Jest to piąta i ostatnia część serii obejmującej rozwiązania wyzwania generatora szeregów liczbowych. W części 1, części 2, części 3 i części 4 omówiłem czyste rozwiązania T-SQL. Na początku, kiedy opublikowałem łamigłówkę, kilka osób stwierdziło, że najlepiej działającym rozwiązaniem będzie prawdopodobnie rozwiązanie oparte na CLR. W tym artykule przetestujemy to intuicyjne założenie. W szczególności omówię rozwiązania oparte na CLR opublikowane przez Kamila Kosno i Adama Machanica.
Wielkie podziękowania dla Alana Bursteina, Joe Obbisha, Adama Machanica, Christophera Forda, Jeffa Modena, Charliego, NoamGr, Kamila Kosno, Dave'a Masona, Johna Nelsona #2, Eda Wagnera, Michaela Burbea i Paula White'a za podzielenie się swoimi pomysłami i komentarzami.
Przeprowadzę testy w bazie danych o nazwie testdb. Użyj następującego kodu, aby utworzyć bazę danych, jeśli nie istnieje, oraz włączyć statystyki we/wy i czasu:
-- DB i statsSET NOCOUNT ON;USTAW STATYSTYKI IO, TIME ON;GO JEŚLI DB_ID('testdb') JEST NULL UTWÓRZ BAZĘ DANYCH testdb;GO USE testdb;GO Dla uproszczenia wyłączę CLR strict security i sprawię, że baza danych będzie wiarygodna za pomocą następującego kodu:
-- Włącz CLR, wyłącz zabezpieczenia CLR strict i spraw, aby db był godny zaufaniaEXEC sys.sp_configure 'pokaż ustawienia zaawansowane', 1;RECONFIGURE; EXEC sys.sp_configure 'clr włączony', 1;EXEC sys.sp_configure 'clr ścisłe zabezpieczenia', 0;RECONFIGURE; EXEC sys.sp_configure 'pokaż ustawienia zaawansowane', 0;RECONFIGURE; ALTER DATABASE testdb USTAWIĆ ZAUFANIE NA; Idź
Wcześniejsze rozwiązania
Zanim omówię rozwiązania oparte na CLR, szybko przeanalizujmy wydajność dwóch najlepiej działających rozwiązań T-SQL.
Najskuteczniejszym rozwiązaniem T-SQL, które nie używało żadnych utrwalonych tabel podstawowych (innych niż fikcyjna pusta tabela magazynu kolumn w celu uzyskania przetwarzania wsadowego), a zatem nie wymagało operacji we/wy, było to zaimplementowane w funkcji dbo.GetNumsAlanCharlieItzikBatch. Omówiłem to rozwiązanie w części 1.
Oto kod tworzący fikcyjną pustą tabelę magazynu kolumn, z której korzysta zapytanie funkcji:
DROP TABLE IF EXISTS dbo.BatchMe;GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);GO
A oto kod z definicją funkcji:
UTWÓRZ LUB ZMIEŃ FUNKCJĘ dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT =1, @high AS BIGINT) ZWRACA TABELĘASRETURN Z L0 JAKO ( WYBIERZ 1 JAKO c Z (WARTOŚCI(1),(1),(1),1 ),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1) AS D(c) ), L1 AS ( WYBIERZ 1 AS c Z L0 JAKO KRZYŻOWY DOŁĄCZ L0 JAK B ), L2 AS ( WYBIERZ 1 AS c Z L1 JAKO KRZYŻOWY DOŁĄCZ L1 JAKO B ), L3 AS ( WYBIERZ 1 AS c FROM L2 JAKO KRZYŻ DOŁĄCZ L2 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM L3 ) SELECT TOP(@high - @low + 1) rownum AS rn, @high + 1 - rownum AS op, @low - 1 + rownum AS n FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0 ORDER BY rownum;GO
Najpierw przetestujmy funkcję żądającą serii 100 milionów liczb, z agregacją MAX zastosowaną do kolumny n:
WYBIERZ MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Przypomnijmy, ta technika testowania pozwala uniknąć przesyłania 100 mln wierszy do wywołującego, a także pozwala uniknąć wysiłku w trybie wiersza związanego z przypisywaniem zmiennych podczas korzystania z techniki przypisywania zmiennych.
Oto statystyki czasu, które otrzymałem podczas tego testu na moim komputerze:
Czas procesora =6719 ms, upływ czasu =6742 ms .Wykonanie tej funkcji nie powoduje oczywiście żadnych odczytów logicznych.
