"Waitstats pomaga nam zidentyfikować liczniki związane z wydajnością. Jednak sama informacja o oczekiwaniu nie wystarczy, aby dokładnie zdiagnozować problemy z wydajnością. Komponent kolejek naszej metodologii pochodzi z liczników Performance Monitor, które zapewniają wgląd w wydajność systemu z punktu widzenia zasobów.”Tom Davidson, Otwieram Microsoft's Performance-Tuning Toolbox
Magazyn SQL Server Pro, grudzień 2003
Oczekiwania i kolejki są używane jako metodologia dostrajania wydajności programu SQL Server od czasu opublikowania powyższego artykułu przez Toma Davidsona, a także dobrze znanego raportu o oczekiwaniach i kolejkach w programie SQL Server 2005 w 2006 roku. W połączeniu z metrykami zasobów, oczekiwania mogą być przydatne dla ocena pewnych charakterystyk wydajności obciążenia pracą i pomoc w sterowaniu wysiłkiem dostrajania. Dane Waits są ujawniane przez wiele rozwiązań do monitorowania wydajności SQL Server i od samego początku byłem zwolennikiem dostrajania przy użyciu tej metodologii. Podejście to miało wpływ na projekt pulpitu nawigacyjnego wydajności SQL Sentry, który przedstawia oczekiwania w otoczeniu kolejek (kluczowe wskaźniki zasobów), aby zapewnić kompleksowy obraz wydajności serwera.
Jednak wydaje się, że niektórzy przeoczyli tezę Davidsona dotyczącą znaczenia zasobów i prawie całkowicie polegają na czekaniu, aby przedstawić obraz wydajności zapytań i stanu systemu. Statystyki oczekiwania pochodzą bezpośrednio z silnika SQL Server i są łatwe do wykorzystania i kategoryzacji. Oczekujące zapytania oznaczają oczekujące aplikacje i użytkowników, a nikt nie lubi czekać! Łatwiej jest ewangelizować strojenie za pomocą czekania jako pojedynczego rozwiązania do szybszego tworzenia zapytań i aplikacji niż opowiedzenia całej historii, która jest bardziej zaangażowana.
Niestety, podejście skoncentrowane na czekaniu i wykluczeniu analizy zasobów może wprowadzać w błąd, a w najgorszym przypadku tracisz wzrok. Członkowie zespołu SentryOne, Kevin Kline i Steve Wright, poruszyli to już wcześniej. W tym poście przyjrzę się dokładniej niektórym najnowszym badaniom, które umożliwił Query Store, które rzuciły nowe światło na to, jak niewystarczające może być dostrajanie z wyłącznością oczekiwania.
Najpopularniejsze zapytania, których nie było
Niedawno klient SentryOne skontaktował się ze mną w sprawie problemów z wydajnością swojej bazy danych SentryOne. W sercu każdego środowiska monitorowania SentryOne znajduje się pojedyncza baza danych SQL Server, a ten klient monitorował około 600 serwerów za pomocą naszego oprogramowania. W tej skali sporadyczne problemy z wydajnością zapytań nie są niczym niezwykłym i trzeba trochę je dostroić, a niektóre rzekomo nowe zapytania w obciążeniu były źródłem ich obaw.
