Zapytania nie są ściśle równoważne
Aby kontekst był jasny:
max(id)wykluczaNULLwartości. AleORDER BY ... LIMIT 1nie.NULLwartości sortuj na końcu w kolejności rosnącej, a najpierw w malejącej. Tak więcIndex Scan Backwardmoże nie znaleźć największej wartości (zgodnie zmax()) najpierw, ale dowolna liczbaNULLwartości.
Formalny odpowiednik:
SELECT max(id) FROM testview;
nie jest:
SELECT id FROM testview ORDER BY id DESC LIMIT 1;
ale:
SELECT id FROM testview ORDER BY id DESC NULLS LAST LIMIT 1;
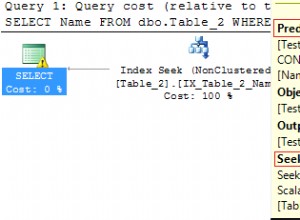
To ostatnie zapytanie nie otrzymuje planu szybkiego zapytania. Ale byłoby z indeksem z pasującą kolejnością sortowania:(id DESC NULLS LAST) .
Inaczej jest w przypadku funkcji agregujących min() i max() . Dostają szybki plan, gdy kierujesz na tabelę test1 bezpośrednio przy użyciu zwykłego indeksu PK na (id) . Ale nie, gdy bazuje na widoku (lub bezpośrednio na bazowym zapytaniu sprzężenia - widok nie jest blokerem). Indeks sortujący wartości NULL we właściwym miejscu nie ma prawie żadnego efektu.
My wiem, że id w tym zapytaniu nigdy nie może być NULL . Kolumna jest zdefiniowana NOT NULL . A sprzężenie w widoku jest w rzeczywistości INNER JOIN które nie mogą wprowadzić NULL wartości dla id .
My wiem również, że indeks na test.id nie może zawierać wartości NULL.
Ale planer zapytań Postgres nie jest sztuczną inteligencją. (Ani nie próbuje być, to może szybko wymknąć się z rąk.) Widzę dwa niedociągnięcia :
min()imax()uzyskaj szybki plan tylko w przypadku kierowania na tabelę, niezależnie od kolejności sortowania indeksu, dodawany jest warunek indeksu:Index Cond: (id IS NOT NULL)ORDER BY ... LIMIT 1otrzymuje szybki plan tylko z dokładnie pasującą kolejnością sortowania indeksów.
Nie jestem pewien, czy można to poprawić (łatwo).
db<>fiddle tutaj - demonstrowanie wszystkich powyższych
Indeksy
Ten indeks jest całkowicie bezużyteczny:
CREATE INDEX ON "test" ("id");
PK na test.id jest zaimplementowany z unikalnym indeksem w kolumnie, który już obejmuje wszystko, co dodatkowy indeks może dla Ciebie zrobić.
Może być więcej, czekam na wyjaśnienie pytania.
Zniekształcony przypadek testowy
Przypadek testowy jest zbyt odległy od rzeczywistego przypadku użycia, aby miał znaczenie.
W konfiguracji testowej każda tabela ma 100 tys. wierszy, nie ma gwarancji, że każda wartość w joincol ma dopasowanie po drugiej stronie, a obie kolumny mogą być NULL
Twoja prawdziwa sprawa ma 10 mln wierszy w table1 i <100 wierszy w table2 , każda wartość w table1.joincol ma dopasowanie w table2.joincol , oba są zdefiniowane NOT NULL i table2.joincol jest unikalny. Klasyczna relacja jeden-do-wielu. Powinien istnieć UNIQUE ograniczenie na table2.joincol i ograniczenie FK t1.joincol --> t2.joincol .
Ale to obecnie wszystko jest pokręcone w pytaniu. Czekam, aż wszystko się posprząta.