Skuteczna obsługa BULK INSERT, UPDATE lub DELETE może pomóc w rozwiązaniu problemów z replikacją.
Wskazówka dla profesjonalistów :Aby WSTAWIĆ ogromne dane do zreplikowanej tabeli w bazie danych Publisher, użyj kreatora IMPORT/EKSPORT w SSMS, ponieważ wstawi on rekordy w partiach po 10000 lub na podstawie rozmiaru rekordu szybciej obliczonego przez SQL Server.
Ogromne zmiany danych w ramach pojedynczej transakcji
Aby zachować integralność danych z perspektywy aplikacji lub programowania, wiele aplikacji ma zdefiniowane transakcje jawne dla operacji o znaczeniu krytycznym. Jednakże, jeśli wiele operacji (WSTAW, AKTUALIZUJ lub USUŃ) jest wykonywanych w ramach pojedynczej transakcji, agent odczytu dziennika najpierw poczeka na zakończenie transakcji, jak widzieliśmy wcześniej.
Gdy transakcja zostanie zatwierdzona przez aplikację, agent czytnika dzienników musi przeskanować te ogromne zmiany danych wykonane w dziennikach transakcji bazy danych Publisher. Podczas tego skanowania możemy zobaczyć ostrzeżenia lub komunikaty informacyjne w agencie czytnika dzienników, takie jak
Agent czytnika dzienników skanuje dziennik transakcji w poszukiwaniu poleceń, które mają zostać zreplikowane. W przebiegu # xxxx przeskanowano około xxxxxx rekordów dziennika, z których oznaczono do replikacji, czas, który upłynął xxxxxxxxx (ms)
Przed zidentyfikowaniem rozwiązania dla tego scenariusza musimy zrozumieć, w jaki sposób Agent czytnika dzienników skanuje rekordy z dzienników transakcyjnych i wstawia rekordy do bazy danych dystrybucji MSrepl_transactions i MSrepl_cmds tabele.
SQL Server wewnętrznie ma numer sekwencji dziennika (LSN) w dziennikach transakcyjnych. Agent czytnika dzienników wykorzystuje wartości LSN do skanowania zmian oznaczonych dla replikacji serwera SQL w kolejności.
Agent czytnika dzienników wykonuje sp_replcmds rozszerzona procedura składowana do pobierania poleceń oznaczonych jako replikacja z bazy danych dzienników transakcyjnych wydawcy.
Sp_replcmds akceptuje parametr wejściowy o nazwie @maxtrans aby pobrać maksymalną liczbę transakcji. Wartość domyślna to 1, co oznacza, że będzie skanować dowolną liczbę transakcji dostępnych z dzienników, które mają zostać wysłane do bazy danych dystrybucji. Jeśli istnieje 10 operacji INSERT wykonanych za pośrednictwem pojedynczej Transakcji i zatwierdzonych w bazie danych Wydawcy, pojedyncza partia może zawierać 1 Transakcję z 10 poleceniami.
Jeśli zostanie zidentyfikowanych wiele transakcji z słabszymi poleceniami, agent odczytu dziennika połączy wiele transakcji lub XACT numer sekwencji do pojedynczej partii replikacji. Ale przechowuje się jako inny XACT Sekwencja liczba w MSRepl_transactions stół. Poszczególne polecenia należące do tej transakcji zostaną przechwycone w MSRepl_commands tabela.
