[ Część 1 | Część 2 | Część 3 ]
W części 1 pokazałem, w jaki sposób kompresja strony i magazynu kolumn może zmniejszyć rozmiar tabeli 1 TB o 80% lub więcej. Chociaż byłem pod wrażeniem, że udało mi się zmniejszyć stół z 1 TB do 50 GB, nie byłem zadowolony z czasu, jaki to zajęło (od 2 do 14 godzin). Z kilkoma wskazówkami łaskawie zapożyczonymi od ludzi takich jak Joe Obbish, Lonny Niederstadt, Niko Neugebauer i innych, w tym poście postaram się wprowadzić pewne zmiany w mojej oryginalnej próbie uzyskania lepszej wydajności ładowania. Ponieważ zwykły indeks magazynu kolumn nie skompresował się lepiej niż kompresja strony w tym zestawie danych , a dotarcie tam zajęło 13 godzin dłużej, skoncentruję się wyłącznie na bardziej zaawansowanym rozwiązaniu przy użyciu COLUMNSTORE_ARCHIVE kompresja.
Oto niektóre z problemów, które moim zdaniem miały wpływ na wydajność:
- Zły wybór układu pliku – Umieściłem 8 plików w jednej grupie plików, z równoległością, ale bez (lub nieoptymalnym) partycjonowaniem, rozrzucając I/O na wiele plików z lekkomyślnym porzuceniem. Aby rozwiązać ten problem, zrobię:
- podziel tabelę na 8 partycji (po jednej na rdzeń)
- umieść plik danych każdej partycji we własnej grupie plików
- użyj 8 oddzielnych procesów do powiązania z każdą partycją
- użyj kompresji archiwum na wszystkich partycjach oprócz „aktywnej”
- zbyt wiele małych partii i nieoptymalna populacja grup wierszy – przetwarzając 10 milionów wierszy na raz, wypełniałem dziewięć grup wierszy ładną 1 048 576 wierszami, a następnie pozostałe 562 816 wierszy trafiało do innej mniejszej grupy wierszy. A wszelkie nierówne rozkłady, które pozostawiły resztę <102 400 wierszy, spowodowały wstawienie wstawek do mniej wydajnej struktury magazynu delta. Aby rozmieścić wiersze bardziej równomiernie i uniknąć przechowywania delta, będę:
- przetwarzaj jak najwięcej danych w dokładnych wielokrotnościach 1 048 576 wierszy
- rozłóż je na 8 partycjach tak równomiernie, jak to możliwe
- użyj rozmiaru partii bliższego 10x -> 100 milionów wierszy
- układanie harmonogramu – chociaż tego nie sprawdzałem, możliwe, że część spowolnienia była spowodowana przez jeden planista, który zabierał zbyt dużo pracy, a inny planista za mało, z powodu okrężnego robienia harmonogramu. Teraz, gdy będę celowo ładować dane za pomocą 8 procesów maxdop 1 zamiast jednego procesu maxdop 8, aby wszystkie harmonogramy były jednakowo zajęte, zrobię:
- użyj procedury składowanej, która stara się zrównoważyć równo w różnych harmonogramach (patrz strony 189-191 w SQLCAT's Guide to:Relational Engine, gdzie znajdziesz inspirację dla tego pomysłu)
- włącz globalne flagi śledzenia 2467 i 2469, zgodnie z ostrzeżeniem w dokumentacji
- zadanie kompresji magazynu kolumn w tle – marnotrawstwem było pozwolić, aby to działało podczas populacji, ponieważ i tak planowałem odbudować na końcu. Tym razem będę:
- wyłącz to zadanie za pomocą globalnej flagi śledzenia 634
Zrezygnowałem z początkowej funkcji i schematu partycji i zbudowałem nowy, oparty na bardziej równomiernym rozmieszczeniu danych. Chcę, aby 8 partycji odpowiadało liczbie rdzeni i liczbie plików danych, aby zmaksymalizować „równoległość biedaka”, której planuję użyć.
