A teraz dochodzimy do drugiego artykułu w naszej migracji z serii Oracle do PostgreSQL. Tym razem przyjrzymy się START WITH/CONNECT BY konstrukcja.
W Oracle START WITH/CONNECT BY służy do tworzenia pojedynczo powiązanej struktury listy, zaczynając od danego wiersza wartowniczego. Połączona lista może mieć formę drzewa i nie wymaga równoważenia.
Aby to zilustrować, zacznijmy od zapytania i załóżmy, że tabela zawiera 5 wierszy.
SELECT * FROM person;
last_name | first_name | id | parent_id
------------+------------+----+-----------
Dunstan | Andrew | 1 | (null)
Roybal | Kirk | 2 | 1
Riggs | Simon | 3 | 1
Eisentraut | Peter | 4 | 1
Thomas | Shaun | 5 | 3
(5 rows)Oto hierarchiczne zapytanie tabeli przy użyciu składni Oracle.
select id, parent_id
from person
start with parent_id IS NULL
connect by prior id = parent_id;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3I znowu używamy PostgreSQL.
WITH RECURSIVE a AS (
SELECT id, parent_id
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT id, parent_id FROM a;
id | parent_id
----+-----------
1 | (null)
4 | 1
3 | 1
2 | 1
5 | 3
(5 rows)To zapytanie korzysta z wielu funkcji PostgreSQL, więc przejdźmy przez nie powoli.
WITH RECURSIVE
To jest „wspólne wyrażenie tabelowe” (CTE). Definiuje zestaw zapytań, które zostaną wykonane w tej samej instrukcji, a nie tylko w tej samej transakcji. Możesz mieć dowolną liczbę wyrażeń w nawiasach i oświadczenie końcowe. Do tego celu potrzebujemy tylko jednego. Deklarując tę instrukcję jako RECURSIVE , będzie wykonywał się iteracyjnie, dopóki nie zostanie zwróconych więcej wierszy.
SELECT
UNION ALL
SELECTJest to fraza zalecana dla zapytania rekurencyjnego. Jest on zdefiniowany w dokumentacji jako sposób rozróżniania punktu początkowego i algorytmu rekurencji. W terminologii Oracle można je traktować jako klauzulę START WITH połączoną z klauzulą CONNECT BY.
JOIN a ON a.id = d.parent_idJest to samodzielne łączenie z instrukcją CTE, która dostarcza dane z poprzedniego wiersza do kolejnej iteracji.
Aby zilustrować, jak to działa, dodajmy do zapytania wskaźnik iteracji.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT * FROM a;
id | parent_id | recursion_level
----+-----------+-----------------
1 | (null) | 1
4 | 1 | 2
3 | 1 | 2
2 | 1 | 2
5 | 3 | 3
(5 rows)Inicjujemy wskaźnik poziomu rekurencji wartością. Zauważ, że w zwracanych wierszach pierwszy poziom rekurencji występuje tylko raz. To dlatego, że pierwsza klauzula jest wykonywana tylko raz.
Druga klauzula to miejsce, w którym dzieje się magia iteracyjna. Tutaj mamy widoczność danych poprzedniego wiersza wraz z danymi bieżącego wiersza. To pozwala nam na wykonywanie obliczeń rekurencyjnych.
Simon Riggs ma bardzo fajny film o tym, jak używać tej funkcji do projektowania grafowej bazy danych. To bardzo pouczające i powinieneś zajrzeć.