Aby zweryfikować rzeczy, które omówiliśmy powyżej, aktualizuję Data modyfikacji kolumna dbo.AWBuildVersion tabeli do dzisiejszej daty i zobacz, co się stanie:
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
Przed wykonaniem UPDATE weryfikujemy rekordy obecne w MSrepl_commands i MSrepl_transactions stoły:
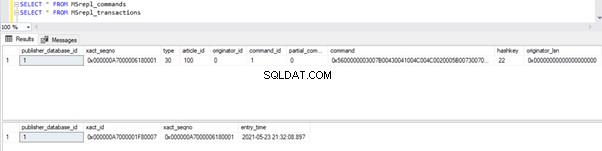
Teraz wykonaj powyższy skrypt UPDATE i zweryfikuj rekordy obecne w tych 2 tabelach:
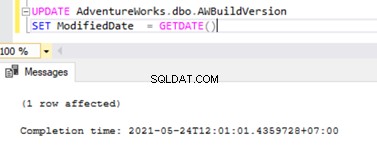
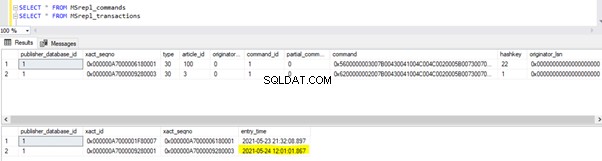
Nowy rekord z czasem UPDATE został wstawiony do MSrepl_transactions tabela z pobliskim entry_time . Sprawdzanie polecenia na tym xact_seqno pokaże listę logicznie pogrupowanych poleceń przy użyciu sp_browsereplcmds procedura.

W Monitorze replikacji możemy zobaczyć pojedynczą instrukcję UPDATE przechwyconą w ramach 1 transakcji z 1 poleceniem od wydawcy do dystrybutora.
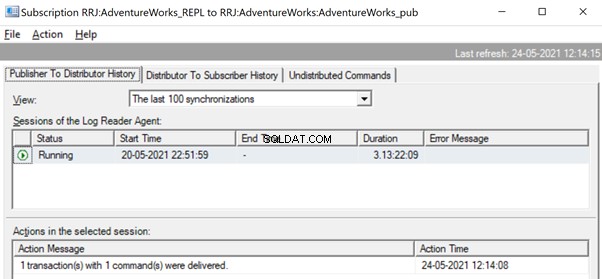
I widzimy, jak to samo polecenie jest dostarczane od dystrybutora do subskrybenta w ułamku sekundy różnicy. Wskazuje, że replikacja przebiega prawidłowo.
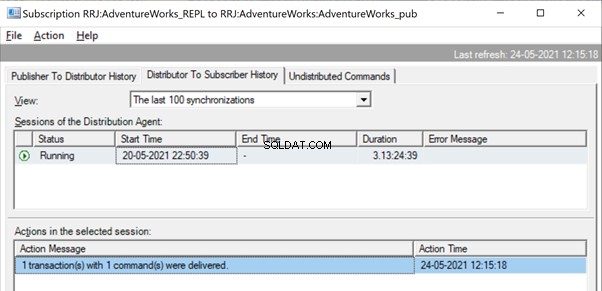
Teraz, jeśli istnieje ogromna liczba transakcji połączonych w jednym xact_seqno , widzimy wiadomości takie jak dostarczono 10 transakcji z 5000 poleceń .
Sprawdźmy to, wykonując UPDATE na 2 różnych stołach w tym samym czasie:
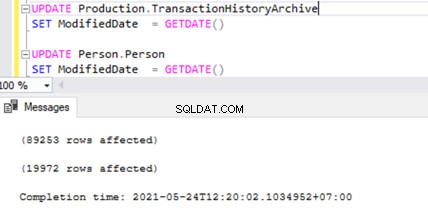
Widzimy dwa rekordy transakcji w MSrepl_transactions tabela pasująca do dwóch operacji UPDATE, a następnie nr. rekordów w tej tabeli pasujących do nr. rekordów zaktualizowanych.
Wynik z MSrepl_transactions tabela:
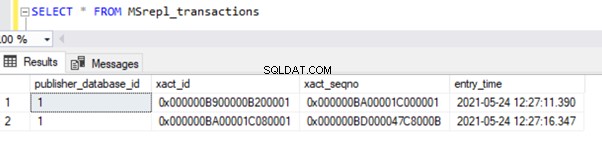
Wynik z MSrepl_commands tabela:
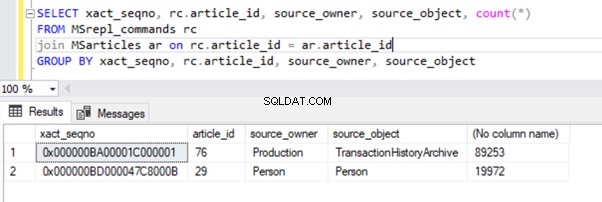
Zauważyliśmy jednak, że te 2 transakcje są logicznie pogrupowane przez agenta czytnika dzienników i połączone w jedną partię jako 2 transakcje z poleceniami 109225.
