Ten artykuł dotyczy podstaw wyszukiwania semantycznego, w tym pełnego przewodnika po wyszukiwaniu semantycznym:zaczynając od zera i kończąc na gotowej do użycia funkcji.
Ponadto czytelnicy poznają niektóre z bardzo przydatnych, ale nie ogólnie znanych funkcji wyszukiwania dostępnych w SQL Server, takich jak wyszukiwanie semantyczne, które zademonstrujemy na kilku podstawowych przykładach.
Ten artykuł podkreśla również znaczenie wyszukiwania semantycznego dla określonej formy analizy, której nie można przeprowadzić za pomocą zwykłego wyszukiwania.
Co to jest wyszukiwanie semantyczne
Najpierw ustalmy, czym dokładnie jest wyszukiwanie semantyczne i czym różni się od wyszukiwania pełnotekstowego.
Definicja Microsoft
Zgodnie z dokumentacją Microsoft, Semantic Search zapewnia głęboki wgląd w nieustrukturyzowane dokumenty.
Alternatywna definicja
Wyszukiwanie semantyczne to specjalna technologia wyszukiwania lub funkcja wykorzystywana do przeprowadzania kompleksowego wyszukiwania lub analizy porównawczej, głównie w nieustrukturyzowanych danych lub dokumentach, takich jak dokumenty MS Word, pod warunkiem, że nieustrukturyzowane dane są przechowywane w bazie danych SQL Server.
Kompatybilność
Wyszukiwanie semantyczne jest kompatybilne tylko z SQL Server 2012 i nowszymi wersjami.
Pamiętaj, że wyszukiwanie semantyczne nie jest kompatybilne z bazą danych Azure SQL lub rozwiązaniami chmurowymi hurtowni danych Azure.
Oznacza to, że aby wykorzystać tę zaawansowaną funkcję, musisz pracować z maszyną wirtualną na platformie Azure lub z lokalną instancją SQL Server.
Wyszukiwanie semantyczne a wyszukiwanie pełnotekstowe
Zgodnie z dokumentacją firmy Microsoft, wyszukiwanie pełnotekstowe umożliwia wyszukiwanie słów w dokumencie; wyszukiwanie semantyczne umożliwia sprawdzenie znaczenia dokumentu.
Wyszukiwanie semantyczne wraz z wyszukiwaniem pełnotekstowym reprezentuje jedną wspólną funkcję oferowaną przez Microsoft SQL Server i można ją zainstalować podczas instalacji instancji SQL Server lub później, dodając nowe funkcje do istniejącej instancji SQL.
Wymagania wstępne
Przejdźmy przez wymagania wstępne dla ogólnego korzystania z wyszukiwania semantycznego wraz z niektórymi rzeczami wymaganymi do wykonania instrukcji w tym artykule.
Zainstalowano wyszukiwanie pełnotekstowe
Znajomość konfiguracji wyszukiwania pełnotekstowego jest obowiązkowa, ponieważ wyszukiwanie pełnotekstowe i semantyczne są oferowane jako wspólna funkcja.
Zapoznaj się z artykułem Implementacja wyszukiwania pełnotekstowego w SQL Server 2016 dla początkujących, aby skonfigurować wyszukiwanie pełnotekstowe, które jest warunkiem wstępnym instalacji wyszukiwania semantycznego w SQL Server.
W tym artykule oczekujemy, że zainstalowałeś wyszukiwanie pełnotekstowe na swojej instancji SQL Server.
dbForge Studio dla serwera SQL
Korzystanie z wyszukiwania semantycznego (w omówieniu tego artykułu) wymaga przechowywania nieustrukturyzowanych danych w bazie danych SQL Server, a w tym artykule zrobiliśmy to za pomocą dbForge Studio dla SQL Server, zamiast zapisywać bezpośrednio nieustrukturyzowane dane w SQL Server.
Serwer SQL 2016
W tym artykule używamy SQL Server 2016, ale kroki powinny być prawie takie same dla każdej innej zgodnej wersji.
