W tym artykule skupimy się na wykorzystaniu JOIN. Zaczniemy od porozmawiania o tym, jak będą miały miejsce JOIN i dlaczego musisz JOIN dane. Następnie przyjrzymy się dostępnym rodzajom JOIN i sposobom ich użycia.
PODSTAWY DOŁĄCZENIA
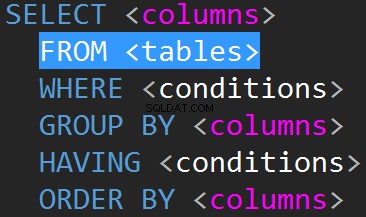
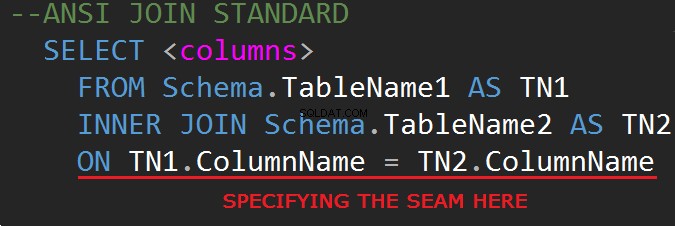
JOIN w TSQL są zazwyczaj wykonywane w linii FROM.
Zanim przejdziemy do czegokolwiek innego, naprawdę wielkie pytanie brzmi:„Dlaczego musimy wykonywać JOIN i jak faktycznie zamierzamy wykonać nasze JOIN?”
Jak się okazuje, każda baza danych, z którą kiedykolwiek pracujemy, będzie miała swoje dane podzielone na wiele tabel. Istnieje wiele różnych przyczyn takiego stanu rzeczy:
- Utrzymanie integralności danych
- Oszczędzanie przechowywanego miejsca
- Szybsza edycja danych
- Zwiększanie elastyczności zapytań
W związku z tym każda baza danych, z którą będziesz pracować, będzie wymagała połączenia tych danych, aby rzeczywiście miały sens.
Na przykład masz osobne tabele dla zamówień i dla klientów. Pytanie, które staje się — „Jak właściwie połączyć wszystkie dane razem?” To jest dokładnie to, co zrobią JOIN.
JAK DZIAŁAJĄ ŁĄCZENIA
Wyobraź sobie przypadek, w którym mamy dwa oddzielne stoły i te stoły zostaną połączone przez utworzenie szwu.
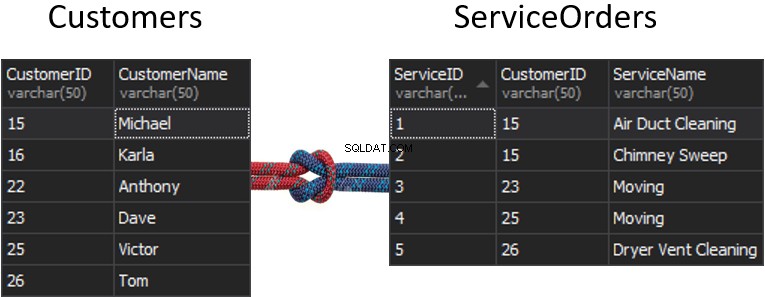
Co się stanie ze szwem, jeśli z każdej tabeli otrzymamy jedną kolumnę, która będzie używana do dopasowania i która określi, które wiersze zostaną zwrócone, a które nie? Na przykład po lewej stronie mamy Klientów, a po prawej ServiceOrders. Jeśli chcemy pozyskać wszystkich klientów i ich zamówienia, musimy POŁĄCZYĆ te dwa stoły razem. W tym celu musimy wybrać jedną kolumnę, która będzie działać jako szew, i oczywiście kolumna, której będziemy używać, to CustomerID.
Nawiasem mówiąc, CustomerID jest znany jako klucz podstawowy dla lewej tabeli, która jednoznacznie identyfikuje każdy wiersz w tabeli Klienci.
W tabeli ServiceOrders mamy również kolumnę CustomerID, znaną jako Klucz obcy . Klucz obcy to po prostu kolumna, która ma wskazywać na inną tabelę. W naszym przypadku jest to powrót do tabeli Klienci. Dlatego właśnie w ten sposób połączymy wszystkie te dane, zapewniając ten szew.
W tych tabelach mamy następujące dopasowania:2 zamówienia na 15 i 1 na 23, 25 i 26. 16 i 22 zostały pominięte.
