W tym artykule wyjaśnię proces instalacji SQL Server na instancji klastra pracy awaryjnej (FCI) na węźle podstawowym. Najpierw spójrzmy na wymagania wstępne.
Szczegóły maszyny wirtualnej:
W celach demonstracyjnych włączyłem rolę Hyper-V na mojej stacji roboczej i stworzyłem cztery maszyny wirtualne. Następnie zainstalowałem system Windows Server 2019 na tych maszynach wirtualnych. Oto szczegóły:
| Maszyna wirtualna | Nazwa hosta | Adres IP | Cel |
| Kontroler domeny | DC.Lokalne | 192.168.1.110 | Ta maszyna wirtualna będzie używana jako kontroler domeny. |
| SAN | SAN.DC.Lokalne | 192.168.1.111 | Ta maszyna wirtualna będzie używana jako wirtualna sieć SAN. Utworzyłem dwa wirtualne dyski iSCSI i używam inicjatora iSCSI; Podłączę je z węzłów klastra pracy awaryjnej. |
| Podstawowy węzeł SQL | SQL01.DC.Local | 192.168.1.112 | Na tej maszynie wirtualnej zainstalujemy wystąpienie klastra pracy awaryjnej. |
| Drugi węzeł SQL | SQL02.DC.Local | 192.168.1.113 | Na tej maszynie wirtualnej zainstalujemy dodatkowy węzeł instancji klastra pracy awaryjnej. |
Szczegóły klastra pracy awaryjnej:
Po utworzeniu i skonfigurowaniu maszyny wirtualnej stworzyłem dwuwęzłowy klaster. Oto szczegóły:
| Maszyna wirtualna | Cel |
| Liczba węzłów | 2 |
| Nazwa klastra | SQLCluster.DC.Local |
| Pamięć | Dwa dyski w klastrze i jeden monitor kworum |
| Aktywny węzeł | SQL01.DC.Local |
| Węzeł pasywny | SQL02.DC.Local |
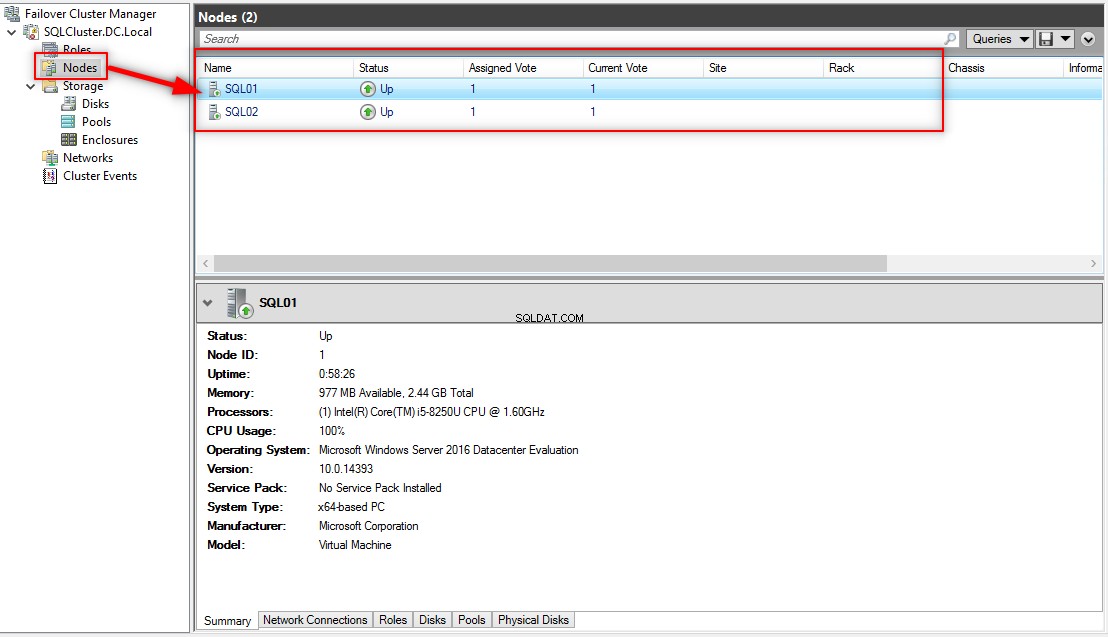
Po włączeniu roli klastra pracy awaryjnej w węzłach skonfigurowałem klaster o nazwie SQLCluster.DC.Local. Klaster ma jeden aktywny węzeł (SQL01.DC.Local ) i jeden pasywny węzeł (SQL02.DC.Local ). Zobacz następujący obraz:
Klaster ma trzy klastrowane woluminy dysków i odpowiednio zmieniłem ich nazwy. Wolumen dysku D ata F pliki służy do przechowywania plików bazy danych, podczas gdy TempDB i Log-F pliki służą do przechowywania plików baz danych i plików T-log. Wolumin o nazwie Qu lub działa jako monitor kworum — skonfigurowałem klaster do używania tego dysku jako monitora kworum . Zobacz następujący obraz:
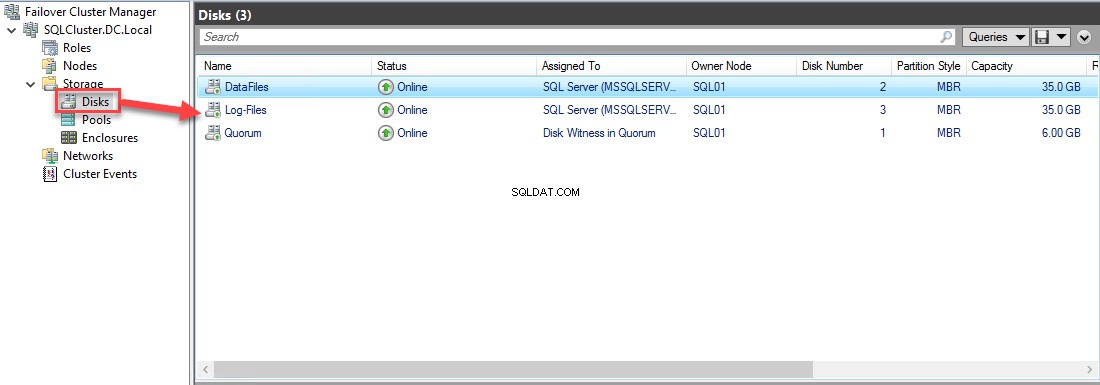
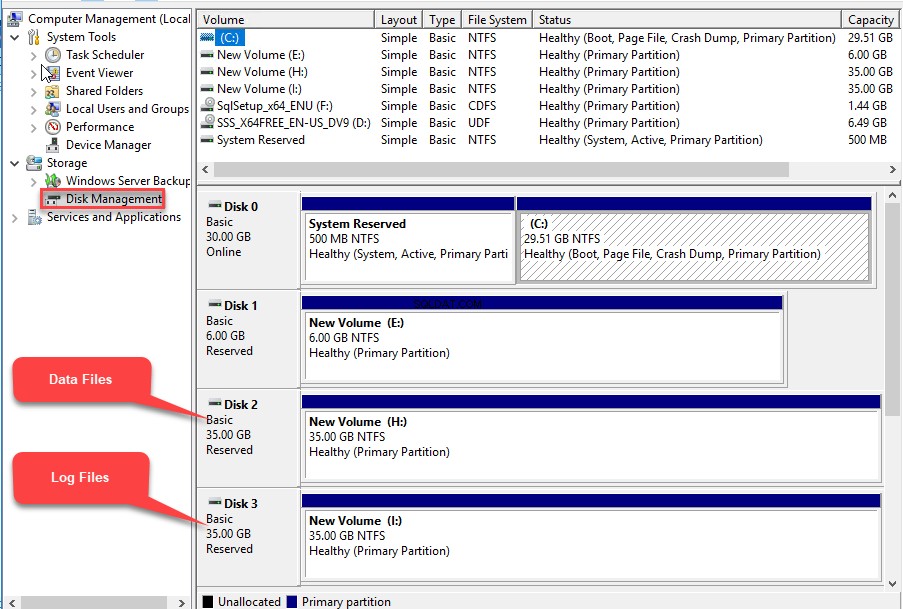
Na SQL01 Node, połączyłem się z obydwoma klastrami woluminów za pomocą inicjatora iSCSI, zainicjowałem te dyski, oznaczyłem je jako online i sformatowałem. Przypisałem literę dysku H:\ do D ata F pliki i Ja:\ do plików dziennika . Zobacz poniższy zrzut ekranu okna Zarządzanie dyskami:
Instalowanie instancji SQL Server Failover Cluster
Po skonfigurowaniu klastra pobierz SQL Server 2017 z tutaj . Po zakończeniu pobierania skopiuj obraz dysku .iso do SQL01 węzeł. Połącz z SQL01 , kliknij dwukrotnie plik .iso, aby go zamontować. Po zamontowaniu pliku .iso uruchom setup.exe . Zobacz następujący obraz:
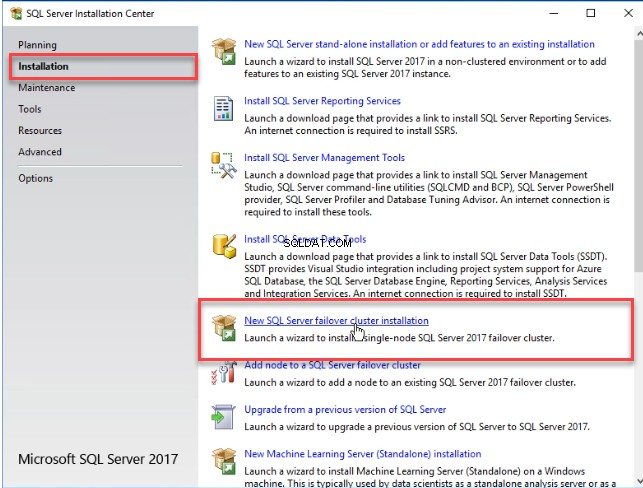
Otworzy się kreator instalacji SQL Server. W lewym okienku kreatora wybierz „Instalacja ”, a następnie kliknij „Instalacja nowego klastra pracy awaryjnej SQL Server”. Zobacz następujący obraz:
W „Kluczu produktu ”, wybierz wersję SQL Server, którą chcesz zainstalować. Jeśli masz klucz licencyjny dla wersji standardowej lub wersji Enterprise programu SQL Server, możesz wprowadzić go w polu tekstowym „Wprowadź klucz produktu”. Jeśli korzystasz z wersji dla programistów lub bezpłatnej wersji próbnej, wybierz dowolne opcje w S określ F ree E wersja menu rozwijane.
W Warunkach licencji zaakceptuj warunki i postanowienia firmy Microsoft. Zobacz następujący obraz:
W „Aktualizacji Microsoft ”, możesz wybrać instalację aktualizacji firmy Microsoft. Jeśli chcesz pobrać aktualizacje ręcznie, możesz pominąć ten krok. Kliknij Dalej .