Następnie przetestujmy to z zamówieniem, używając techniki przypisywania zmiennych:
ZADEKLARUJ @n JAKO DUŻY; SELECT @ n =n FROM dbo. GetNumsAlanCharlieItzikBatch (1, 100000000) ORDER BY n OPTION (MAXDOP 1);
Otrzymałem następujące statystyki czasu dla tej egzekucji:
Czas procesora =9468 ms, upływ czasu =9531 ms .Przypomnijmy, że ta funkcja nie powoduje sortowania przy żądaniu danych uporządkowanych według n; zasadniczo otrzymujesz ten sam plan, niezależnie od tego, czy zażądasz zamówionych danych, czy nie. Większość dodatkowego czasu w tym teście w porównaniu z poprzednim możemy przypisać przypisaniu zmiennych w trybie wiersza 100M.
Najskuteczniejszym rozwiązaniem T-SQL, które wykorzystywało utrwaloną tabelę bazową i w związku z tym skutkowało niektórymi operacjami we/wy, choć bardzo nielicznymi, było rozwiązanie Paula White'a zaimplementowane w funkcji dbo.GetNums_SQLkiwi. Omówiłem to rozwiązanie w części 4.
Oto kod Paula, który tworzy zarówno tabelę magazynu kolumn używaną przez funkcję, jak i samą funkcję:
-- Helper columnstore tableDROP TABLE IF EXISTS dbo.CS; -- 64 tys. wierszy (wystarczy na 4B wierszy przy łączeniu krzyżowym)-- kolumna 1 to zawsze zero-- kolumna 2 to (1...65536)SELECT -- wpisz jako liczba całkowita NOT NULL -- (wszystko jest znormalizowane do 64 bitów w Mimo to tryb magazynu kolumn/wsadu) n1 =ISNULL(CONVERT(integer, 0), 0), n2 =ISNULL(CONVERT(integer, N.rn), 0)INTO dbo.CSFROM (SELECT rn =ROW_NUMBER() OVER (ORDER BY) @@SPID) FROM master.dbo.spt_values JAKO SV1 CROSS JOIN master.dbo.spt_values JAKO SV2 ZAMÓWIENIE BY rn ASC OFFSET 0 ROWS FETCH NEXT 65536 ROWS ONLY) JAK N; -- Pojedyncza skompresowana grupa wierszy składająca się z 65 536 wierszyCREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS WITH (MAXDOP =1); GO -- Funkcja CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi( @low bigint =1, @high bigint)Zwraca tabela ASRETURN SELECT N .rn, n =@low - 1 + N.rn, op =@high + 1 - N.rn FROM ( SELECT -- Użyj @@TRANCOUNT zamiast @@SPID, jeśli lubisz wszystkie zapytania serial rn =ROW_NUMBER() OVER (ORDER BY @@SPID ASC) FROM dbo.CS AS N1 JOIN dbo.CS AS N2 -- Wsadowe łączenie krzyżowe z haszem -- Liczba całkowita nie zerowa Typ danych unikaj pozostałości z sondy mieszającej -- Jest to zawsze 0 =0 ON N2. n1 =N1.n1 GDZIE -- Staraj się unikać SQRT dla liczb ujemnych i włącz uproszczenie -- do pojedynczego stałego skanowania, jeśli @low> @high (z literałami) -- Brak filtrów startowych w trybie wsadowym @high>=@low -- Filtr zgrubny:-- Ogranicz każdą stronę sprzężenie krzyżowe do SQRT(docelowa liczba wierszy) -- IIF unika funkcji SQRT dla liczb ujemnych z parametrami AND N1.n2 <=CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high>=@low, @high - @niski + 1, 0))))) AND N2.n2 <=KONWERSJA(liczba całkowita, SUFIT(PIERWIASTEK(KONWERSJA(liczba, IIF(@wysoki>=@niski, @wysoki - @niski + 1, 0)) ))) ) AS N WHERE – Filtr precyzyjny:– Filtruj w trybie wsadowym ograniczone sprzężenie krzyżowe do dokładnej liczby potrzebnych wierszy – Zapobiega wprowadzaniu przez optymalizator Top w trybie wierszowym z następującymi wartościami skalarnymi w trybie wierszowym @low - 2 + N.rn <@high;GO
Najpierw przetestujmy to bez zamówienia, używając techniki zbiorczej, co skutkuje planem dla wszystkich partii:
WYBIERZ MAX(n) AS mx FROM dbo.GetNums_SQLkiwi (1, 100000000) OPCJA (MAXDOP 1);
Otrzymałem następujący czas i statystyki I/O dla tego wykonania:
Czas procesora =2922 ms, czas, który upłynął =2943 ms .Tabela 'CS'. Liczba skanów 2, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty serwera strony odczyty z wyprzedzeniem 0, logiczne odczyty lob 44 , fizyczne odczyty lobu 0, serwer strony lob odczytuje 0, odczyt z wyprzedzeniem lob odczytuje 0, odczyt z wyprzedzeniem serwera strony lob odczytuje 0.