Ważną rzeczą, na którą należy zwrócić uwagę, jest to, że możemy DOŁĄCZYĆ do wielu stołów . W rzeczywistości dość często łączy się kilka tabel razem, aby uzyskać dowolną formę informacji. Jeśli spojrzysz na najpopularniejszą bazę danych, być może będziesz musiał POŁĄCZYĆ cztery, pięć, sześć i więcej tabel tylko po to, aby uzyskać informacje, których szukasz. Posiadanie diagramu bazy danych będzie pomocne.
Aby pomóc Ci w większości środowisk baz danych, zauważysz, że kolumny przeznaczone do łączenia mają tę samą nazwę.
DOŁĄCZ SKŁADNIA
Trzecia wersja języka zapytań bazy danych SQL (SQL-92) reguluje składnię JOIN:
Możliwe jest wykonanie JOIN na linii GDZIE:
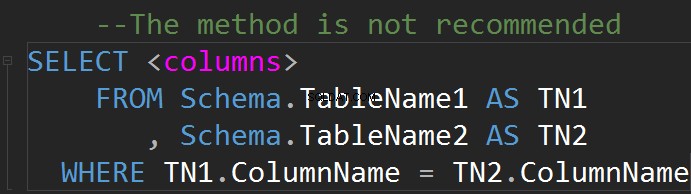
Relacja ma zwykle prostą interpretację graficzną w postaci tabeli.
Najlepsze praktyki i konwencje
- Aliasy nazw tabel.
- Użyj dwuczęściowego nazewnictwa dla kolumn
- Umieść każde złącze JOIN w osobnym wierszu
- Umieszczaj tabele w logicznej kolejności
TYPY DOŁĄCZENIA
SQL Server udostępnia następujące typy sprzężeń:
- DOŁĄCZENIE WEWNĘTRZNE
- ZŁĄCZENIE ZEWNĘTRZNE
- SAMO DOŁĄCZ
- POŁĄCZENIE KRZYŻOWE
Aby uzyskać więcej informacji na ten temat, zapoznaj się z tym artykułem o typach złączeń w SQL Server i dowiedz się, jak łatwo jest pisać takie zapytania za pomocą SQL Complete.
DOŁĄCZENIE WEWNĘTRZNE
Pierwszym typem JOIN, który możemy chcieć wykonać, jest INNER JOIN. Zazwyczaj autorzy odnoszą się do tego typu sprzężeń SQL Server JOIN jako zwykłe lub proste JOIN. Po prostu pomijają prefiks INNER. Ten typ JOIN łączy ze sobą dwie tabele i zwraca tylko pasujące wiersze z obu stron .
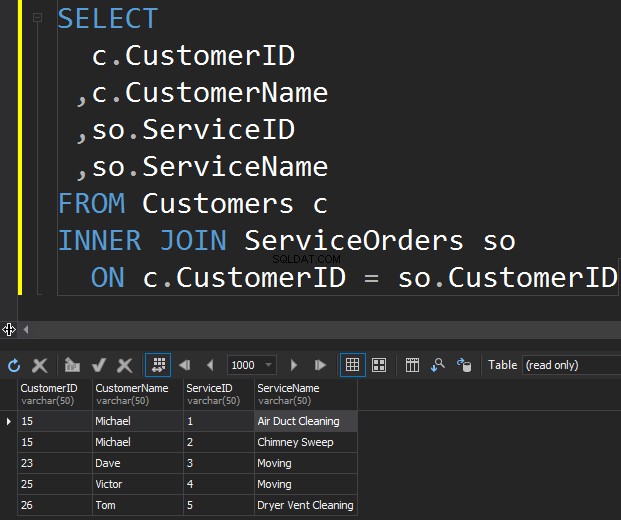
Nie widzimy tutaj Klary i Anthony'ego, ponieważ ich identyfikator klienta nie pasuje w obu tabelach. Chcę również podkreślić fakt, że operacja JOIN zwraca klienta za każdym razem, gdy pasuje do zamówienia . Są dwa zamówienia dla Michaela i jedno dla Dave'a, Victora i Toma.
Podsumowanie:
- INNER JOIN zwraca wiersze tylko wtedy, gdy w obu tabelach jest co najmniej jeden wiersz, który pasuje do warunku JOIN.
- INNER JOIN eliminuje wiersze, które nie pasują do wiersza z innej tabeli
POŁĄCZENIE ZEWNĘTRZNE
Zewnętrzne sprzężenia różnią się, ponieważ zwracają wiersze z tabel lub widoków, nawet jeśli nie są zgodne. Ten rodzaj JOIN jest przydatny, jeśli chcesz odzyskać wszystkich klientów, którzy nigdy nie złożyli zamówienia. Lub na przykład, jeśli szukasz produktu, który nigdy nie był zamawiany.
