Co to jest optymalizacja zapytań w SQL Server? To duży temat. Każda technika lub problem wymaga osobnego artykułu, aby omówić podstawy. Ale kiedy dopiero zaczynasz ulepszać swoją grę za pomocą zapytań, potrzebujesz czegoś prostszego, na czym możesz polegać. To jest cel tego artykułu.
Możesz powiedzieć, że Twoje zapytania są optymalne, wszystko działa dobrze, a użytkownicy są zadowoleni. Oczywiście wydajność to nie wszystko. Wyniki również powinny być poprawne. Niezależnie od tego, czy jest to sprzężenie, podzapytanie, synonim, CTE, widok, czy cokolwiek, musi działać akceptowalnie.
A na koniec dnia możesz wrócić do domu ze swoimi użytkownikami. Nie chcesz zostać w biurze naprawiając wolno działające zapytania przez noc.
Zanim zaczniemy, zapewniam, że podróż nie będzie ciężka. To będzie tylko podkład. Będziemy mieli przykłady, które nie będą dla ciebie zbyt obce. Na koniec, kiedy będziesz gotowy do głębszej analizy, przedstawimy kilka linków, które możesz sprawdzić.
Zacznijmy.
1. Optymalizacja zapytań SQL zaczyna się od projektu i architektury
Zaskoczony? Optymalizacja zapytań SQL nie jest refleksją ani wsparciem, gdy coś się zepsuje. Twoje zapytanie działa tak szybko, jak pozwala na to projekt. Mówimy o znormalizowanych tabelach, odpowiednich typach danych, wykorzystaniu indeksów, archiwizacji starych danych i wszelkich najlepszych praktykach, jakie możesz wymyślić.
Dobry projekt bazy danych działa w synergii z odpowiednim sprzętem i ustawieniami programu SQL Server. Czy zaprojektowałeś go tak, aby działał płynnie przez kilka lat i nadal czuł się jak nowy? To wielkie marzenie, ale mamy tylko określoną (zwykle – krótką) ilość czasu na przemyślenie tego.
Nie będzie idealnie pierwszego dnia produkcji, ale powinniśmy byli pokryć podstawy. Zminimalizujemy dług techniczny. Jeśli pracujesz z zespołem, to świetnie w porównaniu do występu jednoosobowego. Możesz pokryć większość dzwonków i gwizdków.
A co, jeśli baza danych działa na żywo, a ty uderzasz w ścianę wydajności? Oto kilka wskazówek i trików dotyczących optymalizacji zapytań SQL.
2. Wykrywaj problematyczne zapytania dzięki standardowemu raportowi SQL Server
Podczas kodowania łatwo zauważyć długą serię kodu lub procedurę składowaną. Możesz go debugować linia po linii. Opóźnioną linię należy naprawić.
Ale co, jeśli Twój helpdesk wyrzucił tuzin biletów, ponieważ działa wolno? Użytkownicy nie mogą wskazać dokładnej lokalizacji w kodzie, podobnie jak helpdesk. Czas jest twoim największym wrogiem.
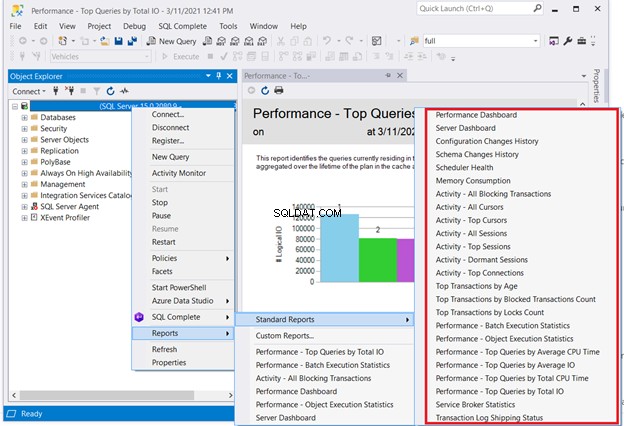
Jednym z rozwiązań, które nie wymaga kodowania, jest sprawdzanie standardowych raportów SQL Server. Kliknij prawym przyciskiem myszy wymagany serwer w SQL Server Management Studio> Raporty> Raporty standardowe . Naszym interesującym miejscem może być Panel wydajności lub Wydajność – najpopularniejsze zapytania według łącznej liczby operacji we/wy . Wybierz pierwsze zapytanie, które działa źle. Następnie rozpocznij optymalizację zapytań SQL lub dostrajanie wydajności SQL.
3. Dostrajanie zapytań SQL za pomocą STATISTICS IO
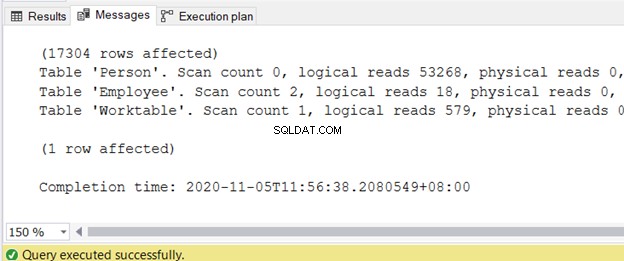
Po namierzeniu zapytania, o którym mowa, możesz rozpocząć sprawdzanie odczytów logicznych w STATISTICS IO. To jedno z narzędzi optymalizacji zapytań SQL.