Dołączyłem do sesji udostępniania ekranu, aby się przyjrzeć, a klient najpierw przedstawił mi dane z innego systemu, który również monitorował bazę danych SentryOne. System zastosował podejście oczekiwania na poziomie zapytania i pokazał dwie procedury składowane jako odpowiedzialne za około połowę czasów oczekiwania na serwerze bazy danych SQL Sentry. Było to niezwykłe, ponieważ te dwie procedury zawsze działały bardzo szybko i nigdy nie wskazywały na rzeczywisty problem z wydajnością w naszej bazie danych. Zdziwiony, przełączyłem się na SQL Sentry, aby zobaczyć, co nam pokaże, i zdziwiłem się, widząc, że w tym samym przedziale czasu procedura nr 1 w drugim systemie była #6, #7 i #8 pod względem całkowitego czasu trwania, procesora i odczyty logiczne odpowiednio:
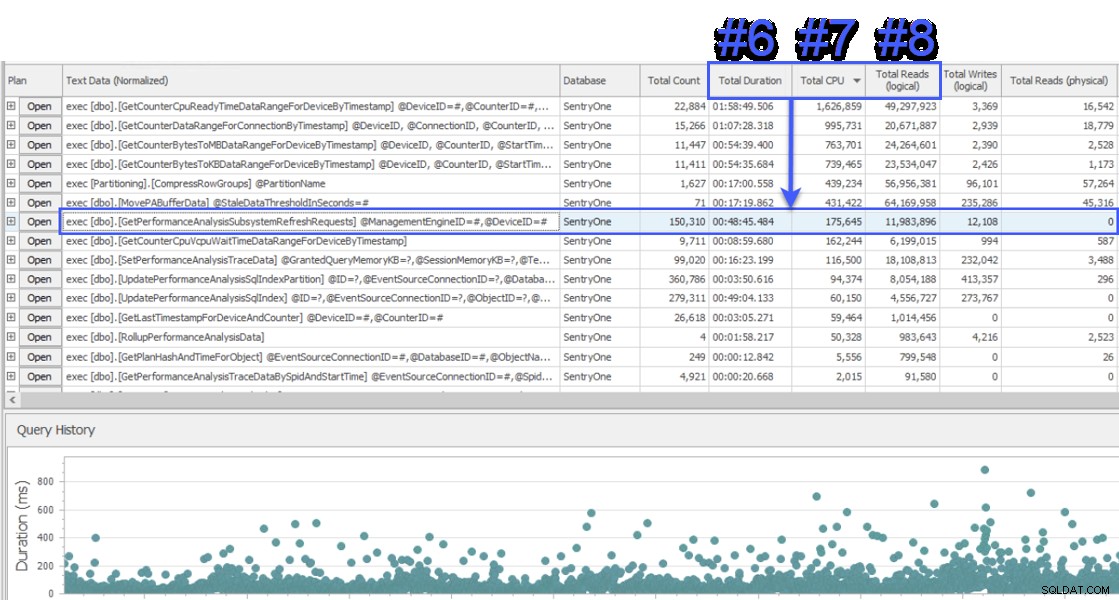 Widok „Top SQL” w SQL Sentry
Widok „Top SQL” w SQL Sentry
Z punktu widzenia zużycia zasobów oznaczało to, że powyższe zapytania reprezentowały 75% całkowitego czasu trwania, 87% całkowitego procesora i 88% odczytów logicznych. Co więcej, procedura nr 2 w drugim systemie nie znalazła się nawet w pierwszej trzydziestce w SQL Sentry, pod żadnym względem! Te dwa zapytania były dalekie od pierwszych dwóch, a zapytania, które stanowiły większość rzeczywistych zużycie w systemie było poważnie niedoreprezentowane.
Zawsze zakładałem, że istnieje silniejsza korelacja między najlepszymi kelnerami a najlepszymi konsumentami zasobów, ale nigdy nie przeprowadzałem takiego bezpośredniego porównania na poziomie zapytania, więc te wyniki były co najmniej zaskakujące. Moje zainteresowanie wzbudziło się, postanowiłem zbadać, czy ta sytuacja była typowa czy anormalna.
Zapytanie Store 2017 na ratunek
W SQL Server 2017 i nowszych, Query Store przechwytuje oczekiwania na poziomie zapytania oprócz zużycia zasobów przez zapytania. Erin Stellato zrobiła świetny post na Query Store czeka tutaj. Jest to mniejsze obciążenie i dokładniejsze niż zapytania DMV czekają na co sekundę, mając nadzieję na przechwycenie zapytań w locie, co jest standardowym podejściem stosowanym przez inne narzędzia, w tym wyżej wymienione.
SQL Sentry zawsze rejestrował oczekiwania, ale na poziomie instancji SQL Server, ze względu na te obawy dotyczące obciążenia i dokładności. Szczegółowe oczekiwania na zapytania są dostępne na żądanie za pośrednictwem zintegrowanego Eksploratora planów. Oceniamy rozszerzenie oczekiwania na poziomie wystąpienia o dane na poziomie zapytania z magazynu zapytań, jeśli są dostępne.
