Indeksy haszujące są integralną częścią baz danych. Jeśli kiedykolwiek korzystałeś z bazy danych, prawdopodobnie widziałeś je w akcji, nawet nie zdając sobie z tego sprawy.
Indeksy mieszające różnią się w działaniu od innych typów indeksów, ponieważ przechowują wartości, a nie wskaźniki do rekordów znajdujących się na dysku. Zapewnia to szybsze wyszukiwanie i wstawianie do indeksu. Dlatego indeksy mieszające są często używane jako klucze podstawowe lub unikalne identyfikatory.
Zrozumienie indeksów haszujących
Indeks mieszający to typ indeksu najczęściej używany w zarządzaniu danymi. Zwykle jest tworzony w kolumnie zawierającej unikalne wartości, takie jak klucz podstawowy lub adres e-mail. Główną zaletą korzystania z indeksów mieszających jest ich szybka wydajność.
Koncepcja tych indeksów może być skomplikowana, aby zrozumieć ją dla kogoś, kto nigdy wcześniej o nich nie słyszał. Jednak zrozumienie indeksów mieszających jest ważne, jeśli chcesz zrozumieć, jak działają bazy danych. Jest niezbędny do rozwiązywania typowych problemów związanych z bazami danych i ich szybkością.
Dobrą wiadomością jest to, że przy odrobinie cierpliwości i wyłączonej komórce możesz na pewno opanować indeksy haszujące! Przyjrzyjmy się więc lepiej.
Szybko i łatwo
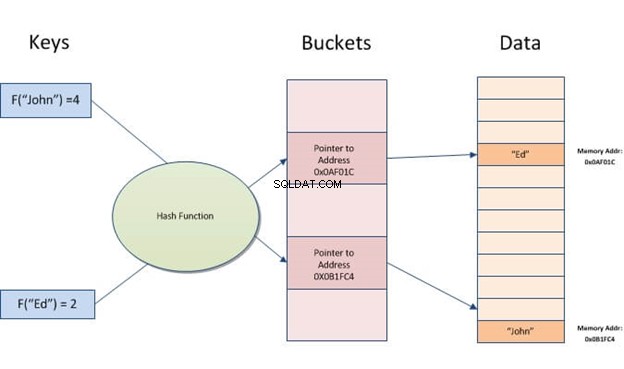
Indeks mieszający to struktura danych, której można użyć do przyspieszenia zapytań do bazy danych. Działa poprzez konwersję rekordów wejściowych na tablicę wiader. Każdy segment ma taką samą liczbę rekordów jak wszystkie inne segmenty w tabeli. Dlatego bez względu na to, ile różnych wartości masz dla danej kolumny, każdy wiersz zawsze będzie mapowany do jednego zasobnika.
Indeksy haszujące pozwalają na szybkie wyszukiwanie danych przechowywanych w tabelach. Działają, tworząc klucz indeksu z wartości, a następnie lokalizując go na podstawie wynikowego skrótu. Jest to przydatne, gdy istnieje wiele danych wejściowych o podobnych wartościach lub duplikatach, ponieważ wystarczy porównać klucze zamiast przeglądać wszystkie rekordy.
Czy nie było to ani szybkie, ani łatwe? Aby zrozumieć, jak działają indeksy haszujące i dlaczego są tak potężne, musisz zrozumieć, co oznacza haszowanie.
Hashowanie bierze kawałek informacji (ciąg) i przekształca go w adres lub wskaźnik, aby później uzyskać szybki dostęp.
Pomysł z haszowaniem polega na tym, że do danych przypisywana jest niewielka liczba. Kiedy przeglądasz dane, nie musisz przesiewać mas. Zamiast tego po prostu wyszukaj ten jeden numer. Najprostszym przykładem jest Ctrl+F-wpisanie słowa, którego szukasz w tekście, zamiast samodzielnego czytania dziesiątek stron.
Do czego służą indeksy haszujące?
Indeks skrótu to sposób na przyspieszenie procesu wyszukiwania. W przypadku tradycyjnych indeksów musisz przejrzeć każdy wiersz, aby upewnić się, że Twoje zapytanie się powiedzie. Ale w przypadku indeksów mieszających tak nie jest!