Skonfiguruj wyszukiwanie semantyczne
Aby korzystać z wyszukiwania semantycznego lub statystycznego wyszukiwania semantycznego, możesz zainstalować je podczas instalacji wyszukiwania pełnotekstowego lub później, dodając wyszukiwanie pełnotekstowe i semantyczne jako nową funkcję.
Sprawdzenie wyszukiwania pełnotekstowego
Sprawdź stan instalacji wyszukiwania pełnotekstowego i wyszukiwania semantycznego, uruchamiając następujący skrypt w głównej bazie danych:
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO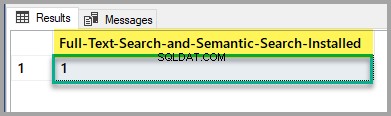
Jeśli wynik wynosi 1, dobrze jest iść, ale jeśli jest to 0, zapoznaj się z artykułem wspomnianym powyżej, aby zainstalować funkcję wyszukiwania pełnotekstowego i wyszukiwania semantycznego przy użyciu konfiguracji SQL Server.
Zainstaluj bazę danych statystycznych języka semantycznego
Zainstaluj bazę danych statystyk języka semantycznego, wyszukując Microsoft® SQL Server® 2016 Semantic Language Statistics w Internecie lub klikając poniższy link.
Wybieranie pobierania na podstawie wersji systemu Windows:
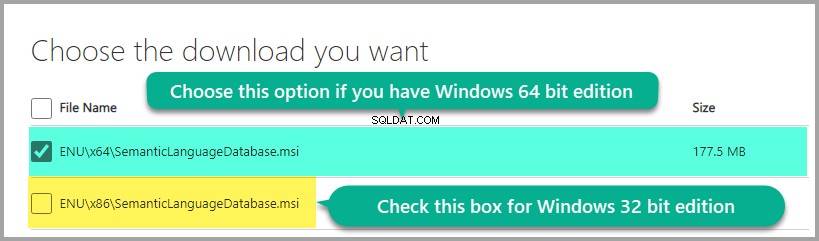
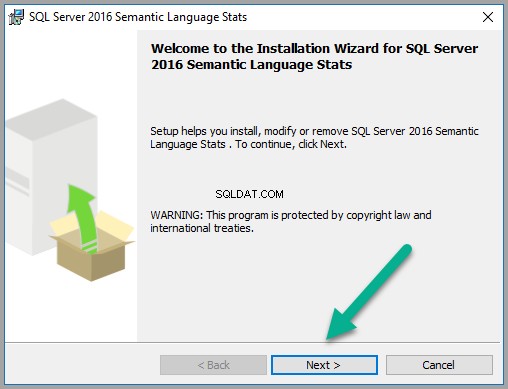
Zainstaluj bazę danych języków:
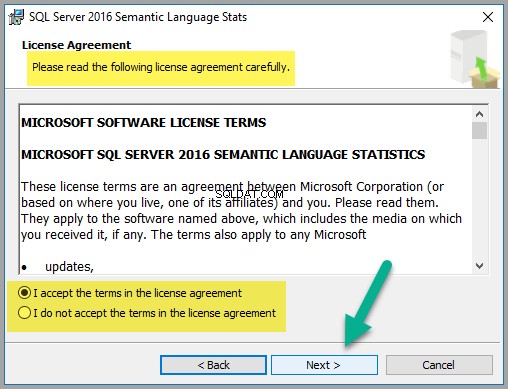
Kliknij Dalej aby kontynuować, jeśli zgadzasz się z warunkami umowy licencyjnej:
Pozostaw domyślne opcje bez zmian, ale zaleca się sprawdzenie kosztu dysku, jak pokazano poniżej:
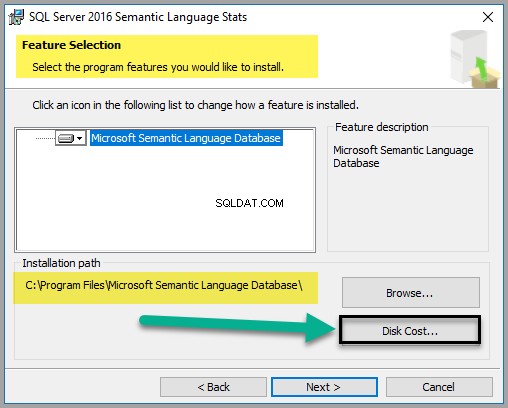
Chociaż plik zajmuje tylko około 747 MB miejsca (w momencie pisania tego artykułu), sprawdź koszt dysku, aby upewnić się, że masz wystarczająco dużo miejsca:
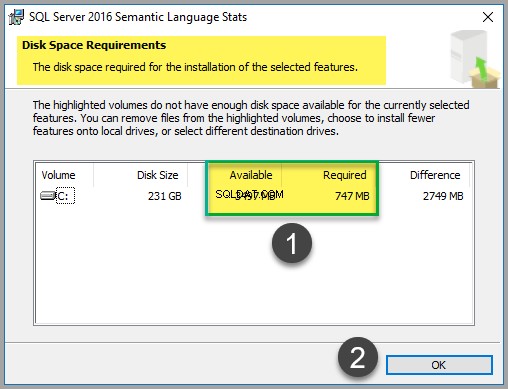
Po zakończeniu sprawdzania kosztów dysku kliknij OK a następnie kliknij Dalej .
