W tym artykule omówimy typowe błędy, z którymi mogą się zetknąć początkujący programiści podczas projektowania kodu T-SQL. Ponadto przyjrzymy się najlepszym praktykom i kilku przydatnym wskazówkom, które mogą pomóc w pracy z SQL Server, a także obejściach poprawiających wydajność.
Spis treści:
1. Typy danych
2. *
3. Alias
4. Kolejność kolumn
5. NOT IN vs NULL
6. Format daty
7. Filtr dat
8. Kalkulacja
9. Konwersja niejawna
10. LIKE i indeks stłumiony
11. Unicode a ANSI
12. UKŁADAJ
13. UKŁADANIE BINARNE
14. Styl kodu
15. [zmienna]znak
16. Długość danych
17. ISNULL vs COALESCE
18. Matematyka
19. UNIA vs UNIA WSZYSTKO
20. Przeczytaj ponownie
21. Podzapytanie
22. PRZYPADEK KIEDY
23. Funkcja skalarna
24. WIDOKI
25. KURSORY
26. STRING_CONCAT
27. Wstrzyknięcie SQL
Typy danych
Głównym problemem, z którym mamy do czynienia podczas pracy z SQL Server, jest nieprawidłowy wybór typów danych.
Załóżmy, że mamy dwie identyczne tabele:
DECLARE @Pracownik1 TABELA (Identyfikator pracownika BIGINT PRIMARY KEY , IsMale VARCHAR(3) , Data urodzenia VARCHAR(20))WSTAW DO @Pracownik1WARTOŚCI (123, 'TAK', '2012-09-01')DECLARE @TABELAIDPracownika2 ( INT PRIMARY KEY , IsMale BIT , Data urodzenia ) WSTAW W @Employees2VALUES (123, 1, '2012-09-01')
Wykonajmy zapytanie, aby sprawdzić, jaka jest różnica:
DECLARE @DataUrodzenia DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE DataUrodzenia =@DataUrodzeniaSELECT * FROM @DataUrodzenia2 WHERE DataUrodzenia =@DataUrodzenia
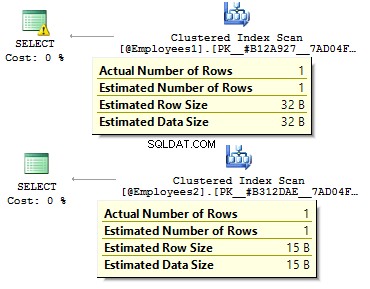
W pierwszym przypadku typy danych są bardziej nadmiarowe niż mogłoby być. Dlaczego powinniśmy przechowywać wartość bitową jako TAK/NIE wiersz? Dlaczego powinniśmy przechowywać datę w rzędzie? Dlaczego powinniśmy używać BIGINT dla pracowników w tabeli, a nie INT ?
Prowadzi to do następujących wad:
- Tabele mogą zajmować dużo miejsca na dysku;
- Musimy przeczytać więcej stron i umieścić więcej danych w BufferPool do obsługi danych.
- Słaba wydajność.
*
Miałem do czynienia z sytuacją, w której programiści pobierają wszystkie dane z tabeli, a następnie po stronie klienta używają DataReader aby wybrać tylko wymagane pola. Nie polecam korzystania z tego podejścia:
USE AdventureWorks2014GOSET STATISTICS TIME, IO ONSELECT *FROM Osoba.PersonSELECT BusinessEntityID , FirstName , SecondName , LastNameFROM Person. PersonSET STATISTICS TIME, IO OFF
Będzie znaczna różnica w czasie wykonania zapytania. Ponadto indeks pokrycia może zmniejszyć liczbę logicznych odczytów.
Tabela „Osoba”. Liczba skanów 1, odczyty logiczne 3819, odczyty fizyczne 3, ... Czasy wykonania programu SQL Server:czas procesora =31 ms, czas trwania =1235 ms.Tabela „Osoba”. Liczba skanów 1, odczyty logiczne 109, odczyty fizyczne 1, ... Czasy wykonywania programu SQL Server:czas procesora =0 ms, czas, który upłynął =227 ms.
Alias
Stwórzmy tabelę:
UŻYJ AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') NIE JEST TABELĄ UPUSZCZENIA NULL Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency ( CurrencyCode NCHAR(3) PRIMARY KEY)WSTAW DO Sales.UserCurrencyVALUES ('USD') Załóżmy, że mamy zapytanie, które zwraca liczbę identycznych wierszy w obu tabelach:
SELECT COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency )
Wszystko będzie działać zgodnie z oczekiwaniami, dopóki ktoś nie zmieni nazwy kolumny w Sales.UserCurrency tabela:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Następnie wykonamy zapytanie i zobaczymy, że otrzymujemy wszystkie wiersze w Sales.Currency tabeli, zamiast 1 wiersza. Podczas budowania planu wykonania, na etapie wiązania, SQL Server sprawdza kolumny Sales.UserCurrency, nie znajdzie CurrencyCode tam i decyduje, że ta kolumna należy do Sales.Currency stół. Następnie optymalizator usunie CurrencyCode =CurrencyCode stan.
Dlatego zalecam używanie aliasów:
SELECT COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u )
Kolejność kolumn
Załóżmy, że mamy stół:
IF OBJECT_ID('dbo.DatePeriod') NIE JEST NULL TABELA UPUSZCZANIA dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod ( Data Rozpoczęcia DATA , Data zakończenia DATA) Zawsze wstawiamy tam dane na podstawie informacji o kolejności kolumn.