Każdy klucz indeksu zawiera tylko jeden wiersz danych tabeli i używa algorytmu indeksowania zwanego haszowaniem co przypisuje im unikalną lokalizację w pamięci, eliminując wszystkie inne klucze ze zduplikowanymi wartościami przed znalezieniem tego, czego szuka.
Indeksy mieszające to jeden z wielu sposobów organizowania danych w bazie danych. Działają, pobierając dane wejściowe i używając ich jako klucza do przechowywania na dysku. Te klucze lub wartości skrótu , może być dowolna, od długości łańcucha do znaków na wejściu.
Indeksy mieszające są najczęściej używane podczas wykonywania zapytań o określone dane wejściowe z określonymi atrybutami. Na przykład może to być znalezienie wszystkich liter A, które są wyższe niż 10 cm. Możesz to zrobić szybko, tworząc funkcję indeksu mieszającego.
Indeksy haszujące są częścią systemu bazodanowego PostgreSQL. Ten system został opracowany w celu zwiększenia szybkości i wydajności. Indeksy haszujące mogą być używane w połączeniu z innymi typami indeksów, takimi jak B-tree lub GiST.
Indeks skrótów przechowuje klucze, dzieląc je na mniejsze porcje zwane wiaderkami, gdzie każdemu wiaderkowi przypisywany jest numer identyfikacyjny, który umożliwia szybkie pobranie go podczas wyszukiwania lokalizacji klucza w tabeli skrótów. Zasobniki są przechowywane sekwencyjnie na dysku, dzięki czemu można szybko uzyskać dostęp do zawartych w nich danych.
Więcej wyjaśnień technicznych można znaleźć na tej stronie (kliknij prawym przyciskiem myszy i wybierz „Przetłumacz na angielski”).
Zalety
Główną zaletą korzystania z indeksów mieszających jest to, że umożliwiają szybki dostęp podczas pobierania rekordu według wartości klucza. Często przydaje się w przypadku zapytań z warunkiem równości. Ponadto użycie testów porównawczych hash nie wymaga dużo miejsca do przechowywania. Jest to zatem skuteczne narzędzie, ale nie pozbawione wad.
Wady
Indeksy mieszające to stosunkowo nowa struktura indeksowania, która może zapewnić znaczne korzyści w zakresie wydajności. Możesz myśleć o nich jako o rozszerzeniu binarnych drzew wyszukiwania (BST).
Indeksy haszujące działają poprzez przechowywanie danych w zasobnikach na podstawie ich wartości hash, co pozwala na szybkie i wydajne pobieranie danych. Gwarantujemy, że są w porządku.
Jednak niemożliwe jest przechowywanie zduplikowanych kluczy w zasobniku. Dlatego zawsze będzie trochę narzutu. Ale jak dotąd zalety korzystania z indeksów mieszających przeważają nad wadami.
Jak to wszystko działa w nieco większej głębi?
Zróbmy demo aviasales bazy danych, aby uzyskać bardziej dogłębne zrozumienie działania indeksów mieszających.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Tutaj możesz zobaczyć, jak wdrażamy indeksy haszujące, kompilując dane w zestawy.
To prosty przykład, ale pamiętaj, że ograniczenia wiążą się z mniejszą infrastrukturą kodu. Może wystąpić brak dostępu do dziennika WAL lub niemożność odzyskania indeksów (indeksów?) po awarii. Poza tym indeksy mogą nie brać udziału w replikacji – jest to spowodowane nieaktualnością PostgreSQL. Jednak, podobnie jak w Pythonie, otrzymujesz ostrzeżenia, które często pozwalają uniknąć błędów.
Możesz zajrzeć głębiej w te indeksy, jeśli jesteś wystarczająco zaintrygowany. W tym celu tworzymy kontrolę strony instancja rozszerzenia.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Jeśli chcesz dokładnie sprawdzić kod, zacznij od README.
Podsumowanie
Indeksy haszujące to struktura danych, która przyspiesza proces wyszukiwania informacji w dużych bazach danych. Działają, dzieląc dane na mniejsze porcje, a następnie je sortując. Dzięki temu, gdy czegoś szukasz, możesz to znaleźć znacznie szybciej.
Jeśli chcesz znaleźć więcej rzeczy, DYOR ma do dyspozycji zasoby. Miej też oko na nasze nowe artykuły, które wychodzą szybciej niż możesz Ctrl+F słowo „hasz” na tej stronie. Mam nadzieję, że to pomoże!