W tym przedsięwzięciu skorzystałem z pomocy SentryOne Product Advisory Council, grupy klientów, partnerów i przyjaciół SentryOne z branży, którzy uczestniczą w prywatnym kanale Slack. Udostępniłem ten skrypt, aby zrzucić dane z ostatnich 8 godzin z Query Store i otrzymałem wyniki z 11 serwerów produkcyjnych z wielu branż, w tym usług finansowych, publikowania gier, śledzenia kondycji i ubezpieczeń.
Tutaj udokumentowano kategorie oczekiwania magazynu zapytań. W analizie uwzględniono wszystkie kategorie z wyjątkiem tych, które zostały usunięte z podanych powodów:
- Równoległość – Może szalenie zawyżać czas oczekiwania na zapytanie znacznie powyżej jego rzeczywistego czasu trwania, ponieważ wiele wątków może odrzucić powiązane oczekiwania, myląc korelację z czasem trwania i innymi metrykami. Co więcej, chociaż podział CXPACKET/CXCONSUMER jest pomocny, CXPACKET nadal oznacza tylko równoległość i niekoniecznie jest problematyczny lub możliwy do wykonania.
- Procesor – Czas oczekiwania na sygnał może być pomocny w ustalaniu wąskich gardeł procesora poprzez korelację z oczekiwaniami na zasoby, ale Query Store obecnie zawiera tylko SOS_SCHEDULER_YIELD w tej kategorii, co nie jest oczekiwaniem w tradycyjnym sensie, jak opisano tutaj. Nie nadaje się do łatwego porównywania lub korelacji, zwłaszcza gdy SQL Server znajduje się na maszynie wirtualnej działającej na hoście z nadmierną subskrypcją. Na przykład, na jednym serwerze oczekiwania procesora Query Store stanowiły 227% całkowitego czasu procesora we wszystkich zapytaniach bez paralelizmu, co nie powinno być możliwe.
- Oczekiwanie na użytkownika iBezczynny – Te kategorie składają się wyłącznie z timera i oczekiwania w kolejce i zostały wykluczone z tego samego powodu, dla którego należy zawsze wykluczać te typy – są nieszkodliwe i powodują tylko hałas.
Nawiasem mówiąc, ostatnio rozmawiałem z ojcem Query Store, Conorem Cunninghamem, o prawdopodobieństwie przyszłych zmian w typach i kategoriach oczekiwania Query Store i powiedział, że jest to z pewnością możliwe… więc musimy mieć oko na to.
Wyniki analizy TL;DR
Po szczegółowej analizie potwierdziłem, że wyniki obserwowane w systemie klienta nie są anormalne, a raczej powszechne. Oznacza to, że jeśli jesteś zależny od narzędzia skoncentrowanego na oczekiwaniu do monitorowania i dostrajania obciążeń, istnieje duże prawdopodobieństwo, że skupiasz się na niewłaściwych zapytaniach i pomijasz te, które odpowiadają za większość czasu trwania zapytania i zużycia zasobów w systemie. Ponieważ zużycie procesora i IO przekłada się bezpośrednio na sprzęt serwerowy i wydatki w chmurze, jest to znaczące.
Większość zapytań nie czeka
Ciekawym i ważnym odkryciem, które omówię jako pierwsze, jest to, że większość zapytań w ogóle nie generuje żadnych oczekiwań. Z 56 438 wszystkich zapytań na wszystkich serwerach tylko 9781 (17%) miało jakikolwiek czas oczekiwania, a tylko 8092 (14%) miało czas oczekiwania ze znaczących typów. Jeśli korzystasz z funkcji oczekiwania w celu określenia, które zapytania należy zoptymalizować, pominiesz większość zapytań w obciążeniu.