Jest kilka punktów I/O, ale powinieneś skupić się na odczytach logicznych. Im wyższe odczyty logiczne, tym bardziej problematyczna jest wydajność zapytania.
Zmniejszając następujące 3 czynniki, możesz przyspieszyć zapytania dostrajające wydajność w SQL:
- wysokie odczyty logiczne,
- wysokie odczyty logiczne LOB,
- lub wysokie odczyty logiczne WorkTable/WorkFile.
Aby uzyskać informacje o odczytach logicznych, włącz STATISTICS IO w oknie zapytań SQL Server Management Studio.
USTAWIĆ WE/WY STATYSTYK
Możesz uzyskać dane wyjściowe na karcie Wiadomości po wykonaniu zapytania. Rysunek 2 przedstawia przykładowe dane wyjściowe:
Napisałem osobny artykuł o zmniejszaniu odczytów logicznych w 3 paskudnych statystykach we/wy, które opóźniają wydajność zapytań SQL. Zapoznaj się z nim, aby zapoznać się z dokładnymi krokami i przykładami kodu z wysokimi odczytami logicznymi i sposobami ich zmniejszenia.
4. Dostrajanie zapytań SQL z planami wykonania
Same odczyty logiczne nie dają pełnego obrazu. Seria kroków wybranych przez optymalizator zapytań opowie historię zestawu wyników. Jak to się wszystko zaczyna po wykonaniu zapytania?
Rysunek 3 poniżej jest diagramem tego, co dzieje się po uruchomieniu wykonania do momentu uzyskania zestawu wyników.
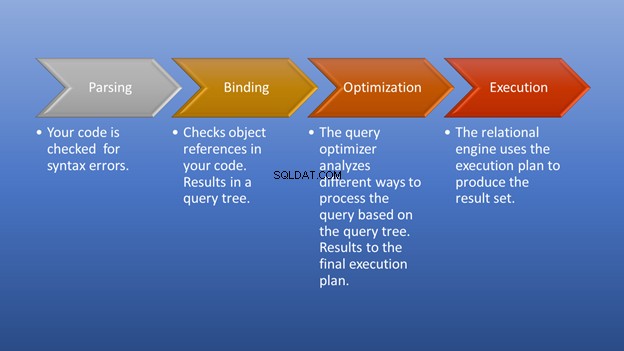
Parsowanie i wiązanie nastąpi błyskawicznie. Niesamowitą częścią jest etap optymalizacji, na którym się skupiamy. Na tym etapie optymalizator zapytań odgrywa kluczową rolę w wyborze najlepszego możliwego planu wykonania. Chociaż ta część wymaga pewnych zasobów, oszczędza dużo czasu, gdy wybiera skuteczny plan wykonania. Dzieje się to dynamicznie, ponieważ baza danych zmienia się w czasie. W ten sposób programista może skupić się na tym, jak stworzyć ostateczny wynik.
Każdy plan rozważany przez optymalizator zapytań ma swój koszt zapytania. Spośród wielu opcji optymalizator wybierze plan o najbardziej rozsądnym koszcie. Uwaga :Rozsądny koszt nie jest równy najniższemu kosztowi. Należy również rozważyć, który plan przyniesie najszybsze rezultaty. Plan o najniższych kosztach nie zawsze jest najszybszy. Na przykład optymalizator może zdecydować się na wykorzystanie kilku rdzeni procesora. Nazywamy to wykonaniem równoległym. Spowoduje to zużycie większej ilości zasobów, ale będzie działać szybciej w porównaniu do wykonywania seryjnego.
Kolejnym punktem do rozważenia są statystyki. Optymalizator zapytań wykorzystuje go do tworzenia planów wykonania. Jeśli statystyki są nieaktualne, nie oczekuj najlepszej decyzji od optymalizatora zapytań.
Kiedy plan zostanie podjęty i realizacja będzie kontynuowana, zobaczysz wyniki. Co teraz?
Sprawdź plan wykonywania zapytań w SQL Server
Kiedy tworzysz zapytanie, chcesz najpierw zobaczyć wyniki. Wyniki muszą być poprawne. Kiedy tak jest, gotowe.
Czy tak jest?
Jeśli masz mało czasu, a stawką jest praca, możesz się na to zgodzić. Poza tym zawsze możesz wrócić. Jeśli jednak pojawią się inne problemy, możesz o nich zapomnieć. A potem upoluje cię duch przeszłości.
A teraz, co najlepiej zrobić po uzyskaniu prawidłowych wyników?
Sprawdź rzeczywisty plan wykonania lub Statystyki zapytań na żywo !
To ostatnie jest dobre, jeśli zapytanie działa wolno i chcesz zobaczyć, co dzieje się w każdej sekundzie przetwarzania wierszy.
