Czy nie jest wspaniale mieć nową wersję SQL Server? To jest coś, co zdarza się tylko co kilka lat, a w tym miesiącu widzieliśmy, jak jeden z nich osiągnął ogólną dostępność. (OK, wiem, że prawie stale otrzymujemy nową wersję bazy danych SQL na platformie Azure, ale uważam to za coś innego). Potwierdzając tę nową wersję, we wtorek T-SQL w tym miesiącu (prowadzony przez Michaela Swarta – @mjswart) poruszany jest temat wszystkich rzeczy związanych z SQL Server 2016!
Czy nie jest wspaniale mieć nową wersję SQL Server? To jest coś, co zdarza się tylko co kilka lat, a w tym miesiącu widzieliśmy, jak jeden z nich osiągnął ogólną dostępność. (OK, wiem, że prawie stale otrzymujemy nową wersję bazy danych SQL na platformie Azure, ale uważam to za coś innego). Potwierdzając tę nową wersję, we wtorek T-SQL w tym miesiącu (prowadzony przez Michaela Swarta – @mjswart) poruszany jest temat wszystkich rzeczy związanych z SQL Server 2016!
Dlatego dzisiaj chcę przyjrzeć się funkcji tabel czasowych SQL 2016 i przyjrzeć się niektórym sytuacjom związanym z planem zapytań, które możesz w końcu zobaczyć. Uwielbiam tabele temporalne, ale natknąłem się na pewien problem, o którym możesz chcieć wiedzieć.
Teraz, pomimo tego, że SQL Server 2016 jest teraz w RTM, używam AdventureWorks2016CTP3, który możesz pobrać tutaj – ale nie tylko pobieraj AdventureWorks2016CTP3.bak , pobierz także SQLServer2016CTP3Samples.zip z tej samej witryny.
Widzisz, w archiwum Samples znajduje się kilka przydatnych skryptów do wypróbowywania nowych funkcji, w tym niektóre dla tabel czasowych. Jest to korzystne dla wszystkich – możesz wypróbować kilka nowych funkcji, a ja nie muszę powtarzać tak dużo skryptu w tym poście. W każdym razie, weź dwa skrypty dotyczące tabel czasowych, uruchamiając AW 2016 CTP3 Temporal Setup.sql , a następnie Temporal System-Versioning Sample.sql .
Skrypty te konfigurują tymczasowe wersje kilku tabel, w tym HumanResources.Employee . Tworzy HumanResources.Employee_Temporal (chociaż technicznie można by to nazwać cokolwiek). Na końcu CREATE TABLE instrukcji, pojawia się ten bit, dodając dwie ukryte kolumny do użycia w celu wskazania, kiedy wiersz jest prawidłowy i wskazując, że należy utworzyć tabelę o nazwie HumanResources.Employee_Temporal_History do przechowywania starych wersji.
... ValidFrom datetime2(7) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL, ValidTo datetime2(7) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [HumanResources].[Employee_Temporal_History]) );
W tym poście chcę omówić to, co dzieje się z planami zapytań, gdy używana jest historia.
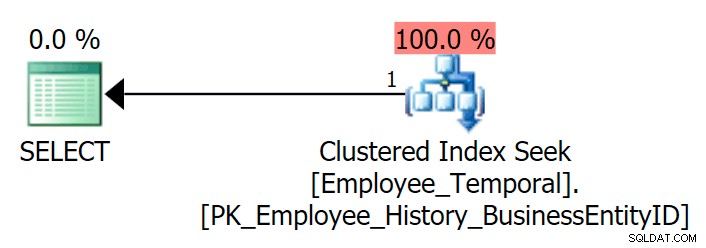
Jeśli wyślę zapytanie do tabeli, aby zobaczyć najnowszy wiersz dla konkretnego BusinessEntityID , zgodnie z oczekiwaniami otrzymuję Clustered Index Seek.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidTo FROM HumanResources.Employee_Temporal AS e WHERE e.BusinessEntityID = 4;
Jestem pewien, że mógłbym wysłać zapytanie do tej tabeli przy użyciu innych indeksów, jeśli takie miały. Ale w tym przypadku tak nie jest. Stwórzmy jeden.