Sposób, w jaki wykonujemy nasze ZŁĄCZENIA ZEWNĘTRZNE, polega na wskazaniu LEWEJ, PRAWEJ lub PEŁNEJ.
Nie ma różnic między następującymi klauzulami:
- LEWE DOŁĄCZENIE ZEWNĘTRZNE =LEWE DOŁĄCZENIE
- PRAWY DOŁĄCZENIE ZEWNĘTRZNE =PRAWE DOŁĄCZENIE
- PEŁNE DOŁĄCZENIE ZEWNĘTRZNE =PEŁNE DOŁĄCZENIE
Zalecam jednak napisanie pełnej klauzuli, ponieważ dzięki temu kod jest bardziej czytelny.
Korzystanie z LEWEJ POŁĄCZENIA ZEWNĘTRZNEGO
Nie ma różnicy między LEFT a RIGHT, z wyjątkiem tego, że po prostu wskazujemy tabelę, z której chcemy uzyskać dodatkowe wiersze. W poniższym przykładzie wymieniliśmy klientów i ich zamówienia. Używamy LEWEJ, aby uzyskać wszystkich klientów, którzy nigdy nie złożyli zamówień. Prosimy SQL Server o pobranie nam dodatkowych wierszy z lewej tabeli.
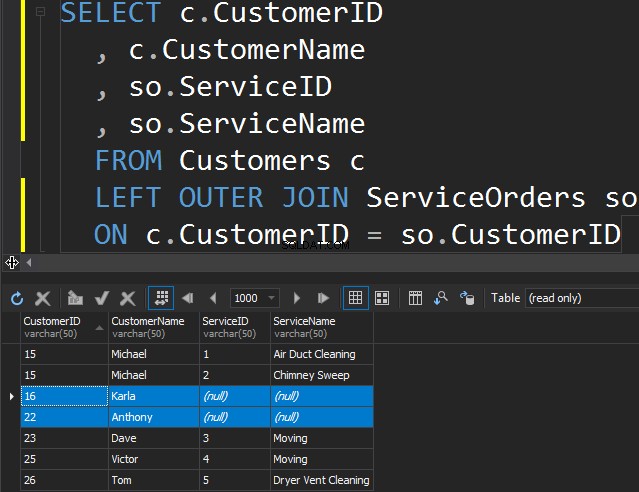
Zauważ, że Karla i Anthony nie złożyli żadnych zamówień, w wyniku czego otrzymujemy wartości NULL dla ServiceName i ServiceID. SQL Server nie wie, co tam umieścić i umieszcza wartości NULL.
Korzystanie z PRAWEGO ZŁĄCZENIA ZEWNĘTRZNEGO
Aby uzyskać mniej popularną usługę z tabeli ServiceOrders, musimy wybrać WŁAŚCIWY kierunek.
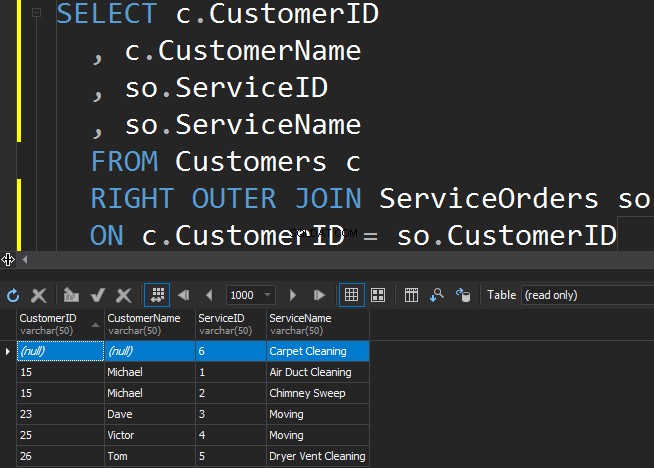
Widzimy, że w tym przypadku SQL Server zwrócił dodatkowe wiersze z właściwej tabeli, a usługa czyszczenia dywanów nigdy nie została zamówiona.
Korzystanie z FULL OUTER JOIN
Ten typ JOIN umożliwia uzyskanie niepasujących informacji poprzez uwzględnienie niepasujących wierszy z obu tabel.
