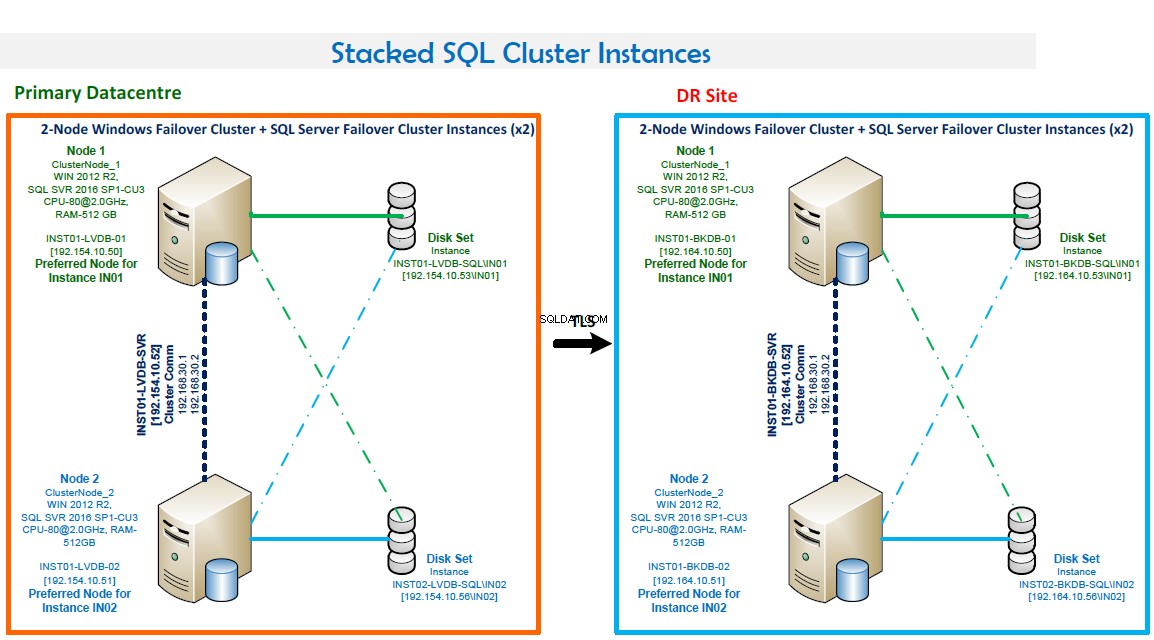
UWAGI:
- Klaster pracy awaryjnej Windows składający się z dwóch węzłów.
- Dwa wystąpienia klastra trybu failover programu SQL Server. Ta konfiguracja optymalizuje sprzęt. IN01 jest preferowany w węźle 1, a IN02 jest preferowany w węźle 2.
- Numery portów:IN01 nasłuchuje na porcie 1435, a IN02 nasłuchuje na porcie 1436.
- Wysoka dostępność. Oba węzły tworzą kopie zapasowe. Przełączanie awaryjne jest automatyczne w przypadku awarii.
- Tryb kworum to większość węzłów i dysków.
- Utwórz kopię zapasową sieci LAN i rutynową kopię zapasową skonfigurowaną za pomocą Veritas
Wprowadzenie
Nierzadko zdarza się, że programiści i kierownicy projektów domagają się nowej instancji SQL Server dla każdej nowej aplikacji lub usługi. Podczas gdy technologie takie jak wirtualizacja i chmura sprawiły, że uruchamianie nowych instancji jest dziecinnie proste, niektóre odwieczne techniki wbudowane w SQL Server umożliwiają uzyskanie krótkich czasów realizacji, gdy istnieje potrzeba udostępnienia nowej bazy danych dla nowej usługi lub aplikacji. Taki stan rzeczy może stworzyć administrator, który może zaprojektować i wdrożyć duży klaster SQL Server zdolny do obsługi większości baz danych SQL Server wymaganych przez organizację. Ten rodzaj konsolidacji ma dodatkowe zalety, takie jak niższe koszty licencji, lepsze zarządzanie i łatwość administrowania. W artykule zwrócimy uwagę na niektóre kwestie, które mieliśmy okazję doświadczyć podczas korzystania z klastrów i stosów jako środków do konsolidacji baz danych SQL Server.