CREATE UNIQUE INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
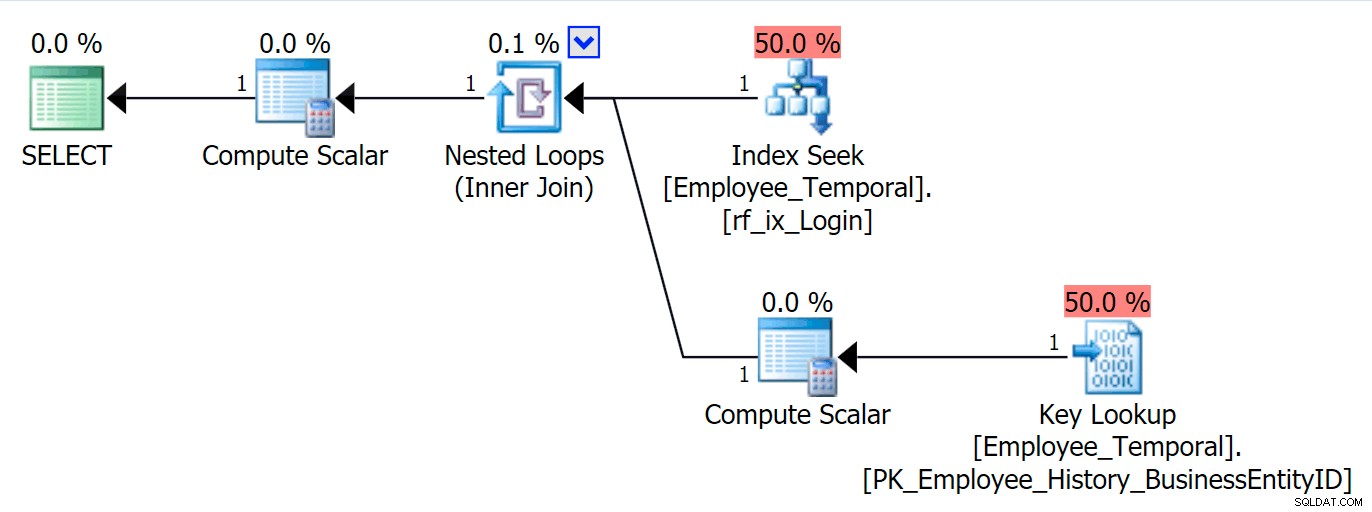
Teraz mogę wysłać zapytanie do tabeli według LoginID i zobaczy Key Lookup, jeśli poproszę o kolumny inne niż Loginid lub BusinessEntityID . Nic z tego nie jest zaskakujące.
SELECT * FROM HumanResources.Employee_Temporal e WHERE e.LoginID = N'adventure-works\rob0';
Skorzystajmy przez chwilę z SQL Server Management Studio i przyjrzyjmy się, jak ta tabela wygląda w Eksploratorze obiektów.

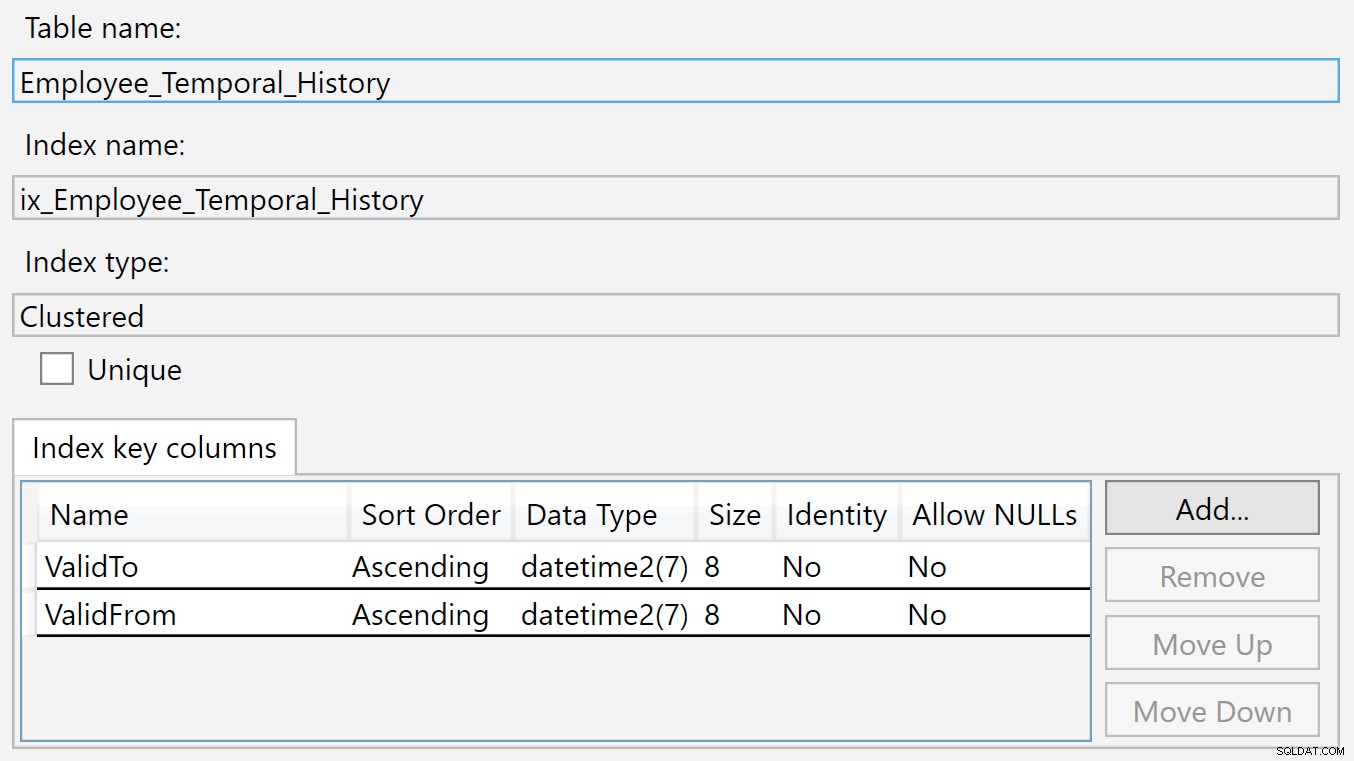
Możemy zobaczyć tabelę Historia wspomnianą w HumanResources.Employee_Temporal oraz kolumny i indeksy z samej tabeli i tabeli historii. Ale podczas gdy indeksy w odpowiedniej tabeli są kluczem podstawowym (w BusinessEntityID ) i indeks, który właśnie utworzyłem, tabela Historia nie ma pasujących indeksów.
Indeks w tabeli historii znajduje się na ValidTo i ValidFrom . Możemy kliknąć indeks prawym przyciskiem myszy i wybrać Właściwości, a zobaczymy to okno dialogowe:
Nowy wiersz jest wstawiany do tej tabeli History, gdy nie jest już ważny w głównej tabeli, ponieważ został właśnie usunięty lub zmieniony. Wartości w ValidTo kolumny są naturalnie wypełnione aktualnym czasem, więc ValidTo działa jak klucz rosnący, jak kolumna tożsamości, dzięki czemu nowe wstawki pojawiają się na końcu struktury b-drzewa.
Ale jak to działa, gdy chcesz wysłać zapytanie do tabeli?
Jeśli chcemy zapytać naszą tabelę o to, co było aktualne w danym momencie, powinniśmy użyć struktury zapytania, takiej jak:
SELECT * FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22';
To zapytanie musi łączyć odpowiednie wiersze z tabeli głównej z odpowiednimi wierszami z tabeli historii.
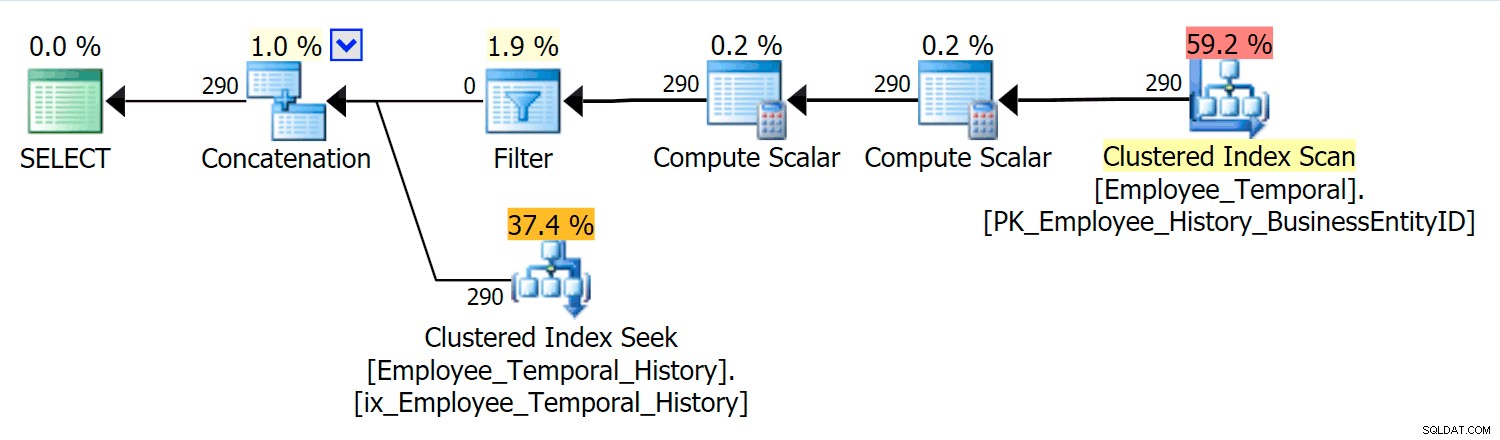
W tym scenariuszu wszystkie wiersze, które były prawidłowe w wybranym przeze mnie momencie, pochodziły z tabeli historii, ale mimo to widzimy klastrowane skanowanie indeksu względem tabeli głównej, która została odfiltrowana przez operator filtru. Predykat tego filtra to:
[HumanResources].[Employee_Temporal].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo] > '2016-06-12 11:22:00.0000000'
Wróćmy do tego za chwilę.