Korelowanie oczekiwania i zasobów
Przeanalizowałem, w jaki sposób oczekiwania odnoszą się do zużycia zasobów, klasyfikując wszystkie zapytania w każdym systemie według oczekiwań i zasobów oraz używając rang do obliczenia korelacji Spearmana. To, co ostatecznie próbujemy ustalić, to czy najlepsi kelnerzy są zazwyczaj najlepszymi konsumentami. Jak się okazuje, nie.
Tabela 1 pokazuje współczynniki korelacji w skali kolorów dla średniego oczekiwania na zapytanie czas z innymi miarami – wartość 1,00 (ciemnoniebieski) reprezentuje dane, które są doskonale skorelowane. Jak widać, korelacja z oczekiwaniami i innymi miarami na większości serwerów nie jest silna, a dla jednego serwera występuje ujemna korelacja z większością miar.
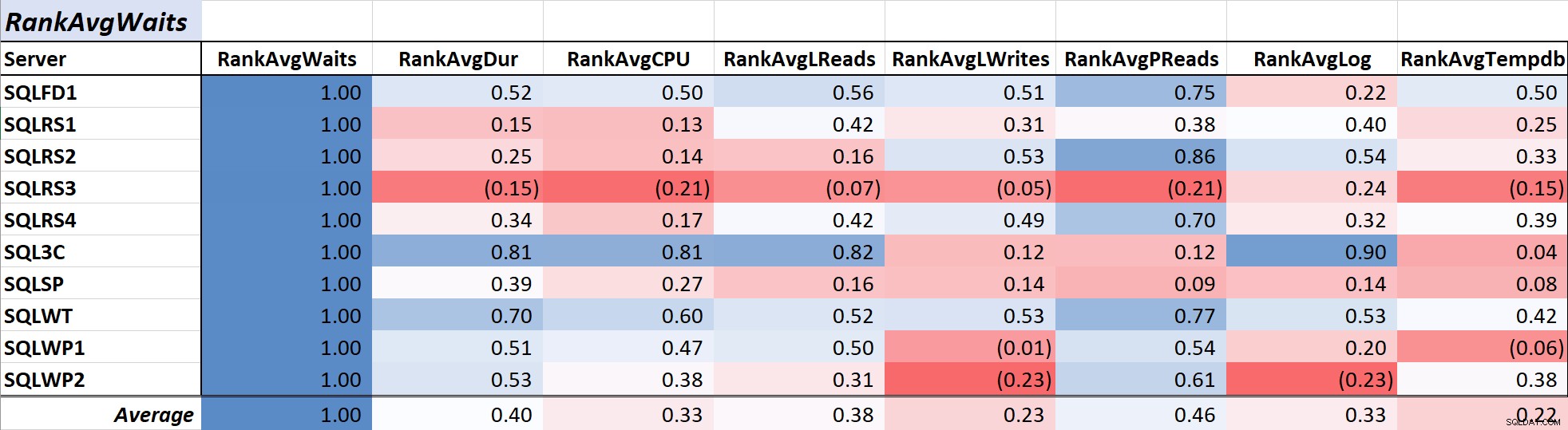 Tabela 1:Korelacja ze średnim czasem oczekiwania na zapytanie (ms)
Tabela 1:Korelacja ze średnim czasem oczekiwania na zapytanie (ms)
Czas trwania zapytania jest często głównym problemem dla administratorów baz danych i programistów, ponieważ przekłada się bezpośrednio na wrażenia użytkownika, a Tabela 2 pokazuje korelację między średnim czasem trwania zapytania i inne środki. Korelacja z czasem trwania i dwoma podstawowymi miarami zasobów, procesorem i odczytami logicznymi, jest dość silna i wynosi odpowiednio 0,97 i 0,75.