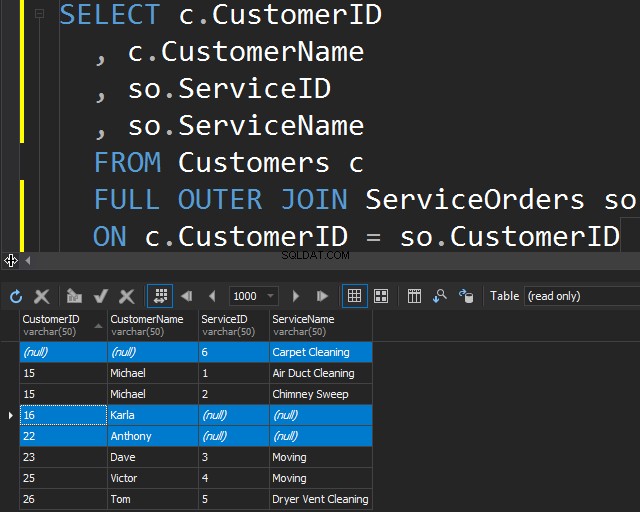
Może to być również przydatne, jeśli chcesz wyczyścić dane.
Podsumowanie:
PEŁNE ZŁĄCZENIE ZEWNĘTRZNE
- Zwraca wiersze z obu tabel, nawet jeśli nie pasują do instrukcji JOIN
LEWO lub PRAWO
- Bez różnicy z wyjątkiem kolejności tabel w klauzuli FROM
- Kierunek wskazuje tabelę, z której pobierają niepasujące wiersze
SAMO DOŁĄCZ
Kolejnym typem JOIN, który mamy, jest SELF JOIN. Jest to prawdopodobnie drugi najmniej powszechny typ JOIN, jaki kiedykolwiek wykonasz. SELF JOIN ma miejsce, gdy dołączasz do stołu. Ogólnie rzecz biorąc, jest to oznaka złego projektu. Aby użyć tej samej tabeli dwukrotnie w jednym zapytaniu, tabela musi mieć alias. Alias pomaga procesorowi zapytań określić, czy kolumny powinny przedstawiać dane z prawej, czy z lewej strony. Dodatkowo musisz eliminować same maszerujące rzędy. Odbywa się to zwykle za pomocą złączenia nierównego.
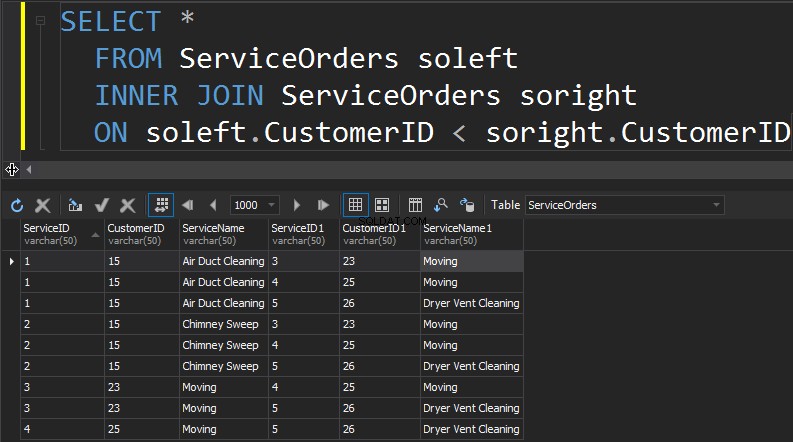
Podsumowanie:
- Dołącza do siebie tabelę
- Ogólnie oznaka złego projektu i normalizacji
- Tabele muszą mieć aliasy
- Trzeba filtrować wiersze pasujące do siebie
POŁĄCZENIA KRZYŻOWE
Ten typ JOIN nie ma WŁ oświadczenie. Każdy wiersz z każdego stołu będzie pasował. Jest to również znane jako produkt kartezjański (w przypadku, gdy CROSS JOIN nie zawiera klauzuli WHERE). Rzadko będziesz używać tego typu JOIN w rzeczywistych scenariuszach, jednak jest to dobry sposób na generowanie danych testowych.
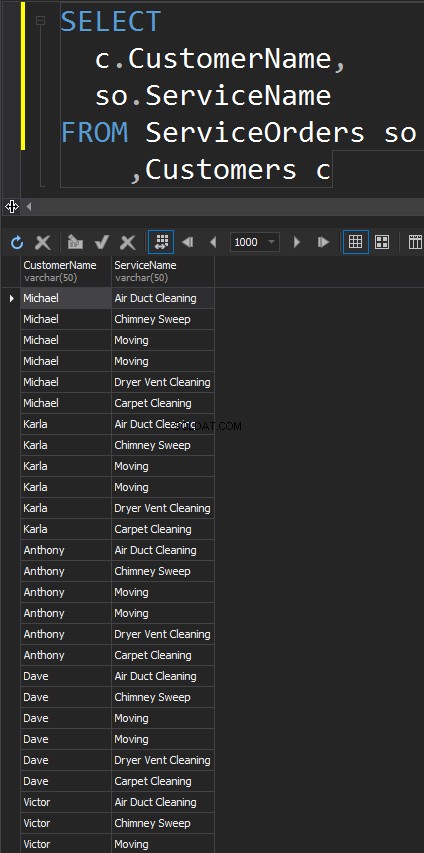
Wynikiem jest zbiór danych, w którym liczba wierszy w lewej tabeli pomnożona przez liczbę wierszy w prawej tabeli. Ostatecznie widzimy, że każdy klient pasuje do każdej usługi.