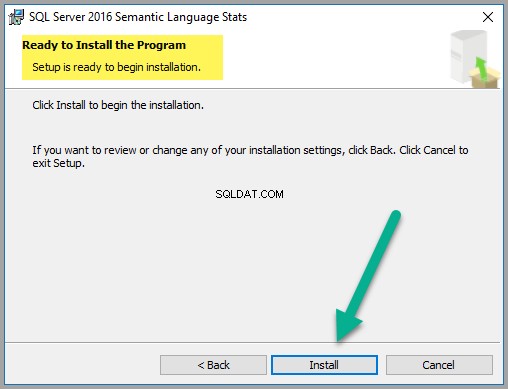
Zostaniesz poproszony o zainstalowanie pliku, kliknij Zainstaluj (jeśli jesteś zainteresowany):
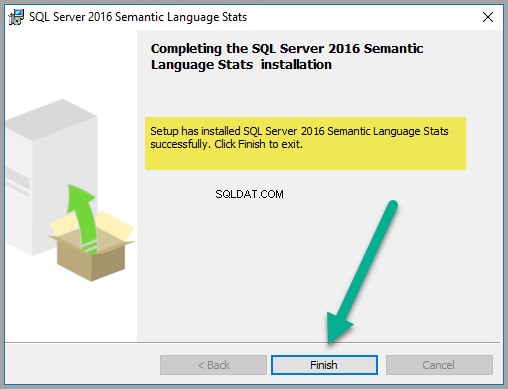
Kliknij Zakończ po pomyślnym zakończeniu instalacji, co powinno wyglądać jak na poniższym zrzucie ekranu:
Znajdź folder, w którym domyślnie zainstalowano bazę danych języka semantycznego (C:\Program Files\Microsoft Semantic Language Database):
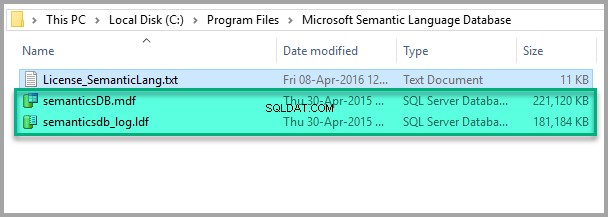
Wszystko wygląda dobrze, więc skopiuj plik Data and Log do folderu Data instancji SQL, jak pokazano poniżej:
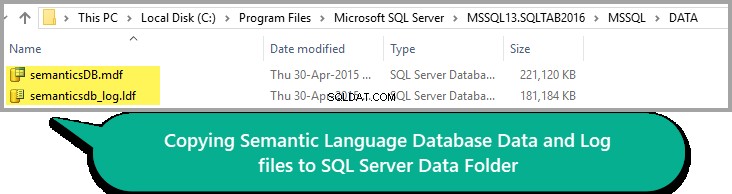
Pamiętaj, że ścieżka folderu DATA może się różnić w zależności od Twojej wersji programu SQL Server.