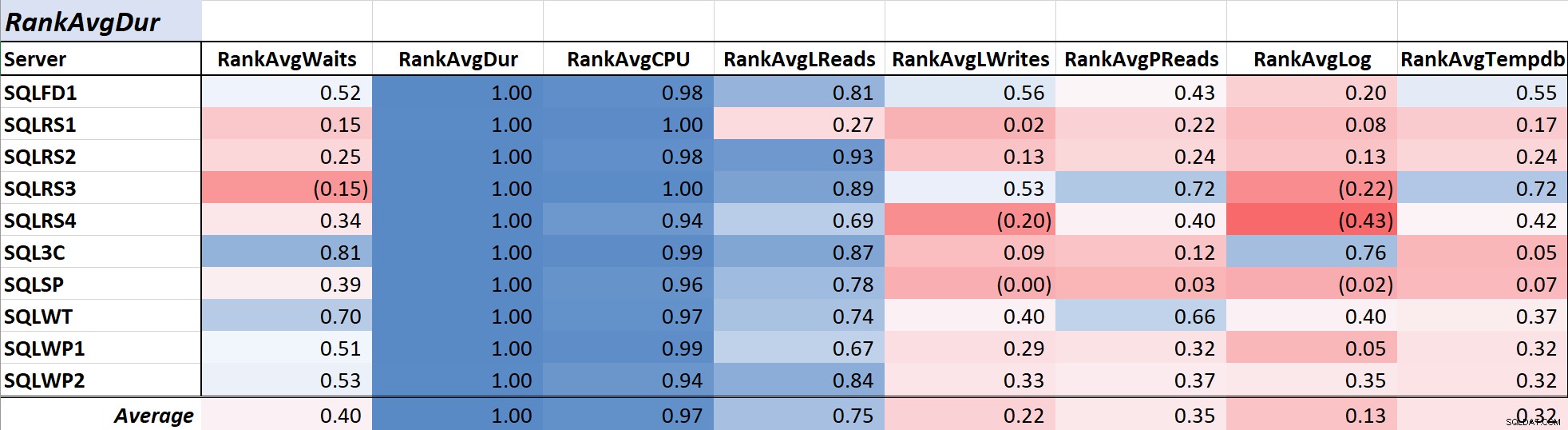 Tabela 2:Korelacja ze średnim czasem trwania zapytania (ms)
Tabela 2:Korelacja ze średnim czasem trwania zapytania (ms)
Ponieważ odczyty logiczne zawsze wykorzystują procesor i, podobnie jak czas trwania, procesor jest mierzony w milisekundach, ta zależność nie jest zaskakująca. Wyniki są zgodne z ideą, że jeśli chcesz, aby aplikacje bazodanowe działały tak szybko, jak to możliwe, skupienie się na zmniejszeniu mocy obliczeniowej zapytań i odczytów logicznych będzie bardziej efektywne w skracaniu czasu trwania niż przy użyciu samych czasów oczekiwania. Na szczęście robienie tego poprzez lepsze projektowanie zapytań, indeksowanie itp. jest zwykle prostszą propozycją niż bezpośrednie skrócenie czasu oczekiwania na zapytanie. Kolega Aaron Bertrand skutecznie przedstawia niektóre zastrzeżenia podczas strojenia z czekami.
% całkowitego czasu oczekiwania
Następnie przyjrzałem się, czy zapytania o najwyższym czasie oczekiwania zwykle odpowiadają za największe zużycie zasobów. Chcemy ustalić, czy to, co widzieliśmy w systemie klienta, jest nietypowe, gdzie 2 najczęściej oczekujące zapytania stanowiły stosunkowo niewielki procent całkowitego zużycia zasobów.
Wykres 1 poniżej pokazuje % całkowitego procesora i odczytów logicznych dla każdego serwera rozliczanych przez zapytania reprezentujące 75% całkowitego czasu oczekiwania. Tylko jeden serwer miał zasób przekraczający 75% – odczyty na SQLRS3. Co do reszty, zapytania odpowiedzialne za 75% czasu oczekiwania pochłaniały mniej niż 75% zasobów – często znacznie mniej. Odzwierciedla to, co widzieliśmy w systemie klienta i jest zgodne z analizą korelacji.