Ten sam wynik otrzymujemy, gdy jawnie używamy klauzuli CROSS JOIN.
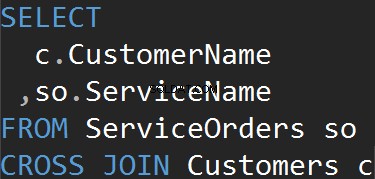
Podsumowanie:
- Wszystkie wiersze pasują do każdej tabeli
- Brak oświadczenia ON
- Może być używany do generowania danych testowych
ALGORYTMY ŁĄCZENIA
W pierwszej części artykułu omówiliśmy logiczne Operatory JOIN, których SQL Server używa podczas analizowania i wiązania zapytań. Są to:
- DOŁĄCZENIE WEWNĘTRZNE
- ZŁĄCZENIE ZEWNĘTRZNE
- POŁĄCZENIE KRZYŻOWE
Operatory logiczne są koncepcyjne i różnią się od fizycznych ŁĄCZENIA. Inaczej mówiąc, logiczne JOIN w rzeczywistości nie dołączają poszczególne kolumny tabeli. Pojedyncze logiczne JOIN może odpowiadać wielu fizycznym JOIN. Podczas optymalizacji SQL Server zastępuje logiczne JOIN na fizyczne JOIN. SQL Server ma następujące fizyczne operatory JOIN:
- PĘTLA ZAGĘSZCZONA
- POŁĄCZ
- HASZ
Użytkownik nie zapisuje ani nie używa tych typów sprzężeń. Są one częścią silnika SQL Server i SQL Server używa ich wewnętrznie do implementacji logicznych sprzężeń. Podczas eksploracji planu wykonania można zauważyć, że SQL Server zastępuje logiczne operatory JOIN jednym z trzech operatorów fizycznych.
Zagnieżdżone łączenie pętli
Zacznijmy od najprostszego operatora, jakim jest zagnieżdżona pętla. Algorytm porównuje każdy wiersz jednej tabeli (tabela zewnętrzna) z każdym wierszem drugiej tabeli (tabela wewnętrzna), szukając wierszy spełniających predykat JOIN.
Poniższy pseudokod opisuje wewnętrzny algorytm zagnieżdżonej pętli sprzężenia:

Poniższy pseudokod opisuje zewnętrzny algorytm zagnieżdżonej pętli sprzężenia:
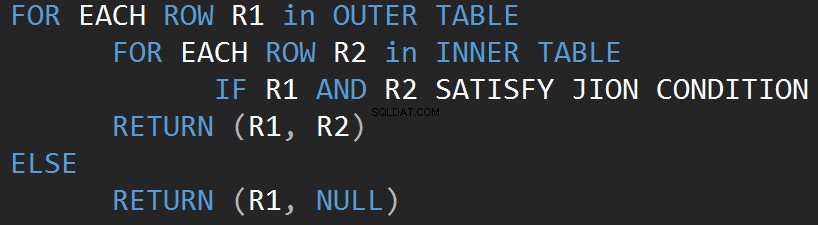
Wielkość danych wejściowych bezpośrednio wpływa na koszt algorytmu. Nakłady rosną, koszty również rosną. Ten rodzaj algorytmu JOIN jest wydajny w przypadku małych danych wejściowych. SQL Server szacuje predykat JOIN dla każdego wiersza w obu danych wejściowych.
Rozważ następujące zapytanie jako przykład, które pozwala uzyskać klientów i ich zamówienia.
