To jest dobre, ale czasami może być złe.
Wąchanie parametrów dotyczy optymalizatora zapytań przy użyciu wartości podanego parametru w celu ustalenia najlepszego możliwego planu zapytań. Jednym z wielu wyborów, który jest dość łatwy do zrozumienia, jest to, czy cała tabela powinna zostać przeskanowana w celu uzyskania wartości, czy też będzie szybsza przy użyciu wyszukiwania indeksu. Jeśli wartość w Twoim parametrze jest wysoce selektywna, optymalizator prawdopodobnie zbuduje plan zapytania z wyszukiwaniami, a jeśli tak nie jest, zapytanie wykona skanowanie Twojej tabeli.
Plan zapytań jest następnie buforowany i ponownie używany dla kolejnych zapytań, które mają różne wartości. Złą częścią wyszukiwania parametrów jest sytuacja, w której plan z pamięci podręcznej nie jest najlepszym wyborem dla jednej z tych wartości.
Przykładowe dane:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
T to tabela z kilkoma tysiącami wierszy z nieklastrowanym indeksem wartości. Istnieje jeden wiersz, w którym wartość wynosi 1 a reszta ma wartość 2 .
Przykładowe zapytanie:
select *
from T
where Value = @Value;
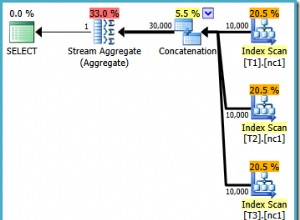
Optymalizator zapytań ma tutaj do wyboru albo wykonanie klastrowego skanowania indeksu i sprawdzenie klauzuli where w każdym wierszu, albo użycie wyszukiwania indeksu w celu znalezienia pasujących wierszy, a następnie wykonanie wyszukiwania klucza, aby uzyskać wartości z kolumn żądanych w listę kolumn.
Gdy wąchana wartość to 1 plan zapytania będzie wyglądał tak:

A kiedy wąchana wartość to 2 będzie wyglądać tak:
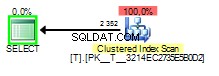
Niewłaściwa część sniffingu parametrów w tym przypadku ma miejsce, gdy plan zapytania jest budowany i sniffuje 1 ale wykonywane później z wartością 2 .
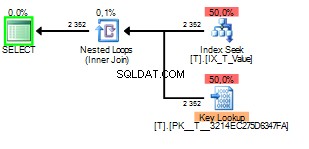
Widać, że wyszukiwanie klucza zostało wykonane 2352 razy. Skanowanie byłoby zdecydowanie lepszym wyborem.
Podsumowując, powiedziałbym, że wąchanie parametrów jest dobrą rzeczą, którą powinieneś starać się osiągnąć jak najwięcej, używając parametrów do swoich zapytań. Czasami może się nie udać i w takich przypadkach jest to najprawdopodobniej spowodowane przekrzywionymi danymi, które zakłócają Twoje statystyki.
Aktualizacja:
Oto zapytanie do kilku dmv, którego możesz użyć, aby dowiedzieć się, które zapytania są najdroższe w twoim systemie. Zmień kolejność według klauzuli, aby zastosować inne kryteria dotyczące tego, czego szukasz. Myślę, że TotalDuration to dobre miejsce na rozpoczęcie.
set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;