Klastrowanie
Windows Server Failover Clustering to bardzo dobrze znane rozwiązanie wysokiej dostępności, które przetrwało wiele wersji systemu Windows Server i w które firma Microsoft zamierza nadal inwestować i ulepszać. Wystąpienia klastra pracy awaryjnej programu SQL Server opierają się na WSFC. Zarówno wersje Standard, jak i Enterprise programu SQL Server obsługują wystąpienia klastra trybu failover programu SQL Server, ale wersja Standard Edition jest ograniczona tylko do dwóch węzłów. Konsolidacja baz danych na pojedynczym SQL Server FCI daje takie korzyści, jak:
- HA domyślnie — Wszystkie bazy danych wdrożone w klastrowanej instancji SQL Server są domyślnie wysoce dostępne! Po zbudowaniu instancji klastrowanej, nowe wdrożenia są obsługiwane pod kątem HA z wyprzedzeniem.
- Łatwość administracji – Mniej administratorów baz danych może poświęcać czas na konfigurowanie, monitorowanie i, w razie potrzeby, rozwiązywanie problemów z JEDNYM wystąpieniem w klastrze obsługującym wiele aplikacji. Prawidłowe dokumentowanie instancji jest również znacznie łatwiejsze w przypadku jednego dużego środowiska. Skonfigurowanie rozwiązania Enterprise Backup do obsługi wszystkich baz danych w Twoim środowisku jest łatwiejsze dzięki temu, że w przypadku korzystania ze skonsolidowanych instancji musisz wykonać tę konfigurację tylko jedną.
- Zgodność – Takie kluczowe wymagania, jak łatanie, a nawet utwardzanie, można wykonać raz przy minimalnym przestoju dużej liczby baz danych w ramach jednego wysiłku administracyjnego. W naszym sklepie wykorzystaliśmy przesyłanie dziennika transakcji między klastrowymi instancjami w dwóch centrach danych, aby zapewnić ochronę baz danych przed ryzykiem katastrof.
- Standardyzacja – Egzekwowanie takich standardów, jak konwencje nazewnictwa, zarządzanie dostępem, uwierzytelnianie Windows, audyty i zarządzanie oparte na zasadach jest znacznie łatwiejsze, gdy mamy do czynienia z jednym lub dwoma środowiskami w zależności od wielkości sklepu
Lista 1: Wyodrębnij informacje o swojej instancji
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Układanie
SQL Server obsługuje do pięćdziesięciu pojedynczych wystąpień na jednym serwerze i do 25 wystąpień klastra pracy awaryjnej w klastrze pracy awaryjnej systemu Windows Server. Różne wersje programu SQL Server można łączyć w stos w tym samym środowisku, aby zapewnić niezawodne środowisko, które będzie obsługiwać różne aplikacje. W takiej konfiguracji uaktualnianie baz danych może przybrać formę prostego promowania ich z jednej instancji SQL Server do kolejnej wersji w tym samym klastrze, aż do starzenia się sprzętu. Jedną z kluczowych kwestii, o których należy pamiętać podczas układania SQL Server w stos, jest to, że należy przydzielić pamięć do każdej instancji w taki sposób, aby całkowita ilość przydzielonej pamięci nie przekroczyła pamięci dostępnej w systemie operacyjnym. Drugim punktem w tym kierunku jest zapewnienie, że konto usługi SQL Server dla każdej instancji musi mieć strony blokady w uprawnieniach pamięci. Przypisanie zablokowanych stron w pamięci zapewnia, że gdy SQL Server pozyska pamięć, system operacyjny nie będzie próbował odzyskać takiej pamięci, gdy inne procesy na serwerze potrzebują pamięci. Skonfigurowanie zdefiniowanego konta usługi SQL Server, skonfigurowanie MAX_SERVER_MEMORY i przyznanie uprawnień Zablokuj strony w pamięci to niezbędne trio podczas układania instancji SQL Server w stos.