WSTAW DO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Załóżmy, że ktoś zmienił kolejność kolumn:
CREATE TABLE dbo.DatePeriod ( EndDate DATA , StartDate DATA)
Dane zostaną wstawione w innej kolejności. W takim przypadku dobrym pomysłem jest jawne określenie kolumn w instrukcji INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT „2015-01-01”, „2015-01-31”
Oto kolejny przykład:
WYBIERZ TOP(1) * Z dbo.DatePeriodZAMÓW DO 2 PIENIĘDZY
Na jakiej kolumnie będziemy porządkować dane? Będzie to zależeć od kolejności kolumn w tabeli. W przypadku zmiany kolejności otrzymujemy błędne wyniki.
NOT IN vs NULL
Porozmawiajmy o NIE W oświadczenie.
Na przykład musisz napisać kilka zapytań:zwróć rekordy z pierwszej tabeli, których nie ma w drugiej tabeli i wers. Zwykle młodzi programiści używają IN i NIE W :
ZADEKLARUJ TABELĘ @t1 (t1 INT, UNIKALNE ZGROMADZONE(t1))WSTAW W WARTOŚCI @t1 (1), (2)ZADEKLARUJ @t2 TABELĘ (t2 INT, UNIKATOWE ZGRUPOWANIE(t2))WSTAW W WARTOŚCI @t2 (1 )SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2)SELECT *FROM @t1WHERE t1 IN (SELECT t2 FROM @t2)
Pierwsze zapytanie zwróciło 2, drugie – 1. Następnie dodamy kolejną wartość w drugiej tabeli – NULL :
WSTAW W WARTOŚCI @t2 (1), (NULL)
Podczas wykonywania zapytania z NIE W , nie otrzymamy żadnych wyników. Dlaczego IN działa, a NIE w nie? Powodem jest to, że SQL Server używa TRUE , FAŁSZ i NIEZNANE logika podczas porównywania danych.
Podczas wykonywania zapytania SQL Server interpretuje warunek IN w następujący sposób:
a IN (1, NULL) ==a=1 LUB a=NULL
NIE W :
a NOT IN (1, NULL) ==a<>1 AND a<>NULL
Porównując dowolną wartość z NULL, SQL Server zwraca NIEZNANE. Albo 1=NULL lub NULL=NULL – oba dają wynik NIEZNANE. O ile w wyrażeniu mamy AND, obie strony zwracają NIEZNANE.
Zaznaczam, że ten przypadek nie jest rzadki. Na przykład oznaczysz kolumnę jako NOT NULL. Po chwili inny programista postanawia zezwolić na NULL dla tę kolumnę. Może to prowadzić do sytuacji, w której raport klienta przestaje działać po wstawieniu wartości NULL do tabeli.
W takim przypadku polecam wykluczenie wartości NULL:
SELECT *FROM @t1WHERE t1 NOT IN ( SELECT t2 FROM @t2 GDZIE t2 NIE JEST NULL )
Ponadto można użyć OPRÓCZ :
WYBIERZ * Z @t1EXCEPTSELECT * Z @t2
Alternatywnie możesz użyć NIE ISTNIEJE :
SELECT *FROM @t1GDZIE NIE ISTNIEJE( SELECT 1 FROM @t2 WHERE t1 =t2 )
Która opcja jest bardziej preferowana? Druga opcja z NIE ISTNIEJE wydaje się być najbardziej produktywny, ponieważ generuje bardziej optymalny predicate pushdown operatora, aby uzyskać dostęp do danych z drugiej tabeli.
W rzeczywistości wartości NULL mogą zwrócić nieoczekiwany wynik.
Rozważ to na tym konkretnym przykładzie:
USE AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color ='Szary'SELECT COUNT_BIG(*)FROM Production.ProduktWHERE Kolor <> 'Szary'
Jak widać, nie uzyskałeś oczekiwanego wyniku, ponieważ wartości NULL mają oddzielne operatory porównania:
SELECT COUNT_BIG(*)FROM Produkcja.ProduktWHERE Kolor IS NULLSELECT COUNT_BIG(*)FROM Produkcja.ProduktWHERE Kolor NIE JEST NULL
Oto kolejny przykład z CHECK ograniczenia:
IF OBJECT_ID('tempdb.dbo.#temp') NIE JEST NULL DROP TABLE #tempGOCREATE TABLE #temp ( Color VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Color IN ('Black', 'White') )) Tworzymy tabelę z uprawnieniami do wstawiania tylko białych i czarnych kolorów:
WSTAW W WARTOŚCI #temp ('Czarny')(1 wiersz(e) dotyczy) Wszystko działa zgodnie z oczekiwaniami.
INSERT INTO #temp VALUES ('Red') Instrukcja INSERT kolidowała z ograniczeniem CHECK... Instrukcja została zakończona. Teraz dodajmy NULL:
WSTAW W WARTOŚCI #temp (NULL) (1 wiersz(e) dotyczy)
Dlaczego ograniczenie CHECK przekazał wartość NULL? Cóż, powodem jest to, że jest wystarczająco dużo NIE FAŁSZ warunek dokonania zapisu. Rozwiązaniem jest jawne zdefiniowanie kolumny jako NOT NULL lub użyj NULL w ograniczeniu.
Format daty
Bardzo często możesz mieć problemy z typami danych.
