Zgrupowana konkatenacja jest częstym problemem w SQL Server, bez bezpośrednich i zamierzonych funkcji, które go obsługują (takich jak XMLAGG w Oracle, STRING_AGG lub ARRAY_TO_STRING(ARRAY_AGG()) w PostgreSQL i GROUP_CONCAT w MySQL). Poproszono o to, ale jeszcze się nie udało, o czym świadczą te elementy Connect:
- Połącz #247118:SQL wymaga wersji funkcji MySQL group_Concat (przełożone)
- Połącz #728969:Uporządkowane funkcje zestawu — klauzula WEWNĄTRZ GRUPY (zamknięta, ponieważ nie da się naprawić)
** AKTUALIZACJA ze stycznia 2017 r. ** :STRING_AGG() będzie w SQL Server 2017; przeczytaj o tym tutaj, tutaj i tutaj.
Co to jest zgrupowana konkatenacja?
W przypadku nieinicjowanej konkatenacji zgrupowanej ma miejsce, gdy chcesz zebrać wiele wierszy danych i skompresować je w jeden ciąg (zwykle z ogranicznikami, takimi jak przecinki, tabulatory lub spacje). Niektórzy mogą nazwać to „sprzężeniem poziomym”. Szybki wizualny przykład pokazujący, jak skompresować listę zwierząt należących do każdego członka rodziny, od znormalizowanego źródła do „spłaszczonego” wyniku:
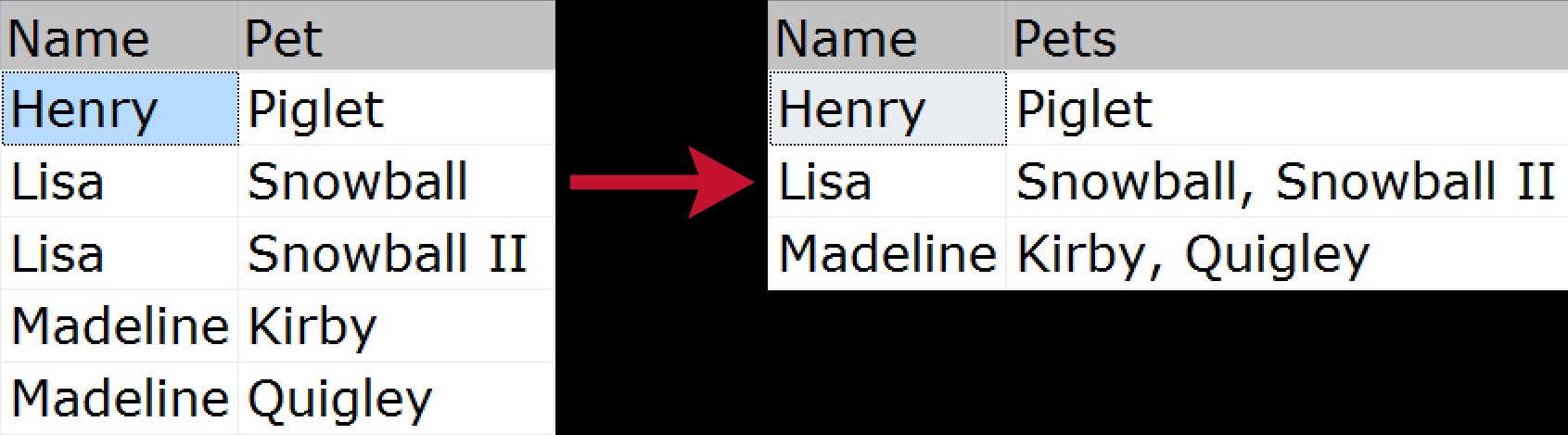
Przez lata istniało wiele sposobów rozwiązania tego problemu; oto tylko kilka, w oparciu o następujące przykładowe dane:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Nie zamierzam przedstawiać wyczerpującej listy wszystkich grupowych podejść konkatenacji, jakie kiedykolwiek wymyślono, ponieważ chcę skupić się na kilku aspektach zalecanego przeze mnie podejścia, ale chcę wskazać kilka z bardziej powszechnych:
Skalarny UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Uwaga:istnieje powód, dla którego tego nie robimy:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Z DISTINCT , funkcja jest uruchamiana dla każdego wiersza, a następnie duplikaty są usuwane; z GROUP BY , duplikaty są usuwane jako pierwsze.
Środowisko uruchomieniowe języka wspólnego (CLR)
Używa GROUP_CONCAT_S funkcja znaleziona na https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
Rekursywny CTE
Istnieje kilka odmian tej rekurencji; ten wyciąga zestaw różnych nazw jako kotwicę:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Kursor
Niewiele tu do powiedzenia; kursory zwykle nie są optymalnym podejściem, ale może to być jedyny wybór, jeśli utkniesz na SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Dziwaczna aktualizacja
Niektórzy ludzie *kochają* to podejście; W ogóle nie rozumiem tej atrakcji.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; DLA ŚCIEŻKI XML
Całkiem łatwo moja ulubiona metoda, przynajmniej częściowo, ponieważ jest to jedyny sposób na *zagwarantowanie* zamówienia bez użycia kursora lub CLR. To powiedziawszy, jest to bardzo surowa wersja, która nie rozwiązuje kilku innych nieodłącznych problemów, które omówię dalej:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Widziałem wiele osób błędnie zakładających, że nowy CONCAT() funkcja wprowadzona w SQL Server 2012 była odpowiedzią na te żądania funkcji. Ta funkcja ma działać tylko na kolumnach lub zmiennych w jednym wierszu; nie może być używany do łączenia wartości w wierszach.