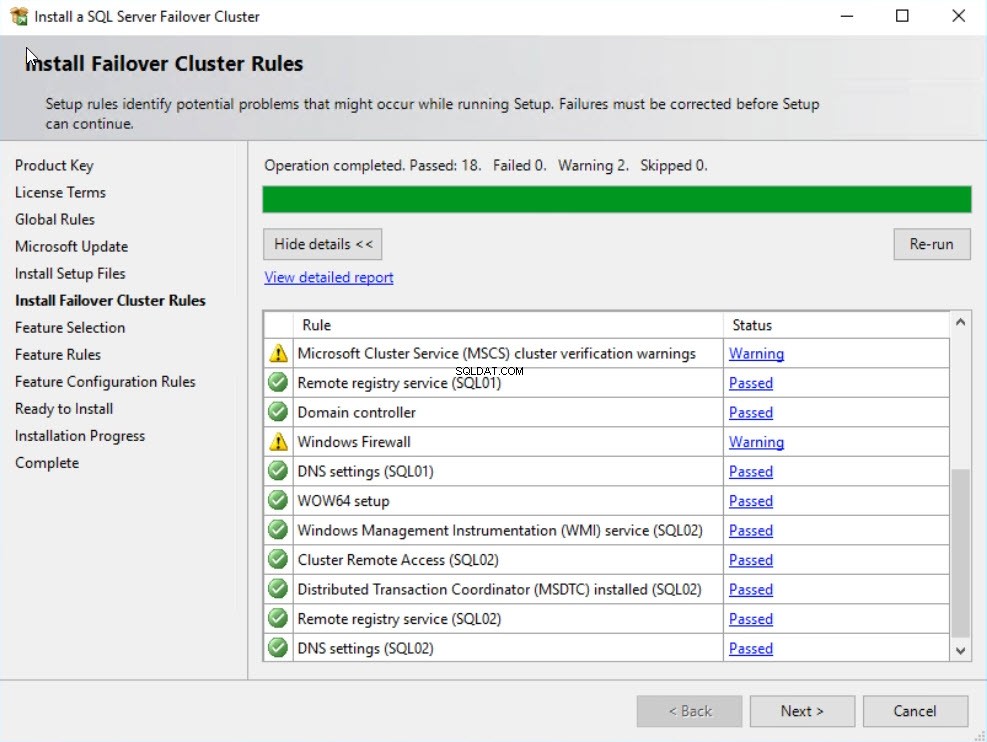
W Zainstaluj reguły klastra pracy awaryjnej ekranie, upewnij się, że wszystkie reguły zostały pomyślnie zweryfikowane. Jeśli jakakolwiek reguła nie powiedzie się lub wyświetli ostrzeżenie, należy ją naprawić i kontynuować konfigurację. W tym demo pominąłem ostrzeżenie. Zobacz następujący obraz:
W Wyborze funkcji w oknie dialogowym wybierz funkcje, które chcesz zainstalować. Z SQL Server 2016 możemy pobrać oddzielnie studio zarządzania serwerem SQL. Zobacz następujący obraz:
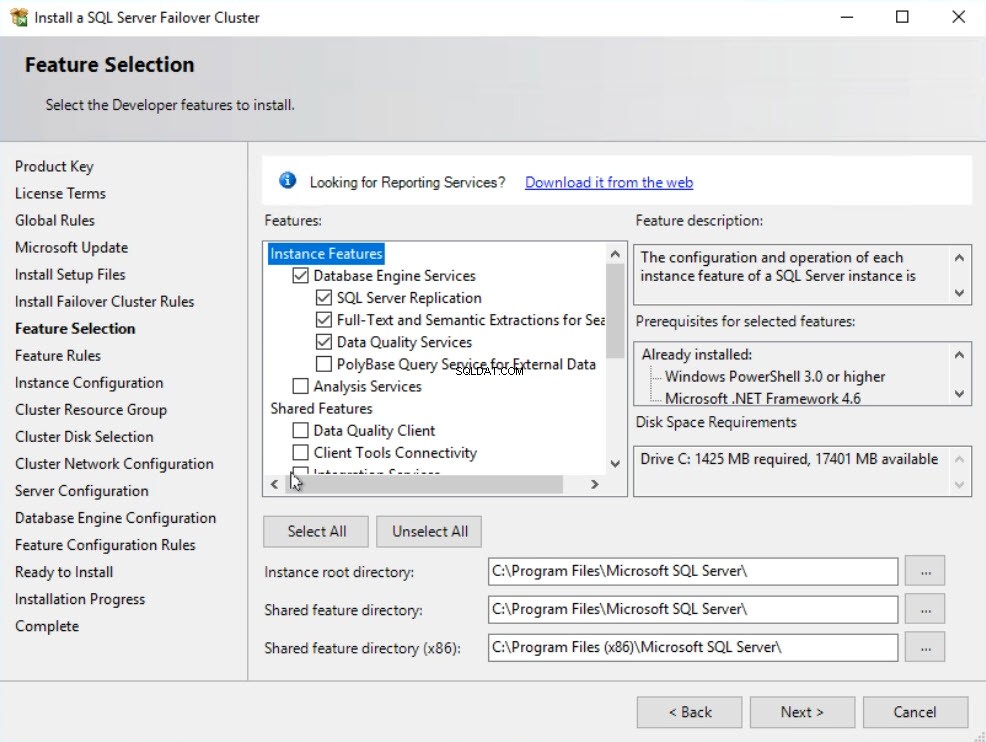
W Konfiguracji instancji w oknie dialogowym wprowadź Nazwę sieciową serwera SQL – jest używany przez aplikację i SQL Server Management Studio do łączenia się z instancją klastra pracy awaryjnej. Możesz wybrać między instancją domyślną lub nazwana