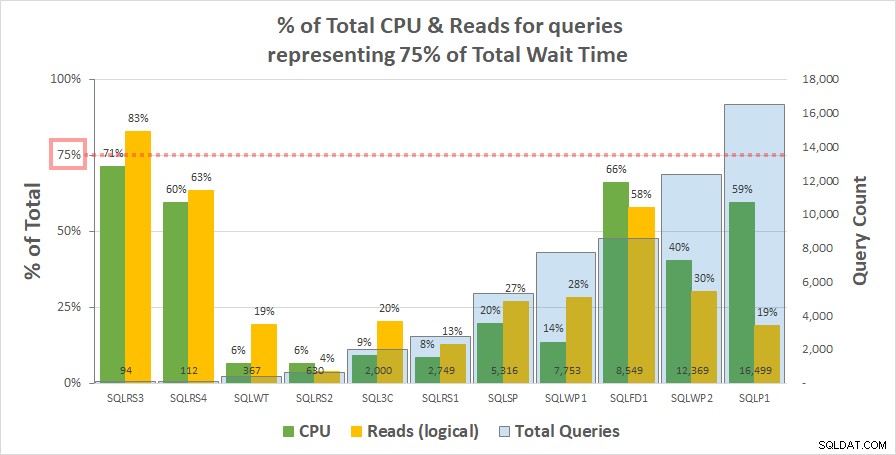 Wykres 1
Wykres 1
Zwróć uwagę, że wydaje się, że istnieje związek z łączną liczbą zapytań w obciążeniu. Jest to reprezentowane przez jasnoniebieską serię kolumn na pomocniczej osi y, a wykres jest posortowany rosnąco według tej serii. Dwa serwery o najwyższych miarach zasobów przy 75% oczekiwania miały również najmniej zapytań (SQLRS3 i SQLRS4). Im mniejsze obciążenie, tym większy potencjalny wpływ małej liczby zapytań, i oczywiście na obu serwerach tylko dwa zapytania odpowiadały za większość czasu oczekiwania i zasobów. Jednym ze sposobów patrzenia na to jest to, że czekanie pomaga najbardziej zidentyfikować najcięższe zapytania, gdy najmniej ich potrzebujesz.
Czas oczekiwania i czas trwania zapytania
Na koniec oszacowałem % całkowitego czasu oczekiwania do całkowitego czasu trwania zapytania w każdym systemie. Tabela 3 zawiera kolumny dla:
- Całkowity czas trwania zapytania w ms
- Całkowity czas oczekiwania ms – surowe
- Całkowity czas oczekiwania ms – bez równoległości, bezczynności i oczekiwania użytkownika (Rev1)
- Całkowity czas oczekiwania ms – bez równoległości, bezczynności, oczekiwania użytkownika i procesora (Rev2)
- % czasu trwania dla 3 kolumn czasu oczekiwania z paskami danych
- Całkowita liczba unikalnych zapytań z paskami danych
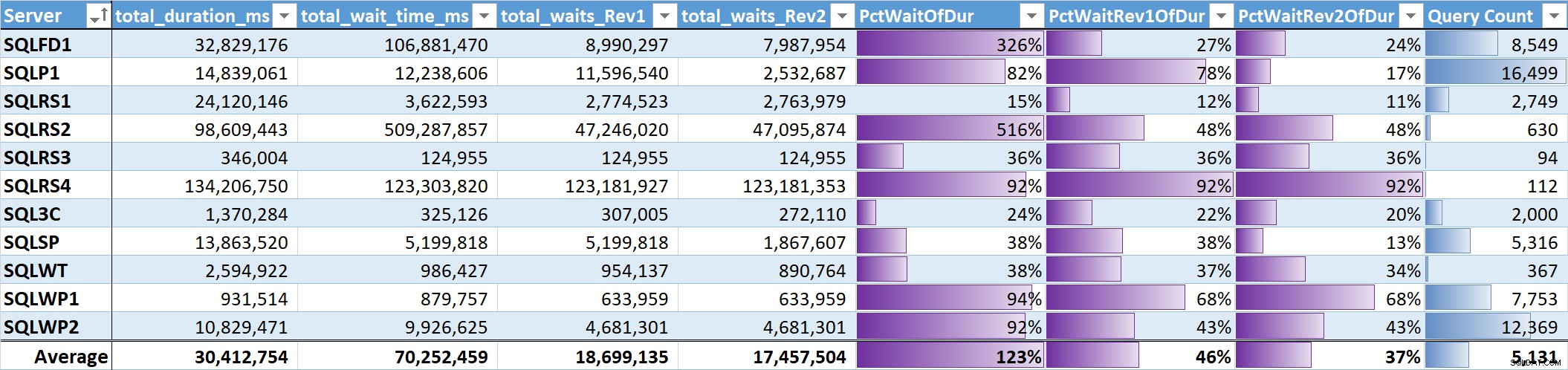 Tabela 3
Tabela 3
Nieważona średnia dla znaczących oczekiwań (Wersja 2) we wszystkich systemach stanowi 37% całkowitego czasu trwania zapytania. Na pięciu systemach było to mniej niż 25%, a tylko na dwóch przekraczało 50%. W systemie z 92% czasem oczekiwania (SQLRS4), jednym z najmniejszą liczbą zapytań, dwa zapytania odpowiadały za 99% czasów oczekiwania, 97% czasu trwania, 84% procesora i 86% odczytów.