Czasami sytuacja zmusi cię do natychmiastowego sprawdzenia planu. Aby rozpocząć, naciśnij Control+M lub kliknij Dołącz rzeczywisty plan wykonania z paska narzędzi SQL Server Management Studio. Jeśli wolisz dbForge Studio dla SQL Server, przejdź do Query Profiler – zawiera te same informacje + kilka dzwonków i gwizdków, których nie znajdziesz w SSMS.
Widzieliśmy Rzeczywisty plan wykonania . Przejdźmy dalej.
Czy brakuje indeksu lub zaleceń dotyczących indeksu?
Brakujący indeks jest łatwy do zauważenia – natychmiast otrzymasz ostrzeżenie.
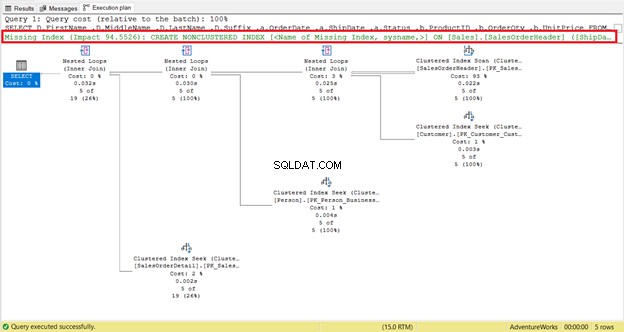
Aby uzyskać natychmiastowy kod do utworzenia indeksu, kliknij prawym przyciskiem myszy Brak indeksu wiadomość (w ramce na czerwono). Następnie wybierz Brakujące szczegóły indeksu . Pojawi się nowe okno zapytania z kodem do utworzenia brakującego indeksu. Utwórz indeks.
Ta część jest łatwa do naśladowania. To dobry punkt wyjścia do szybszej realizacji. Ale w niektórych przypadkach nie przyniesie to efektu. Czemu? Niektórych kolumn potrzebnych w zapytaniu nie ma w indeksie. Dlatego powróci do skanowania indeksu klastrowego.
Po utworzeniu indeksu należy ponownie sprawdzić plan wykonania, aby sprawdzić, czy potrzebne są dołączone kolumny. Następnie odpowiednio dostosuj indeks i ponownie uruchom zapytanie. Następnie ponownie sprawdź plan wykonania.
Ale co, jeśli nie brakuje indeksu?
Przeczytaj plan wykonania
Aby rozpocząć, musisz znać kilka podstawowych rzeczy:
- Operatorzy
- Właściwości
- Kierunek czytania
- Ostrzeżenia
OPERATORZY
Optymalizator zapytań używa pewnego rodzaju miniprogramów zwanych operatorami. Widziałeś niektóre z nich na Rysunku 4 – Poszukiwanie indeksu klastrowego , Skanowanie indeksu klastrowego , Pętle zagnieżdżone i Wybierz .
Aby uzyskać pełną listę z nazwami, ikonami i opisami, możesz sprawdzić to odniesienie od firmy Microsoft.
WŁAŚCIWOŚCI
Diagramy graficzne nie wystarczą, aby zrozumieć, co dzieje się za kulisami. Musisz głębiej zagłębić się w właściwości każdego operatora. Na przykład Skanowanie indeksu klastrowego na rysunku 4 ma następujące właściwości:
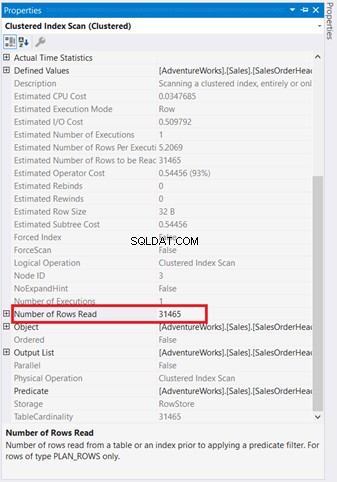
Jeśli przyjrzysz się temu uważnie, Skanowanie indeksu klastrowego operator jest okropny. Jak pokazuje rysunek 5, odczytuje on 31 465 wierszy, ale ostateczny zestaw wyników to tylko 5 wierszy. Dlatego na rysunku 4 znajduje się zalecenie dotyczące indeksu, aby zmniejszyć liczbę odczytanych wierszy. Logiczne odczyty zapytania są również wysokie, co wyjaśnia dlaczego.
Aby dowiedzieć się więcej o tych właściwościach, zapoznaj się z listą wspólnych właściwości operatorów i właściwości planu.
KIERUNEK CZYTANIA
Generalnie przypomina to czytanie japońskiej mangi – od prawej do lewej. Postępuj zgodnie ze strzałkami, które wskazują w lewo. Oto prosty przykład z dbForge Studio dla SQL Server.
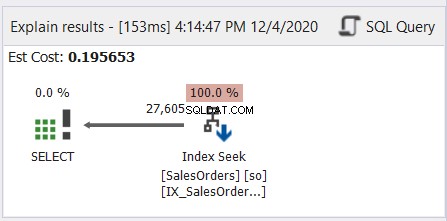
Jak pokazuje Rysunek 6, strzałka wskazuje w lewo od operatora Index Seek do operatora SELECT.