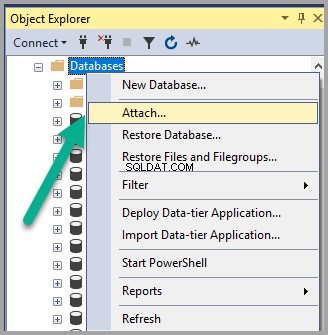
Dołącz bazę danych języka semantycznego do instancji SQL
Kliknij prawym przyciskiem myszy Bazy danych węzeł w Eksploratorze obiektów w SSMS (SQL Server Management Studio) i kliknij Dołącz :
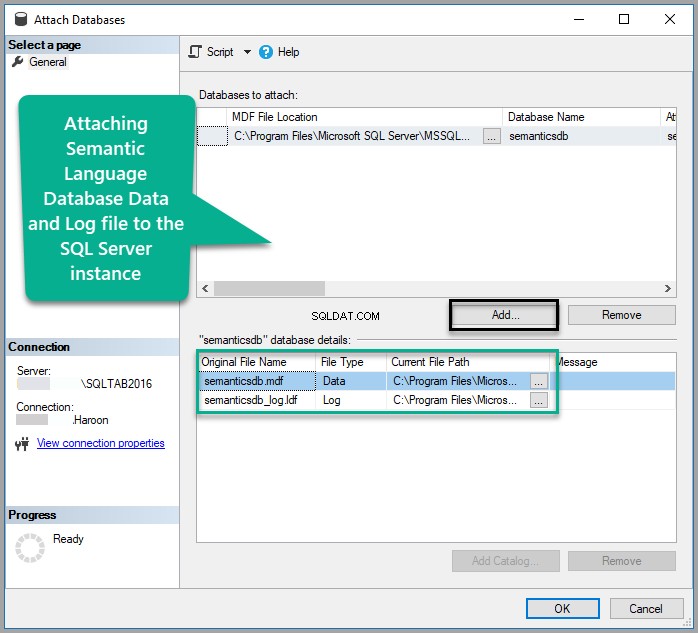
Dodaj Semanticsdb.mdf i kliknij OK :
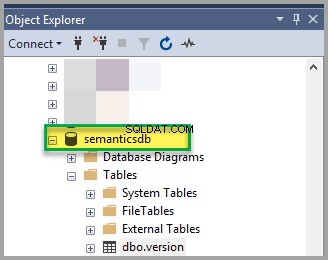
Wyświetl bazę danych:
Zarejestruj semantyczną bazę danych
Wpisz następujący skrypt w głównej bazie danych, aby zarejestrować bazę danych statystyk języka semantycznego:
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOSprawdź stan semantycznej bazy danych
Sprawdź stan bazy danych statystyk języka semantycznego, uruchamiając następujący skrypt w głównej bazie danych:
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GODane wyjściowe nie mogą być puste i wyglądają następująco:

Pamiętaj, że powyższe wartości mogą się różnić na twoim komputerze, co jest normalne, o ile widzisz wiersz, oznacza to, że baza danych statystyk języka semantycznego została pomyślnie zainstalowana na twojej instancji SQL.
Korzystanie z wyszukiwania semantycznego
Po skonfigurowaniu wyszukiwania semantycznego jesteśmy gotowi do użycia go w SQL Server.
Scenariusz wyszukiwania semantycznego
Zamierzamy przechowywać dokumenty pracowników (próbki) w formacie tekstu sformatowanego w bazie danych SQL Server, które będą później przeszukiwane i porównywane za pomocą wyszukiwania semantycznego.
