Przechowywanie ~3,5 TB danych i wstawianie około 1 tys.
- jakie masz w tym celu wymagania dotyczące dostępności? 99,999% czasu pracy, czy wystarczy 95%?
- jakie masz wymagania dotyczące niezawodności? Czy brak wkładki kosztuje 1 milion dolarów?
- jakie masz wymagania dotyczące możliwości odzyskania? Jeśli stracisz jeden dzień danych, czy to ma znaczenie?
- jakie masz wymagania dotyczące spójności? Czy zapis musi być gwarantowany, aby był widoczny przy następnym czytaniu?
Jeśli potrzebujesz wszystkich tych wymagań, które podkreśliłem, proponowane obciążenie będzie kosztować miliony sprzętu i licencji w systemie relacyjnym, dowolnym systemie, bez względu na to, jakich sztuczek spróbujesz (sharding, partycjonowanie itp.). System nosql z samej definicji nie spełniałby wszystkich te wymagania.
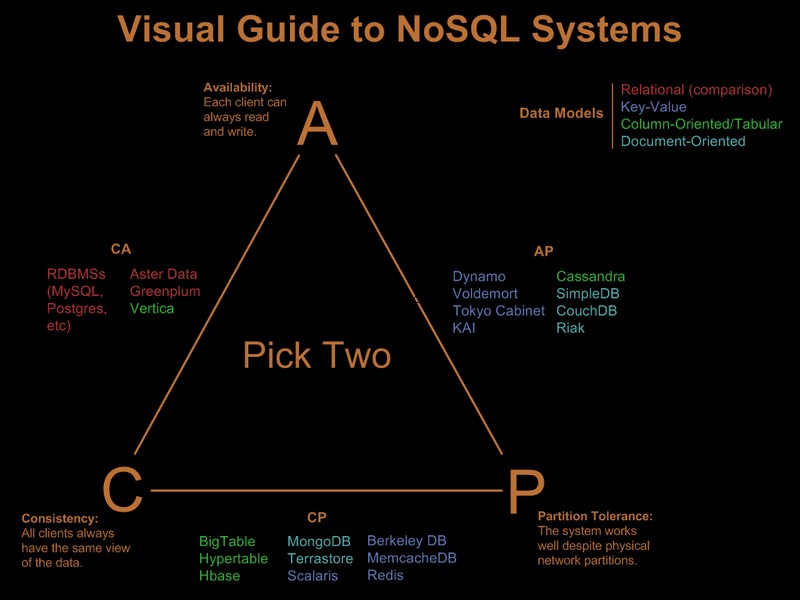
Więc oczywiście złagodziłeś już niektóre z tych wymagań. Istnieje ładny wizualny przewodnik porównujący oferty nosql w oparciu o paradygmat „wybierz 2 z 3” w Visual Guide to NoSQL Systems:
Po aktualizacji komentarza OP
Z SQL Server byłaby to prosta implementacja:
- jeden klucz klastrowy pojedynczej tabeli (GUID, czas). Tak, ulegnie fragmentacji, ale czy fragmentacja ma wpływ na odczyty z wyprzedzeniem, a odczyty z wyprzedzeniem są potrzebne tylko w przypadku skanowania o dużym zasięgu. Ponieważ zapytania dotyczą tylko określonego identyfikatora GUID i zakresu dat, fragmentacja nie będzie miała większego znaczenia. Tak, jest to klucz szeroki, więc strony bez kartek będą miały słabą gęstość klucza. Tak, doprowadzi to do słabego współczynnika wypełnienia. I tak, mogą wystąpić podziały stron. Pomimo tych problemów, biorąc pod uwagę wymagania, nadal jest to najlepszy wybór klucza klastrowego.
- Podziel tabelę według czasu, aby umożliwić skuteczne usuwanie wygasłych rekordów za pomocą automatycznego okna przesuwnego. Uzupełnij to przebudową partycji indeksu online z ostatniego miesiąca, aby wyeliminować słaby współczynnik wypełnienia i fragmentację wprowadzoną przez klastrowanie GUID.
- włącz kompresję stron. Ponieważ najpierw klastrowane są grupy kluczy według GUID, wszystkie rekordy GUID będą znajdować się obok siebie, dając kompresji strony dużą szansę na wdrożenie kompresji słownika.
- Będziesz potrzebować szybkiej ścieżki we/wy do pliku dziennika. Interesuje Cię wysoka przepustowość, a nie małe opóźnienia, aby dziennik mógł nadążyć za 1 tys.
Partycjonowanie i kompresja stron wymagają serwera SQL w wersji Enterprise Edition, nie będą działać w wersji Standard Edition i oba są bardzo ważne, aby spełnić wymagania.
Na marginesie, jeśli rekordy pochodzą z frontowej farmy serwerów WWW, umieściłbym Express na każdym serwerze WWW i zamiast INSERT na zapleczu, SEND informacje do zaplecza, korzystając z lokalnego połączenia/transakcji w ekspresie znajdującym się w tym samym miejscu co serwer sieciowy. Daje to znacznie lepszą historię dostępności rozwiązania.
Więc tak zrobiłbym to w SQL Server. Dobrą wiadomością jest to, że problemy, z którymi się zmierzysz, są dobrze zrozumiane, a rozwiązania znane. to niekoniecznie oznacza, że jest to lepsze niż to, co można osiągnąć za pomocą Cassandry, BigTable lub Dynamo. Pozwolę komuś bardziej kompetentnemu w sprawach nie-sql-owskich argumentować swoją sprawę.
Zauważ, że nigdy nie wspomniałem o modelu programowania, obsłudze .Net i tym podobnych. Szczerze myślę, że są one nieistotne w przypadku dużych wdrożeń. Robią ogromną różnicę w procesie rozwoju, ale po wdrożeniu nie ma znaczenia, jak szybki był program, jeśli narzut ORM zmniejsza wydajność :)