Tabela „CS”. Segment odczytuje 2, segment pominięty 0.
Przetestujmy funkcję z zamówieniem przy użyciu techniki przypisywania zmiennych:
ZADEKLARUJ @n JAKO DUŻY; SELECT @ n =n FROM dbo. GetNums_SQLkiwi (1, 10000000) ORDER BY n OPTION (MAXDOP 1);
Podobnie jak w przypadku poprzedniego rozwiązania, również to rozwiązanie pozwala uniknąć jawnego sortowania w planie, a zatem otrzymuje ten sam plan, niezależnie od tego, czy poprosisz o zamówione dane, czy nie. Ale znowu, ten test wiąże się z dodatkową karą, głównie ze względu na zastosowaną tutaj technikę przypisywania zmiennych, co powoduje, że część przypisania zmiennych w planie jest przetwarzana w trybie wierszowym.
Oto czas i statystyki I/O, które otrzymałem dla tego wykonania:
Czas procesora =6985 ms, upływ czasu =7033 ms .Tabela 'CS'. Liczba skanów 2, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty serwera strony odczyty z wyprzedzeniem 0, logiczne odczyty lob 44 , fizyczne odczyty lobu 0, serwer strony lob odczytuje 0, odczyt z wyprzedzeniem lob odczytuje 0, odczyt z wyprzedzeniem serwera strony lob odczytuje 0.
Tabela „CS”. Segment odczytuje 2, segment pominięty 0.
Rozwiązania CLR
Zarówno Kamil Kosno, jak i Adam Machonic najpierw dostarczyli proste rozwiązanie oparte wyłącznie na CLR, a później opracowali bardziej wyrafinowaną kombinację CLR+T-SQL. Zacznę od rozwiązań Kamila, a następnie omówię rozwiązania Adama.
Rozwiązania Kamila Kosno
Oto kod CLR użyty w pierwszym rozwiązaniu Kamila do zdefiniowania funkcji o nazwie GetNums_KamilKosno1:
Funkcja przyjmuje dwa dane wejściowe o nazwie low i high i zwraca tabelę z kolumną BIGINT o nazwie n. Funkcja jest funkcją strumieniową, która zwraca wiersz z następną liczbą w serii na żądanie wiersza z zapytania wywołującego. Jak widać, Kamil wybrał bardziej sformalizowany sposób implementacji interfejsu IEnumerator, który polega na zaimplementowaniu metod MoveNext (przesuwa enumerator w celu pobrania kolejnego wiersza), Current (pobiera wiersz w bieżącej pozycji enumeratora) oraz Reset (ustawia moduł wyliczający do pozycji początkowej, czyli przed pierwszym wierszem).
Zmienna przechowująca aktualny numer w serii nazywa się _current. Konstruktor ustawia _current na dolną granicę żądanego zakresu minus 1 i to samo dotyczy metody Reset. Metoda MoveNext zwiększa _current o 1. Następnie, jeśli _current jest większe niż górna granica żądanego zakresu, metoda zwraca wartość false, co oznacza, że nie zostanie wywołana ponownie. W przeciwnym razie zwraca true, co oznacza, że zostanie wywołana ponownie. Metoda Current w naturalny sposób zwraca _current. Jak widać, dość podstawowa logika.
Projekt Visual Studio nazwałem GetNumsKamil1 i użyłem do tego ścieżki C:\Temp\. Oto kod, którego użyłem do wdrożenia funkcji w bazie danych testdb:
UPUŚĆ FUNKCJĘ, JEŚLI ISTNIEJE dbo.GetNums_KamilKosno1; UPUŚĆ ZESPÓŁ, JEŚLI ISTNIEJE GetNumsKamil1;GO UTWÓRZ ZESPÓŁ GetNumsKamil1 Z 'C:\Temp\GetNumsKamil1\GetNumsKamil1\bin\Debug\GetNumsKamil1.dll';GO CREATE FUNCTION BNKomsbo1. TABLE(n BIGINT) ORDER(n) JAKO NAZWA ZEWNĘTRZNA GetNumsKamil1.GetNumsKamil1.GetNums_KamilKosno1;GO
Zwróć uwagę na użycie klauzuli ORDER w instrukcji CREATE FUNCTION. Funkcja emituje wiersze w kolejności n, więc gdy wiersze muszą zostać przetworzone w planie w kolejności n, na podstawie tej klauzuli SQL Server wie, że może uniknąć sortowania w planie.