Jednak czytanie od prawej do lewej może nie zawsze być poprawne. Zobacz Rysunek 7 z przykładem z SSMS:
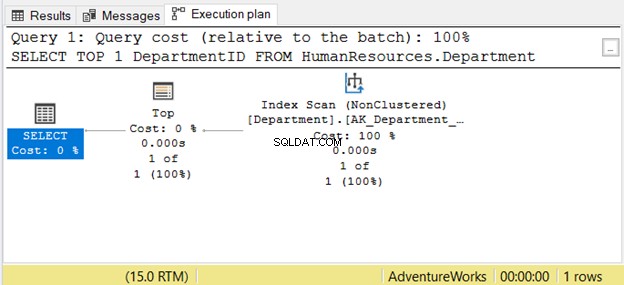
Jeśli przeczytasz go od prawej do lewej, zobaczysz, że skanowanie indeksu wyjście operatora to 1 z 1 rzędu. Skąd mógł wiedzieć tylko 1 wiersz do pobrania? Wynika to z Najwyższej operator. To nas zmyli, jeśli będziemy czytać od prawej do lewej.
Aby lepiej zrozumieć ten przypadek, przeczytaj go jako „operator SELECT używa Top do pobrania 1 wiersza za pomocą skanowania indeksu”. Od lewej do prawej.
Czego powinniśmy użyć? Od prawej do lewej czy od lewej do prawej?
To trochę jedno i drugie – cokolwiek pomoże ci zrozumieć plan.
Podczas gdy strzałka wskazuje nam kierunek przepływu danych, jej grubość daje nam wskazówki dotyczące rozmiaru danych. Odwołajmy się ponownie do rysunku 4.
Skanowanie indeksu klastrowego przejście do pętli zagnieżdżonej ma grubszą strzałę w porównaniu do innych. Właściwości szczegóły Skanowania indeksu na rysunku 5 powiedz nam, dlaczego jest gruby (odczytano 31 465 wierszy, aby uzyskać końcowy wynik 5 wierszy).
OSTRZEŻENIA
Ikona ostrzeżenia pojawiająca się w operatorze planu wykonania mówi nam, że coś złego stało się z tym operatorem. Może to utrudnić optymalizację zapytań SQL, zużywając więcej zasobów.
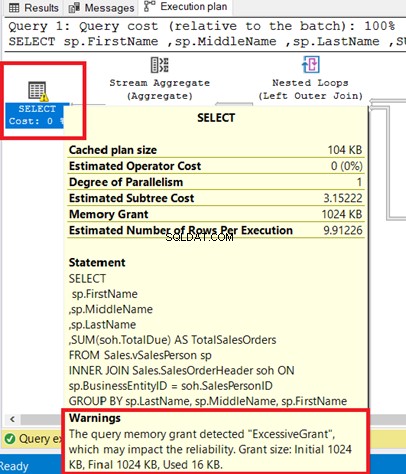
Możesz zobaczyć ostrzeżenie w operatorze SELECT. Najechanie na tego operatora powoduje wyświetlenie komunikatu ostrzegawczego. Nadmierny grant spowodował to ostrzeżenie.
Nadmierny grant dzieje się, gdy używana jest mniejsza ilość pamięci niż została zarezerwowana dla zapytania. Więcej informacji można znaleźć w tej dokumentacji firmy Microsoft.
Rysunek 8 przedstawia zapytanie używane jako INNER JOIN widoku do tabeli. Możesz usunąć ostrzeżenie, dołączając do tabel podstawowych zamiast do widoku.
Teraz, gdy masz już podstawowe pojęcie o czytaniu planów wykonania, jak zdefiniować, co spowalnia Twoje zapytanie?
Poznaj 5 łotrów operatorów wspólnego planu
Opóźnienie w wykonaniu zapytania jest jak przestępstwo. Musisz ścigać i aresztować tych łotrów.
1. Skanowanie indeksu klastrowego lub nieklastrowego
Pierwszym łotrem, o którym wszyscy się dowiadują, jest zgrupowany lub Skanowanie indeksu bez klastrów . Jego powszechna wiedza na temat optymalizacji zapytań SQL, że skany są złe, a wyszukiwania są dobre. Widzieliśmy jeden na rysunku 4. Z powodu braku indeksu Skanowanie indeksu klastrowego odczytuje 31 465, aby uzyskać 5 wierszy.
Jednak nie zawsze tak jest. Rozważ 2 zapytania na tej samej tabeli na rysunku 9. Jedno będzie miało wyszukiwanie, a drugie skanowanie.