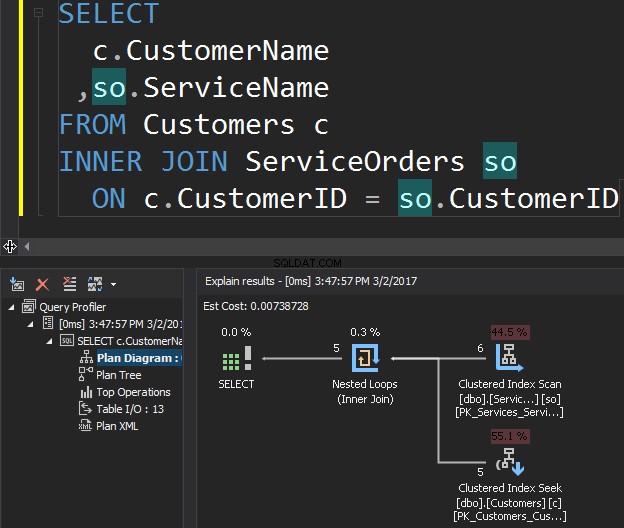
Operator klastrowego skanowania indeksu jest zewnętrznym wejściem a wyszukiwanie indeksu klastrowego jest wewnętrznym wejściem . Operator zagnieżdżonej pętli faktycznie znajduje dopasowanie. Operator szuka każdego rekordu w zewnętrznych danych wejściowych i znajduje pasujące wiersze w wewnętrznych danych wejściowych. SQL Server wykonuje operację klastrowego skanowania indeksu (wejście zewnętrzne) tylko raz, aby uzyskać wszystkie odpowiednie rekordy. Clustered Index Seek jest wykonywane dla każdego rekordu z zewnętrznych danych wejściowych. Aby to potwierdzić, najedź kursorem na ikonę operatora i sprawdź podpowiedź.
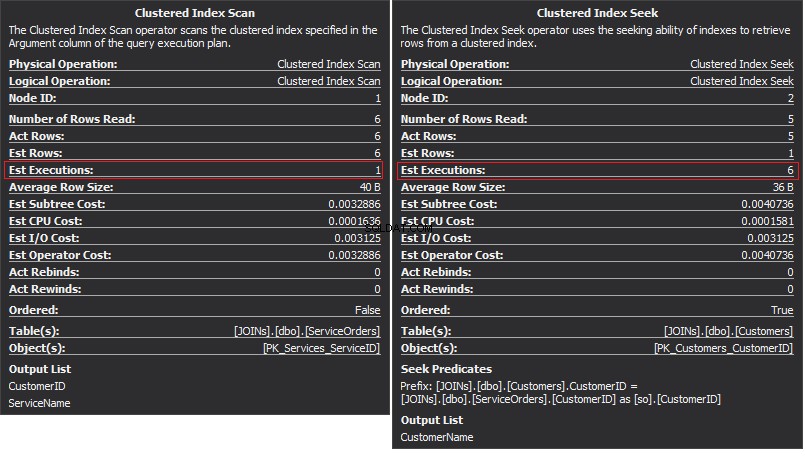
Porozmawiajmy o złożoności. Załóżmy, że N to numer wiersza dla wyjścia zewnętrznego. M to całkowita liczba wierszy w Zamówieniach sprzedaży stół. Zatem złożoność zapytania to O(NLogM) gdzie LogM jest złożoność każdego poszukiwania wewnętrznego wkładu. Optymalizator wybierze ten operator za każdym razem, gdy zewnętrzne dane wejściowe są małe, a wewnętrzne dane wejściowe zawierają indeks w kolumnie, która działa jak szew. Dlatego indeksy i statystyki są niezbędne dla tego typu JOIN, w przeciwnym razie SQL Server może przypadkowo pomyśleć, że w jednym z danych wejściowych nie ma zbyt wielu wierszy. Lepiej jest wykonać jedno skanowanie tabeli niż przeszukiwanie indeksu 100 tys. razy. Zwłaszcza, gdy wewnętrzny rozmiar danych wejściowych przekracza 100K.
Podsumowanie:
Zagnieżdżone pętle
- Złożoność:O(NlogM)
- Stosowane zwykle, gdy jeden stół jest mały
- Większa tabela zawiera indeks, który umożliwia wyszukiwanie jej za pomocą klawisza łączenia
Połącz, dołącz
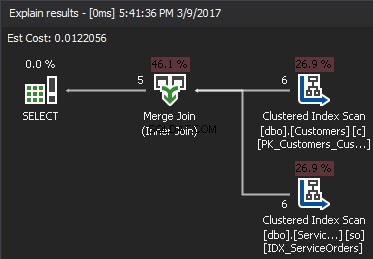
Niektórzy programiści nie rozumieją w pełni funkcji Hash i Merge JOIN i często kojarzą je ze słabymi zapytaniami.