Więcej na temat FOR XML PATH
FOR XML PATH('') samo w sobie nie jest wystarczająco dobre – ma znane problemy z entycyzacją XML. Na przykład, jeśli zaktualizujesz imię jednego z zwierzaków, tak aby zawierało nawias HTML lub znak ampersand:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Po drodze są one tłumaczone na bezpieczne jednostki XML:
Qui>gle&y
Dlatego zawsze używam PATH, TYPE).value() , w następujący sposób:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Zawsze używam też NVARCHAR , ponieważ nigdy nie wiadomo, kiedy jakaś podstawowa kolumna będzie zawierać Unicode (lub później zostanie w tym celu zmieniona).
Możesz zobaczyć następujące odmiany w .value() , a nawet inne:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Są one wymienne, wszystkie ostatecznie reprezentują ten sam ciąg; różnice w wydajności między nimi (więcej poniżej) były znikome i prawdopodobnie całkowicie niedeterministyczne.
Innym problemem, który możesz napotkać, są pewne znaki ASCII, których nie można przedstawić w XML; na przykład, jeśli ciąg zawiera znak 0x001A (CHAR(26) ), pojawi się następujący komunikat o błędzie:
Dla XML nie można serializować danych dla węzła „NoName”, ponieważ zawiera on znak (0x001A), który nie jest dozwolony w XML. Aby pobrać te dane za pomocą FOR XML, przekonwertuj je na binarny, varbinary lub typ danych obrazu i użyj dyrektywy BINARY BASE64.
Wydaje mi się to dość skomplikowane, ale mam nadzieję, że nie musisz się tym martwić, ponieważ nie przechowujesz takich danych lub przynajmniej nie próbujesz ich używać w zgrupowanej konkatenacji. Jeśli tak, być może będziesz musiał wrócić do jednego z innych podejść.
Wydajność
Powyższe przykładowe dane ułatwiają udowodnienie, że wszystkie te metody robią to, czego oczekujemy, ale trudno je sensownie porównać. Wypełniłem więc tabelę znacznie większym zestawem:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Dla mnie było to 575 obiektów z 7080 rzędami; najszerszy obiekt miał 142 kolumny. Muszę przyznać, że nie zamierzałem porównywać każdego podejścia wymyślonego w historii SQL Server; tylko kilka najważniejszych wydarzeń, które opublikowałem powyżej. Oto wyniki:
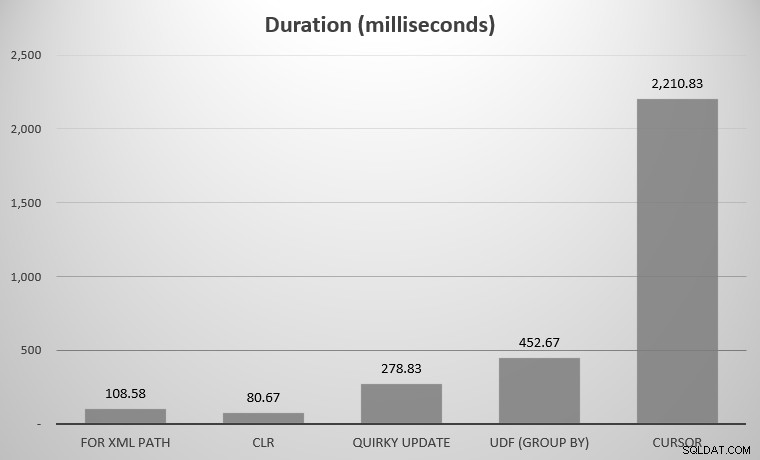
Możesz zauważyć, że brakuje kilku pretendentów; UDF przy użyciu DISTINCT a rekurencyjne CTE były tak poza wykresami, że przekrzywiły skalę. Oto wyniki wszystkich siedmiu podejść w formie tabelarycznej:
| Podejście | Czas trwania (milisekundy) |
|---|---|
| DLA ŚCIEŻKI XML | 108,58 |
| CLR | 80,67 |
| Dziwaczna aktualizacja | 278,83 |
| UDF (GRUPA WG) | 452,67 |
| UDF (DISTINCT) | 5893,67 |
| Kursor | 2210,83 |
| Rekurencyjne CTE | 70 240,58 |
Średni czas trwania w milisekundach dla wszystkich podejść
Zwróć też uwagę, że odmiany FOR XML PATH były testowane niezależnie, ale wykazywały bardzo niewielkie różnice, więc po prostu połączyłem je dla średniej. Jeśli naprawdę chcesz wiedzieć, .[1] notacja wyszła najszybciej w moich testach; MMW.
Wniosek
Jeśli nie jesteś w sklepie, w którym CLR jest w jakikolwiek sposób przeszkodą, a zwłaszcza jeśli nie masz do czynienia tylko z prostymi nazwami lub innymi ciągami, zdecydowanie powinieneś rozważyć projekt CodePlex. Nie próbuj wymyślać koła na nowo, nie próbuj nieintuicyjnych sztuczek i hacków, aby CROSS APPLY lub inne konstrukcje działają tylko trochę szybciej niż powyższe podejścia bez CLR. Po prostu weź to, co działa i podłącz to. I do licha, skoro masz też kod źródłowy, możesz go ulepszyć lub rozszerzyć, jeśli chcesz.
Jeśli problem stanowi CLR, to FOR XML PATH to prawdopodobnie najlepsza opcja, ale nadal musisz uważać na trudne postacie. Jeśli utkniesz na SQL Server 2000, jedyną możliwą opcją jest UDF (lub podobny kod nie opakowany w UDF).
Następnym razem
Kilka rzeczy, które chcę omówić w kolejnym poście:usuwanie duplikatów z listy, porządkowanie listy według czegoś innego niż sama wartość, przypadki, w których umieszczenie któregokolwiek z tych podejść w UDF może być bolesne i praktyczne przypadki użycia dla tej funkcji.