Najpierw musimy utworzyć nowy zestaw grup plików, każda z własnym plikiem:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Następnie przyjrzałem się liczbie wierszy w tabeli:3 754 965 954. Aby je rozpowszechniać dokładnie równomiernie na 8 partycjach, byłoby to 469 370 744,25 wierszy na partycję. Aby wszystko działało dobrze, zróbmy granice partycji, aby pomieściły następne wielokrotność 1 048 576 rzędów. To jest 1,048,576 x 448 = 469,762,048 – tyle byłoby rzędów, o które strzelamy w pierwszych 7 partycjach, pozostawiając 466 631 618 rzędów w ostatniej partycji. Aby zobaczyć rzeczywisty OID wartości, które posłużyłyby jako granice zawierające optymalną liczbę wierszy w każdej partycji, uruchomiłem to zapytanie względem oryginalnej tabeli (ponieważ uruchomienie zajęło 25 minut, szybko nauczyłem się zrzucać te wyniki do osobnej tabeli):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
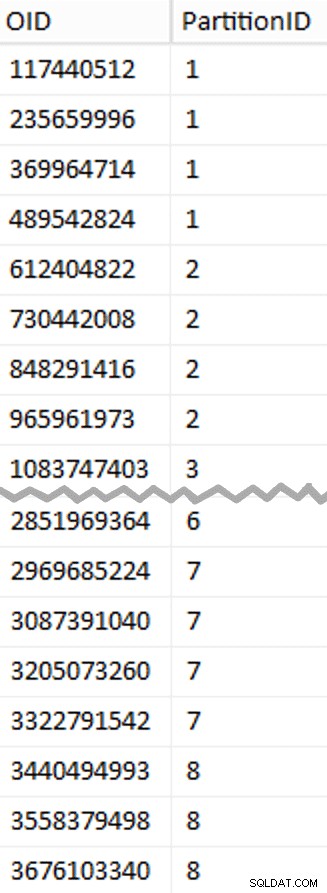 Więcej do rozpakowania, niż można by się spodziewać. CTE wykonuje wszystkie ciężkie prace, ponieważ musi zeskanować całą tabelę o pojemności 1,14 TB i przypisać numer wiersza każdemu rzędowi . Chcę zwracać tylko co
Więcej do rozpakowania, niż można by się spodziewać. CTE wykonuje wszystkie ciężkie prace, ponieważ musi zeskanować całą tabelę o pojemności 1,14 TB i przypisać numer wiersza każdemu rzędowi . Chcę zwracać tylko co (1048576*112)th wiersz, ponieważ są to moje wiersze graniczne partii, więc to jest to, co WHERE klauzula. Pamiętaj, że chcę podzielić pracę na partie bliższe 100 milionom wierszy na raz, ale tak naprawdę nie chcę przetwarzać 469 milionów wierszy w jednym ujęciu. Więc oprócz podziału danych na 8 partycji, chcę podzielić każdą z tych partycji na cztery partie po 117 440 512 (1,048,576*112) wydziwianie. Każdy sąsiadujący zestaw czterech partii należy do jednej partycji, więc PartitionID Wyprowadzam po prostu dodaje jeden do wyniku bieżącego numeru wiersza liczba całkowita podzielone przez (1,048,576*448) , co zapewnia, że granica zawsze znajduje się w „lewym” zestawie. Następnie dodajemy jeden do wyniku, ponieważ w przeciwnym razie odwołujemy się do kolekcji partycji opartej na 0, a nikt tego nie chce.
Ok, to było dużo słów. Po prawej stronie znajduje się obrazek przedstawiający (w skrócie) zawartość stage tabela (kliknij, aby wyświetlić pełny wynik, podświetlając wartości granic partycji).