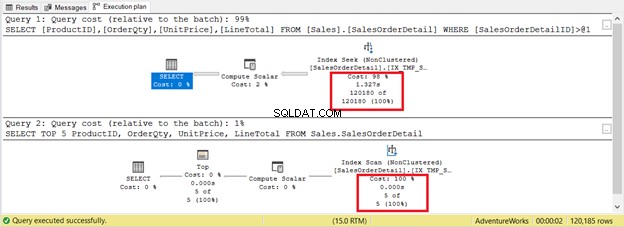
Jeśli oprzesz kryteria tylko na liczbie rekordów, skanowanie indeksu wygrywa z tylko 5 rekordami w porównaniu do 120 180. Wyszukiwanie indeksu potrwa dłużej.
Oto kolejny przypadek, w którym skanowanie lub wyszukiwanie prawie nie ma znaczenia. Zwracają te same 6 rekordów z tej samej tabeli. Odczyty logiczne są takie same, a upływający czas w obu przypadkach wynosi zero. Tabela jest bardzo mała i zawiera tylko 6 rekordów. Dołącz rzeczywisty plan wykonania i uruchom poniższe stwierdzenia.
-- Run this with Include Actual Execution Plan
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT AddressTypeID, Name
FROM Person.AddressType
WHERE AddressTypeID >= 1
ORDER BY AddressTypeID DESC
Następnie zapisz plan wykonania do późniejszego porównania. Kliknij prawym przyciskiem myszy plan wykonania> Zapisz plan wykonania jako .
Teraz uruchom poniższe zapytanie.
SELECT AddressTypeID, Name
FROM Person.AddressType
ORDER BY AddressTypeID DESC
SET STATISTICS IO OFF
GO
Następnie kliknij prawym przyciskiem myszy plan wykonania i wybierz Porównaj plan pokazowy . Następnie wybierz zapisany wcześniej plik. Powinieneś mieć takie same dane wyjściowe, jak na Rysunku 10 poniżej.
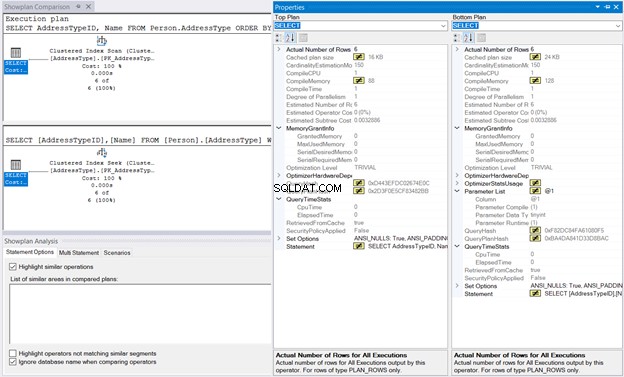
MemoryGrant i QueryTimeStats są takie same. 128 KB Pamięć kompilacji używane w Clustered Index Seek w porównaniu do 88 KB skanowania indeksu klastrowego jest prawie znikome. Bez tych liczb do porównania, wykonanie będzie takie samo.
2. Unikanie skanowania tabeli
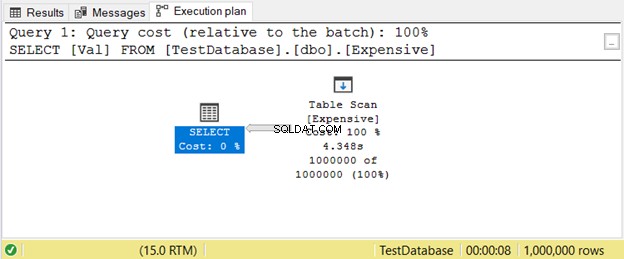
Dzieje się tak, gdy nie masz indeksu. Zamiast szukać wartości za pomocą indeksu, SQL Server będzie skanować wiersze jeden po drugim, aż otrzyma to, czego potrzebujesz w zapytaniu. Spowoduje to spore opóźnienie na dużych stołach. Prostym rozwiązaniem jest dodanie odpowiedniego indeksu.
Oto przykład planu wykonania z Skanowaniem tabeli operator na rysunku 11.
3. Zarządzanie wydajnością sortowania
Jak wynika z nazwy, zmienia kolejność wierszy. Może to być kosztowna operacja.
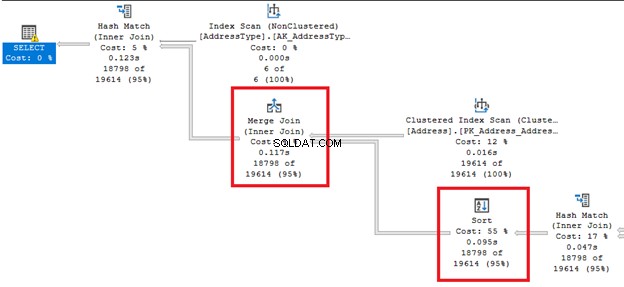
Spójrz na te grube linie strzałek z prawej i lewej strony Sortuj operator. Ponieważ optymalizator zapytań zdecydował się na łączenie scalające , sortowanie jest wymagane. Zauważ również, że ma najwyższy procent kosztów wszystkich operatorów (55%).