Na przykład musisz uzyskać aktualną datę. W tym celu możesz użyć funkcji POBIERZ DATĘ:
WYBIERZ POBIERZDATĘ()
Następnie po prostu skopiuj zwrócony wynik w wymaganym zapytaniu i usuń czas:
WYBIERZ * Z sys.objectsWHERE data_tworzenia <'14.11.2016'
Czy to prawda?
Data jest określona przez stałą łańcuchową:
SET LANGUAGE EnglishSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -grudzień-2016'SELECT @d1, @d2, @d3, @d4
Wszystkie wartości mają interpretację jednowartościową:
----------- ----------- ----------- -----------2016-12 -05 2016-05-12 2016-05-12 05.12.2016
Nie spowoduje to żadnych problemów, dopóki zapytanie z tą logiką biznesową nie zostanie wykonane na innym serwerze, na którym ustawienia mogą się różnić:
SET DATEFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dec -2016'SELECT @d1, @d2, @d3, @d4
Jednak te opcje mogą prowadzić do nieprawidłowej interpretacji daty:
----------- ----------- ----------- -----------2016-05 -12 05.12.2016 05.12.2016 05.12.2016
Co więcej, ten kod może prowadzić zarówno do widocznego, jak i ukrytego błędu.
Rozważmy następujący przykład. Musimy wstawić dane do tabeli testowej. Na serwerze testowym wszystko działa idealnie:
ZADEKLARUJ @t TABELA (DATA GODZINA) WSTAW W WARTOŚCI @t ('13.05.2016') Mimo to po stronie klienta to zapytanie będzie powodować problemy, ponieważ ustawienia naszego serwera są różne:
DECLARE @t TABLE (a DATETIME)SET DATEFORMAT DMYINSERT IN @t VALUES ('13.05.2016') Wiadomość 242, poziom 16, stan 3, wiersz 28. Konwersja typu danych varchar na typ danych data/godzina skutkowała wartością spoza zakresu.
Zatem jakiego formatu powinniśmy użyć do deklarowania stałych daty? Aby odpowiedzieć na to pytanie, wykonaj to zapytanie:
SET DATEFORMAT YMDSET LANGUAGE EnglishDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-sty-2016' , @d4 DATETIME ='20160112 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='12.01.2016' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12.01.2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
Interpretacja stałych może się różnić w zależności od zainstalowanego języka:
----------- ----------- ----------- -----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Dlatego lepiej jest skorzystać z dwóch ostatnich opcji. Chciałbym również dodać, że jednoznaczne określenie daty nie jest dobrym pomysłem:
SET LANGUAGE FrenchDECLARE @d DATETIME =„Wiadomość z 12 stycznia 2016 r.” 241, poziom 16, stan 1, wiersz 29 Sprawdź konwersję daty i/lub heure na partir d'une chaîne de caractères.
Dlatego jeśli chcesz, aby stałe z datami były poprawnie interpretowane, musisz określić je w następującym formacie RRRRMMDD.
Ponadto chciałbym zwrócić uwagę na zachowanie niektórych typów danych:
SET LANGUAGE EnglishSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01- 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
W przeciwieństwie do DATETIME, DATE typ jest poprawnie interpretowany z różnymi ustawieniami na serwerze:
---------- ----------2016-01-12 2016-01-12---------- ------- ---2016-01-12 2016-12-01
Filtr daty
Aby przejść dalej, zastanowimy się, jak skutecznie filtrować dane. Zacznijmy od nich DATA CZAS/DATA:
UŻYJ AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Teraz spróbujemy dowiedzieć się, ile wierszy zwraca zapytanie dla określonego dnia:
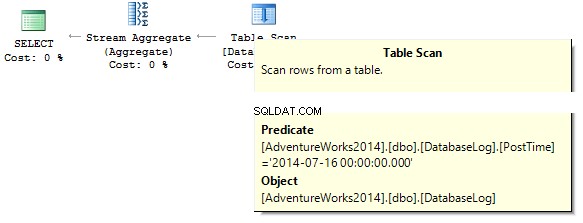
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ='20140716'
Zapytanie zwróci 0. Podczas budowania planu wykonania serwer SQL próbuje rzutować stałą łańcuchową na typ danych kolumny, którą musimy odfiltrować:
Utwórz indeks:
UTWÓRZ INDEKS NIESKLASTRAROWANY IX_PostTime NA dbo.DatabaseLog (PostTime)
Istnieją poprawne i niepoprawne opcje wyprowadzania danych. Na przykład musisz usunąć kolumnę czasu:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Lub musimy określić zakres:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140716' AND PostTime <'20140717'
Biorąc pod uwagę optymalizację, mogę powiedzieć, że te dwa zapytania są najbardziej poprawne. Chodzi o to, że wszystkie konwersje i obliczenia odfiltrowanych kolumn indeksowych mogą drastycznie obniżyć wydajność i wydłużyć czas odczytów logicznych:
Tabela „Dziennik bazy danych”. Liczba skanów 1, odczyty logiczne 7, ... Tabela 'DatabaseLog'. Liczba skanów 1, odczyty logiczne 2, ...