Następnie możemy wyprowadzić kolejne zapytanie z tej tabeli pomostowej, które pokazuje nam wartości minimalne i maksymalne dla każdej partii w każdej partycji, a także dodatkową partię nieuwzględnioną (wiersze w oryginalnej tabeli z OID większa niż najwyższa wartość graniczna):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Te wartości wyglądają tak:
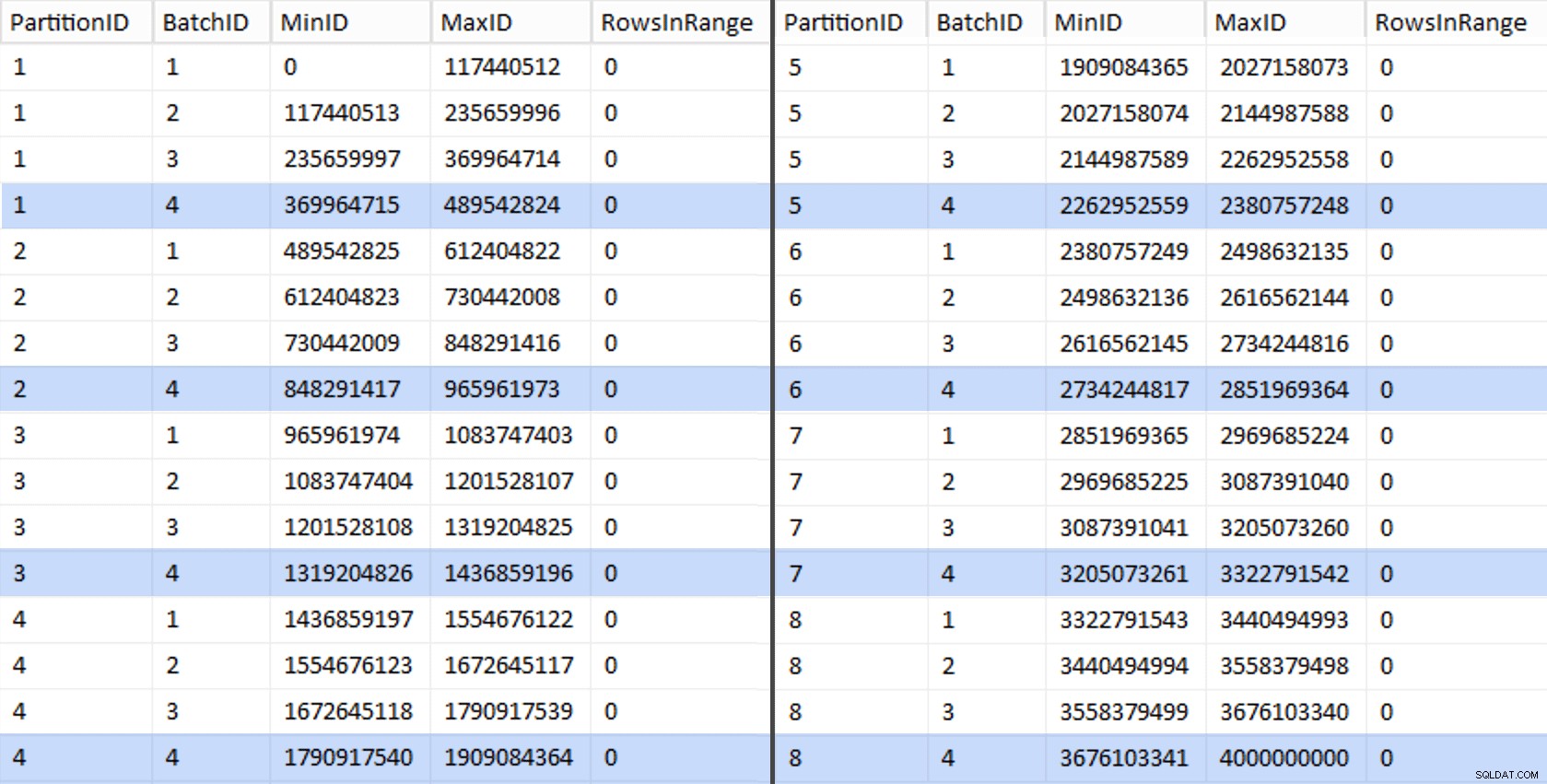
Aby przetestować naszą pracę, możemy wyprowadzić z tego zestaw zapytań, które zaktualizują BatchQueue z rzeczywistymi liczbami wierszy z tabeli.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; W moim systemie zajęło to około 6 minut. Następnie możesz uruchomić następujące zapytanie, aby pokazać, że każda partia, z wyjątkiem ostatniej, jest w stanie w pełni wypełnić grupy wierszy i nie pozostawiać żadnych pozostałości do potencjalnego użycia magazynu różnicowego:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Teraz tabela wygląda tak:
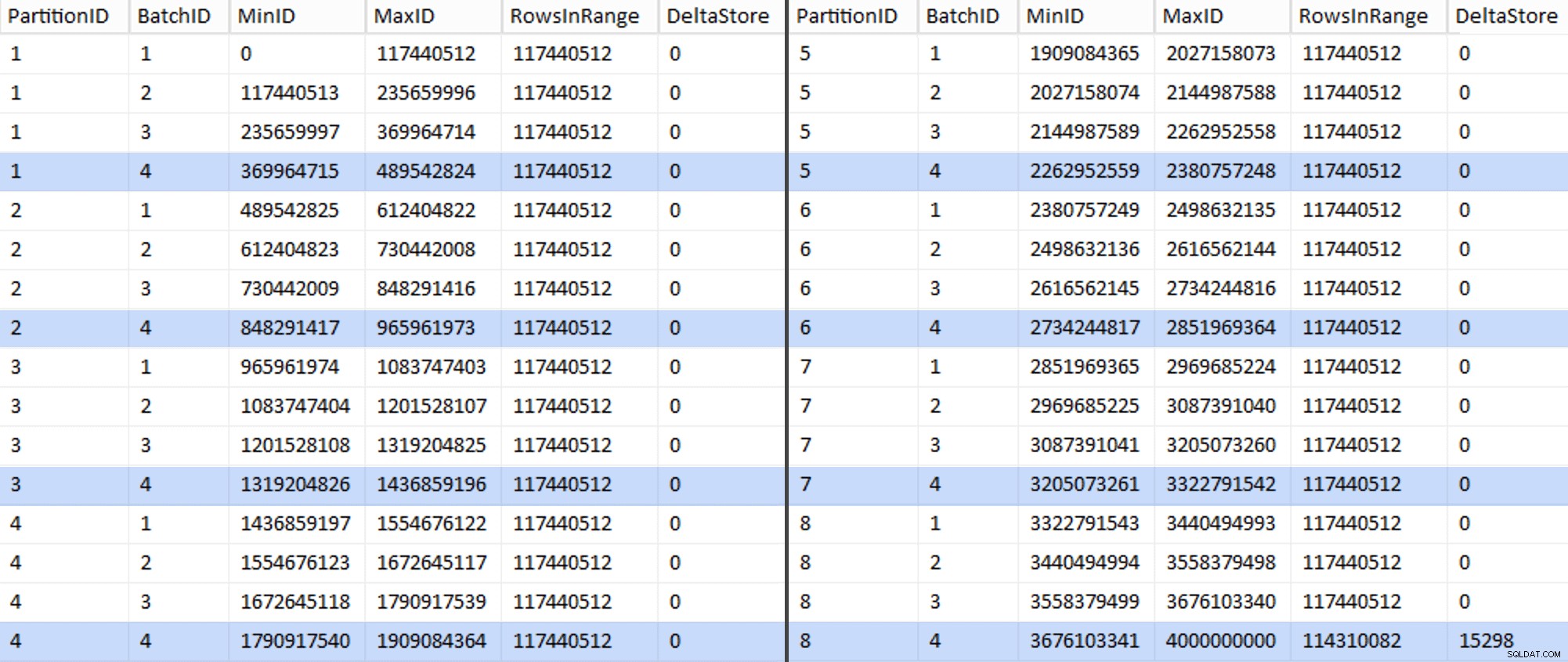
Rzeczywiście, każda partia ma obliczoną 117 440 512 milionów wierszy, z wyjątkiem ostatniego, który przynajmniej idealnie będzie zawierał nasz jedyny nieskompresowany magazyn delta. Prawdopodobnie możemy temu również zapobiec, zmieniając nieznacznie rozmiar partii dla tej partycji tak, aby wszystkie cztery partie były