Microsoft pobiera kilka tysięcy dolarów za parę rdzeni procesora. Zestawienie instancji SQL Server w stos pozwala wykorzystać ten model licencjonowania, ponieważ instancje współużytkują ten sam zestaw procesorów (pocenie się zasobu). Wspomnieliśmy już, że można układać różne wersje SQL Server, dzięki czemu można zadbać o starsze aplikacje, które nadal działają w wersjach starszych niż na przykład SQL Server 2016. Korzystając z różnych wersji programu SQL Server, warto rozważyć użycie powinowactwa procesora zgodnie z opisem Glena Berry'ego w tym artykule. Koligacja procesora może być również używana do kontrolowania sposobu współdzielenia zasobów procesora między instancjami, tak jak kontrolujesz pamięć. Układanie w stos rozwiązuje również problemy związane z bezpieczeństwem aplikacji, które muszą na przykład korzystać z konta SA, lub problemy z konfiguracją dla aplikacji, które wymagają dedykowanego wystąpienia, lub takie opcje są określonym sortowaniem. Troska o wydajność współdzielonej bazy danych TempDB to kolejny powód, dla którego możesz chcieć łączyć wszystkie bazy danych w stos, zamiast gromadzić je w jednej instancji klastrowanej.
Warto zauważyć, że wartość grupowania, jak podkreślono wcześniej, rozszerza się jeszcze bardziej wraz ze stosowaniem. Na przykład, podczas łatania instancji SQL Server z kilkoma FCI, wszystkie FCI można załatać za jednym razem.
Wskazuje na uwagę
W przypadku korzystania z klastrów pewne konwencje nieco ułatwią administrowanie i zarządzanie środowiskiem oraz usprawnią pracę nad zasobami. Pokrótce omówimy kilka z nich:
- Aktualne narzędzia klienta — podczas próby zarządzania instancją programu SQL Server 2016 za pomocą programu SQL Server Management Studio 2012 mogą wystąpić nietypowe błędy. Błędy nie informują konkretnie, że problem dotyczy wersji narzędzia klienta. Zazwyczaj mamy instancję SQL Server Management Studio 17.3 na kliencie, którego chcemy użyć do połączenia z naszymi instancjami.
- Konwencje nazewnictwa — Konwencja nazewnictwa ułatwia upewnienie się, nad którą instancją pracujesz w dowolnym momencie. Używając aliasów, możesz jeszcze bardziej zmniejszyć obciążenie związane z zapamiętywaniem długiej nazwy instancji dla użytkowników końcowych, którzy potrzebują dostępu do bazy danych.
- Preferowany węzeł — ustawienie preferowanego węzła dla każdej roli SQL Server w Menedżerze klastra pracy awaryjnej to dobry pomysł, dobry sposób na zapewnienie wykorzystania mocy obliczeniowej wszystkich węzłów klastra. W naszym sklepie, po skonfigurowaniu preferowanych węzłów, skonfigurowaliśmy rolę do powrotu po awarii między 0500 HRS a 0600 HRS w przypadku nieumyślnego przełączenia.
- Wysyłanie dziennika transakcji — podczas konfigurowania odzyskiwania po awarii dla FCI sensowne jest identyfikowanie wszystkich ścieżek UNC przy użyciu nazw wirtualnych, a nie nazw lub adresów IP węzłów klastra. Gwarantuje to, że rzeczy będą nadal działać poprawnie, jeśli nastąpi przełączenie awaryjne. Bardzo ważne jest również upewnienie się, że konta agentów SQL Server w obu witrynach mają pełną kontrolę nad tymi ścieżkami.