Przetestujmy funkcję, najpierw techniką agregacji, gdy zamawianie nie jest potrzebne:
WYBIERZ MAX(n) AS mx FROM dbo.GetNums_KamilKosno1(1, 100000000);
Mam plan pokazany na rysunku 1.
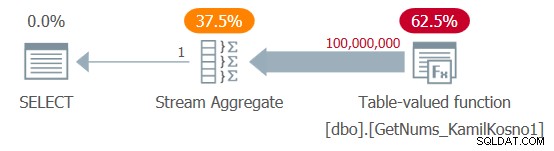 Rysunek 1:Plan dla funkcji dbo.GetNums_KamilKosno1
Rysunek 1:Plan dla funkcji dbo.GetNums_KamilKosno1
Nie ma wiele do powiedzenia na temat tego planu, poza faktem, że wszyscy operatorzy używają trybu wykonywania wierszy.
Otrzymałem następujące statystyki czasu dla tej egzekucji:
Czas procesora =37375 ms, czas, który upłynął =37488 ms .I oczywiście nie było żadnych odczytów logicznych.
Przetestujmy funkcję z zamówieniem, używając techniki przypisywania zmiennych:
ZADEKLARUJ @n JAKO DUŻY; SELECT @n =n FROM dbo.GetNums_KamilKosno1(1, 100000000) ORDER BY n;
Mam plan pokazany na Rysunku 2 dla tego wykonania.
 Rysunek 2:Plan dla funkcji dbo.GetNums_KamilKosno1 z ORDER BY
Rysunek 2:Plan dla funkcji dbo.GetNums_KamilKosno1 z ORDER BY
Zauważ, że w planie nie ma sortowania, ponieważ funkcja została utworzona z klauzulą ORDER(n). Należy jednak podjąć pewne wysiłki, aby upewnić się, że wiersze są rzeczywiście emitowane z funkcji w obiecanej kolejności. Odbywa się to za pomocą operatorów segmentu i projektu sekwencji, które są używane do obliczania numerów wierszy, oraz operatora Assert, który przerywa wykonywanie zapytania, jeśli test się nie powiedzie. Ta praca ma skalowanie liniowe — w przeciwieństwie do skalowania n log n, które otrzymalibyśmy, gdyby wymagany był sortowanie — ale nadal nie jest tania. Otrzymałem następujące statystyki czasu dla tego testu:
Czas procesora =51531 ms, czas, który upłynął =51905 ms .Wyniki mogą być zaskakujące dla niektórych — zwłaszcza dla tych, którzy intuicyjnie zakładali, że rozwiązania oparte na CLR będą działać lepiej niż rozwiązania T-SQL. Jak widać, czasy wykonania są o rząd wielkości dłuższe niż w przypadku naszego najlepiej działającego rozwiązania T-SQL.
Drugie rozwiązanie Kamila to hybryda CLR-T-SQL. Poza niskimi i wysokimi danymi wejściowymi funkcja CLR (GetNums_KamilKosno2) dodaje dane wejściowe krokowe i zwraca wartości między niskimi a wysokimi, które są od siebie oddalone o krok. Oto kod CLR, którego Kamil użył w swoim drugim rozwiązaniu:
Projekt VS nazwałem GetNumsKamil2, umieściłem go również w ścieżce C:\Temp\ i użyłem następującego kodu, aby wdrożyć go w bazie danych testdb:
-- Utwórz zestaw i funkcję UPUŚĆ FUNKCJĘ, JEŚLI ISTNIEJE dbo.GetNums_KamilKosno2;UPUŚĆ ZESPOŁ, JEŚLI ISTNIEJE GetNumsKamil2;GO UTWÓRZ ZESPOŁ GetNumsKamil2 Z 'C:\Temp\GetNumsKamil\Kamil'sGetNum1; .GetNums_KamilKosno2 (@low AS BIGINT =1, @high AS BIGINT, @step AS BIGINT) TABELA ZWROTÓW(n BIGINT) ORDER(n) JAKO NAZWA ZEWNĘTRZNA GetNumsKamil2.GetNumsKamil2.GetNums_KamilKosno2;GO
Jako przykład użycia funkcji, oto żądanie wygenerowania wartości od 5 do 59, z krokiem 10:
WYBIERZ n Z dbo.GetNums_KamilKosno2(5, 59, 10);
Ten kod generuje następujące dane wyjściowe:
n---51525354555
Jeśli chodzi o część T-SQL, Kamil użył funkcji o nazwie dbo.GetNums_Hybrid_Kamil2 z następującym kodem:
UTWÓRZ LUB ZMIEŃ FUNKCJĘ dbo.GetNums_Hybrid_Kamil2(@low AS BIGINT, @high AS BIGINT) TABELA ZWROTÓWASPOWRÓT WYBIERZ TOP (@high - @low + 1) V.n FROM dbo.GetNums_KamilKosno2(@low, @high, 10) AS ZASTOSUJ KRZYŻ (WARTOŚCI(0+GN.n),(1+GN.n),(2+GN.n),(3+GN.n),(4+GN.n), (5+GN.n ),(6+GN.n),(7+GN.n),(8+GN.n),(9+GN.n)) AS V(n);GO
Jak widać, funkcja T-SQL wywołuje funkcję CLR z tymi samymi danymi wejściowymi @low i @high, które otrzymuje, a w tym przykładzie używa kroku o wielkości 10. Zapytanie używa CROSS APPLY między wynikiem funkcji CLR a Konstruktor wartości tabeli, który generuje końcowe liczby, dodając wartości z zakresu od 0 do 9 na początku kroku. Filtr TOP służy do zapewnienia, że nie otrzymasz więcej niż żądana liczba numerów.