Skonfiguruj przykładową bazę danych pracowników
Utwórz przykładową bazę danych z pojedynczą tabelą, uruchamiając skrypt T-SQL względem głównej bazy danych w następujący sposób:
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOSprawdź przykładową bazę danych
Uruchom następujący skrypt tylko po to, aby sprawdzić przykładową tabelę bazy danych:
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efssDane wyjściowe są następujące:
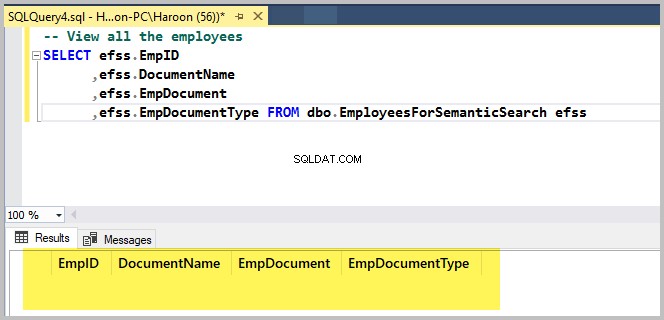
Dodaj pierwszy plik sformatowanego tekstu za pomocą dbForge Studio dla SQL Server
Zamierzamy dodać dane binarne do tabel, które są reprezentowane przez sformatowane pliki tekstowe, używając dbForge Studio dla SQL Server .
Otwórz przykładową bazę danych EmployeesSample w dbForge Studio dla SQL Server.
Kliknij prawym przyciskiem myszy PracownicyForSemanticSearch tabeli i kliknij Pobierz dane:
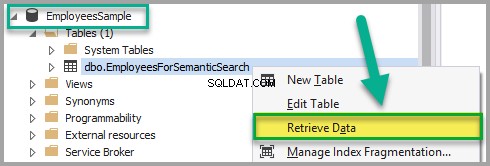
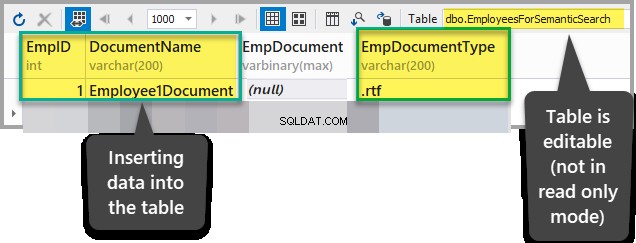
Dodaj następujące dane do EmployeesForSemanticSearch tabela z wyjątkiem EmpDocument kolumna po upewnieniu się, że tabela nie jest w trybie tylko do odczytu:
Identyfikator:1
DocumentName:Employee1Document
EmpDocument:(null)
EmpDocumentType:.rtf
Wstaw dokument w formacie RTF do EmpDocument kolumnę, dodając następujący tekst do tabeli (klikając wielokropek i dodając dane):
This is a research based article and it is a new research which is in process but this is superb in the field of research.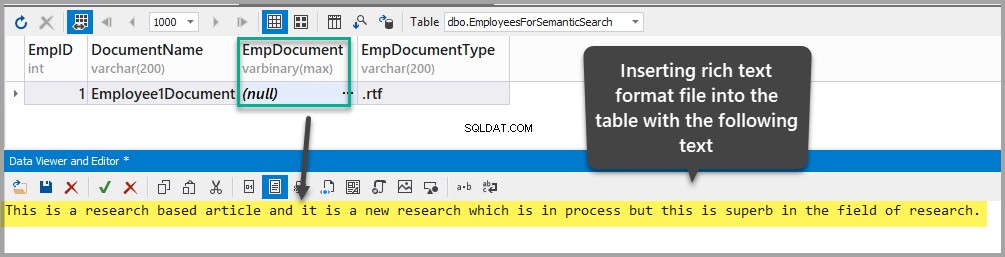
