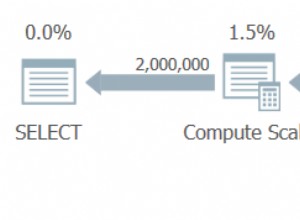
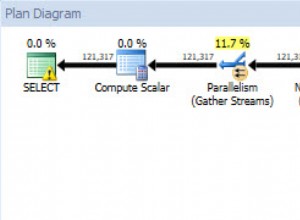
Potrzebujesz odrębnego identyfikatora wiersza w pierwszej tabeli — być może jest wśród innych kolumn. Może to być jedna lub więcej kolumn. Następnie możesz użyć count(distinct) :
select tree_id,
count(distinct <unique row column>) filter (where count_if_true)
from t
group by tree_id;