Ważne: Należy podkreślić, że Kamil zakłada tutaj, że filtr TOP jest stosowany na podstawie kolejności numerów wyników, co nie jest tak naprawdę gwarantowane, ponieważ zapytanie nie zawiera klauzuli ORDER BY. Jeśli dodasz klauzulę ORDER BY do obsługi TOP lub zastąpisz TOP filtrem WHERE, aby zagwarantować filtr deterministyczny, może to całkowicie zmienić profil wydajności rozwiązania.
W każdym razie przetestujmy najpierw funkcję bez zamówienia przy użyciu techniki agregacji:
WYBIERZ MAX(n) AS mx Z dbo.GetNums_Hybrid_Kamil2(1, 100000000);
Mam plan pokazany na Rysunku 3 dla tego wykonania.
 Rysunek 3:Plan dla funkcji dbo.GetNums_Hybrid_Kamil2
Rysunek 3:Plan dla funkcji dbo.GetNums_Hybrid_Kamil2
Ponownie, wszyscy operatorzy w planie używają trybu wykonywania wierszy.
Otrzymałem następujące statystyki czasu dla tej egzekucji:
Czas procesora =13985 ms, czas, który upłynął =14069 ms .I oczywiście żadnych logicznych odczytów.
Przetestujmy funkcję za pomocą kolejności:
ZADEKLARUJ @n JAKO DUŻY; SELECT @n =n FROM dbo.GetNums_Hybrid_Kamil2(1, 100000000) ORDER BY n;
Mam plan pokazany na rysunku 4.
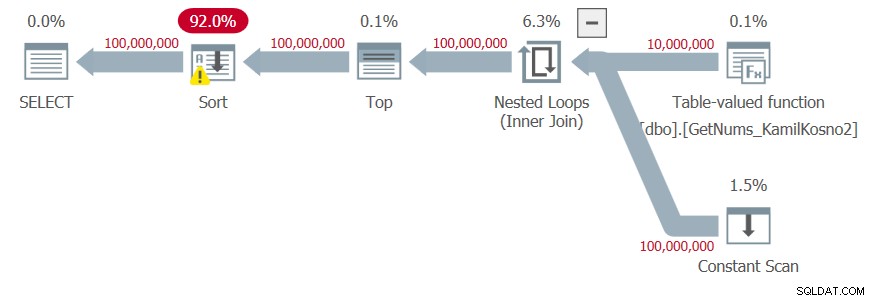 Rysunek 4:Plan dla funkcji dbo.GetNums_Hybrid_Kamil2 z ORDER BY
Rysunek 4:Plan dla funkcji dbo.GetNums_Hybrid_Kamil2 z ORDER BY
Ponieważ liczby wyników są wynikiem manipulacji dolnym ograniczeniem kroku zwracanego przez funkcję CLR i deltą dodaną w konstruktorze wartości tabeli, optymalizator nie ufa, że liczby wyników są generowane w żądanej kolejności, a dodaje wyraźne sortowanie do planu.
Otrzymałem następujące statystyki czasu dla tej egzekucji:
Czas procesora =68703 ms, czas, który upłynął =84538 ms .Wydaje się więc, że gdy zamówienie nie jest potrzebne, drugie rozwiązanie Kamila radzi sobie lepiej niż jego pierwsze. Ale kiedy potrzebny jest porządek, jest odwrotnie. Tak czy inaczej, rozwiązania T-SQL są szybsze. Osobiście ufałbym poprawności pierwszego rozwiązania, ale nie drugiego.