Zapisz dokument jako Employee1Document.rtf w dowolnym odpowiednim folderze Windows:
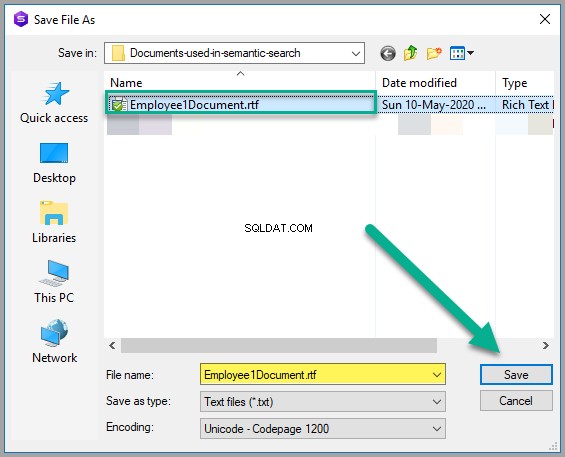
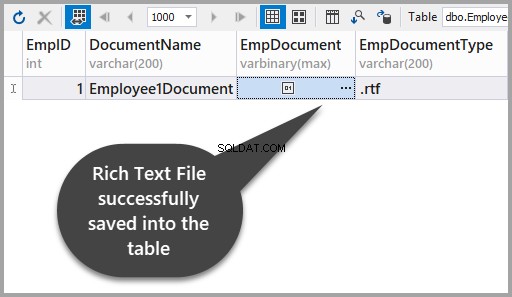
Zastosuj zmiany, aby sprawdzić, czy plik z tekstem sformatowanym został pomyślnie zapisany w tabeli:
Dodaj drugi plik z tekstem sformatowanym za pomocą dbForge Studio dla SQL Server
Następnie dodaj kolejny plik sformatowanego tekstu do EmployeesForSemanticSearch w taki sam sposób jak powyżej, korzystając z następujących informacji:
Identyfikator:2
DocumentName:Employee2Document
EmpDocument:(null)
EmpDocumentType:.rtf
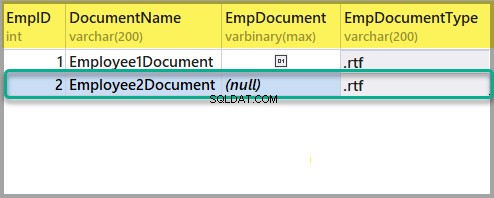
Dodaj kolejny plik z tekstem sformatowanym z następującym tekstem:
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.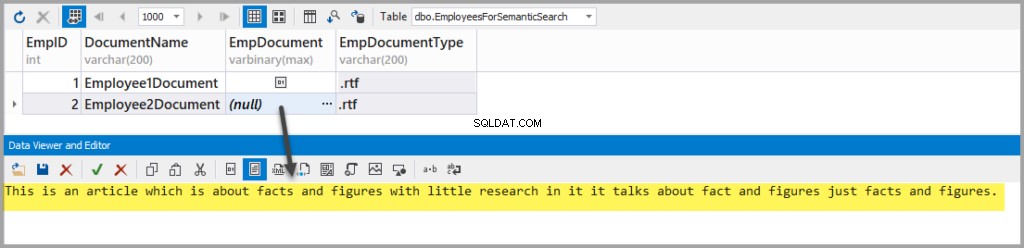
Zapisz dokument w tym samym folderze w następujący sposób:
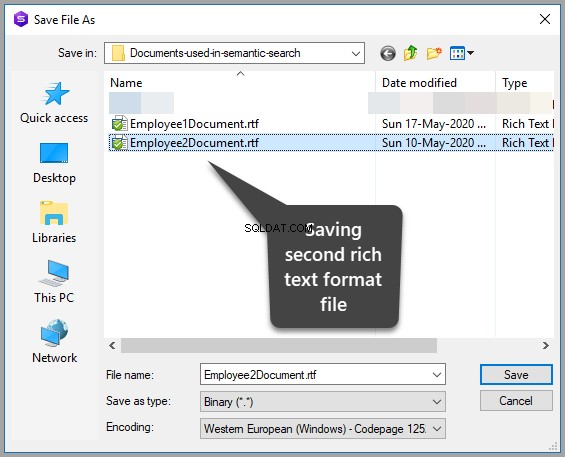
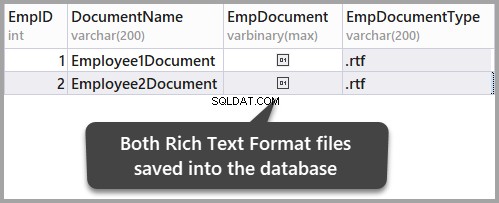
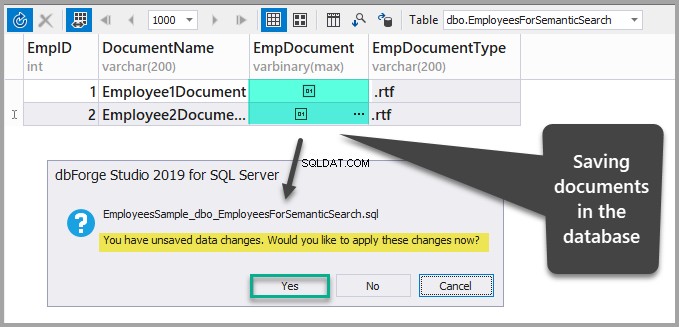
Zapisz dane, odświeżając tabelę, a następnie potwierdzając wprowadzone zmiany, klikając tak:
Utwórz unikalny indeks, indeks pełnotekstowy i indeks semantyczny za pomocą kreatora
Wróć do SSMS (SQL Server Management Studio), kliknij prawym przyciskiem myszy tabelę i kliknij Indeks pełnotekstowy a następnie kliknij Zdefiniuj indeks pełnotekstowy… jak pokazano poniżej:
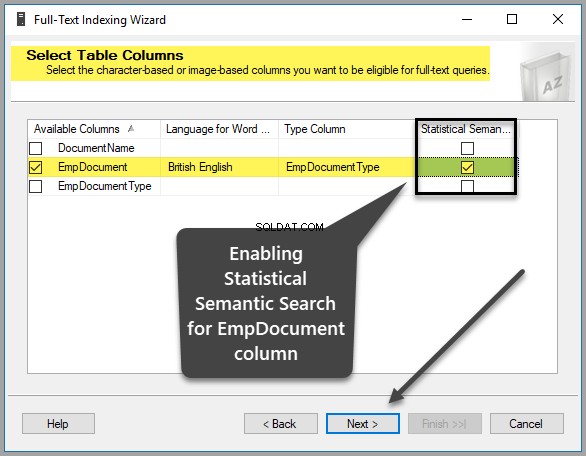