W przeciwieństwie do pętli zagnieżdżonej, która akceptuje dowolny predykat JOIN, łączenie scalające wymaga co najmniej jednego złączenia equi. Dodatkowo oba wejścia muszą być posortowane według klawiszy JOIN.
Pseudokod algorytmu MERGE JOIN:
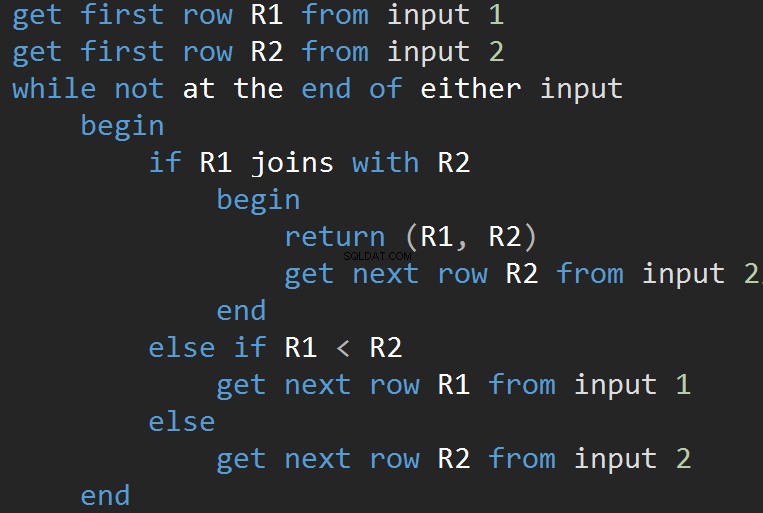
Algorytm porównuje dwa posortowane dane wejściowe. Jeden rząd na raz. W przypadku równości między dwoma wierszami, wyniki algorytmu łączą wiersze i kontynuują. Jeśli nie, algorytm odrzuca mniejsze z dwóch danych wejściowych i kontynuuje. W przeciwieństwie do pętli zagnieżdżonej, koszt jest tutaj proporcjonalny do sumy liczby wierszy wejściowych. Pod względem złożoności – O(N+M). Dlatego ten typ sprzężeń jest często lepszy w przypadku dużych nakładów.
Poniższa animacja pokazuje, w jaki sposób algorytm MERGE JOIN faktycznie łączy wiersze tabeli.
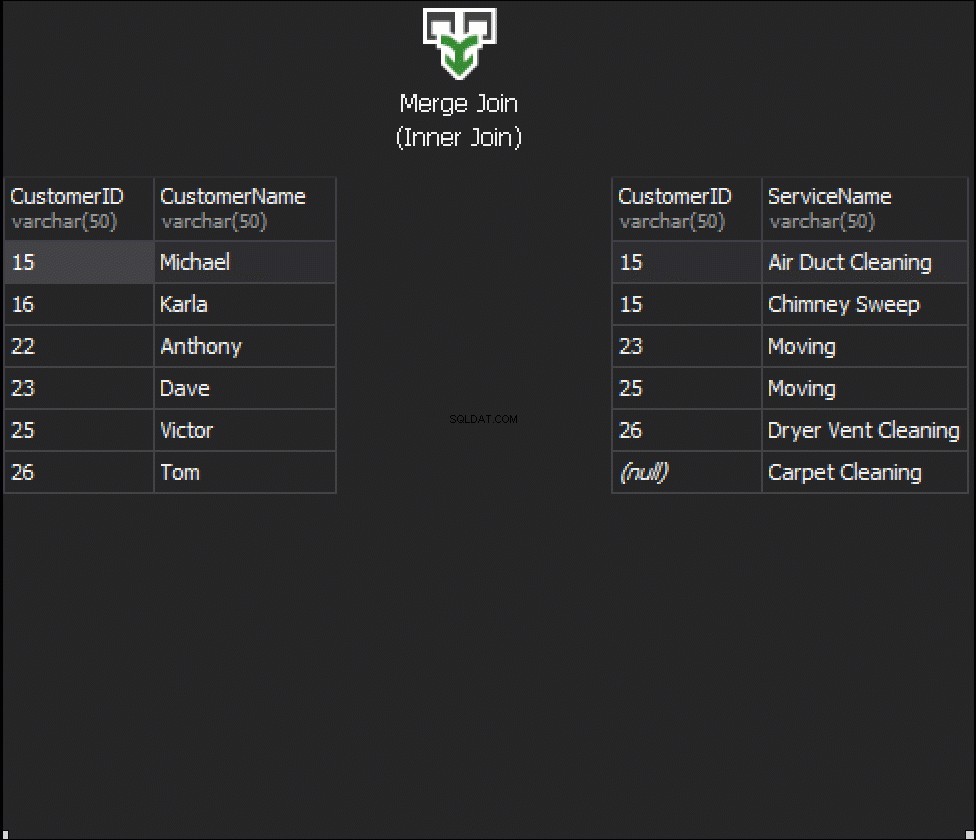
Podsumowanie
- Złożoność:O(N+M)
- Oba dane wejściowe muszą być posortowane według klucza łączenia
- Używany jest operator równości
- Doskonały do dużych stołów
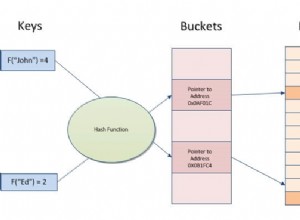
Dołącz haszujący
Hash Join doskonale nadaje się do dużych tabel bez użytecznego indeksu. W pierwszym kroku – faza budowania algorytm tworzy indeks skrótu w pamięci na wejściu po lewej stronie. Drugi etap nazywa się fazą sondy . Algorytm przechodzi przez dane wejściowe po prawej stronie i znajduje dopasowania przy użyciu indeksu utworzonego podczas fazy budowania. Prawdę mówiąc, nie jest to dobry znak, że optymalizator wybiera ten typ algorytmu JOIN.