Poczta pole nie było wcześniej uwzględnione w indeksie i nie widzieliśmy żadnej skuteczności w stosowaniu tego poprawnego podejścia do filtrowania. Inną rzeczą jest sytuacja, gdy musimy wyprowadzać dane przez miesiąc:
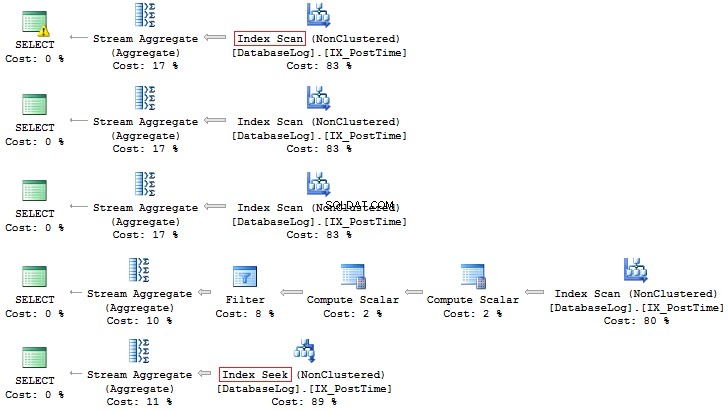
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014 AND DATEPART(MIESIĄC, PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='20140731'boSELECT COUNT_BIG(*EData)FROM PostTime>='20140701' ORAZ PostTime <'20140801'
Ponownie, ta druga opcja jest bardziej preferowana:
Ponadto zawsze możesz utworzyć indeks na podstawie pola obliczeniowego:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') NIE JEST NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH(PostTime.aTyX SISTEDLASTEXDAstMiesiąc W porównaniu z poprzednim zapytaniem różnica w odczytach logicznych może być znacząca (w przypadku dużych tabel):
SET STATISTICS IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE MonthLastDay ='20140731'SET STATgable'.'IO OFFT Liczba skanów 1, odczyty logiczne 7, ... Tabela 'DatabaseLog'. Liczba skanów 1, odczyty logiczne 3, ...
Obliczenia
Jak już zostało omówione, wszelkie obliczenia na kolumnach indeksów zmniejszają wydajność i zwiększają czas odczytów logicznych:
UŻYJ AdventureWorks2014GOSET STATYSTYKI IO ONSELECT IDPodmiotuBiznesowego Osoba.Osoba.OsobaWHERE IDPodmiotuBiznesowego * 2 =10000SELECTIDPodmiotuBiznesowegoFROM Osoba.Osoba.OsobaWHERE IDPodmiotuBiznesowego =2500 * 2SELECT IDPodmiotuBiznesowegoFROM Osoba.OsobaWHERE IDPodmiotuBiznesowego =5000Tabela 'Osoba'. Liczba skanów 1, odczyty logiczne 67, ...Tabela „Osoba”. Liczba skanów 0, odczyty logiczne 3, ...
Jeśli spojrzymy na plany wykonania, to w pierwszym z nich SQL Server wykonuje IndexScan :
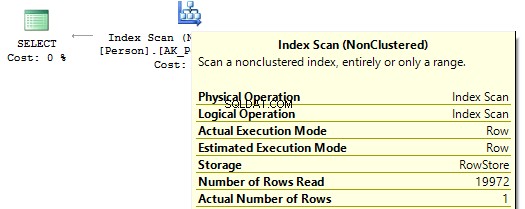
Następnie, gdy nie będzie żadnych obliczeń w kolumnach indeksu, zobaczymy IndexSeek :

Konwersja niejawna
Przyjrzyjmy się tym dwóm zapytaniom, które filtrują według tej samej wartości:
USE AdventureWorks2014GOSELECT Identyfikator jednostki biznesowej, Krajowy numer IDFROM Zasoby ludzkie.PracownikWHERE Krajowy numerID =30845SELECT Identyfikator jednostki biznesowej, Krajowy numerIDFROM Zasoby ludzkie.PracownikWHERE Krajowy numerID ='30845'
Plany wykonania zawierają następujące informacje:
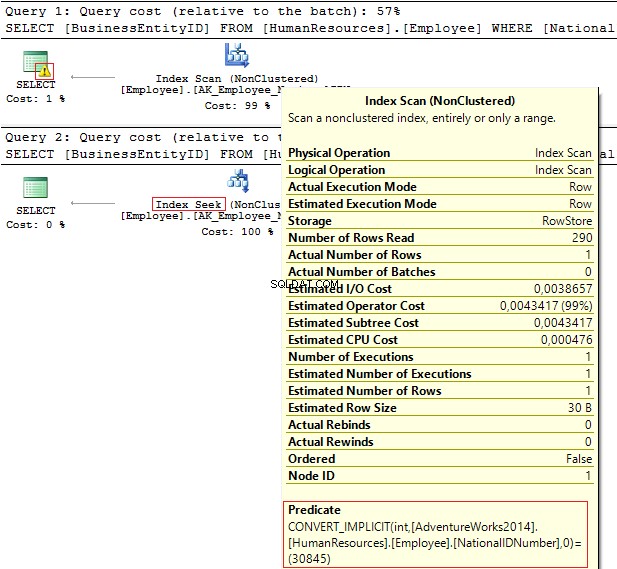
- Ostrzeżenie i IndexScan na pierwszym planie
- Wyszukiwanie indeksu – na drugim.
Tabela „Pracownik”. Liczba skanów 1, odczyty logiczne 4, ...Tabela „Pracownik”. Liczba skanów 0, odczyty logiczne 2, ...
NationalIDNumber kolumna ma NVARCHAR(15) typ danych. Stała, której używamy do filtrowania danych, jest ustawiona jako INT co prowadzi nas do niejawnej konwersji typu danych. Z kolei może obniżyć wydajność. Możesz to monitorować, gdy ktoś modyfikuje typ danych w kolumnie, jednak zapytania nie są zmieniane.