Wyszukiwanie indeksu klastrowego w tabeli Historia musi wyraźnie wykorzystywać predykat wyszukiwania na ValidTo. Początek skanowania zakresu wyszukiwania to HumanResources.Employee_Temporal_History.ValidTo > Operator skalarny('2016-06-12 11:22:00') , ale nie ma End, ponieważ każdy wiersz, który ma ValidTo po czasie, na którym nam zależy, jest wierszem kandydującym i musi zostać przetestowany pod kątem odpowiedniego ValidFrom wartość przez predykat rezydualny, którym jest HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Teraz przedziały są trudne do indeksowania; to znana rzecz, o której dyskutowano na wielu blogach. Najbardziej efektywne rozwiązania uwzględniają kreatywne sposoby pisania zapytań, ale takie inteligentne rozwiązania nie zostały wbudowane w tabele czasowe. Możesz jednak umieścić indeksy również w innych kolumnach, takich jak ValidFrom, a nawet mieć indeksy pasujące do typów zapytań, które możesz mieć w głównej tabeli. Z indeksem klastrowym będącym kluczem złożonym w obu ValidTo i ValidFrom , te dwie kolumny są uwzględniane w każdej innej kolumnie, co stanowi dobrą okazję do niektórych testów rezydualnych predykatów.
Jeśli wiem, którym loginem jestem zainteresowany, mój plan przybiera inny kształt.
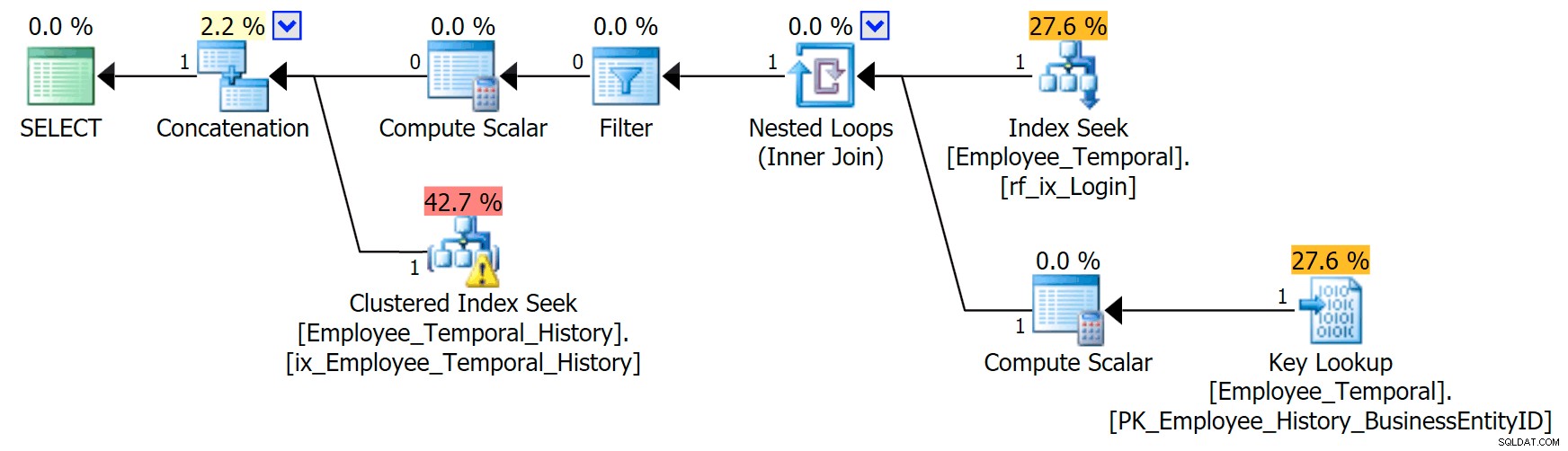
Górna gałąź operatora konkatenacji wygląda podobnie do poprzedniej, chociaż operator filtra wszedł do walki, aby usunąć wszystkie nieprawidłowe wiersze, ale Clustered Index Seek w dolnej gałęzi ma ostrzeżenie. Jest to ostrzeżenie dotyczące rezydualnego predykatu, podobnie jak przykłady w moim wcześniejszym poście. Jest w stanie filtrować do wpisów, które są ważne do pewnego momentu po czasie, na którym nam zależy, ale predykat rezydualny filtruje teraz do LoginID jak również ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <= '2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] = N'adventure-works\rob0'
Zmiany w wierszach rob0 będą stanowić niewielką część wierszy w historii. Ta kolumna nie będzie unikatowa jak w głównej tabeli, ponieważ wiersz mógł być zmieniany wiele razy, ale wciąż jest dobry kandydat do indeksowania.
