SQL Server udostępnia nam szereg funkcji okna, które pomagają nam wykonywać obliczenia w zbiorze wierszy, bez konieczności powtarzania wywołań do bazy danych. W przeciwieństwie do standardowych funkcji agregujących, funkcje okna nie grupują wierszy w pojedynczy wiersz wyjściowy, zwrócą pojedynczą zagregowaną wartość dla każdego wiersza, zachowując oddzielne tożsamości dla tych wierszy. Termin Okno tutaj nie jest związany z systemem operacyjnym Microsoft Windows, opisuje zestaw wierszy, które funkcja będzie przetwarzać.
Jednym z najbardziej użytecznych typów funkcji okna jest Ranking funkcji okna, który służy do oceniania określonych wartości pól i kategoryzowania ich zgodnie z rangą każdego wiersza, co daje w wyniku pojedynczą zagregowaną wartość dla każdego uczestniczącego wiersza. SQL Server obsługuje cztery funkcje okna rankingowego; ROW_NUMBER(), RANK(), DENSE_RANK() i NTILE(). Wszystkie te funkcje są używane do obliczania ROWID dla podanego okna wierszy na swój własny sposób.
Cztery funkcje okna rankingu używają klauzuli OVER(), która definiuje określony przez użytkownika zestaw wierszy w zestawie wyników zapytania. Definiując klauzulę OVER(), możesz również dołączyć klauzulę PARTITION BY, która określa zestaw wierszy, które funkcja okna będzie przetwarzać, podając kolumny lub kolumny oddzielone przecinkami w celu zdefiniowania partycji. Ponadto można dołączyć klauzulę ORDER BY, która definiuje kryteria sortowania w obrębie partycji, przez które funkcja będzie przechodzić przez wiersze podczas przetwarzania.
W tym artykule omówimy, jak praktycznie używać czterech funkcji okna rankingowego:ROW_NUMBER(), RANK(), DENSE_RANK() i NTILE(), oraz różnice między nimi.
Aby obsłużyć nasze demo, utworzymy nową prostą tabelę i wstawimy do niej kilka rekordów za pomocą poniższego skryptu T-SQL:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Możesz sprawdzić, czy dane zostały wstawione pomyślnie, używając następującej instrukcji SELECT:
SELECT * FROM StudentScore ORDER BY Student_ScorePo zastosowaniu posortowanego wyniku zestaw wyników wygląda następująco:

ROW_NUMBER()
Funkcja okna rankingu ROW_NUMBER() zwraca unikalny numer sekwencyjny dla każdego wiersza w obrębie partycji określonego okna, zaczynając od 1 dla pierwszego wiersza w każdej partycji i bez powtarzania lub pomijania liczb w wyniku rankingu każdej partycji. Jeśli w zestawie wierszy występują zduplikowane wartości, numery identyfikacyjne rankingu zostaną przypisane arbitralnie. Jeśli określono klauzulę PARTITION BY, numer wiersza rankingu zostanie zresetowany dla każdej partycji. W poprzednio utworzonej tabeli poniższe zapytanie pokazuje, jak użyć funkcji okna rankingu ROW_NUMBER do uszeregowania wierszy tabeli StudentScore zgodnie z wynikiem każdego ucznia:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Z poniższego zestawu wyników jasno wynika, że funkcja okna ROW_NUMBER klasyfikuje wiersze tabeli zgodnie z wartościami kolumny Student_Score dla każdego wiersza, generując unikalny numer każdego wiersza, który odzwierciedla jego ranking Student_Score, zaczynając od liczby 1 bez duplikatów lub przerw i traktując wszystkie wiersze jako jedną partycję. Możesz również zobaczyć, że zduplikowane wyniki są losowo przydzielane do różnych rang:
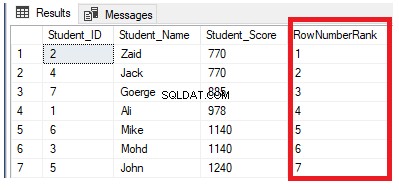
Jeśli zmodyfikujemy poprzednie zapytanie, dołączając klauzulę PARTITION BY, aby mieć więcej niż jedną partycję, jak pokazano w zapytaniu T-SQL poniżej:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Wynik pokaże, że funkcja okna ROW_NUMBER uszereguje wiersze tabeli zgodnie z wartościami kolumny Student_Score dla każdego wiersza, ale zajmie się wierszami, które mają taką samą wartość Student_Score jako jedna partycja. Zobaczysz, że dla każdego wiersza zostanie wygenerowany unikalny numer odzwierciedlający jego ranking Student_Score, zaczynając od numeru 1 bez duplikatów lub przerw w tej samej partycji, resetując numer rangi po przejściu do innej wartości Student_Score.
