Dynamiczny SQL i procedury składowane to dwa najważniejsze składniki SQL Server. W tym artykule przyjrzymy się zaletom i wadom każdego z nich oraz kiedy ich używać.
Wydajność
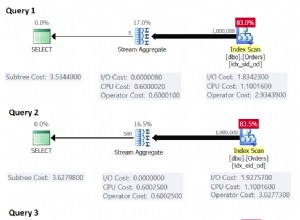
Każdy zna odpowiedź na to pytanie. Procedury składowane przewyższają dynamiczny SQL pod względem wydajności. Procedura składowana jest buforowana w pamięci serwera, a jej wykonanie jest znacznie szybsze niż dynamicznego SQL. Jeśli wszystkie pozostałe zmienne są utrzymywane na stałym poziomie, procedura składowana przewyższa dynamiczny SQL.
Oddzielenie obaw
Jeśli chodzi o separację obaw, procedury składowane wygrywają z dynamicznym SQL.
Procedury składowane umożliwiają oddzielenie logiki bazy danych od logiki biznesowej. Dlatego jeśli w logice biznesowej wystąpi błąd, wystarczy zmienić kod aplikacji. Z drugiej strony, jeśli wystąpi problem z logiką bazy danych, należy zmodyfikować tylko procedurę składowaną. Ponadto, jeśli procedura składowana zostanie zaktualizowana, kod aplikacji nie musi być ponownie kompilowany i wdrażany.
Jeśli używasz dynamicznych zapytań SQL w kodzie klienta, będziesz musiał zaktualizować kod aplikacji, jeśli wystąpi błąd w zapytaniu SQL. Oznacza to, że będziesz musiał ponownie skompilować i wdrożyć kod aplikacji.
Ruch sieciowy
Procedury składowane generują mniejszy ruch w sieci niż dynamiczny SQL, ponieważ wykonanie procedury składowanej wymaga wysłania przez sieć tylko nazwy procedury i parametrów (jeśli są).
Wykonywanie dynamicznego SQL wymaga przesłania całego zapytania przez sieć, zwiększając ruch w sieci, szczególnie jeśli zapytanie jest bardzo duże.
Ataki iniekcyjne SQL
Procedury składowane nie są podatne na ataki SQL Injection.
Zapytania dynamicznego SQL są podatne na ataki typu SQL injection, jeśli nie są używane zapytania parametryczne, a zapytań parametrycznych nie można używać z dynamicznym SQL, jeśli jako parametr przekazano nazwę tabeli lub kolumny.
W tym przypadku obejściem jest to, że funkcja nazwy kodu może zostać użyta do zapobiegania atakom typu SQL injection.
Ponowne wykorzystanie planów zapytań w pamięci podręcznej
Procedury składowane poprawiają wydajność bazy danych, ponieważ umożliwiają ponowne wykorzystanie buforowanych planów zapytań. W przypadku dynamicznego SQL będziesz musiał użyć zapytań parametrycznych, aby zwiększyć możliwość ponownego wykorzystania buforowanego planu zapytań. W przypadku braku sparametryzowanych planów zapytań serwer SQL automatycznie wykrywa parametry i generuje buforowane plany zapytań, co zapewnia lepszą wydajność.
Należy tutaj wspomnieć, że tylko systemy OLTP korzystają z możliwości ponownego wykorzystania buforowanego planu zapytań. W przypadku systemów OLAP, wybór optymalizatora zmienia się, system OLAP korzysta z unikalnego planu.
Konserwacja
Procedury składowane ze statycznym SQL są łatwiejsze w utrzymaniu. Na przykład w przypadku statycznego kodu SQL w procedurze składowanej błędy składniowe mogą zostać przechwycone przed uruchomieniem. W przypadku dynamicznego SQL wewnątrz procedur składowanych, błędy składniowe nie mogą zostać wyłapane przed wykonaniem zapytania.
Co więcej, procedury składowane są bardziej podobne do funkcji, są definiowane raz, a następnie można je wywoływać w dowolnym miejscu w skrypcie. Dlatego jeśli chcesz zaktualizować procedurę składowaną, wystarczy zaktualizować ją w jednym miejscu. Wszystkie części aplikacji wywołujące procedurę składowaną będą miały dostęp do zaktualizowanej wersji. Jednak wadą jest to, że te części aplikacji mogą również mieć wpływ, gdy nie chcesz zaktualizowanej procedury składowanej. W przypadku dynamicznego SQL może być konieczne napisanie skryptu SQL w wielu miejscach, ale w takich przypadkach aktualizacja skryptu w jednym miejscu nie wpływa na inne. Decyzja między użyciem procedury składowanej a dynamicznego SQL zależy od funkcjonalności aplikacji.
Bezpieczeństwo
Jeśli wiele aplikacji uzyskuje dostęp do bazy danych, bezpieczniej jest używać procedur zapisanych w bazie niż dynamicznego SQL.