Sortowanie może być bardziej kłopotliwe, jeśli SQL Server musi kilkakrotnie uporządkować wiersze. Możesz uniknąć tego operatora, jeśli Twoja tabela jest wstępnie posortowana na podstawie wymagań zapytania. Możesz też podzielić jedno zapytanie na wiele.
4. Wyeliminuj kluczowe wyszukiwania
Na powyższym rysunku 4 SQL Server zalecał dodanie kolejnego indeksu. Zrobiłem to, ale nie dało mi to dokładnie tego, czego chciałem. Zamiast tego dał mi Poszukiwanie indeksu do nowego indeksu w połączeniu z Key Lookup operatora.
Tak więc nowy indeks dodał dodatkowy krok.
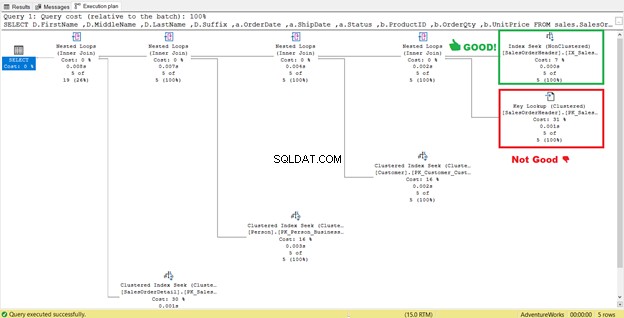
Do czego służy to Wyszukiwanie klucza operator tak?
Procesor zapytań użył nowego indeksu nieklastrowego, zaznaczonego na zielono na rysunku 13. Ponieważ nasze zapytanie wymaga kolumn, których nie ma w nowym indeksie, musi pobrać te dane za pomocą Wyszukiwania klucza z indeksu klastrowego. Skąd to wiemy? Najechanie myszą na Wyszukiwanie klawiszy ujawnia niektóre ze swoich właściwości i potwierdza naszą rację.
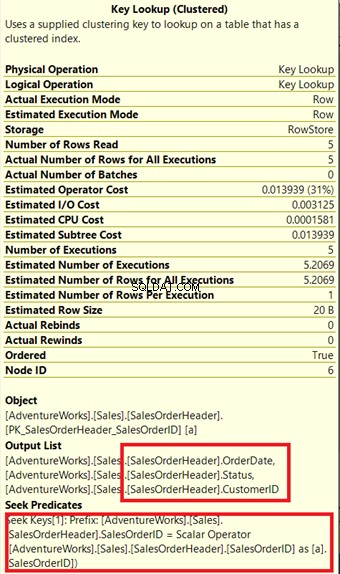
Na rysunku 14 zwróć uwagę na listę wyników. Musimy pobrać 3 kolumny, używając PK_SalesOrderHeader_SalesOrderID indeks klastrowy. Aby to usunąć, musisz uwzględnić te kolumny w nowym indeksie. Oto nowy plan po uwzględnieniu tych kolumn.
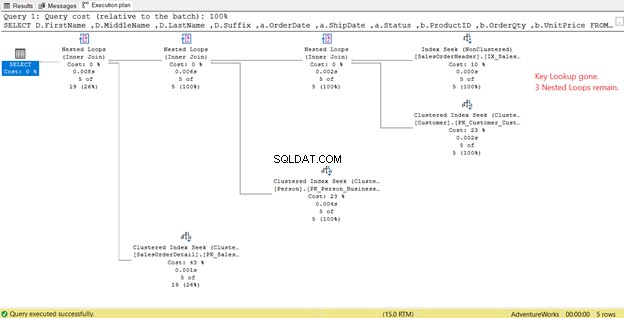
Na rysunku 14 widzieliśmy 4 pętle zagnieżdżone . Czwarty jest potrzebny do dodanego Wyszukiwania klucza . Ale po dodaniu 3 kolumn jako Uwzględnione kolumny do nowego indeksu, tylko 3 pętle zagnieżdżone pozostaną, a Wyszukiwanie klucza jest usunięty. Nie potrzebujemy żadnych dodatkowych kroków.
5. Równoległość w planie wykonania SQL Server
Do tej pory widziałeś plany egzekucji w seryjnych egzekucjach. Ale oto plan, który wykorzystuje równoległe wykonanie. Oznacza to, że optymalizator zapytań wykorzystuje więcej niż 1 procesor do uruchomienia zapytania. Kiedy używamy wykonywania równoległego, widzimy Parallelism operatorów w planie, a także inne zmiany.
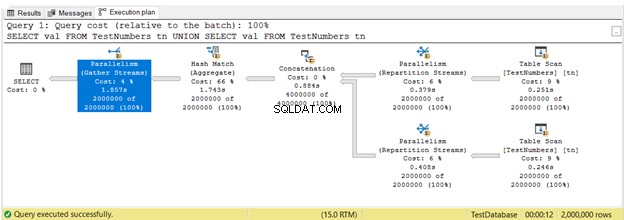
Na rysunku 16, 3 Równoległość użyto operatorów. Zauważ również, że Skanowanie tabeli ikona operatora jest nieco inna. Dzieje się tak, gdy używane jest wykonywanie równoległe.