Być może zauważyłeś, że to zapytanie może prowadzić do sytuacji kołowej. To jest poprawne. Deweloper musi dodać klauzulę ograniczającą do drugiego zapytania, aby zapobiec tej niekończącej się rekursji. Na przykład, powtarzając tylko 4 poziomy głębokości, zanim po prostu się poddasz.
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level --<-- initialize it here
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1 --<-- iteration increment
FROM person d
JOIN a ON a.id = d.parent_id
WHERE d.recursion_level <= 4 --<-- bail out here
) SELECT * FROM a;
Nazwy kolumn i typy danych są określone przez pierwszą klauzulę. Zwróć uwagę, że w przykładzie zastosowano operator rzutowania dla poziomu rekurencji. Na bardzo głębokim wykresie ten typ danych można również zdefiniować jako 1::bigint recursion_level .
Ten wykres jest bardzo łatwy do wizualizacji za pomocą małego skryptu powłoki i narzędzia graphviz.
#!/bin/bash -
#===============================================================================
#
# FILE: pggraph
#
# USAGE: ./pggraph
#
# DESCRIPTION:
#
# OPTIONS: ---
# REQUIREMENTS: ---
# BUGS: ---
# NOTES: ---
# AUTHOR: Kirk Roybal (), example@sqldat.com
# ORGANIZATION:
# CREATED: 04/21/2020 14:09
# REVISION: ---
#===============================================================================
set -o nounset # Treat unset variables as an error
dbhost=localhost
dbport=5432
dbuser=$USER
dbname=$USER
ScriptVersion="1.0"
output=$(basename $0).dot
#=== FUNCTION ================================================================
# NAME: usage
# DESCRIPTION: Display usage information.
#===============================================================================
function usage ()
{
cat <<- EOT
Usage : ${0##/*/} [options] [--]
Options:
-h|host name Database Host Name default:localhost
-n|name name Database Name default:$USER
-o|output file Output file default:$output.dot
-p|port number TCP/IP port default:5432
-u|user name User name default:$USER
-v|version Display script version
EOT
} # ---------- end of function usage ----------
#-----------------------------------------------------------------------
# Handle command line arguments
#-----------------------------------------------------------------------
while getopts ":dh:n:o:p:u:v" opt
do
case $opt in
d|debug ) set -x ;;
h|host ) dbhost="$OPTARG" ;;
n|name ) dbname="$OPTARG" ;;
o|output ) output="$OPTARG" ;;
p|port ) dbport=$OPTARG ;;
u|user ) dbuser=$OPTARG ;;
v|version ) echo "$0 -- Version $ScriptVersion"; exit 0 ;;
\? ) echo -e "\n Option does not exist : $OPTARG\n"
usage; exit 1 ;;
esac # --- end of case ---
done
shift $(($OPTIND-1))
[[ -f "$output" ]] && rm "$output"
tee "$output" <<eof< span="">
digraph g {
node [shape=rectangle]
rankdir=LR
EOF
psql -h $dbhost -U $dbuser -d $dbname -p $dbport -qtAf cte.sql |
sed -e 's/^/node/' -e 's/.*(null)|/node/' -e 's/^/\t/' -e 's/|[[:digit:]]*$//' |
sed -e 's/|/ -> node/' | tee -a "$output"
tee -a "$output" <<eof< span="">
}
EOF
dot -Tpng "$output" > "${output/dot/png}"
[[ -f "$output" ]] && rm "$output"
open "${output/dot/png}"</eof<></eof<>Ten skrypt wymaga tego wyrażenia SQL w pliku o nazwie cte.sql
WITH RECURSIVE a AS (
SELECT id, parent_id, 1::integer recursion_level
FROM person
WHERE parent_id IS NULL
UNION ALL
SELECT d.id, d.parent_id, a.recursion_level +1
FROM person d
JOIN a ON a.id = d.parent_id )
SELECT parent_id, id, recursion_level FROM a;Następnie wywołujesz to w ten sposób:
chmod +x pggraph
./pggraphI zobaczysz wynikowy wykres.

INSERT INTO person (id, parent_id) VALUES (6,2);Uruchom narzędzie ponownie i zobacz natychmiastowe zmiany w skierowanym wykresie:

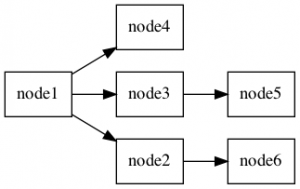
Teraz to nie było takie trudne, prawda?