uruchamiane z tym samym rozmiarem, lub zmieniając liczbę partii, aby uwzględnić inną wielokrotność 102 400 lub 1 048 576. Ponieważ wymagałoby to uzyskania nowego OID wartości z tabeli bazowej, dodając kolejne 25 minut plus do naszych wysiłków związanych z migracją, pozwolę, aby ta jedna niedoskonała partycja przesunęła się — zwłaszcza, że i tak nie uzyskamy z niej pełnej kompresji archiwalnej.
BatchQueue tabela zaczyna wykazywać oznaki przydatności do przetwarzania naszych partii w celu migracji danych do naszej nowej, podzielonej na partycje, klastrowanej tabeli magazynu kolumn. Które musimy stworzyć, teraz, gdy znamy granice. Jest tylko 7 granic, więc z pewnością można to zrobić ręcznie, ale lubię, aby dynamiczny SQL wykonywał moją pracę za mnie:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Wyniki:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Po utworzeniu możemy stworzyć nasz schemat partycji i przypisać każdą kolejną partycję do jej dedykowanego pliku:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Teraz możemy utworzyć tabelę i przygotować ją do migracji:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
W części 3 dalej skonfiguruję BatchQueue tabeli, zbuduj procedurę dla procesów, aby przesłać dane do nowej struktury i przeanalizować wyniki.
[ Część 1 | Część 2 | Część 3 ]