Paralelizm nie jest z natury zły. Zwiększa szybkość zapytań dzięki wykorzystaniu większej liczby rdzeni procesora. Jednak zużywa więcej zasobów procesora. Gdy wiele zapytań używa paralelizmów, spowalnia to serwer. Możesz sprawdzić próg kosztów dla ustawienia równoległości w swoim SQL Server.
5. Najlepsze praktyki dotyczące optymalizacji zapytań SQL
Do tej pory zajmowaliśmy się optymalizacją zapytań SQL za pomocą metod, które odkrywają trudne do zauważenia problemy. Ale są sposoby, aby to wykryć w kodzie. Oto kilka zapachów kodu w SQL.
Za pomocą WYBIERZ *
W pośpiechu? Wtedy wpisanie * może być łatwiejsze niż określanie nazw kolumn. Jest jednak pewien haczyk. Kolumny, których nie potrzebujesz, opóźnią Twoje zapytanie.
Jest dowód. Przykładowe zapytanie, którego użyłem na rysunku 15, to:
USE AdventureWorks
GO
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Już go zoptymalizowaliśmy. Ale zmieńmy to na WYBIERZ *
USE AdventureWorks
GO
SELECT *
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = d.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'
Jest krótsza, dobrze, ale sprawdź poniższy plan wykonania:
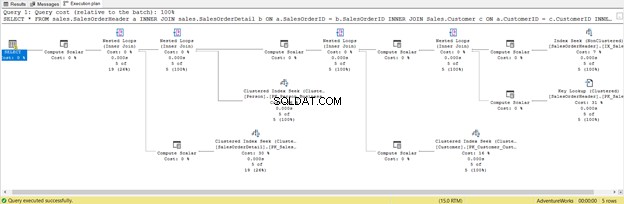
Jest to konsekwencja uwzględnienia wszystkich kolumn, nawet tych, których nie potrzebujesz. Zwrócił Wyszukiwanie klucza i wiele obliczeń skalarnych . Krótko mówiąc, to zapytanie ma duże obciążenie i w rezultacie będzie opóźnione. Zwróć też uwagę na ostrzeżenie w operatorze SELECT. Wcześniej go tam nie było. Co za strata!
Funkcje w klauzuli WHERE lub JOIN
Innym zapachem kodu jest posiadanie funkcji w klauzuli WHERE. Rozważ następujące 2 instrukcje SELECT mające ten sam zestaw wyników. Różnica tkwi w klauzuli WHERE.
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE YEAR(a.ShipDate) = 2011
AND MONTH(a.ShipDate) = 7
SELECT
D.FirstName
,D.MiddleName
,D.LastName
,D.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM sales.SalesOrderHeader a
INNER JOIN sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate BETWEEN '07/1/2011' AND '07/31/2011'
Pierwsza instrukcja SELECT używa funkcji daty YEAR i MONTH do wskazania dat wysyłki w lipcu 2011 r. Druga instrukcja SELECT używa operatora BETWEEN z literałami daty.
Pierwsza instrukcja SELECT będzie miała plan wykonania podobny do przedstawionego na rysunku 4, ale bez rekomendacji indeksu. Drugi będzie miał lepszy plan wykonania podobny do rysunku 15.
Lepiej zoptymalizowany jest oczywisty.
Korzystanie z symboli wieloznacznych
Jak dzikie symbole wieloznaczne mogą wpływać na optymalizację zapytań SQL? Miejmy przykład.
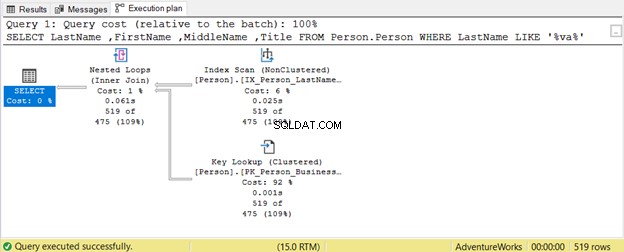
Zapytanie próbuje znaleźć ciąg znaków w nazwisku w dowolnej pozycji. Dlatego Nazwisko LIKE „%va%” . Jest to nieefektywne w przypadku dużych tabel, ponieważ wiersze będą sprawdzane jeden po drugim pod kątem obecności tego ciągu. Dlatego Skanowanie indeksu Jest używane. Ponieważ żaden indeks nie zawiera Tytułu kolumna, Wyszukiwanie klucza jest również używany.
Można to naprawić projektowo.
Czy aplikacja do wykonywania połączeń tego wymaga? A może wystarczy użyć LIKE „va%”?
LIKE „va%” używa szukania indeksu ponieważ tabela ma indeks na nazwisko , imię i drugie imię .
Czy możesz również dodać więcej filtrów w klauzuli WHERE, aby zmniejszyć odczyt rekordów?
Twoje odpowiedzi na te pytania pomogą Ci naprawić to zapytanie.