Lista 2: Konfiguruj monitorowanie wysyłania dziennika transakcji za pomocą poczty e-mail
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Dyski dyskowe
Jednym skutkiem ubocznym układania instancji SQL Server w stos i zapewniania obsługi kilku baz danych jest tendencja do wyczerpywania się liter dysków. Obeszliśmy ten problem, konfigurując punkty montowania woluminów. Każdy dysk przypisany do roli klastra jest skonfigurowany jako punkt instalacji z literą dysku potrzebną tylko dla jednego lub dwóch dysków na wystąpienie. Ważną kwestią, na którą należy zwrócić uwagę podczas korzystania z punktów montowania woluminów w klastrze, jest to, że w przyszłości, gdy będziesz musiał dodać więcej punktów montowania, aby wykonać podobne zadania konserwacyjne, konieczne będzie umieszczenie ZARÓWNO głównego dysku, który jest właścicielem litery dysku, jak i montowania punkt w trybie konserwacji w klastrze.
W naszym przypadku znaleźliśmy nazwę każdego punktu montażu woluminu w oparciu o rolę klastra, do której został przypisany. Przy tak wielu dyskach, z którymi musisz sobie poradzić, zdecydowanie będziesz musiał wypracować sposób, aby zarówno Ty, jak i administrator pamięci masowej zidentyfikowali unikalny dysk, tak aby na przykład utrzymanie dysków na poziomie pamięci nie było dużym problemem.
Lista 3: Monitoruj wykorzystanie miejsca na dysku podczas korzystania z punktów montowania woluminów
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Wdrażanie bazy danych
W naszym przypadku naszą strategią było zapewnienie, że nowe bazy danych będą zgodne z naszym standardem. Starsze bazy danych były traktowane z nieco większą ostrożnością, ponieważ w pewnym sensie konsolidowaliśmy i aktualizowaliśmy w tym samym czasie. Asystent migracji bazy danych pomógł nam powiedzieć, które bazy danych na pewno nie będą kompatybilne z naszą uświęconą instancją SQL Server 2016 i zostawiliśmy je w spokoju (niektóre z poziomami zgodności są tak niskie, jak 100). Każda wdrożona baza danych powinna mieć własne woluminy dla plików danych i dzienników, w zależności od jej rozmiaru. Używanie oddzielnych woluminów dla każdej bazy danych to kolejny krok w kierunku bardzo dobrze zorganizowanego środowiska, co jest ważne, biorąc pod uwagę potencjalną złożoność tego skonsolidowanego środowiska. Ostatnie stwierdzenie oznacza również, że kiedy zezwalasz aplikacji na tworzenie własnych baz danych, musisz jako administrator danych przenieść pliki danych po zakończeniu wdrożenia, ponieważ aplikacja będzie używać tych samych lokalizacji plików, które są używane przez modelową bazę danych.
Lista 4: Przenoszenie baz danych użytkowników
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Zarządzanie dostępem
Zgodzisz się, że w naszym skonsolidowanym środowisku możemy mieć bardzo długą listę obiektów na poziomie serwera, takich jak loginy. Korzystanie z grup systemu Windows pomoże skrócić tę listę i uprościć zarządzanie dostępem w każdej instancji klastrowanej. Zazwyczaj będziesz potrzebować grup utworzonych w Active Directory dla administratorów aplikacji, którzy potrzebują dostępu, kont usługi aplikacji, użytkowników biznesowych, którzy muszą pobierać raporty i oczywiście administratorów baz danych. Jedną z kluczowych korzyści wynikających z używania Grup systemu Windows jest to, że dostęp można przyznać lub cofnąć, po prostu zarządzając członkostwem w tych grupach bezpośrednio w Active Directory.
Jest już chyba oczywiste, że ta korzyść w obszarze zarządzania dostępem jest możliwa tylko z uwierzytelnianiem Windows. Logowaniami SQL Server nie można zarządzać w grupach.
Lista 5: Logowanie się do instancji, użytkownicy bazy danych i ich role
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Wniosek
Zbadaliśmy na bardzo wysokim poziomie korzyści, jakie można osiągnąć poprzez klastrowanie i układanie instancji SQL Server w stosy jako sposób na osiągnięcie konsolidacji, optymalizacji kosztów i łatwości zarządzania. Jeśli okaże się, że jesteś w stanie kupić duży sprzęt, możesz zapoznać się z tą opcją i czerpać korzyści, które opisaliśmy powyżej.