CREATE INDEX rf_ixHist_loginid ON HumanResources.Employee_Temporal_History(LoginID);
Ten nowy indeks ma znaczący wpływ na nasz plan.
Teraz zmieniło nasze wyszukiwanie indeksu klastrowego w skanowanie indeksu klastrowego!!
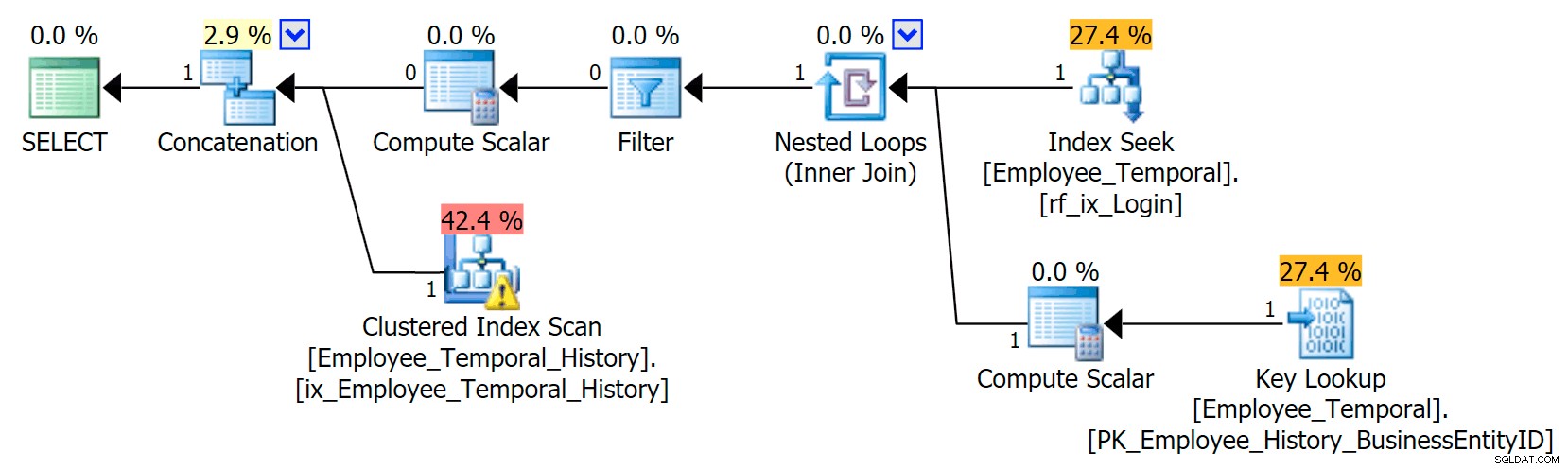
Widzisz, Optymalizator zapytań sprawdza teraz, że najlepiej byłoby użyć nowego indeksu. Ale decyduje również, że wysiłek związany z wyszukiwaniem, aby uzyskać wszystkie inne kolumny (ponieważ prosiłem o wszystkie kolumny) byłby po prostu zbyt dużo pracy. Osiągnięto punkt krytyczny (niestety błędne założenie w tym przypadku), a zamiast tego wybrano Clustered Index SCAN. Nawet jeśli bez indeksu nieklastrowego najlepszą opcją byłoby użycie wyszukiwania indeksu klastrowego, gdy indeks nieklastrowy zostanie wzięty pod uwagę i odrzucony z powodów krytycznych, wybiera skanowanie.