Ale wcześniej możemy zobaczyć komunikaty takie jak Dostarczanie zreplikowanych transakcji, liczba xact:1, liczba poleceń 46601 .
Będzie się to działo, dopóki Agent czytnika dzienników nie zeskanuje pełnego zestawu zmian i zidentyfikuje, że 2 transakcje UPDATE zostały w pełni odczytane z dzienników transakcyjnych.
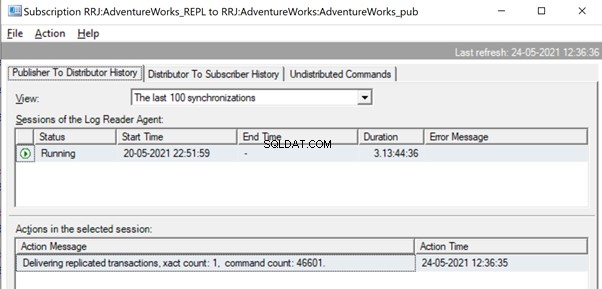
Gdy polecenia zostaną w pełni odczytane z dzienników transakcyjnych, widzimy, że 2 transakcje z 109225 poleceniami zostały dostarczone przez agenta czytnika dzienników:
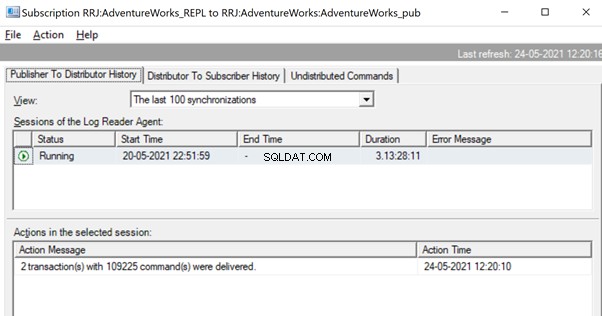
Ponieważ agent dystrybucji czeka na replikację dużej transakcji, możemy zobaczyć komunikat taki jak Dostarczanie zreplikowanych transakcji wskazuje, że nastąpiła replikacja dużej transakcji i musimy poczekać, aż zostanie ona całkowicie zreplikowana.
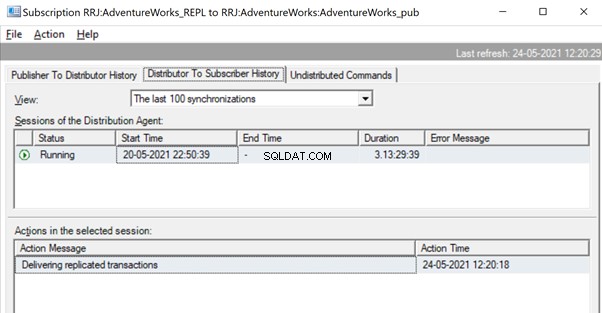
Po replikacji możemy również zobaczyć poniższą wiadomość w agencie dystrybucji:
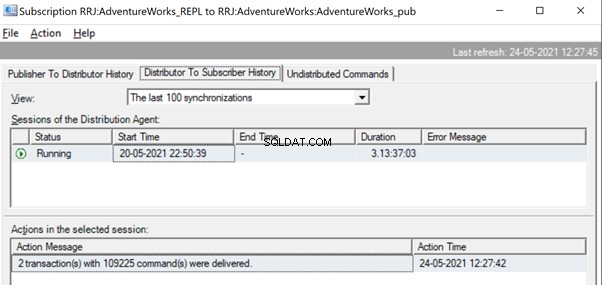
Kilka sposobów jest pomocnych w rozwiązaniu tych problemów.
Sposób 1:UTWÓRZ nową procedurę składowaną SQL
Musisz utworzyć nową procedurę składowaną i zawrzeć w niej logikę aplikacji w zakresie Transakcji.
Po utworzeniu dodaj ten artykuł Procedura składowana do Replikacja i zmień właściwość artykułu Replikuj na Wykonywanie procedury składowanej opcja.