Na przykład uczniowie z wynikiem 770 zostaną uszeregowani w ramach tego wyniku, przypisując mu numer rangi. Jednakże, gdy zostanie przeniesiony do ucznia z wynikiem 885, numer startowy rang zostanie zresetowany, aby rozpocząć ponownie od 1, jak pokazano poniżej:
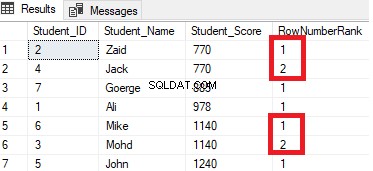
RANK()
Funkcja okna rankingowego RANK() zwraca unikalny numer rangi dla każdego odrębnego wiersza w partycji zgodnie z określoną wartością kolumny, zaczynając od 1 dla pierwszego wiersza w każdej partycji, z tą samą rangą dla zduplikowanych wartości i pozostawiając luki między rangami; ta luka pojawia się w kolejności po zduplikowanych wartościach. Innymi słowy, funkcja okna rankingu RANK() zachowuje się jak funkcja ROW_NUMBER(), z wyjątkiem wierszy o równych wartościach, w których będzie klasyfikowana z tym samym identyfikatorem rangi i wygeneruje po nim przerwę. Jeśli zmodyfikujemy poprzednie zapytanie rankingowe tak, aby używało funkcji rankingowej RANK():
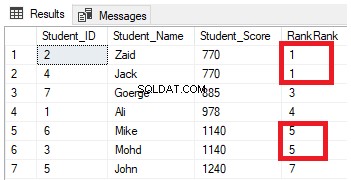
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreNa podstawie wyniku zobaczysz, że funkcja okna RANK uszereguje wiersze tabeli zgodnie z wartościami kolumny Student_Score dla każdego wiersza, przy czym wartość rankingu odzwierciedla jego Student_Score, zaczynając od liczby 1, i uszereguje wiersze, które mają ten sam Student_Score z ta sama wartość rangi. Możesz również zobaczyć, że dwa wiersze mające wartość Student_Score równą 770 są uszeregowane z tą samą wartością, pozostawiając lukę, która jest pominiętą liczbą 2, po drugim wierszu. To samo dzieje się z wierszami, w których Student_Score jest równy 1140, które są sklasyfikowane z tą samą wartością, pozostawiając lukę, czyli brakującą liczbę 6, po drugim wierszu, jak pokazano poniżej:
Modyfikowanie poprzedniego zapytania poprzez uwzględnienie klauzuli PARTITION BY tak, aby zawierało więcej niż jedną partycję, jak pokazano w poniższym zapytaniu T-SQL:
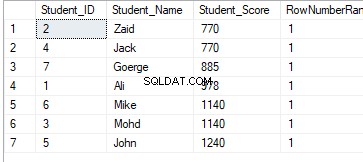
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreWynik rankingu nie będzie miał znaczenia, ponieważ ranking zostanie wykonany zgodnie z wartościami Student_Score na każdą partycję, a dane zostaną podzielone na partycje zgodnie z wartościami Student_Score. A ponieważ każda partycja będzie miała wiersze z tymi samymi wartościami Student_Score, wiersze z tymi samymi wartościami Student_Score w tej samej partycji zostaną uszeregowane z wartością równą 1. Tak więc po przejściu do drugiej partycji ranga będzie zresetować, zaczynając ponownie od numeru 1, mając wszystkie wartości rankingu równe 1, jak pokazano poniżej:
DENSE_RANK()
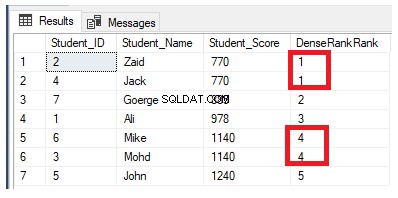
Funkcja okna rankingu DENSE_RANK() jest podobna do funkcji RANK() poprzez generowanie unikalnego numeru rangi dla każdego odrębnego wiersza w partycji zgodnie z określoną wartością kolumny, zaczynając od 1 dla pierwszego wiersza w każdej partycji, klasyfikując wiersze za pomocą równe wartości z tym samym numerem rangi, z wyjątkiem tego, że nie pomija żadnej rangi, nie pozostawiając żadnych przerw między rangami.