Istnieją dwie ważne koncepcje leżące u podstaw tego typu sprzężeń:funkcja mieszająca i tablica mieszająca.
funkcja skrótu to dowolna funkcja, która może być używana do mapowania danych o zmiennym rozmiarze na dane o stałym rozmiarze.
tabela mieszająca to struktura danych używana do implementacji tablicy asocjacyjnej, struktury, która może mapować klucze na wartości. Tablica mieszająca wykorzystuje funkcję mieszającą do obliczenia indeksu w tablicy segmentów lub przedziałów, z których można znaleźć żądaną wartość.
Na podstawie dostępnych statystyk SQL Server wybiera najmniejsze dane wejściowe jako dane wejściowe kompilacji i używa ich do zbudowania tabeli mieszania w pamięci. Jeśli nie ma wystarczającej ilości pamięci, SQL Server używa miejsca na dysku fizycznym w TempDB. Po utworzeniu tabeli skrótów SQL Server pobiera dane z danych wejściowych sondy (większa tabela) i porównuje je z tabelą skrótów przy użyciu funkcji dopasowywania skrótów. W rezultacie zwraca dopasowane wiersze.
Jeśli spojrzymy na plan wykonania, prawym górnym elementem jest dane wejściowe kompilacji , a prawy dolny element to dane wejściowe sondy . W przypadku, gdy oba wejścia są bardzo duże, koszt jest zbyt wysoki.
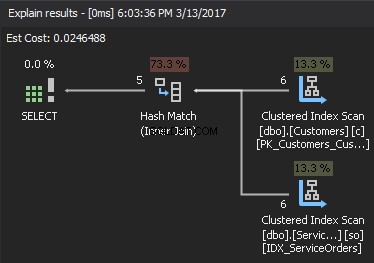
Aby oszacować złożoność, załóżmy, że:
hc – złożoność tworzenia tablicy mieszającej
hm – złożoność funkcji hash match
N – mniejszy stolik
M – większy stół
J – dodanie złożoności do dynamicznego obliczania i tworzenia funkcji skrótu
Złożoność będzie wyglądać następująco:O(N*hc + M*hm + J)
Optymalizator wykorzystuje statystyki do określenia liczności wartości. Następnie dynamicznie tworzy funkcję mieszającą, która dzieli dane na wiele wiader o równych rozmiarach. Często trudno jest oszacować złożoność procesu tworzenia tablicy mieszającej, a także złożoność każdego dopasowania mieszającego ze względu na dynamiczny charakter. Plan wykonania może nawet pokazywać nieprawidłowe oszacowania, ponieważ optymalizator wykonuje wszystkie te dynamiczne operacje w czasie wykonania. W niektórych przypadkach plan wykonania może wskazywać, że Nested Loop jest droższy niż Hash Join, ale w rzeczywistości Hash Join jest wykonywany wolniej z powodu nieprawidłowego oszacowania kosztów.
Podsumowanie
- Złożoność:O(N*hc +M*hm +J)
- Typ przyłączenia „ostatniej deski ratunku”
- Wykorzystuje tablicę mieszającą i funkcję dynamicznego dopasowywania mieszającego do dopasowywania wierszy
Przydatne produkty:
SQL Complete – napisz, upiększ, zrefaktoruj swój kod łatwo i zwiększ produktywność.