Pomoże to wykonać artykuł o procedurze przechowywanej u subskrybenta zamiast replikować wszystkie indywidualne zmiany danych, które miały miejsce.
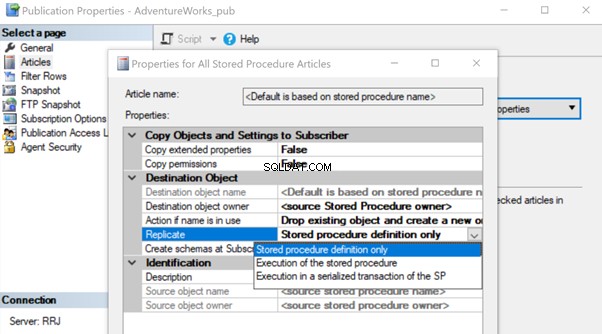
Zobaczmy, jak wykonywanie procedury przechowywanej opcja Replikuj zmniejsza obciążenie replikacji. Aby to zrobić, możemy utworzyć testową procedurę przechowywaną, jak pokazano poniżej:
CREATE procedure test_proc
AS
BEGIN
UPDATE AdventureWorks.dbo.AWBuildVersion
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Production.TransactionHistoryArchive
SET ModifiedDate = GETDATE()
UPDATE TOP(10) Person.Person
SET ModifiedDate = GETDATE()
END
Powyższa procedura spowoduje UAKTUALNIENIE pojedynczego rekordu w AWBuildVersion tabela i po 10 rekordów w Production.TransactionHistoryArchive i Osoba.Osoba tabele zawierające do 21 zmian rekordów.
Po utworzeniu tej nowej procedury zarówno dla wydawcy, jak i subskrybenta, dodaj ją do replikacji. W tym celu kliknij prawym przyciskiem myszy Publikacja i wybierz artykuł dotyczący procedury Replikacja z domyślną definicją tylko procedury przechowywanej opcja.
Po zakończeniu możemy zweryfikować rekordy dostępne w MSrepl_transactions i MSrepl_commands tabele.
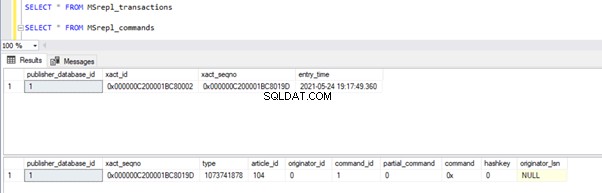
Teraz wykonajmy procedurę w bazie danych Publishera, aby zobaczyć, ile rekordów jest śledzonych.
W tabelach dystrybucji widać następujące elementy MSrepl_transactions i MSrepl_commands :
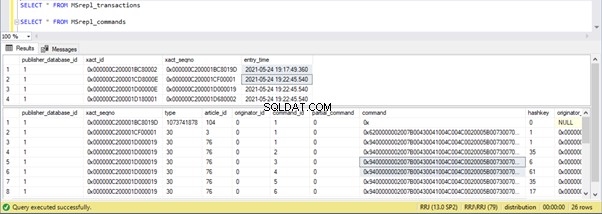
Trzy xact_seqno zostały utworzone dla trzech operacji UPDATE w MSrepl_transactions tabeli i 21 poleceń zostało wstawionych do MSrepl_commands tabela.
Otwórz Monitor replikacji i zobacz, czy są one wysyłane jako 3 różne partie replikacji, czy jako pojedyncza partia z 3 transakcjami razem.
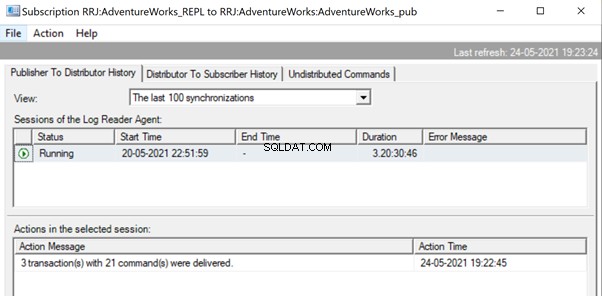
Widzimy, że trzy xact_seqno została skonsolidowana jako pojedyncza partia replikacji. W związku z tym widzimy, że 3 transakcje z 21 poleceniami zostały pomyślnie dostarczone.