Następnie musisz wybrać unikalny indeks, który w rzeczywistości jest wybierany domyślnie, ponieważ utworzyliśmy EmpID kolumna klucza podstawowego wcześniej, jak pokazano poniżej, dlatego kliknij Dalej aby kontynuować:
Wybierz EmpDocument z Dostępnych kolumn , brytyjski angielski jako Język łamacza słów , EmpDocumentType jako Wpisz kolumnę i sprawdź Statystyczne wyszukiwanie semantyczne pole w tym samym wierszu w następujący sposób:
Wybierz opcję śledzenia zmian, pozostawiając ją jako ustawienia domyślne, chyba że masz solidny powód, aby zmienić te ustawienia:
Utwórz nowy katalog jako EmployeeCatalog :
Kliknij Dalej ponownie:
Wreszcie po kilku dodatkowych kliknięciach (kliknij Dalej ), wymagana tabela jest gotowa do przeszukiwania przez Wyszukiwanie semantyczne:
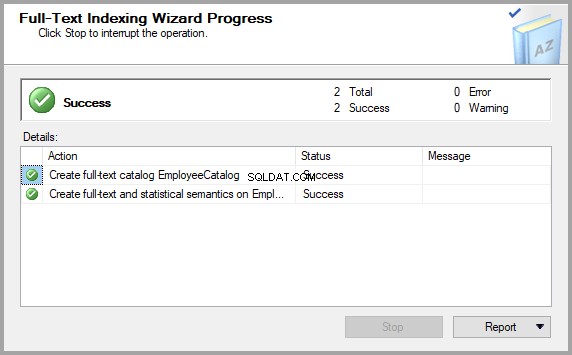
Sprawdź, czy wyszukiwanie semantyczne jest włączone dla tabeli
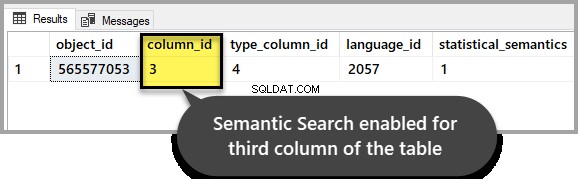
Sprawdź, czy wyszukiwanie semantyczne pozostaje nienaruszone dla tabeli zainteresowania, uruchamiając następujący skrypt w przykładowej bazie danych:
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GODane wyjściowe powinny wskazywać, że zostało włączone dla trzeciej kolumny, tak jak ustawiliśmy ją na początku instrukcji:
Przykład 1:Wykorzystanie wyniku wyszukiwania semantycznego do znalezienia odpowiedniego dokumentu
Możemy teraz użyć wyszukiwania semantycznego, aby porównać dwa dokumenty w celu znalezienia interesującego słowa kluczowego i jego względnego wyniku, co pomoże nam wskazać bardziej odpowiednie dokumenty.