Ważne jest, aby zrozumieć, że niejawna konwersja typu danych może prowadzić do błędów w czasie wykonywania. Na przykład zanim pole PostalCode było numeryczne, okazało się, że kod pocztowy może zawierać litery. W ten sposób zaktualizowano typ danych. Jeśli jednak wstawimy alfabetyczny kod pocztowy, stare zapytanie przestanie działać:
SELECT AdresIDFROM Osoba.[Adres]WHERE KodPocztowy =92700SELECT AdresIDFROM Osoba.[Adres]WHERE KodPocztowy ='92700'Wiadomość 245, Poziom 16, Stan 1, Wiersz 16 Konwersja nie powiodła się podczas konwersji wartości nvarchar 'K4B 1S2' na typ danych wewn.
Innym przykładem jest sytuacja, w której musisz użyć EntityFramework w projekcie, który domyślnie interpretuje wszystkie pola wierszy jako Unicode:
SELECT ID klienta, numer kontaFROM sprzedaż.KlientWHERE numer konta =N'AW00000009'SELECT ID klienta, numer kontaFROM sprzedaż.KlientWHERE numer konta ='AW00000009'
Dlatego generowane są nieprawidłowe zapytania:

Aby rozwiązać ten problem, upewnij się, że typy danych są zgodne.
Polubienie i indeks pominięty
W rzeczywistości posiadanie indeksu pokrycia nie oznacza, że będziesz go efektywnie wykorzystywać.
Sprawdźmy to na tym konkretnym przykładzie. Załóżmy, że musimy wypisać wszystkie wiersze zaczynające się od…
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT WierszAdresu1FROM Osoba.[Adres]WHERE SUBSTRING(WierszAdresu1, 1, 3) ='100'SELECT WierszAdresu1FROM Osoba.[Adres]WHERE LEFT(WierszAdresu1, 3) ='100'SELECT WierszAdresu1FROM Osoba.[ Adres]WHERE CAST(WierszAdresu1 AS CHAR(3)) ='100'WYBIERZ WierszAdresu1FROM Osoba.[Adres]WHERE WierszAdresu1 LIKE '100%'
Otrzymamy następujące odczyty logiczne i plany wykonania:
Tabela „Adres”. Liczba skanów 1, odczyty logiczne 216, ...Tabela „Adres”. Liczba skanów 1, odczyty logiczne 216, ...Tabela „Adres”. Liczba skanów 1, odczyty logiczne 216, ...Tabela „Adres”. Liczba skanów 1, odczyty logiczne 4, ...
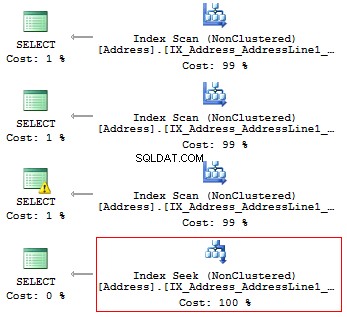
Tak więc, jeśli istnieje indeks, nie powinien zawierać żadnych obliczeń ani konwersji typów, funkcji itp.
Ale co zrobić, jeśli chcesz znaleźć wystąpienie podciągu w ciągu?
SELECT Wiersz Adresu1FROM Osoba.[Adres]WHERE Wiersz Adresu1 LIKE '%100%'v
Do tego pytania wrócimy później.
Unicode a ANSI
Należy pamiętać, że istnieje UNICODE i ANSI smyczki. Typ UNICODE obejmuje NVARCHAR/NCHAR (2 bajty na jeden symbol). Przechowywanie ANSI stringi, możliwe jest użycie VARCHAR/CHAR (1 bajt na 1 symbol). Jest też TEKST/NTEKST , ale nie polecam ich używania, ponieważ mogą zmniejszać wydajność.
Jeśli określisz stałą Unicode w zapytaniu, konieczne jest poprzedzenie jej symbolem N. Aby to sprawdzić, wykonaj następujące zapytanie:
WYBIERZ '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI UNICODE
Jeśli N nie poprzedza stałej, SQL Server spróbuje znaleźć odpowiedni symbol w kodowaniu ANSI. Jeśli nie znajdzie, wyświetli znak zapytania.
UKŁADAJ
Bardzo często podczas wywiadu na stanowisko Middle/Senior DB Developer, ankieter często zadaje pytanie:Czy to zapytanie zwróci dane?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'SELECT @a, @bWHERE @a =@b
To zależy. Po pierwsze, symbol N nie poprzedza stałej łańcuchowej, dlatego będzie interpretowany jako ANSI. Po drugie, wiele zależy od aktualnej wartości COLLATE, która jest zbiorem reguł podczas wybierania i porównywania danych łańcuchowych.
USE [master]GOIF DB_ID('test') NIE JEST NULL POCZĄTEK ALTER DATABASE test SET SINGLE_USER Z WYCOFANIEM NATYCHMIASTOWE DROP DATABASE test ENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1 ) ='Ф'WYBIERZ @a, @bWHERE @a =@b Ta instrukcja COLLATE zwróci znaki zapytania, ponieważ ich symbole są równe:
---- ----? ?
Jeśli zmienimy instrukcję COLLATE na inną instrukcję:
Test ALTER BAZY DANYCH UKŁADANIE cyrylicy_General_100_CI_AS
W takim przypadku zapytanie nie zwróci nic, ponieważ znaki cyrylicy zostaną zinterpretowane poprawnie.
Dlatego jeśli stała łańcuchowa zajmuje UNICODE, konieczne jest ustawienie N przed stałą łańcuchową. Mimo to nie zalecałbym ustawiania go wszędzie z powodów, które omówiliśmy powyżej.
