Wyjaśnienie
Wybór podrzędny w FROM klauzula Twojej UPDATE zwraca trzy wydziwianie. Ale każdy wiersz w tabeli docelowej można zaktualizować tylko raz w jednej UPDATE Komenda. Efekt jest taki, że widzisz tylko efekt jednego z tych trzech rzędów.
Lub słowami instrukcji :
Na marginesie:nie nazywaj swojego podzapytania „cte”. To nie jest wspólne wyrażenie tabelowe .
Właściwa UPDATE
UPDATE table_ t
SET value_ = jsonb_set(value_, '{iProps}', sub2.new_prop, false)
FROM (
SELECT id
, jsonb_agg(jsonb_set(prop, '{value, rules}', new_rules, false)
ORDER BY idx1) AS new_prop
FROM (
SELECT t.id, arr1.prop, arr1.idx1
, jsonb_agg(jsonb_set(rule, '{ao,sc}', rule #> '{ao,sc,name}', false)
ORDER BY idx2) AS new_rules
FROM table_ t
, jsonb_array_elements(value_->'iProps') WITH ORDINALITY arr1(prop,idx1)
, jsonb_array_elements(prop->'value'->'rules') WITH ORDINALITY arr2(rule,idx2)
GROUP BY t.id, arr1.prop, arr1.idx1
) sub1
GROUP BY id
) sub2
WHERE t.id = sub2.id;
db<>fiddle tutaj
Użyj jsonb_set() na każdym obiekcie (element tablicy) przed ich ponownym zagregowaniem w tablicę. Najpierw na poziomie liści i ponownie na głębszym poziomie.
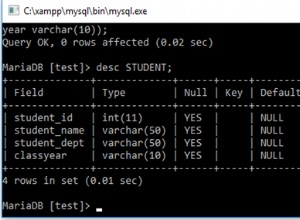
Dodałem id jako PRIMARY KEY na stół. Potrzebujemy jakiejś unikalnej kolumny, aby oddzielić wiersze.
Dodany ORDER BY może, ale nie musi być wymagane. Dodano go, aby zagwarantować oryginalne zamówienie.
Oczywiście, jeśli Twoje dane są tak regularne jak próbka, projekt relacyjny z dedykowanymi kolumnami może być prostszą alternatywą. Zobacz