Jeśli jesteśmy zainteresowani, aby zobaczyć dokument, w którym słowo „badania ” jest wymieniany częściej w porównaniu z innym dokumentem, wtedy musimy zwracać uwagę na wynik każdego z dokumentów, gdy uruchamiamy następujący skrypt T-SQL:
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;Wynik powyższego zapytania jest następujący:
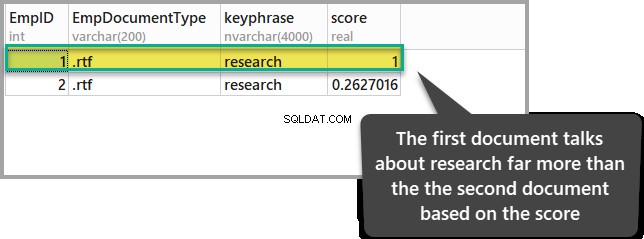
Dokument z najwyższym wynikiem pokazuje, że ma większe znaczenie w porównaniu z innym dokumentem, jeśli chodzi o nasz punkt zainteresowania (badania).
Przykład 2:użycie wyniku wyszukiwania semantycznego do znalezienia odpowiedniego dokumentu
Możemy również znaleźć dokument, w którym słowo „fakt” dominuje w porównaniu z jakimkolwiek innym dokumentem, uruchamiając poniższy skrypt:
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;Wyniki są następujące:
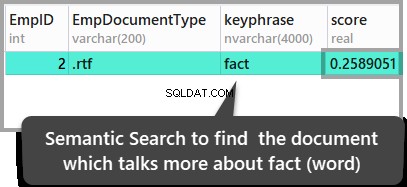
Powyższe wyniki prowadzą do wniosku, że drugi przechowywany dokument jest jedynym dokumentem, w którym słowo fakt jest wspomniane, ale jeśli chcesz sprawdzić te wyniki, otwórz zapisane dokumenty, aby je zobaczyć.
Gratulacje! Pomyślnie nauczyłeś się nie tylko konfigurować wyszukiwanie semantyczne w SQL Server, ale także zdobyłeś praktyczne doświadczenie w korzystaniu z wyszukiwania semantycznego.
Rzeczy do zrobienia
Teraz, gdy możesz skonfigurować i napisać kilka podstawowych zapytań wyszukiwania semantycznego, spróbuj wykonać następujące czynności, aby jeszcze bardziej poprawić swoje umiejętności:
- Spróbuj dodać kolejny dokument, który mówi o badaniach a następnie uruchom skrypt w pierwszym przykładzie, aby zobaczyć, który dokument jest najbardziej odpowiednim dokumentem, porównując ich wyniki.
- Mając na uwadze ten artykuł, dodaj kolejny dokument, w którym słowo fakt jest wspomniany kilka razy, a następnie uruchom T-SQL w przykładzie 2 tego artykułu, aby sprawdzić, czy wyniki pozostają takie same, czy też się zmieniają.
- Spróbuj użyć wyszukiwania semantycznego, dodając więcej dokumentów i więcej tekstu zarówno do istniejących, jak i nowych dokumentów, a następnie znajdź dokumenty pasujące do Twoich interesujących słów.
- Przejrzyj przykłady dalej, aby dowiedzieć się na własną rękę, czy w wyszukiwaniu semantycznym rozróżniana jest wielkość liter lub wielkość liter nie jest rozróżniana (wskazówka:możesz nieznacznie zmodyfikować przykłady).