Jeśli przepiszemy poprzednie zapytanie rankingowe, aby użyć funkcji rankingowej DENSE_RANK():
Ponownie zmodyfikuj poprzednie zapytanie, dołączając klauzulę PARTITION BY tak, aby zawierała więcej niż jedną partycję, jak pokazano w poniższym zapytaniu T-SQL:
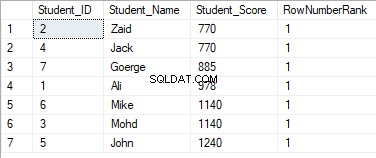
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Wartości rankingu nie będą miały znaczenia, gdzie wszystkie wiersze zostaną uszeregowane z wartością 1, ze względu na przypisanie zduplikowanych wartości do tej samej wartości rankingu i zresetowanie początkowego identyfikatora rangi podczas przetwarzania nowej partycji, jak pokazano poniżej:
NTILE(N)
Funkcja okna rankingowego NTILE(N) służy do podziału wierszy w wierszach ustawionych na określoną liczbę grup, zapewniając każdemu wierszowi w zestawie wierszy unikalny numer grupy, zaczynając od numeru 1, który pokazuje grupę, do której należy ten wiersz do, gdzie N jest liczbą dodatnią, która określa liczbę grup, na które należy rozmieścić ustawione wiersze.
Innymi słowy, jeśli potrzebujesz podzielić określone wiersze danych w tabeli na 3 grupy, w oparciu o poszczególne wartości kolumn, funkcja okna rankingowego NTILE(3) pomoże Ci to łatwo osiągnąć.
Liczbę rzędów w każdej grupie można obliczyć dzieląc liczbę rzędów na wymaganą liczbę grup. Jeśli zmodyfikujemy poprzednie zapytanie rankingowe, aby użyć funkcji okna rankingowego NTILE(4) do uporządkowania siedmiu wierszy tabeli na cztery grupy, tak jak w poniższym zapytaniu T-SQL:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Liczba rzędów powinna wynosić (7/4=1,75) rzędów w każdej grupie. Używając funkcji NTILE(), SQL Server Engine przypisze 2 wiersze do pierwszych trzech grup i jeden wiersz do ostatniej grupy, aby wszystkie wiersze były zawarte w grupach, jak pokazano w zestawie wyników poniżej:
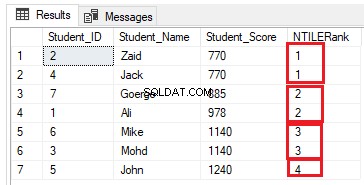
Modyfikowanie poprzedniego zapytania poprzez uwzględnienie klauzuli PARTITION BY tak, aby zawierało więcej niż jedną partycję, jak pokazano w poniższym zapytaniu T-SQL:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreRzędy zostaną podzielone na cztery grupy na każdej partycji. Na przykład, pierwsze dwa wiersze z Student_Score równym 770 będą znajdować się w tej samej partycji i zostaną rozdzielone w ramach grup oceniających każdy z unikalnym numerem, jak pokazano w zestawie wyników poniżej:
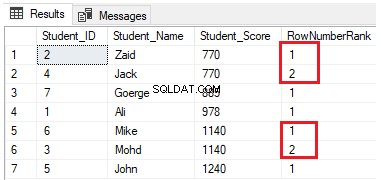
Wszystko razem
Aby uzyskać bardziej przejrzysty scenariusz porównania, skróćmy poprzednią tabelę, dodajmy kolejne kryterium klasyfikacji, czyli klasę uczniów, a na koniec wstawmy nowe siedem wierszy za pomocą poniższego skryptu T-SQL:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Następnie uszeregujemy siedem wierszy zgodnie z wynikiem każdego ucznia, dzieląc uczniów według klasy. Innymi słowy, każda partycja będzie zawierać jedną klasę, a każda klasa uczniów zostanie uszeregowana zgodnie z ich wynikami w tej samej klasie, przy użyciu czterech wcześniej opisanych funkcji okna rankingu, jak pokazano w poniższym skrypcie T-SQL:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOZe względu na to, że nie ma zduplikowanych wartości, cztery funkcje okna rankingowego będą działały w ten sam sposób, zwracając ten sam wynik, jak pokazano w zestawie wyników poniżej:
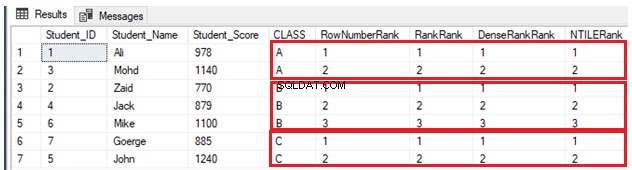
Jeśli inny uczeń jest zaliczany do klasy A z wynikiem, który ma już inny uczeń z tej samej klasy, korzystając z poniższej instrukcji INSERT:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Nic się nie zmieni dla funkcji okna rankingu ROW_NUMBER() i NTILE(). Funkcje RANK i DENSE_RANK() przypiszą tę samą rangę uczniom z tym samym wynikiem, z przerwą w rangach po zduplikowanych rangach przy użyciu funkcji RANK i bez przerwy w rangach po zduplikowanych rangach przy użyciu DENSE_RANK( ), jak pokazano w poniższym wyniku:
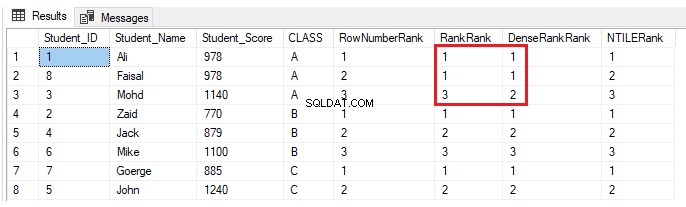
Praktyczny scenariusz
Funkcje okna rankingu są powszechnie używane przez programistów SQL Server. Jeden z typowych scenariuszy użycia funkcji rankingowych, gdy chcesz pobrać określone wiersze i pominąć inne, używając funkcji okna rankingowego ROW_NUMBER(,) w CTE, jak w poniższym skrypcie T-SQL, który zwraca uczniów z rangami między 2 i 5 i pomiń pozostałe:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Wynik pokaże, że zostaną zwróceni tylko uczniowie z rangą od 2 do 5:
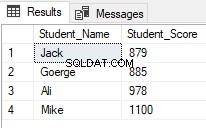
Począwszy od SQL Server 2012, nowe przydatne polecenie, OFFSET FETCH został wprowadzony, który może być użyty do wykonania tego samego poprzedniego zadania poprzez pobranie określonych rekordów i pominięcie innych za pomocą poniższego skryptu T-SQL:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Pobieranie tego samego poprzedniego wyniku, jak pokazano poniżej:
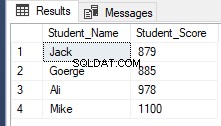
Wniosek
SQL Server zapewnia nam cztery funkcje okna rankingowego, które pomagają nam uszeregować dostarczone wiersze zgodnie z określonymi wartościami kolumn. Te funkcje to:ROW_NUMBER(), RANK(), DENSE_RANK() i NTILE(). Wszystkie te funkcje rankingu wykonują zadanie rankingu na swój własny sposób, zwracając ten sam wynik, gdy w wierszach nie ma zduplikowanych wartości. Jeśli w zestawie wierszy występuje zduplikowana wartość, funkcja RANK przypisze ten sam identyfikator rankingu do wszystkich wierszy o tej samej wartości, pozostawiając luki między rangami po duplikatach. Funkcja DENSE_RANK również przypisze ten sam identyfikator rankingu do wszystkich wierszy o tej samej wartości, ale nie pozostawi żadnej przerwy między rangami po duplikatach. W tym artykule omawiamy różne scenariusze, aby uwzględnić wszystkie możliwe przypadki, które pomogą Ci w praktycznym zrozumieniu funkcji okna rankingowego.
Referencje:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- Klauzula OFFSET FETCH (SQL Server Compact)