Rozwiązania Adama Machanicia
Pierwsze rozwiązanie Adama to również podstawowa funkcja CLR, która stale zwiększa licznik. Tylko zamiast korzystać z bardziej zaangażowanego sformalizowanego podejścia, jak zrobił to Kamil, Adam zastosował prostsze podejście, które wywołuje polecenie uzysku dla każdego wiersza, który musi zostać zwrócony.
Oto kod CLR Adama dla jego pierwszego rozwiązania, definiującego funkcję przesyłania strumieniowego o nazwie GetNums_AdamMachic1:
Rozwiązanie jest tak eleganckie w swojej prostocie. Jak widać, funkcja przyjmuje dwa dane wejściowe o nazwie min i max, reprezentujące dolny i górny punkt graniczny żądanego zakresu, i zwraca tabelę z kolumną BIGINT o nazwie n. Funkcja inicjuje zmienne o nazwie min_int i max_int z wartościami parametrów wejściowych odpowiedniej funkcji. Następnie funkcja uruchamia pętlę tak długo, jak min_int <=max_int, która w każdej iteracji zwraca wiersz z bieżącą wartością min_int i zwiększa min_int o 1. To wszystko.
Projekt nazwałem GetNumsAdam1 w VS, umieściłem go w C:\Temp\ i użyłem następującego kodu do jego wdrożenia:
-- Utwórz zestaw i funkcję UPUŚĆ FUNKCJĘ, JEŚLI ISTNIEJE dbo.GetNums_AdamMachanic1;UPUŚĆ ZESPOŁ, JEŚLI ISTNIEJE GetNumsAdam1;GO UTWÓRZ ZESPOŁ GetNumsAdam1 Z 'C:\Temp\GetNumsAdam1\Get\dam1. .GetNums_AdamMachanic1(@low AS BIGINT =1, @high AS BIGINT) TABELA ZWROTÓW(n BIGINT) ORDER(n) JAKO NAZWA ZEWNĘTRZNA GetNumsAdam1.GetNumsAdam1.GetNums_AdamMachanic1;GO
Użyłem poniższego kodu, aby przetestować go techniką agregacji, w przypadkach, gdy kolejność nie ma znaczenia:
WYBIERZ MAX(n) AS mx FROM dbo.GetNums_AdamMachanic1 (1, 100000000);
Mam plan pokazany na Rysunku 5 dla tego wykonania.
 Rysunek 5:Plan dla funkcji dbo.GetNums_AdamMachanic1
Rysunek 5:Plan dla funkcji dbo.GetNums_AdamMachanic1
Plan jest bardzo podobny do tego, który widzieliście wcześniej dla pierwszego rozwiązania Kamila i to samo dotyczy jego wykonania. Otrzymałem następujące statystyki czasu dla tej egzekucji:
Czas procesora =36687 ms, czas, który upłynął =36952 ms .I oczywiście nie były potrzebne żadne logiczne odczyty.
Przetestujmy funkcję z zamówieniem, używając techniki przypisywania zmiennych:
ZADEKLARUJ @n JAKO DUŻY; SELECT @n =n FROM dbo.GetNums_AdamMachanic1 (1, 100000000) ORDER BY n;
Mam plan pokazany na Rysunku 6 dla tego wykonania.
 Rysunek 6:Plan dla funkcji dbo.GetNums_AdamMachanic1 z ORDER BY
Rysunek 6:Plan dla funkcji dbo.GetNums_AdamMachanic1 z ORDER BY
Ponownie plan wygląda podobnie do tego, który widzieliście wcześniej dla pierwszego rozwiązania Kamila. Nie było potrzeby jawnego sortowania, ponieważ funkcja została utworzona z klauzulą ORDER, ale plan obejmuje pewne prace w celu sprawdzenia, czy wiersze są rzeczywiście zwracane w kolejności zgodnej z obietnicą.
Otrzymałem następujące statystyki czasu dla tej egzekucji:
Czas procesora =55047 ms, czas, który upłynął =55498 ms .W swoim drugim rozwiązaniu Adam połączył również część CLR i część T-SQL. Oto opis logiki Adama, którego użył w swoim rozwiązaniu:
„Próbowałem wymyślić, jak obejść problem gadatliwości SQLCLR, a także główne wyzwanie tego generatora liczb w T-SQL, a mianowicie fakt, że nie możemy po prostu zaczarować wierszy.