Chociaż czas oczekiwania może reprezentować znaczną część czasu wykonywania zapytań w niektórych systemach i wydaje się intuicyjne, że jeśli skrócisz czas oczekiwania, czas oczekiwania również spadnie, zauważyliśmy, że czas oczekiwania i czas trwania są słabo skorelowane. To raczej nie będzie takie proste, a moje własne doświadczenie to potwierdza. Potrzebne są dalsze badania.
Kompleksowe dostrajanie za pomocą programu Plan Explorer i SQL Sentry
Jak często sugeruje ten doskonały raport dotyczący SQLskills, źródłem długich czasów oczekiwania są często niezoptymalizowane zapytania i indeksy. Bezpłatny SentryOne Plan Explorer został stworzony z myślą o zmniejszeniu zużycia zasobów poprzez efektywne dostrajanie zapytań za pomocą modułu analizy indeksów i wielu innych innowacyjnych funkcji. SQL Sentry integruje Plan Explorer bezpośrednio z modułami Top SQL, Blocking i Deadlocks, dzięki czemu możesz automatycznie przechwytywać i dostrajać problematyczne zapytania w jednym miejscu. Możesz łatwo wybrać zakres zainteresowań na historycznych wykresach oczekiwania, procesora lub we/wy na pulpicie nawigacyjnym SQL Sentry i przejść do widoku Top SQL, aby znaleźć zapytania, które w tym czasie pochłaniają najwięcej zasobów. Następnie jednym kliknięciem możesz otworzyć zapytanie w Eksploratorze planów i uzyskać szczegółowe oczekiwania na poziomie zapytania i zasoby na żądanie w razie potrzeby. Nie sądzę, że istnieje lepsze ucieleśnienie pełnej metodologii dostrajania Waits and Queues niż ta.