Usuńmy procedurę z replikacji i dodajmy ją z powrotem za pomocą drugiego wykonania procedury przechowywanej opcja. Teraz wykonaj procedurę i zobacz, jak rekordy są replikowane.
Sprawdzanie rekordów z tabel dystrybucji pokazuje poniższe szczegóły:
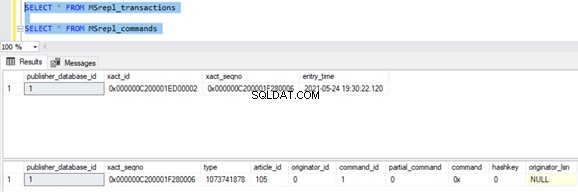
Teraz wykonaj procedurę w bazie danych Publisher i zobacz, ile rekordów jest rejestrowanych w tabelach dystrybucji. Wykonanie procedury zaktualizowało 21 rekordów (1 rekord, 10 rekordów i 10 rekordów) jak wcześniej.
Tabele weryfikacji dystrybucji zawierają poniższe dane:
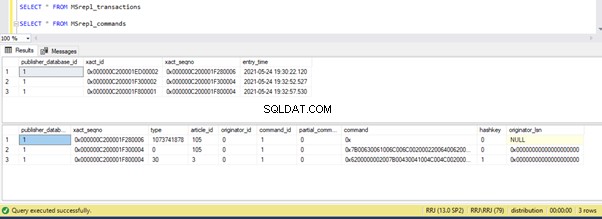
Rzućmy okiem na sp_browsereplcmds, aby zobaczyć otrzymane polecenie:

Polecenie to „{call „dbo”.”test_proc” }” które zostaną wykonane w bazie danych subskrybentów.
W Monitorze replikacji widzimy, że tylko 1 transakcja z 1 poleceniem została dostarczona przez replikację:
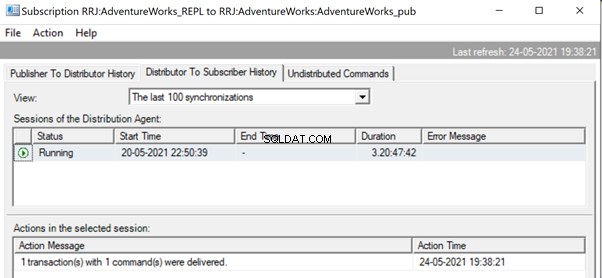
W naszym przypadku testowym zastosowaliśmy procedurę z zaledwie 21 zmianami danych. Jeśli jednak zrobimy to w przypadku skomplikowanej procedury obejmującej miliony zmian, wówczas podejście procedury składowanej z wykonaniem procedury składowanej opcja będzie skuteczna w zmniejszaniu obciążenia replikacji.
Musimy zweryfikować to podejście, sprawdzając, czy procedura ma logikę aktualizacji tylko tego samego zestawu rekordów w bazach danych wydawcy i subskrybenta. W przeciwnym razie spowoduje to problemy z niespójnością danych u wydawcy i subskrybenta.
Sposób 2:Konfigurowanie parametrów agenta czytnika dzienników MaxCmdsInTran, ReadBatchSize i ReadBatchThreshold
MaxCmdsInTran – wskazuje maksymalną liczbę poleceń, które można logicznie pogrupować w ramach Transakcji podczas odczytywania danych z bazy danych Dzienników Transakcyjnych wydawcy i zapisywania w bazie danych Dystrybucji.
W naszych wcześniejszych testach zauważyliśmy, że około 109225 poleceń zostało zgromadzonych w jednej dokładnej sekwencji replikacji, co skutkuje niewielkim spowolnieniem lub opóźnieniem. Jeśli ustawimy MaxCmdsInTran parametr na 10000, pojedyncza dokładna sekwencja liczba zostanie podzielona na 11 dokładne sekwencje skutkujące szybszym dostarczaniem poleceń od wydawcy do dystrybutora . Mimo że ta opcja pomaga zmniejszyć rywalizację o bazę danych dystrybucji i szybciej replikować dane z wydawcy do bazy danych subskrybenta, należy zachować ostrożność podczas korzystania z tej opcji. Może to zakończyć się dostarczeniem danych do bazy danych subskrybentów i uzyskaniem do nich dostępu z tabel bazy danych subskrybentów przed końcem oryginalnego zakresu transakcji.