CLR jest dobrą odpowiedzią na drugą część, ale jest oczywiście utrudniony przez pierwszą kwestię. Więc jako kompromis stworzyłem T-SQL TVF [o nazwie GetNums_AdamMachonic2_8192] zakodowany na sztywno z wartościami od 1 do 8192. (Dość dowolny wybór, ale za duży i QO zaczyna się trochę dusić.) Następnie zmodyfikowałem moją funkcję CLR [ o nazwie GetNums_AdamMachanic2_8192_base], aby wyprowadzić dwie kolumny, „max_base” i „base_add”, i wyprowadzić wiersze, takie jak:
- max_base, base_add
——————
8191, 1
8192, 8192
8192, 16384
…
8192, 99991552
257, 99999744
Teraz to prosta pętla. Wyjście CLR jest wysyłane do T-SQL TVF, który jest skonfigurowany tak, aby zwracał tylko do wierszy „max_base” swojego zestawu zakodowanego na sztywno. A dla każdego wiersza dodaje „base_add” do wartości, generując w ten sposób wymagane liczby. Myślę, że kluczem jest tutaj to, że możemy wygenerować N wierszy za pomocą tylko jednego logicznego sprzężenia krzyżowego, a funkcja CLR musi zwrócić tylko 1/8192 tyle wierszy, więc jest wystarczająco szybka, aby działać jako generator baz.”
Logika wydaje się całkiem prosta.
Oto kod użyty do zdefiniowania funkcji CLR o nazwie GetNums_AdamMachanic2_8192_base:
Projekt VS nazwałem GetNumsAdam2 i umieściłem w ścieżce C:\Temp\ podobnie jak inne projekty. Oto kod, którego użyłem do wdrożenia funkcji w bazie danych testdb:
-- Utwórz zestaw i funkcję UPUŚĆ FUNKCJĘ, JEŚLI ISTNIEJE dbo.GetNums_AdamMachanic2_8192_base;UPUŚĆ ZESPOŁ, JEŚLI ISTNIEJE GetNumsAdam2;PRZEJDŹ UTWÓRZ ZESPOŁ GetNumsAdam2 Z 'C:\Temp\GetNumsAdam2'gAdam2\binAmNGetA. .GetNums_AdamMachanic2_8192_base(@max_base AS BIGINT, @add_base AS BIGINT) TABELA ZWROTÓW(max_base BIGINT, base_add BIGINT) ORDER(base_add) JAKO NAZWA ZEWNĘTRZNA GetNumsAdam2.GetNumsAdam2.GetNums2_ApreOto przykład użycia GetNums_AdamMachanic2_8192_base z zakresem od 1 do 100M:
WYBIERZ * Z dbo.GetNums_AdamMachanic2_8192_base(1, 100000000);Ten kod generuje następujące dane wyjściowe, pokazane tutaj w skróconej formie:
max_base base_add-------------------- --------------------8191 18192 81928192 163848192 245768192 32768...8192 999669768192 999751688192 999833608192 99991552257 99999744 (12208 wierszy, których dotyczy)Oto kod z definicją funkcji T-SQL GetNums_AdamMachanic2_8192 (w skrócie):
UTWÓRZ LUB ZMIEŃ FUNKCJĘ dbo.GetNums_AdamMachanic2_8192(@max_base JAKO DUŻY, @add_base JAKO DUŻY) ZWRACA TABELĘ JAKO POWRÓT WYBIERZ TOP (@max_base) V.i + @add_base JAKO WARTOŚĆ OD ( WARTOŚCI (0), (1), (2), (3), (4), ... (8187), (8188), (8189), (8190), (8191)) AS V(i);GOWażne: Również tutaj powinienem podkreślić, że podobnie jak to, co powiedziałem o drugim rozwiązaniu Kamila, Adam zakłada tutaj, że filtr TOP wydobędzie górne wiersze na podstawie kolejności występowania wierszy w konstruktorze wartości tabeli, co nie jest do końca gwarantowane. Jeśli dodasz klauzulę ORDER BY do obsługi TOP lub zmienisz filtr na filtr WHERE, uzyskasz filtr deterministyczny, ale może to całkowicie zmienić profil wydajności rozwiązania.
Wreszcie, oto najbardziej zewnętrzna funkcja T-SQL, dbo.GetNums_AdamMachanic2, którą użytkownik końcowy wywołuje w celu uzyskania serii liczb:
UTWÓRZ LUB ZMIEŃ FUNKCJĘ dbo.GetNums_AdamMachanic2(@low AS BIGINT =1, @high AS BIGINT) ZWRACA TABELĘASRETURN SELECT Y.val AS n FROM ( SELECT max_base, base_add FROM dbo.GetNums_AdamMachanic2_8192_base)(@low)8192_base X KRZYŻ ZASTOSUJ dbo.GetNums_AdamMachanic2_8192(X.max_base, X.base_add) JAKO YGOTa funkcja używa operatora CROSS APPLY, aby zastosować wewnętrzną funkcję T-SQL dbo.GetNums_AdamMachanic2_8192 na wiersz zwrócony przez wewnętrzną funkcję CLR dbo.GetNums_AdamMachanic2_8192_base.