instancja jako identyfikator instancji. Jeśli chcesz zainstalować wiele wystąpień w klastrze pracy awaryjnej, możesz użyć wystąpienia nazwanego. W tym demo użyłem Instancji domyślnej Zobacz następujący obraz:
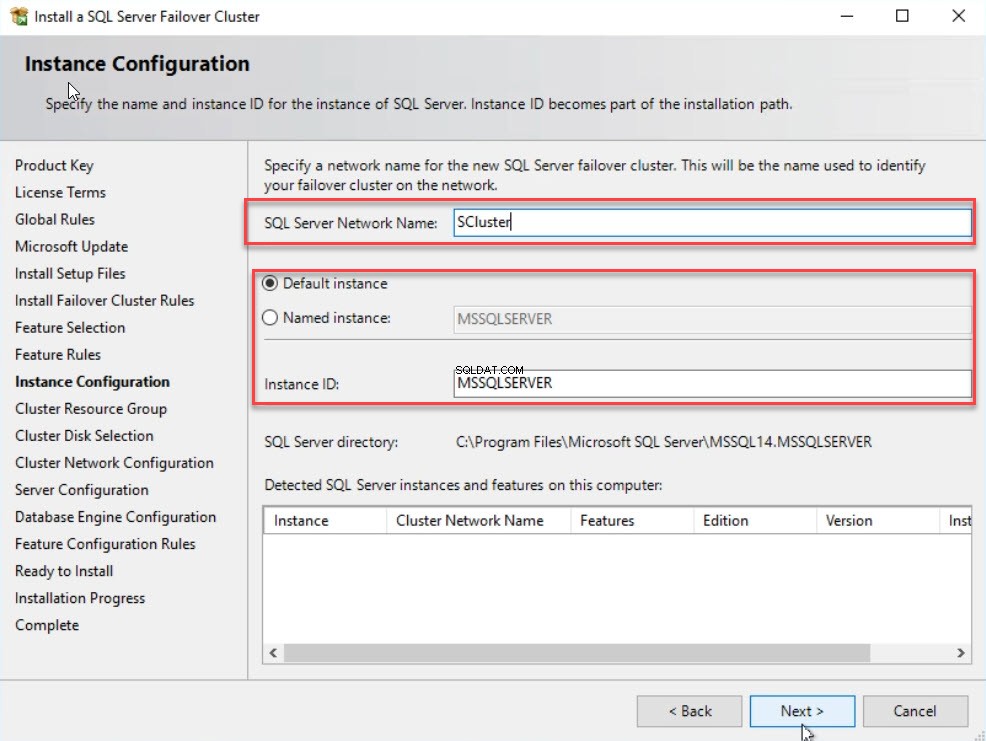
W grupie zasobów klastra w oknie dialogowym określ nazwę grupy zasobów klastra pracy awaryjnej systemu Windows. Istnieją dwie opcje:albo utworzenie nowej grupy zasobów dla MSSQLSERVER, albo wybranie istniejącej w Nazwie grupy zasobów klastra SQL Server upuścić pudło. Zobacz następujący obraz:
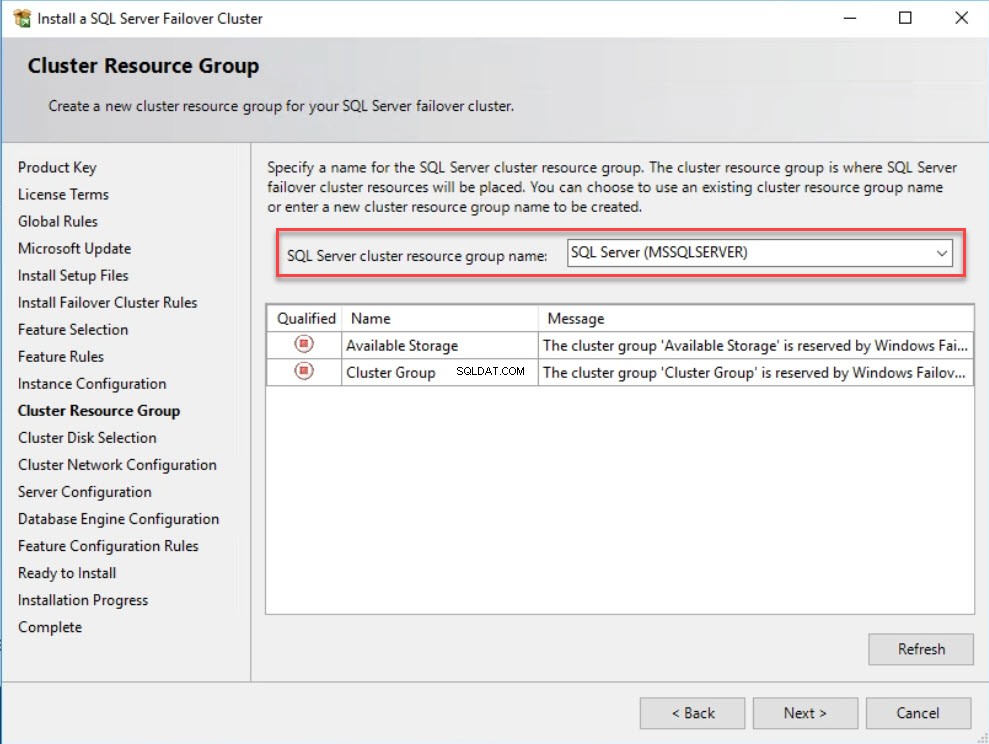
W menu Wybór dysku klastrowego w oknie dialogowym wybierz udostępniony dysk grupy klastra pracy awaryjnej. Ten dysk będzie używany przez wystąpienie klastra pracy awaryjnej programu SQL Server. Utworzyłem już dwa dyski klastrowe o nazwie Dane F je s i L og- F je s. Wybrałem te dyski i kliknąłem Dalej . Zobacz następujący obraz:
W klastrze N sieć C konfiguracja w oknie dialogowym podaj adres IP i maskę podsieci. Ten adres IP będzie używany przez SQL Server FCI. W tym przykładzie używam 192.168.1.150 . Jeśli używasz statycznego adresu IP, zaznacz pole wyboru obok Ipaddress kolumnę i kliknij N wew. Zobacz następujący obraz:
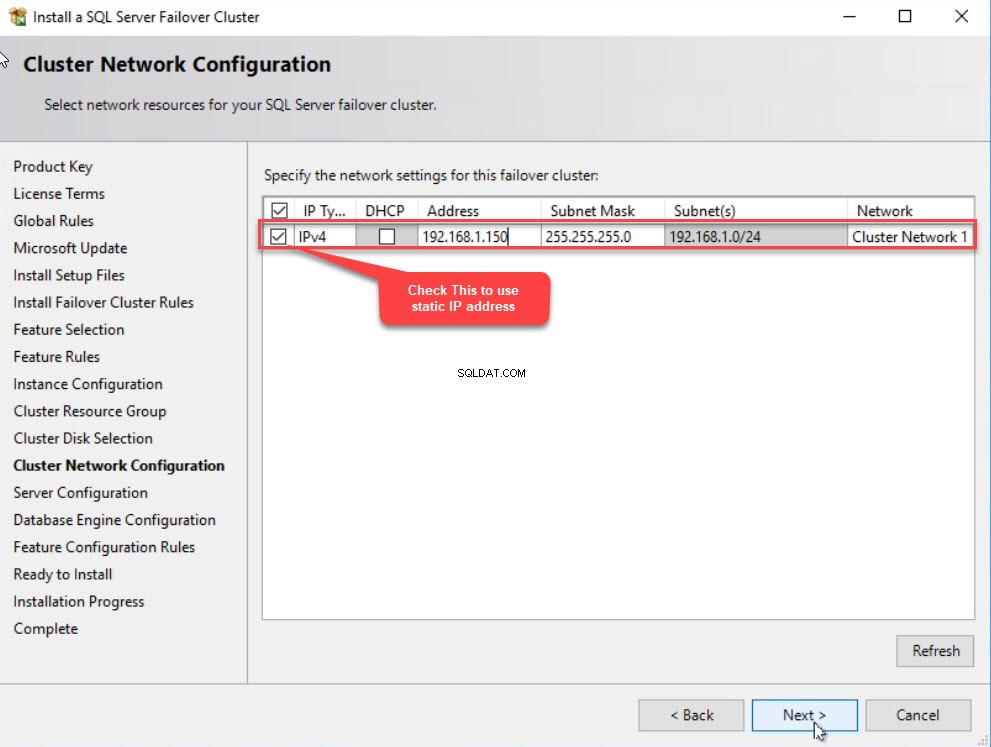
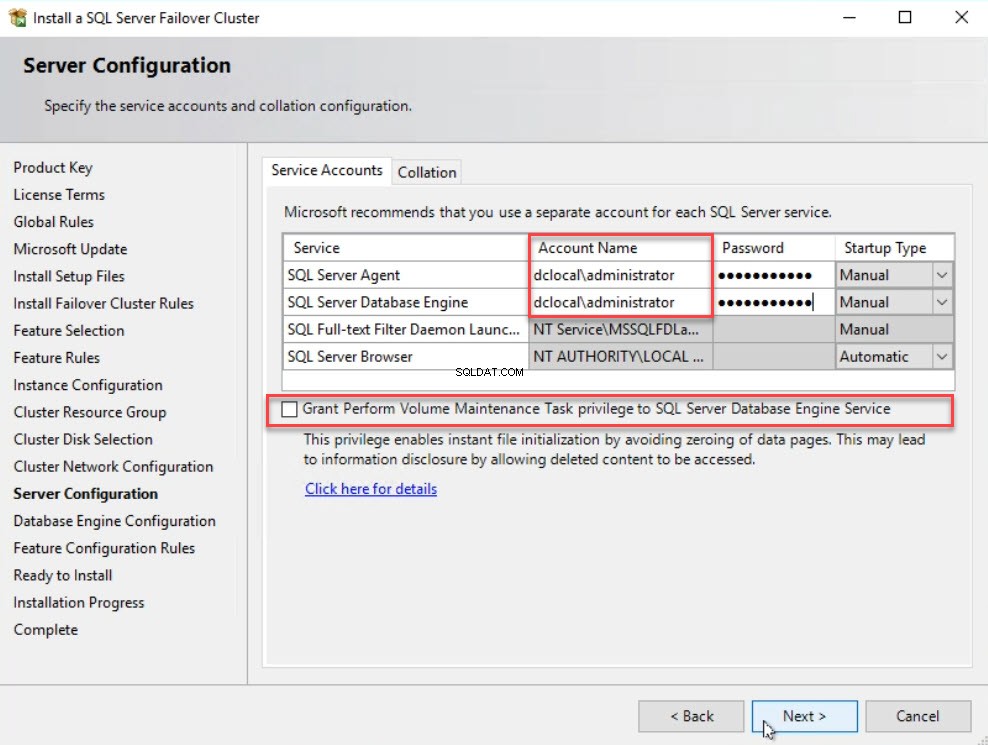
W Konfiguracji serwera w oknie dialogowym podaj nazwę użytkownika i hasło konta usługi SQL w polu Nazwa konta kolumna. W tym oknie dialogowym można włączyć natychmiastową inicjalizację plików. IFI eliminuje proces zerowania podczas opcji autowzrostu. Aby to zrobić, włącz opcję Grant Performance Volume M konserwacja T zapytaj P przywilej opcja. Kliknij N dosz . Zobacz następujący obraz:
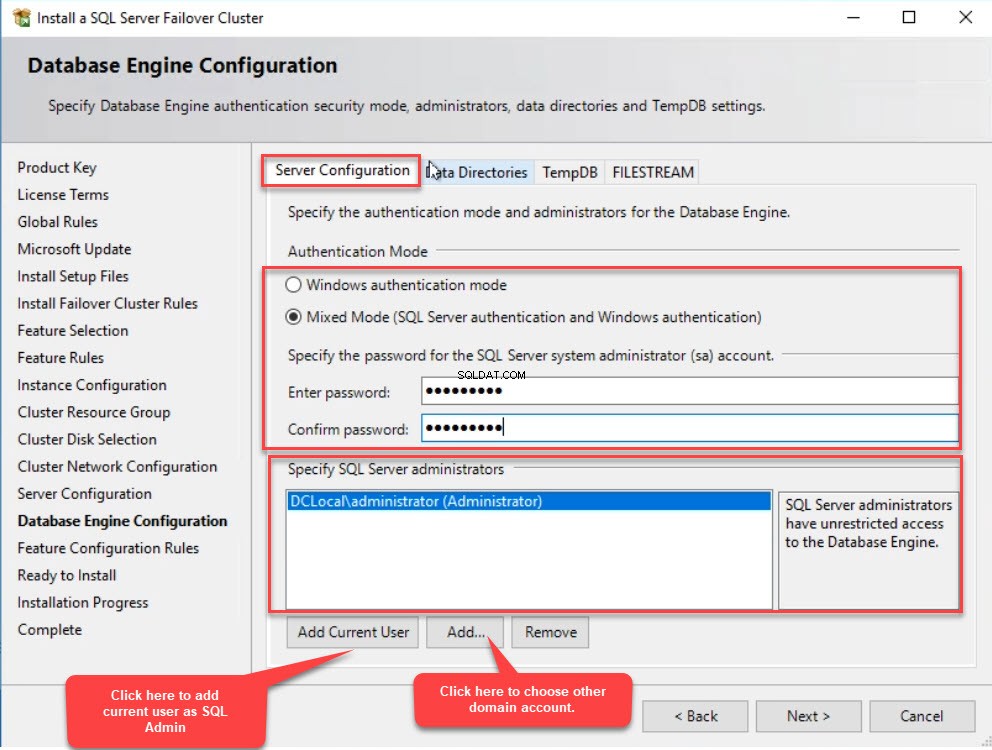
W Konfiguracji silnika bazy danych okno dialogowe, pod S serwer C konfiguracja , określ tryb uwierzytelniania. Możesz skonfigurować instancję tak, aby używała tylko trybu uwierzytelniania Windows lub M tryb stały (uwierzytelnianie Windows i SQL Server). Możesz dodać bieżącego użytkownika (użytkownika instalującego program SQL Server), klikając przycisk Dodaj bieżącego użytkownika przycisk. Możesz także dodać inne konta domeny. Wybrałem tryb mieszany jako typ uwierzytelniania i dodałem bieżącego użytkownika jako administratora SQL Server. Zobacz następujący obraz:
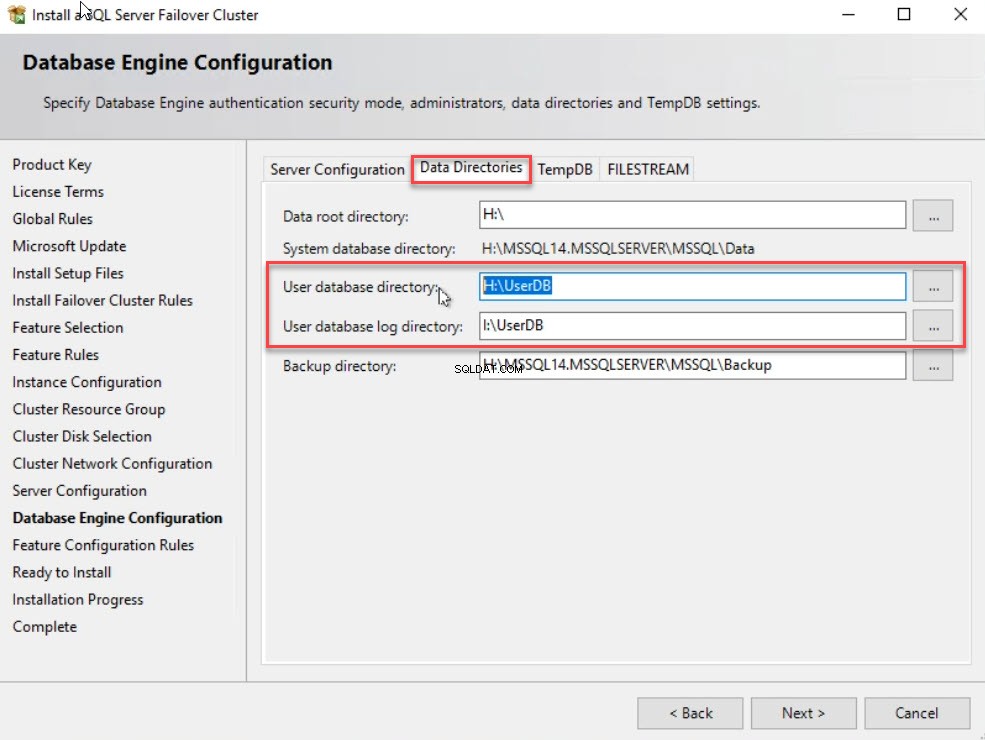