Odczytaj rozmiar wsadu – Ten parametr może nie być pomocny w przypadku scenariusza pojedynczej dużej transakcji. Jednak pomaga, gdy w bazie danych wydawców odbywa się wiele mniejszych transakcji.
Jeśli liczba poleceń na transakcję jest mniejsza, Agent czytnika dzienników połączy wiele zmian w jeden zakres transakcji polecenia replikacji. Rozmiar Read Batch wskazuje, ile transakcji można odczytać w dzienniku transakcji przed wysłaniem zmian do bazy danych Distribution. Wartości mogą wynosić od 500 do 10000.
OdczytPróg wsadu – wskazuje liczbę poleceń do odczytania z dziennika transakcyjnego bazy danych Wydawcy przed wysłaniem do Subskrybenta z domyślną wartością 0 w celu przeskanowania pełnego pliku dziennika. Możemy jednak zmniejszyć tę wartość, aby szybciej wysyłać dane, ograniczając ją do 10000 lub 100000 takich poleceń.
Sposób 3:Konfigurowanie najlepszych wartości dla parametru SubscriptionStreams
Strumienie subskrypcji – wskazuje liczbę połączeń, które agent dystrybucji może wykonać równolegle w celu pobrania danych z bazy danych Distribution i rozpropagowania ich do bazy danych subskrybenta. Domyślna wartość to 1, co sugeruje tylko jeden strumień lub połączenie z dystrybucji do bazy danych subskrybentów. Wartości mogą wynosić od 1 do 64. Jeśli zostanie dodanych więcej strumieni subskrypcji, może to skończyć się przeciążeniem CXPACKET (innymi słowy, równoległość). Dlatego należy zachować ostrożność podczas konfigurowania tej opcji w środowisku produkcyjnym.
Podsumowując, staraj się unikać ogromnych INSERT, UPDATE lub DELETE w jednej transakcji. Jeśli niemożliwe jest wyeliminowanie tych operacji, najlepszą opcją byłoby przetestowanie powyższych sposobów i wybranie tego, który najlepiej odpowiada Twoim konkretnym warunkom.
Blokowania w bazie danych dystrybucji
Dystrybucyjna baza danych jest sercem replikacji transakcyjnej serwera SQL i jeśli nie będzie właściwie obsługiwana, wystąpi wiele problemów z wydajnością.
Podsumowując wszystkie zalecane praktyki dotyczące konfiguracji bazy danych dystrybucji, musimy upewnić się, że poniższe konfiguracje zostały wykonane poprawnie:
- Pliki danych z baz danych dystrybucji powinny być umieszczane na dyskach o dużej liczbie IOPS. Jeśli baza danych Publisher będzie miała wiele zmian danych, musimy upewnić się, że baza danych dystrybucji jest umieszczona na dysku z wysokimi IOPS. Będzie stale otrzymywać dane od agenta Log Reader, wysyłając dane do bazy danych subskrybentów za pośrednictwem agenta dystrybucji. Wszystkie zreplikowane dane będą usuwane z bazy danych dystrybucji co 10 minut za pośrednictwem zadania czyszczenia dystrybucji.
- Skonfiguruj właściwości początkowego rozmiaru pliku i automatycznego wzrostu bazy danych dystrybucji z zalecanymi wartościami na podstawie poziomów aktywności bazy danych wydawcy. W przeciwnym razie doprowadzi to do fragmentacji danych i plików dziennika, powodując problemy z wydajnością.
- Dołącz dystrybucyjne bazy danych do regularnych zadań konserwacji indeksu skonfigurowanych na serwerach, na których znajduje się dystrybucyjna baza danych.
- Uwzględnij dystrybucyjne bazy danych w harmonogramie zadań pełnej kopii zapasowej, aby rozwiązać określone problemy.