Najpierw przetestujmy to rozwiązanie za pomocą techniki agregacji, gdy kolejność nie ma znaczenia:
WYBIERZ MAX(n) AS mx Z dbo.GetNums_AdamMachanic2(1, 100000000);Dostałem plan pokazany na Rysunku 7 dla tego wykonania.
Rysunek 7:Plan dla funkcji dbo.GetNums_AdamMachanic2
Otrzymałem następujące statystyki czasu dla tego testu:
SQL Server czas analizowania i kompilacji :Czas procesora =313 ms, czas, który upłynął =339 ms .
SQL Server czas wykonania :Czas procesora =8859 ms, czas, który upłynął =8849 ms .Żadne odczyty logiczne nie były potrzebne.
Czas wykonania nie jest zły, ale zwróć uwagę na długi czas kompilacji ze względu na użyty duży konstruktor wartości tabeli. Zapłaciłbyś tak długi czas kompilacji, niezależnie od żądanego rozmiaru zakresu, więc jest to szczególnie trudne, gdy używasz funkcji z bardzo małymi zakresami. A to rozwiązanie jest wciąż wolniejsze niż te T-SQL.
Przetestujmy funkcję za pomocą kolejności:
ZADEKLARUJ @n JAKO DUŻY; SELECT @n =n FROM dbo.GetNums_AdamMachanic2(1, 100000000) ORDER BY n;Dostałem plan pokazany na Rysunku 8 dla tego wykonania.
Rysunek 8:Plan dla funkcji dbo.GetNums_AdamMachanic2 z ORDER BY
Podobnie jak w przypadku drugiego rozwiązania Kamila, w planie potrzebne jest wyraźne sortowanie, które wiąże się ze znaczną utratą wydajności. Oto statystyki czasu, które otrzymałem podczas tego testu:
Czas wykonania:czas procesora =54891 ms, czas, który upłynął =60981 ms .Ponadto nadal istnieje wysoka kara czasu kompilacji wynosząca około jednej trzeciej sekundy.
Wniosek
Interesujące było przetestowanie rozwiązań opartych na CLR pod kątem wyzwań związanych z szeregami liczb, ponieważ wiele osób początkowo zakładało, że najlepiej działającym rozwiązaniem będzie prawdopodobnie rozwiązanie oparte na CLR. Kamil i Adam zastosowali podobne podejście, z pierwszą próbą wykorzystującą prostą pętlę, która zwiększa licznik i zwraca wiersz z następną wartością na iterację, oraz bardziej wyrafinowaną drugą próbę, która łączy części CLR i T-SQL. Osobiście nie podoba mi się to, że zarówno w drugim rozwiązaniu Kamila, jak i Adama opierali się na niedeterministycznym filtrze TOP, a kiedy przerobiłem go na deterministyczny we własnych testach, miało to negatywny wpływ na wydajność rozwiązania . Tak czy inaczej, nasze dwa rozwiązania T-SQL działają lepiej niż rozwiązania CLR i nie powodują jawnego sortowania w planie, gdy potrzebne są uporządkowane wiersze. Więc tak naprawdę nie widzę wartości w dalszym kontynuowaniu trasy CLR. Rysunek 9 zawiera podsumowanie wydajności rozwiązań, które przedstawiłem w tym artykule.
Rysunek 9:Porównanie wydajności czasu
Dla mnie GetNums_AlanCharlieItzikBatch powinien być rozwiązaniem z wyboru, gdy nie potrzebujesz absolutnie żadnego śladu we/wy, a GetNums_SQKWiki powinno być preferowane, gdy nie masz nic przeciwko małym śladom we/wy. Oczywiście zawsze możemy mieć nadzieję, że pewnego dnia Microsoft doda to niezwykle przydatne narzędzie jako wbudowane i miejmy nadzieję, że jeśli/kiedy to zrobią, będzie to wydajne rozwiązanie obsługujące przetwarzanie wsadowe i równoległość. Nie zapomnij więc zagłosować na tę prośbę o ulepszenie funkcji, a może nawet dodaj swoje komentarze, dlaczego jest to dla Ciebie ważne.
Bardzo podobała mi się praca nad tą serią. I learned a lot during the process, and hope that you did too.