Frustrujące jest to, że dopiero co stworzyłem ten indeks i jego statystyki powinny być dobre. Powinien wiedzieć, że wyszukiwanie, które wymaga dokładnie jednego wyszukiwania, powinno być lepsze niż skanowanie indeksu klastrowego (tylko według statystyk – jeśli myślisz, że powinno to wiedzieć, ponieważ LoginID jest wyjątkowy w tabeli głównej, pamiętaj, że nie zawsze tak było). Podejrzewam więc, że należy unikać wyszukiwań w tabelach historii, chociaż nie zrobiłem jeszcze wystarczająco dużo badań na ten temat.
Teraz, gdybyśmy przeszukiwali tylko te kolumny, które pojawiają się w naszym indeksie nieklastrowym, uzyskalibyśmy znacznie lepsze zachowanie. Teraz, gdy wyszukiwanie nie jest wymagane, nasz nowy indeks w tabeli historii jest szczęśliwie używany. Nadal musi zastosować predykat rezydualny oparty tylko na możliwości filtrowania według LoginID i ValidTo , ale zachowuje się znacznie lepiej niż w przypadku skanowania indeksu klastrowego.
SELECT LoginID, ValidFrom, ValidTo FROM HumanResources.Employee_Temporal FOR SYSTEM_TIME AS OF '20160612 11:22' WHERE LoginID = N'adventure-works\rob0'
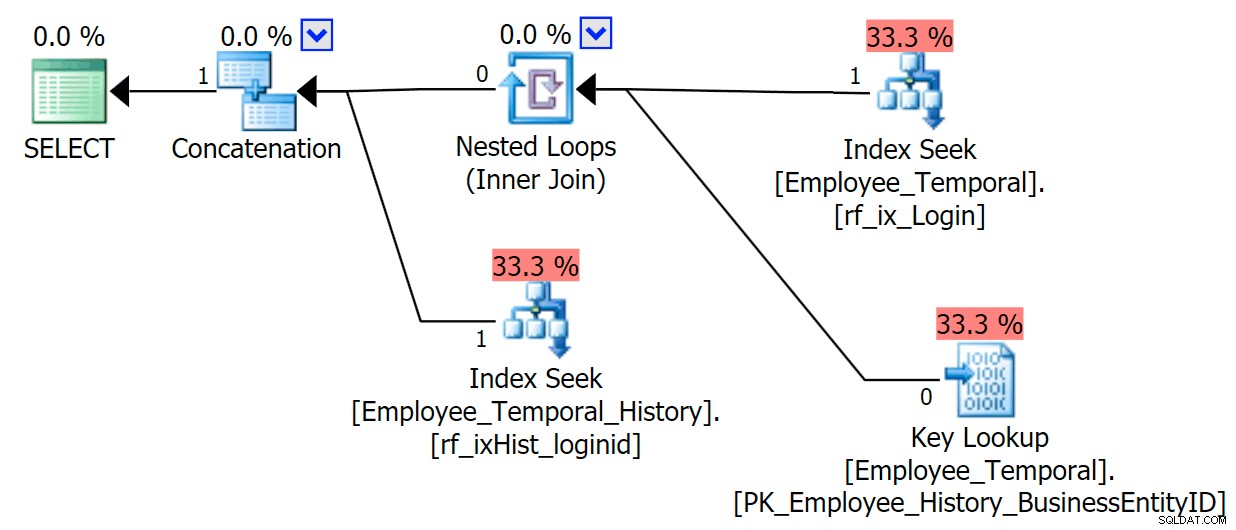
Dlatego indeksuj swoje tabele historii na dodatkowe sposoby, biorąc pod uwagę sposób, w jaki będziesz je przeszukiwać. Dołącz niezbędne kolumny, aby uniknąć wyszukiwań, ponieważ naprawdę unikasz skanowań.
Te tabele historii mogą się powiększać, jeśli dane często się zmieniają. Uważaj więc na to, jak się z nimi obchodzisz. Ta sama sytuacja ma miejsce, gdy używasz drugiego FOR SYSTEM_TIME konstruktów, więc powinieneś (jak zawsze) przejrzeć plany tworzone przez Twoje zapytania i zaindeksować, aby upewnić się, że jesteś dobrze przygotowany do wykorzystania bardzo potężnej funkcji SQL Server 2016.