- Upewnij się, że Czyszczenie dystrybucji:dystrybucja zadanie jest uruchamiane co 10 minut zgodnie z domyślnym harmonogramem. W przeciwnym razie rozmiar bazy danych dystrybucji stale rośnie i prowadzi do problemów z wydajnością.
Jak zauważyliśmy do tej pory, w bazie danych dystrybucji, zaangażowane tabele kluczy to MSrepl_transactions i MSrepl_commands . Rekordy są tam wstawiane przez zadanie agenta odczytującego dzienniki, wybrane przez zadanie agenta dystrybucji, stosowane w bazie danych subskrybentów, a następnie usuwane lub czyszczone przez zadanie agenta czyszczenia dystrybucji.
Jeśli baza danych dystrybucji nie jest poprawnie skonfigurowana, możemy napotkać blokowanie sesji w tych 2 tabelach, co spowoduje problemy z wydajnością replikacji SQL Server.
Możemy wykonać poniższe zapytanie w dowolnej bazie danych, aby wyświetlić sesje blokujące dostępne w bieżącej instancji SQL Server:
SELECT *
FROM sys.sysprocesses
where blocked > 0
order by waittime desc
Jeśli powyższe zapytanie zwróci jakiekolwiek wyniki, możemy zidentyfikować polecenia w tych zablokowanych sesjach, wykonując DBCC INPUTBUFFER(spid) poleceniem konsoli i podejmij odpowiednie działania.
Problemy związane z korupcją
Baza danych SQL Server używa swojego algorytmu lub logiki do przechowywania danych w tabelach i przechowywania ich w ekstentach lub stronach. Uszkodzenie bazy danych to proces, w którym fizyczny stan plików/zakresów/stron związanych z bazą danych zmienia się z normalnego na niestabilny lub bez pobierania, co utrudnia lub uniemożliwia pobieranie danych.
Wszystkie bazy danych SQL Server są podatne na uszkodzenia bazy danych. Przyczynami mogą być:
- Awarie sprzętu, takie jak problemy z dyskiem, pamięcią masową lub kontrolerem;
- Awarie systemu operacyjnego serwera, takie jak problemy z poprawkami;
- Awarie zasilania skutkujące nagłym wyłączeniem serwerów lub niewłaściwym zamknięciem bazy danych.
Jeśli uda nam się odzyskać lub naprawić bazy danych bez utraty danych, nie będzie to miało wpływu na replikację SQL Server. Jeśli jednak dojdzie do utraty danych podczas odzyskiwania lub naprawy uszkodzonych baz danych, zaczniemy otrzymywać wiele problemów z integralnością danych, które omówiliśmy w naszym poprzednim artykule.
Korupcja może wystąpić na różnych komponentach, takich jak:
- Uszkodzone dane wydawcy/pliki dziennika
- Uszkodzone dane/pliki dziennika subskrybenta
- Uszkodzone dane/pliki dziennika w bazie danych dystrybucji
- Uszkodzone dane/pliki dziennika bazy danych Msdb
If we receive a lot of data integrity issues after fixing up Corruption issues, it is recommended to remove the Replication completely, fix all Corruption issues in the Publisher, Subscriber, or Distributor database and then reconfigure Replication to fix it. Otherwise, data integrity issues will persist and lead to data inconsistency across the Publisher and Subscriber. The time required to fix the Data integrity issues in case of Corrupted databases will be much more compared to configuring Replication from scratch. Hence identify the level of Corruption encountered and take optimal decisions to resolve the Replication issues faster.
Wondering why msdb database corruption can harm Replication? Since msdb database hold all details related to SQL Server Agent Jobs including Replication Agent jobs, any corruption on msdb database will harm Replication. To recover quickly from msdb database corruptions, it is recommended to restore msdb database from the last Full Backup of msdb database. This also signifies the importance of taking Full Backups of all system databases including msdb database.
Wniosek
Thanks for successfully going through the final power-packed article about the Performance issues in the SQL Server Transactional Replication. If you have gone through all articles carefully, you should be able to troubleshoot almost any Transactional Replication-based issues and fix them out efficiently.
If you need any further guidance or have any Transactional Replication-related issues in your environment, you can reach out to me for consultation. And if I missed anything essential in this article, you are welcome to point to that in the Comments section.