 Wykres „Oczekiwania” w panelu SQL Sentry
Wykres „Oczekiwania” w panelu SQL Sentry
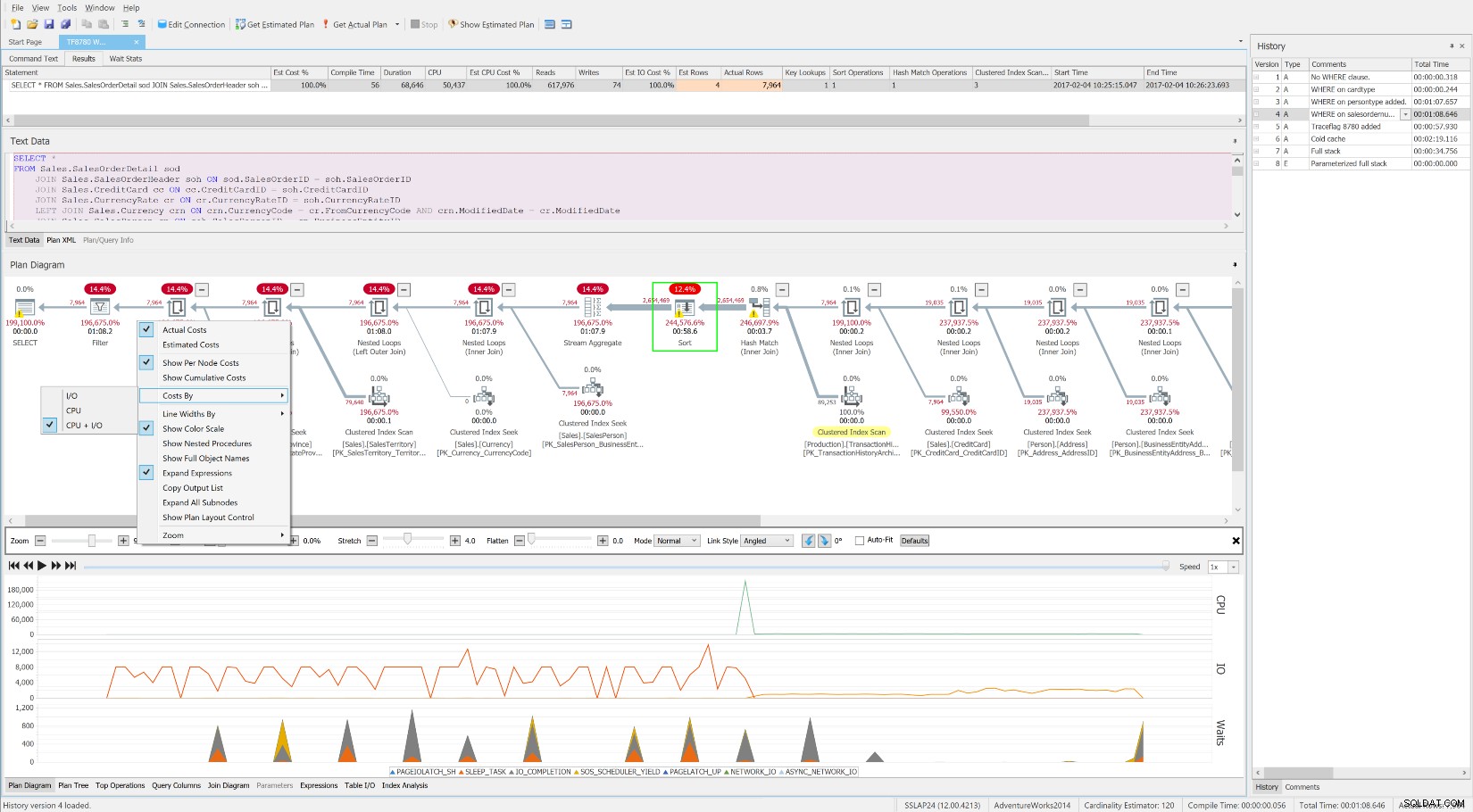 Bezpłatny Eksplorator planów SentryOne pokazujący oczekiwania w czasie wraz z poziomem operacji koszty i zasoby
Bezpłatny Eksplorator planów SentryOne pokazujący oczekiwania w czasie wraz z poziomem operacji koszty i zasoby
Wniosek
Dostrajanie za pomocą czasów oczekiwania i kolejek ma takie samo zastosowanie do wydajności SQL Server dzisiaj, jak w 2006 roku. Jednak skupianie się na oczekiwaniach z wykluczeniem zasobów jest niebezpieczne dla biznesu, ponieważ z danych jasno wynika, że spowoduje to ogólnie niezoptymalizowane i nieopłacalne systemy. Jeśli chodzi o zasoby sprzętowe i wydatki na chmurę, ostatecznie płacisz za zasoby obliczeniowe i we/wy, a nie za czas oczekiwania, dlatego celowa jest optymalizacja bezpośrednio pod kątem zużycia. Z mojego doświadczenia wynika, że wraz ze spadkiem zużycia zasobów i związanej z nim rywalizacji, naturalnie nastąpi skrócenie czasu oczekiwania.
Potwierdzenie
Chciałbym podziękować Fredowi Frostowi, głównemu naukowcowi ds. danych w SentryOne, za jego cenny wkład i krytyczną recenzję tej analizy.