Niejawna konwersja
SQL Server wykonuje niejawną konwersję za kulisami w celu uzgodnienia typów danych podczas porównywania wartości. Na przykład wygodnie jest przypisać liczbę do kolumny ciągu bez cudzysłowów. Ale jest pewien haczyk. Efekt jest podobny, gdy używasz funkcji w klauzuli WHERE.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
WHERE NationalIDNumber = 56920285
NationalIDNumner to NVARCHAR(15), ale jest utożsamiane z liczbą. Będzie działać pomyślnie z powodu niejawnej konwersji. Ale zwróć uwagę na plan wykonania na rysunku 19 poniżej.
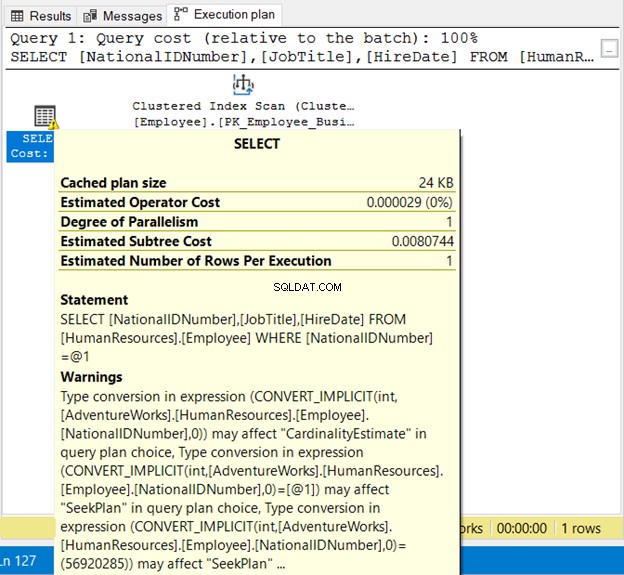
Widzimy tutaj 2 złe rzeczy. Po pierwsze, ostrzeżenie. Następnie Skanowanie indeksu . Skanowanie indeksu nastąpiło z powodu niejawnej konwersji. Dlatego pamiętaj, aby ujmować ciągi w cudzysłowy lub testować wartości literałów z tym samym typem danych, co kolumna.
Wnioski dotyczące optymalizacji zapytań SQL
Otóż to. Czy podstawy optymalizacji zapytań SQL sprawiły, że poczułeś się trochę gotowy na swoje zapytania? Zróbmy podsumowanie.
- Jeśli chcesz zoptymalizować swoje zapytania, zacznij od dobrego projektu bazy danych.
- Jeśli baza danych jest już w produkcji, wykryj problematyczne zapytania za pomocą standardowych raportów SQL Server.
- Dowiedz się, jak duży jest wpływ powolnego zapytania dzięki logicznym odczytom z STATISTICS IO.
- Zagłęb się w historię swojego powolnego zapytania dzięki Planom realizacji.
- Obejrzyj 4 zapachy kodu, które spowalniają Twoje zapytania.
Istnieją inne wskazówki dotyczące optymalizacji zapytań SQL, dzięki którym powolne zapytanie będzie działać szybko. Jak powiedziałem na początku, to duży temat. Daj nam więc znać w sekcji Komentarze, co jeszcze przegapiliśmy.
A jeśli podoba Ci się ten post, udostępnij go na swoich ulubionych platformach społecznościowych.
Więcej optymalizacji zapytań SQL z poprzednich artykułów
Jeśli potrzebujesz więcej przykładów, oto kilka przydatnych postów związanych z technikami optymalizacji zapytań w SQL Server.
- Czy podzapytania mają negatywny wpływ na wydajność? Zapoznaj się z Prostym przewodnikiem korzystania z podzapytań w SQL Server .
- Korzystanie z HierarchyID a projektowanie nadrzędne/podrzędne — co jest szybsze? Odwiedź stronę Jak korzystać z SQL Server HierarchyID za pomocą prostych przykładów .
- Czy zapytania do bazy danych wykresów mogą przewyższać ich relacyjne odpowiedniki w systemie rekomendacji w czasie rzeczywistym? Sprawdź Jak korzystać z funkcji bazy danych wykresów SQL Server .
- Co jest szybsze:COALESCE czy ISNULL? Dowiedz się w Najważniejszych odpowiedziach na 5 palących pytań dotyczących funkcji SQL COALESCE .
- SELECT FROM Widok a SELECT FROM Tabele podstawowe — która z nich będzie działać szybciej? Odwiedź 3 najważniejsze wskazówki, które musisz znać, aby szybciej pisać widoki SQL .
- CTE a tabele tymczasowe a podzapytania. Dowiedz się, który z nich wygra w Wszystko, co musisz wiedzieć o SQL CTE w jednym miejscu .
- Używanie SQL SUBSTRING w klauzuli WHERE – pułapka wydajności? Sprawdź, czy to prawda z przykładami w Jak analizować ciągi jak profesjonalista za pomocą funkcji SQL SUBSTRING()?
- SQL UNION ALL jest szybszy niż UNION. Dowiedz się, dlaczego w Ściągawce SQL UNION z 10 łatwymi i przydatnymi wskazówkami .