Teraz musisz przejść do Katalogów danych i określ ścieżki do przechowywania pliku bazy danych użytkownika, pliku dziennika bazy danych użytkownika oraz pliku kopii zapasowej. W tym przykładzie określiłem „H:\UserDB ” w katalogu bazy danych użytkowników pole i „I:\UserDB ” w katalogu dziennika bazy danych użytkownika skrzynka. Zobacz następujący obraz:
Następnie przejdź do TempDB tab, aby określić lokalizację bazy danych TempDB. Ponadto można określić liczbę baz danych TempDB i plików dziennika, ich początkowy rozmiar oraz wartość automatycznego wzrostu. Na H:\ dysk, utworzyłem folder o nazwie TempDB do przechowywania plików TempDB. Tak więc w katalogu danych w polu tekstowym określ „H:\TempDB. W tym przykładzie nie zmieniłem wartości liczby plików, początkowego rozmiaru i automatycznego wzrostu. Po określeniu wszystkich wartości kliknij N dosz . Zobacz następujący obraz:
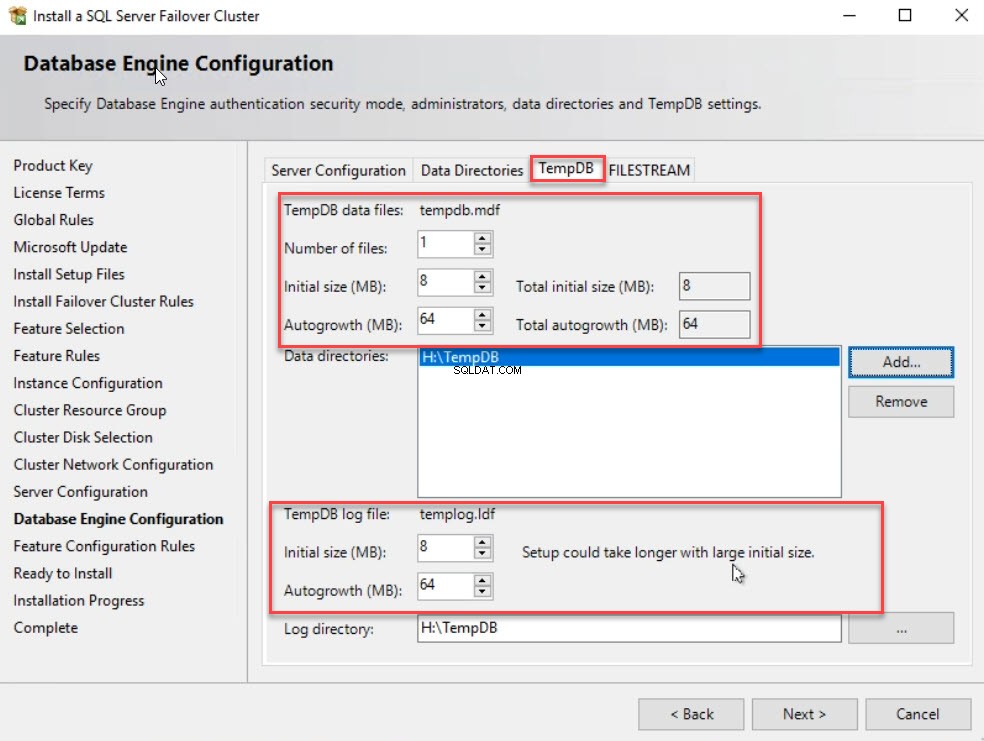
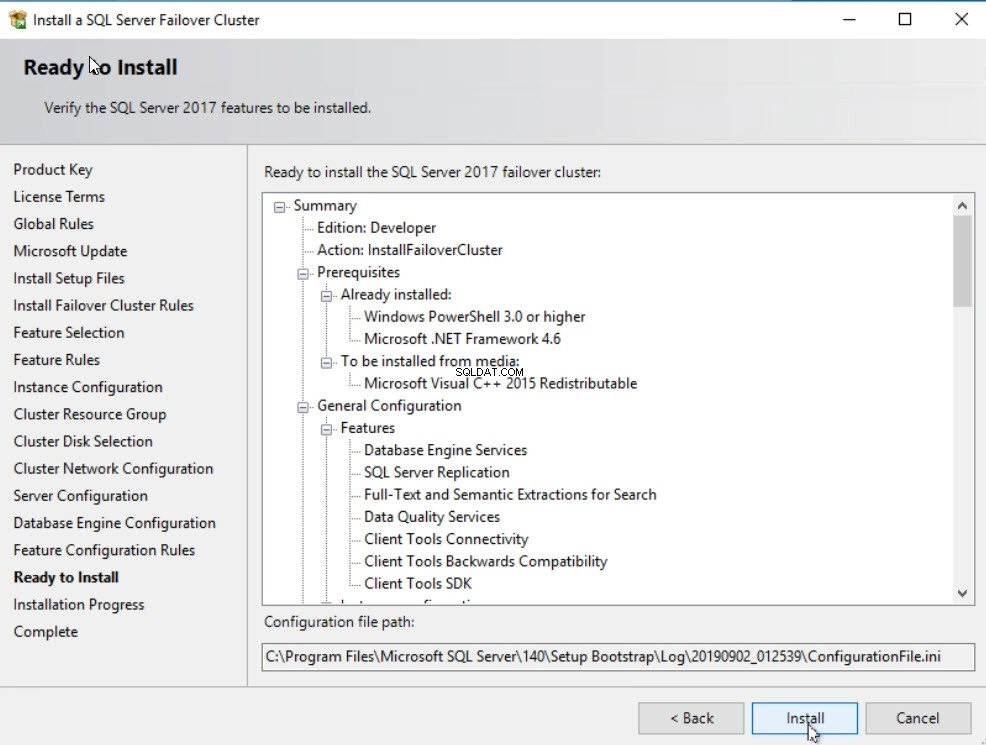
Na R gotowe Ja ninstaluj ekranie, przejrzyj wszystkie ustawienia i kliknij Zainstaluj aby rozpocząć proces instalacji. Zobacz następujący obraz:
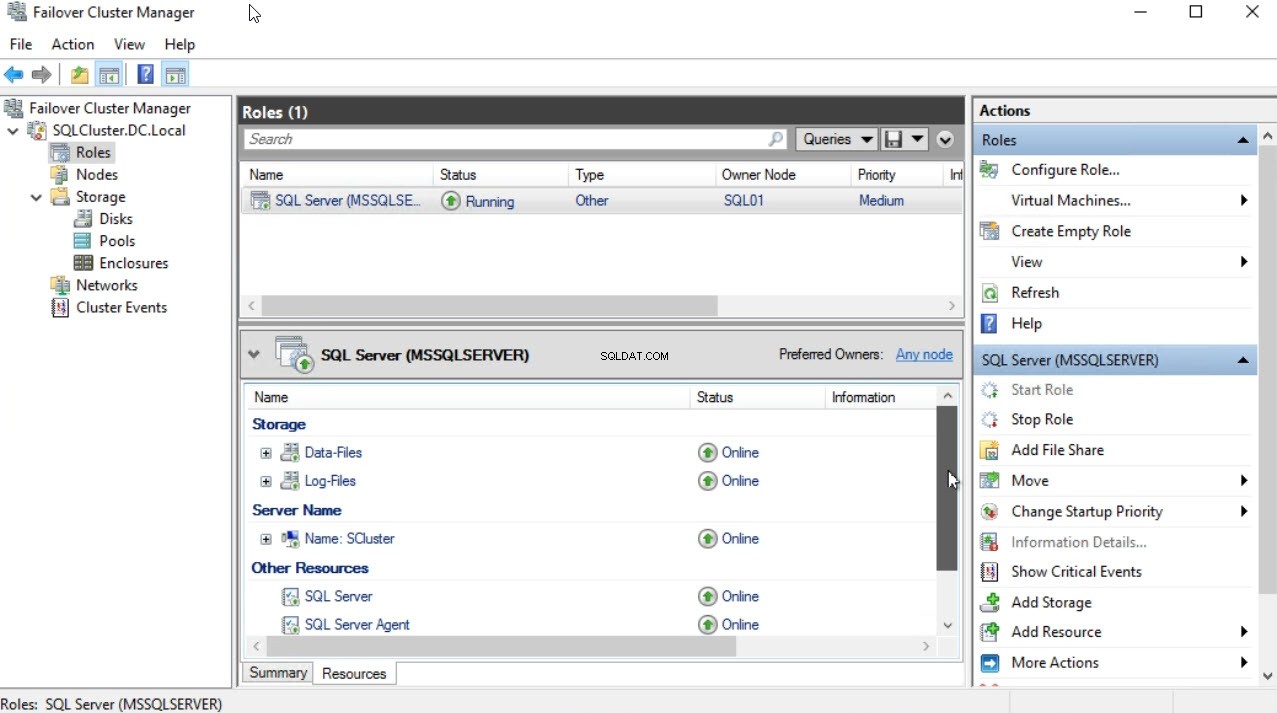
Po zakończeniu instalacji otwórz Menedżera klastra pracy awaryjnej. W rolach widać, że SQL Server (MSSQLSERVER) rola została pomyślnie zainstalowana. Upewnij się, że wszystkie jego zależności są w trybie online. Zobacz następujący obraz:
Podsumowanie
W tym artykule krok po kroku wyjaśniłem proces instalacji instancji klastra SQL Server Failover. W następnym artykule wyjaśnię, jak zainstalować dodatkowy węzeł w instancji klastra pracy awaryjnej SQL Server i zademonstruję ręczny proces przełączania awaryjnego. Bądź na bieżąco!