Kolejne pytanie, które należy zadać podczas rozmowy kwalifikacyjnej, dotyczy porównania wierszy.
Rozważ następujący przykład:
DECLARE @a VARCHAR(10) ='TEKST' , @b VARCHAR(10) ='tekst'SELECT IIF(@a =@b, 'PRAWDA', 'FAŁSZ')
Czy te wiersze są równe? Aby to sprawdzić, musimy wyraźnie określić COLLATE:
DECLARE @a VARCHAR(10) ='TEKST' , @b VARCHAR(10) ='tekst' SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b UKŁADAJ Latin1_General_CS_AS, 'TRUE', 'FALSE')
Ponieważ podczas porównywania i zaznaczania wierszy istnieje rozróżnianie wielkości liter (CS) i bez uwzględniania wielkości liter (CI), nie możemy powiedzieć na pewno, czy są one równe. Ponadto istnieją różne sortowania zarówno na serwerze testowym, jak i po stronie klienta.
Zdarza się, że COLLATE bazy docelowej i tempdb nie pasują.
Utwórz bazę danych za pomocą COLLATE:
UŻYJ [master]GOIF DB_ID('test') NIE JEST NULL ROZPOCZNIJ ZMIEŃ test BAZY DANYCH ZESTAW SINGLE_USER Z WYCOFANIEM NATYCHMIASTOWE UPUŚĆ test BAZY DANYCHENDGOCREATE test BAZY DANYCH SORTALUJ albański_100_CS_ASGOUSE testGOCREATE TABELA t (c CHAR(1)) WSTAW W WARTOŚCI t ('a ')GOIF OBJECT_ID('tempdb.dbo.#t1') NIE JEST NULL TABELĄ UPUSZCZANIA #t1IF OBJECT_ID('tempdb.dbo.#t2') NIE JEST NULL TABELĄ UPUSZCZANIA #t2IF OBJECT_ID('tempdb.dbo.#t3') NIE JEST NULL DROP TABLE #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT IN #t1 VALUES ('a')CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)INSERT IN #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'sortowanie ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'porównanie')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'porównanie') FROM tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'porównanie') FROM # t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'porównanie') FROM # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'porównanie') FROM #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'porównanie') FROM @t Tworząc tabelę, dziedziczy ona COLLATE z bazy danych. Jedyną różnicą w przypadku pierwszej tabeli tymczasowej, dla której określamy strukturę jawnie bez funkcji COLLATE, jest to, że dziedziczy ona COLLATE z tempdb baza danych.
------ --------------------------tempdb Cyrillic_General_CI_AStest Albański_100_CS_ASt Albański_100_CS_AS#t1 Cyrillic_General_CI_AS#t2 Albański_100_CS_AS#t3 Albański_100_CS_AS@t Albański_100_CS_AS
Opiszę przypadek, w którym COLLATEs nie pasują do konkretnego przykładu z #t1.
Na przykład dane nie są poprawnie odfiltrowywane, ponieważ SORTOWANIE może nie uwzględniać przypadku:
WYBIERZ *FROM #t1WHERE c ='A'
Ewentualnie możemy mieć konflikt, aby połączyć tabele z różnymi zestawami:
WYBIERZ *Z #t1JOIN t ON [#t1].c =t.c
Wydaje się, że wszystko działa idealnie na serwerze testowym, podczas gdy na serwerze klienckim pojawia się błąd:
Wiadomość 468, poziom 16, stan 9, wiersz 93 Nie można rozwiązać konfliktu sortowania między „Albanian_100_CS_AS” a „Cyrillic_General_CI_AS” w operacji równej.
Aby to obejść, musimy wszędzie ustawić hacki:
WYBIERZ *Z #t1JOIN t ON [#t1].c =t.c UKŁADAJ bazę_domyślną
UKŁADANIE BINARNE
Teraz dowiemy się, jak korzystać z funkcji COLLATE dla Twojej korzyści.
Rozważmy przykład z wystąpieniem podciągu w ciągu:
SELECT Wiersz Adresu1FROM Osoba.[Adres]WHERE Wiersz Adresu1 LIKE '%100%'
Możliwe jest zoptymalizowanie tego zapytania i skrócenie czasu jego wykonania.
Najpierw musimy wygenerować dużą tabelę:
UŻYJ [master]GOIF DB_ID('test') NIE JEST NULL ROZPOCZNIJ ZMIEŃ test BAZY DANYCH ZESTAW SINGLE_USER Z WYCOFANIEM NATYCHMIASTOWE UPUSZCZENIE test BAZY DANYCHENDGOCREATE test BAZY DANYCH ZESTAWANIE Latin1_General_100_CS_ASGOALTER test BAZY DANYCH MODYFIKOWANIE PLIKU (NAZWA =N'test', ROZMIAR =64MB)GOALTER Test BAZY DANYCH MODYFIKUJ PLIK (NAZWA =N'test_log', ROZMIAR =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL)GO;WITH E1(N) AS ( SELECT * FROM ( WARTOŚCI (1),(1),(1),(1),(1),(1),(1),(1),(1),(1) t(N) ), E2(N ) AS (WYBIERZ 1 Z E1 a, E1 b), E4(N) AS (WYBIERZ 1 Z E2 a, E2 b), E8(N) AS (WYBIERZ 1 Z E4 a, E4 b) WSTAW DO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Utwórz kolumny obliczeniowe z binarnymi zestawieniami i indeksami:
ALTER TABELA t DODAJ ansi_bin JAKO GÓRNE(ansi) UKŁADANIE Latin1_General_100_Bin2ALTER TABELA t DODAJ unicod_bin JAKO GÓRNE(unicod) UKŁADANIE Latin1_General_100_BIN2CREATE INDEKS BEZ SKLEJSOWANIA ansi ON t (ansi)DONCREATE INDEXLUT (ansi)DONCREATE . ansi_bin)UTWÓRZ INDEKS NIESKLASTRAROWANY unicod_bin W t (unicod_bin)
Wykonaj proces filtracji:
SET STATISTICS TIME, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATYSTYKI CZAS, IO WYŁĄCZONE
Jak widać, to zapytanie zwraca następujący wynik:
Czasy wykonywania programu SQL Server:Czas procesora =350 ms, czas, który upłynął =354 ms.Czasy wykonywania programu SQL Server:Czas procesora =335 ms, czas, który upłynął =355 ms.Czas wykonywania programu SQL Server:czas procesora =16 ms, czas, który upłynął =18 ms.Czasy wykonywania programu SQL Server:czas procesora =17 ms, upływ czasu =18 ms.