Procedury składowane zapewniają dodatkową warstwę bezpieczeństwa, podczas gdy kontekst użytkownika jest jedynym sposobem kontrolowania uprawnień do dynamicznych skryptów SQL. Podsumowując, zabezpieczenie dynamicznego SQL jest pracochłonne w porównaniu z procedurami składowanymi.
Identyfikowanie zależności
W relacyjnej bazie danych tabele są zależne od innych tabel w bazie danych.
Rozważ scenariusz, w którym chcesz usunąć tabelę, ale zanim to zrobisz, chcesz poznać wszystkie zależności tabeli. Mówiąc prościej, chcesz znaleźć zapytania, które uzyskują dostęp do tabeli, którą chcesz usunąć. W takich przypadkach można użyć procedury składowanej sp_depends.
Jednak sp_depends może wykryć tylko te zależności, w których statyczny kod SQL jest używany wewnątrz procedury składowanej. W przypadku, gdy dynamiczny kod SQL jest zależny od tabeli, ta zależność nie może zostać wykryta przez procedurę składowaną sp_depends. Zobaczmy to w akcji za pomocą prostego przykładu.
Przygotowywanie fikcyjnych danych
Stwórzmy kilka fikcyjnych danych, które pomogą wyjaśnić koncepcję zależności w statycznym i dynamicznym SQL.
CREATE DATABASE deptest;
USE deptest
CREATE TABLE student
(
Id int identity primary key,
Name VARCHAR(50) NOT NULL,
Gender VARCHAR(50) NOT NULL,
Age int
)
INSERT INTO student
VALUES
('James', 'Male', 20),
('Helene', 'Female', 20),
('Sofia', 'Female', 20),
('Ed', 'Male', 20),
('Ron', 'Female', 20) Teraz mamy testową bazę danych zawierającą tabelę i trochę danych testowych. Teraz utwórzmy dwie procedury składowane, które mają dostęp do tabeli ucznia.
Pierwsza procedura składowana używa statycznego kodu SQL do pobrania wszystkich rekordów z tabeli uczniów:
USE deptest GO CREATE PROC spStatProc AS BEGIN SELECT * FROM student END
Wykonaj powyższy skrypt. Ten skrypt tworzy procedurę składowaną „spStatProc” wewnątrz bazy danych deptest.
Utwórzmy inną procedurę składowaną, która zawiera dynamiczny kod SQL, który pobiera wszystkie rekordy z tabeli uczniów.
USE deptest GO CREATE PROC spDynProc AS BEGIN DECLARE @query NVARCHAR(100) SET @query = 'SELECT * FROM student' EXECUTE sp_execute @query END
Ten skrypt tworzy procedurę składowaną „spDynProc” wewnątrz bazy danych deptest. Ta procedura składowana wykorzystuje dynamiczną instrukcję SQL do pobrania wszystkich rekordów z tabeli uczniów.
Teraz mamy dwie procedury składowane, które są zależne od tabeli uczniów. Jeden z nich zawiera statyczny SQL, a drugi zawiera dynamiczny SQL.
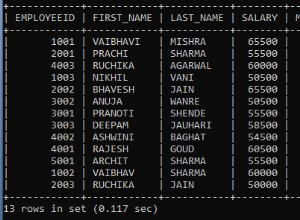
Jeśli jednak wykonasz procedurę składowaną sp_depends i przekażesz ją do tabeli uczniów jako parametr, zobaczysz, że zostanie pobrana tylko procedura składowana „spStatProc”. Dzieje się tak, ponieważ zawiera statyczny kod SQL. Procedura składowana „spDynProc” zostanie zignorowana, ponieważ zawiera dynamiczny SQL.
Wykonaj następujący skrypt.
USE deptest GO EXECUTE sp_depends student
Otrzyma następujące dane wyjściowe:
[identyfikator tabeli=40 /]
Widać, że sp_depends nie był w stanie zgłosić zależności „spDynProc” i zgłosił tylko „spStatProc”.
Złożoność
Procedury składowane mogą być bardzo złożone, jeśli używasz dużej liczby filtrów, a między filtrami jest wiele klauzul AND i OR. Z drugiej strony, używając dynamicznego SQL, możesz dynamicznie generować klauzule WHERE w zależności od typu filtrów. To sprawia, że dynamiczny SQL jest lepszym wyborem, jeśli chcesz zaimplementować niezwykle złożoną logikę.
Wniosek
Ogólnie rzecz biorąc, procedura składowana przewyższa dynamiczny SQL w prawie wszystkich aspektach. Są szybsze, bezpieczne i łatwe w utrzymaniu oraz wymagają mniejszego ruchu w sieci. Z reguły procedury składowane powinny być używane w scenariuszach, w których nie trzeba modyfikować zapytań, a zapytania nie są bardzo złożone. Jeśli jednak często zmieniasz nazwy tabel, nazw kolumn lub liczbę parametrów w zapytaniu, dynamiczny SQL jest lepszym wyborem ze względu na prostszą strategię implementacji.
Przydatne linki
- Dynamiczny SQL a procedury przechowywane
- Nie bój się dynamicznego SQL
- Tworzenie wysokowydajnych procedur składowanych
- Klasy dotyczące procedur zapisanych