Chodzi o to, że filtrowanie na podstawie porównania binarnego zajmuje mniej czasu. Jeśli więc często i szybko trzeba filtrować występowanie ciągów, to istnieje możliwość przechowywania danych z opcją COLLATE kończącą się na BIN. Należy jednak zauważyć, że we wszystkich binarnych zestawieniach COLATE jest rozróżniana wielkość liter.
Styl kodu
Styl kodowania jest ściśle indywidualny. Mimo to ten kod powinien być po prostu utrzymywany przez innych programistów i zgodny z określonymi regułami.
Utwórz osobną bazę danych i tabelę w środku:
UŻYJ [master]GOIF DB_ID('test') NIE JEST NULL ROZPOCZNIJ ZMIEŃ test BAZY DANYCH ZESTAW SINGLE_USER Z WYCOFANIEM NATYCHMIASTOWE UPUŚĆ test BAZY DANYCHENDGOCREATE test BAZY DANYCH SORTALUJ Latin1_General_CI_ASGOUSE testGOCREATE TABELA dbo.Employee (EmployeeID) INT PRIMARY>
Następnie wpisz zapytanie:
wybierz identyfikator pracownika od pracownika
Teraz zmień opcję COLLATE na dowolną, w której rozróżniana jest wielkość liter:
Test ALTER BAZY DANYCH UKŁADANIE Latin1_General_CS_AI
Następnie spróbuj ponownie wykonać zapytanie:
Wiadomość 208, poziom 16, stan 1, wiersz 19. Nieprawidłowa nazwa obiektu „pracownik”.
Optymalizator używa reguł dla bieżącego COLLATE na etapie wiązania, gdy sprawdza tabele, kolumny i inne obiekty, a także porównuje każdy obiekt drzewa składni z rzeczywistym obiektem katalogu systemowego.
Jeśli chcesz generować zapytania ręcznie, musisz zawsze używać właściwej wielkości liter w nazwach obiektów.
Jeśli chodzi o zmienne, COLLATE są dziedziczone z bazy danych master. Dlatego też, aby z nimi pracować, musisz użyć odpowiedniej wielkości liter:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid
W takim przypadku nie pojawi się błąd:
--------------------------Cyrillic_General_CI_AS-----------1
Mimo to na innym serwerze może pojawić się błąd wielkości liter:
--------------------------Latin1_General_CS_ASMsg 137, Poziom 15, Stan 2, Wiersz 4Musisz zadeklarować zmienną skalarną „@empid”.
[var]znak
Jak wiesz, są naprawione (CHAR , NCHAR ) i zmienna (VARCHAR , NVARCHAR ) typy danych:
DECLARE @a CHAR(20) ='tekst' , @b VARCHAR(20) ='tekst'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'SELECT [a =b] =IIF(@a =@b, 'TRUE', 'FALSE') , [b =a] =IIF(@b =@a, 'PRAWDA', 'FAŁSZ') , [a PODOBNE b] =IIF(@a PODOBNE @b, 'PRAWDA', 'FAŁSZ') , [b PODOBNE a] =IIF(@ b JAK @a, „PRAWDA”, „FAŁSZ”)
Jeśli wiersz ma stałą długość, powiedzmy 20 symboli, ale wpisano tylko 4 symbole, SQL Server domyślnie doda 16 pustych miejsc po prawej stronie:
--- --- ---- ---- ------------ ----------- -----------4 4 20 4 „tekst” „tekst”
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operatora.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
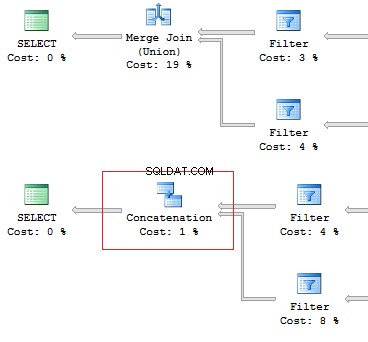
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
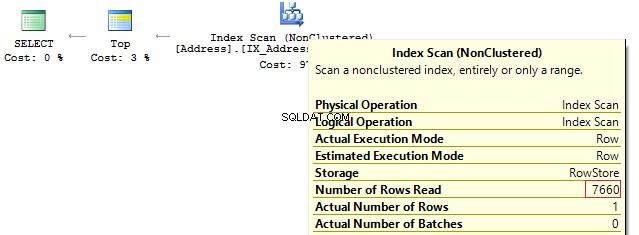
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
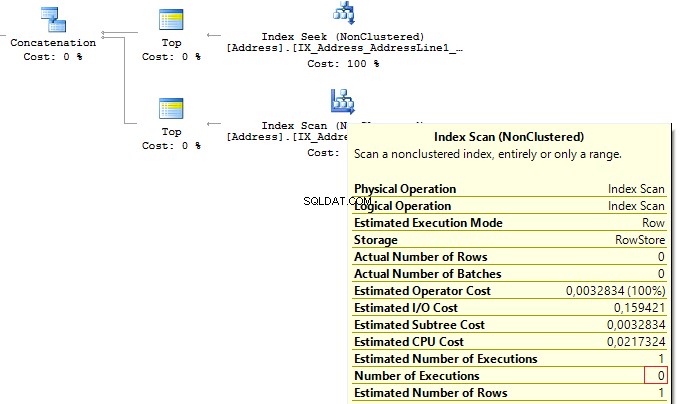
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
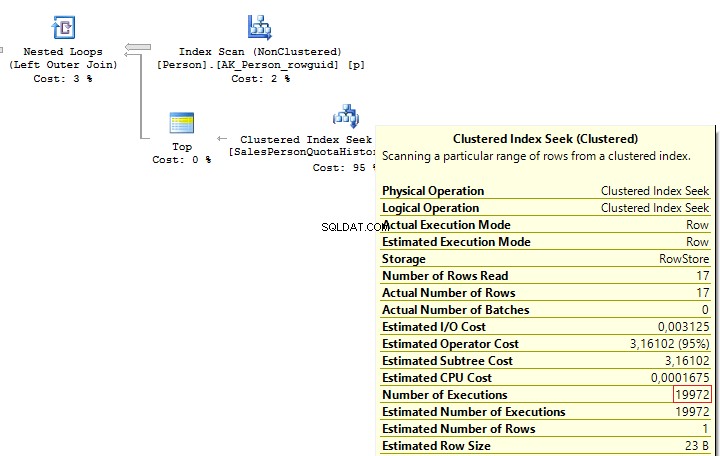
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
We get the following result:
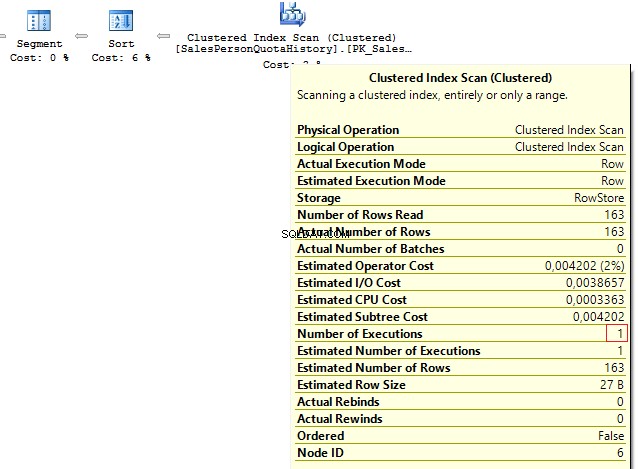
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
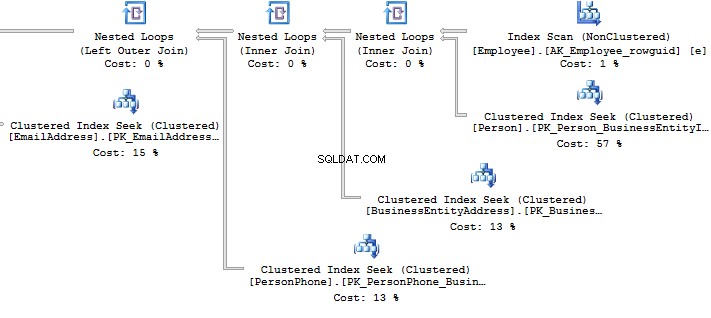
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
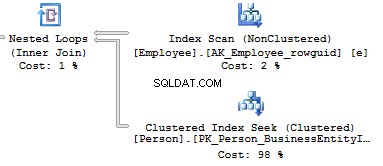
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
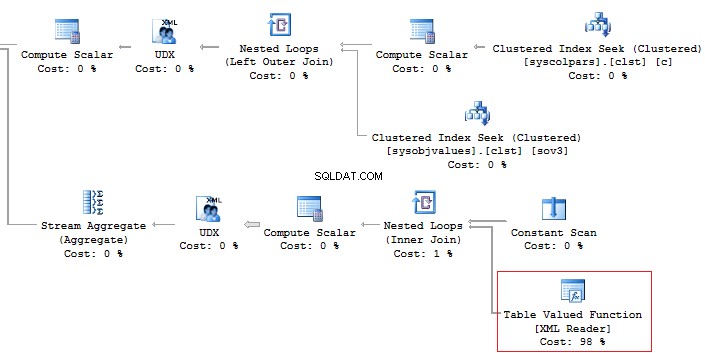
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
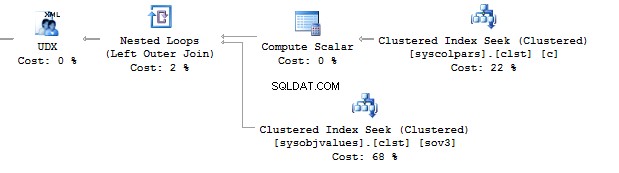
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Podsumowanie
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.